基于Apriori算法的零售商品购买关联分析
2021-09-26王明艳
王明艳
(湖南财经工业职业技术学院,湖南 衡阳 421002)
大数据、云计算技术的不断发展,改变了人们的教育、医疗、消费等生活习惯,数据量正以惊人的速度扩增。海量的数据中能够真正被企业分析和运用的只占较小的一部分。大部分企业进行业务决策常常依赖于“直觉”或“本能”。企业在面对日益激烈的市场竞争时,需要不断提高决策的准确度和灵敏度。企业产生的数据隐藏着巨大的商业价值,企业需要从大量数据中挖掘出有助于企业决策的信息与知识。在此背景下,数据挖掘 (Data Mining,DM)、商务智能 (Business Intelligence,BI)应运而生,并日益得到了相关行业的重视。
零售商店购物系统在运作过程中产生了大量的商品消费数据,数据蕴藏了零售商店所有消费者的消费行为,如果不加以合理利用,这些数据将变得毫无价值。经典的购物篮分析就是帮助企业针对商品的相关性分析顾客一般同时会购买哪些商品,购买了很多商品之后,还会购买哪些商品,以及购买这些商品的概率,为企业的经营活动提供决策参考。本文采用数据挖掘中的Apriori算法,挖掘商品与商品之间的关联关系,通过了解用户在店铺中同时会购买什么商品,来优化店铺商品的布局,并将几种商品摆放在一起或者放在网页中的同一页,方便用户快速找到该商品,促进商品的销售;帮助企业设计有效的促销方案,将商品进行捆绑销售,推出商品的优惠套餐,提升购买的价值;了解用户购买了什么商品,还会购买什么商品,可以在实体店或电子商务网站进行商品的关联推荐。
1 数据挖掘概述
DM也称为数据库中的知识发现,简称KDD(Knowledge Discover in Database),已成为数据库和人工智能(AI)领域的研究热点。DM的技术定义是从大量的 (Massive)、不完全的 (Incomplete)、有噪声的 (Noisy)、模糊的 (Fuzzy)、随机的(Random)实际应用数据中提取出隐含的(Implicit)、事先不知道的(Previously unknown)、潜在有用的(Potentially useful)信息和知识的过程[1]。DM是一门交叉学科,是包含了人工智能、机器学习、高性能计算、统计学、模式识别、可视化、数据库技术等学科领域的产物。数据挖掘能帮助企业预测未来发展趋势并辅助企业进行科学决策。常见的挖掘算法包含分类与预测、聚类、关联规则、孤立点探测,数据挖掘广泛应用于零售业、金融、电信、医药、制造业、政府等行业和领域。将数据挖掘技术应用于传统商业领域可提高企业数据分析能力,优化企业业务流程,有效提高企业市场竞争力。
2 关联分析概述
关联分析(Association analysis)是一种无监督的学习算法,用于寻找交易事务中不同商品之间存在的关联关系。
2.1 频繁项集
频繁项集(Frequent itemsets)是指在数据集中频繁出现的项集,该项集是满足最小支持度、置信度阈值的所有项的集合。
2.2 关联规则
关联规则(Association Rules)能够反映一种事物与其他事物之间的相互依存和关联关系,关联规则挖掘可以发现大量数据中项集之间频繁出现的项集[2]。关联规则是在1993年SIGMOD会议上,由Agrawal,lmielinski,Swami提出。关联规则是数据挖掘中一个重要的研究方向,通过关联分析能够为用户提供具有参考价值的信息,辅助决策。对于消费者而言,在网上购物时,商城系统会自动为用户推荐合适的商品、赠送优惠券,满足用户需求的同时诱导消费者消费。对于商家而言,通过商品的关联程度设计商品的促销方案、调整商品的摆放位置和组合方式,方便顾客购买更多所需要的商品,进行相关推荐或将相应的关联商品进行精准营销,挖掘更多潜在客户。关联规则挖掘的步骤是找到所有频繁项集,频繁项集生成强关联规则,关联规则必须要大于或等于最小支持度和最小置信度。
2.3 支持度和置信度
支持度(Support)是指关联的数据在数据集中出现的次数在总数据集中所占的比例,在[0,1]中取值。例如购买了A商品,还购买了B商品,支持度计算公式为Support(A→B)=P(A∪B),该度量值表示A商品和B商品同时出现的概率。支持度和置信度是Apriori算法中两个重要的值,置信度(Confidence)用来表示一个数据出现后,另一个数据出现的概率,即数据的条件概率,在[0,1]中取值。置信度的计算公式为Confidence(A→B)=Support(A∪B)/Support(A),该度量值表示商品A和商品B同时出现的概率占商品A出现概率的比值。
2.4 提升度
置信度没有考虑后项中项集的支持度,因此需要用提升度(Lift)来代替置信度以确保规则的可信度。提升度反映了关联规则中商品A与商品B的相关性,是置信度和后项中项集的支持度的比值,通过Lift(A→B)=Support(A→B)/Support(A)*Support(B)=Confidence(A→B)/Support(B)公式进行计算。当Lift(A→B)>1时,表示A对B有诱导作用,A与B正相关,提升度越高,正相关性越高;当Lift(A→B)=1时,表示A与B相互独立,没有相关性;当Lift(A→B)<1时,表示A对B有抑制作用,A与B负相关,提升度越高,负相关性越高。
3 Apriori算法原理
Apriori算法常用来挖掘数据间的关联规则,在数据挖掘中应用广泛,主要通过在大规模数据集中寻找频繁项集和关联规则[3]。算法包含两个方面,一是寻找频繁项集,二是挖掘关联规则。Apriori算法剪枝过程中需要满足先验性原理,即频繁项集的子集必为频繁项集,例如项集{A,C}是频繁项集,则{A}和{C}也是频繁项集;非频繁项集的超集一定是非频繁项集,例如项集{D}不是频繁项集,则{A,D}和{C,D}也不是频繁项集。
Apriori算法包含两个步骤,连接步和剪枝步,Apriori算法是将最小支持度和数据集作为输入参数,算法首先扫描所有项集表,生成所有单个元素的项集,接着通过比较项集大于或等于最小支持度和置信度,不满足的项集将会被删除,接着通过连接步生成包含两个元素的项集,重复上述步骤,在通过算法中的剪枝步,将不满足先验性原理的项集删除,直到找到满足要求的频繁项集。
除了Apriori算法,还有一种经典的FP-growth算法。Apriori算法产生频繁项集的过程中需要多次扫描交易数据库;FP-growth算法是利用树形结构,不需要产生候选频繁项集,节省了扫描数据库的次数,加速了寻找频繁项集的速度。使用FP-growth算法可以高效地发现频繁项集,但不能用于发现关联规则。因此,在实际应用中,可使用FP-growth算法来找出频繁项集,采用Apriori算法进行关联规则的挖掘。
4 零售商品购买关联分析
采集某零售商店消费者购买商品的部分数据,利用Apriori算法对消费者购买商品进行关联分析。
每一条交易称为一个事务,给定一个事务集合T(Transaction),假设Ck是候选项集,Lk是频繁项集,连接步就是从频繁k-1项集集合中产生候选k项集集合。表1为事务购买集合。

表1 事务购买集合
结合Apriori算法,对事务集合进行扫描计数,得到C1候选项集,并计算支持度,得到相关数据,见表2。

表2 C1候选集支持度
通过比较,去掉低于最小支持度50%的项集,产生频繁项集L1,见第52页表3。

表3 L 1频繁项集支持度
接着,进行连接步,产生候选项集C2,得到相关数据,见第52页表4。
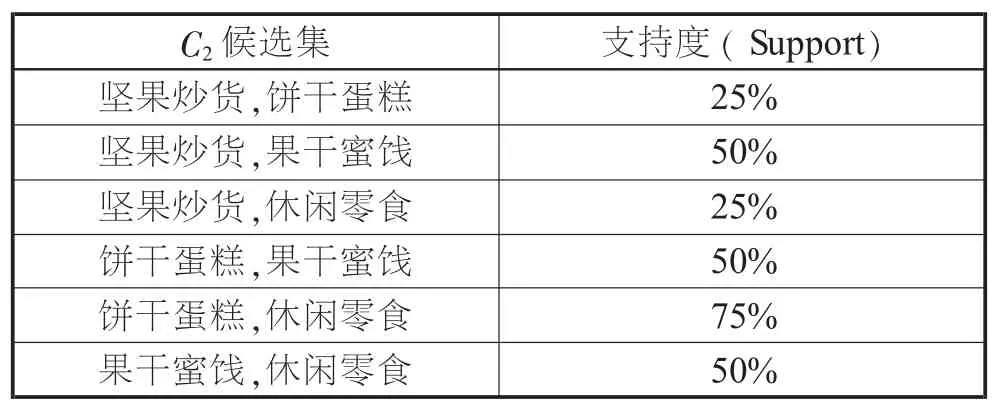
表4 C2候选集支持度
通过比较,去掉低于最小支持度50%的项集,产生频繁项集L2,得到相关数据,见第52页表5。

表5 L 2频繁项集支持度
由表5可知, {坚果炒货,果干蜜饯}和{饼干蛋糕,果干蜜饯}相乘,得到{坚果炒货,饼干蛋糕,果干蜜饯},通过Apriori算法的剪枝步将非频繁项集删除,例如{坚果炒货,饼干蛋糕,果干蜜饯}的3个子项, {坚果炒货,饼干蛋糕},{坚果炒货,果干蜜饯},{饼干蛋糕,果干蜜饯},其中{坚果炒货,饼干蛋糕}不在频繁2-项集中,经过剪枝得到频繁3-项集{饼干蛋糕,果干蜜饯,休闲零食},见表6。

表6 L 3频繁项集支持度
结束算法得到关联规则:顾客购买了饼干蛋糕,又购买了果干蜜饯,接下来购买休闲零食的可能性是50%/50%,即100%,因此顾客购买了饼干蛋糕和果干蜜饯,就一定会购买休闲零食。
5 基于SPSS Mode le r软件的关联分析
5.1 SPSS Modeler软件介绍
SPSS Modeler软件(原名Clementine)是一个直观的、拖放式的数据挖掘工具,是领先可视化数据科学和预测分析的平台,可以快速建立预测性模型,能够进行数据准备和发现、预测分析,帮助企业实现价值并获得预期的效果。SPSS Modeler软件提供了一系列数据挖掘技术,可以满足任何数据挖掘需要,包含预测、聚类、关联、分类等算法[4]。
5.2 数据准备
零售商店消费者购买记录存放在SPSS文件中,打开SPSS Modeler软件后,将一个SPSS统计文件拖拽到数据流编辑区进行数据收集、数据展示与预处理、数据建模、模型评价等。打开零售商店消费者购买记录.sav文件,并勾选“使用字段格式信息确定存储类型”,通过过滤器将不需要的字段删除,例如将商品的单价等对商品关联分析没有价值的字段去掉,只留下商品信息和消费者ID,接着读取数据类型,并预览表中所有的原始数据记录。
5.3 数据预处理
通过消费者ID对消费者进行排序,在节点工具中选择记录排序,拖动记录选项下的排序到数据流编辑区,并将数据流编辑区中的消费者购买记录.sav文件与排序节点建立连接,接着对排序节点进行设置,按照消费者ID进行升序排序。接着在节点工具下选择“设为标志”节点来实现整个数据的标志化、结构化的处理,具体操作步骤是:首先通过读取前的商品信息得到可用的设置值;其次勾选“字段名扩展”设置字段的前缀或后缀名称,通过向左的按钮创建“标志字段”,标志字段分别用T和F表示,T表示消费者购买了哪种商品,F表示消费者未购买该种商品;最后勾选汇总关键字,通过消费者ID进行汇总,将多条同一消费者ID记录变成一条记录。通过上述步骤完成数据预处理阶段,下面将对得到的数据进行关联分析。
5.4 关联分析
在数据预处理的基础上,通过Apriori算法实现建模的分析。首先,可以通过字段选项的“类型”节点制定变量的角色,将类型节点拖动到数据流编辑区,建立过滤器节点与类型节点的连接,编辑类型节点,将类型中的每一种角色都设置为“任意”,各字段既是输入又是目标。其次,使用Apriori算法构建关联规则模型,将建模下的Apriori节点拖动至数据流编辑区,建立类型与Apriori节点之间的连接并编辑,字段设置为使用预定义角色,模型设置选择自动,使用“分区数据”,勾选“仅包含标志变量的true值”,并设置Apriori算法里的最小支持度、置信度和最大前项数。设置完成后点击运行,可以得到一个能够反映数据之间强弱关系的网络图,商品与商品间连接线的粗细能够表示连接强度,网络图的下方含有阈值条限定,用于显示连接线的频数值,拖动阈值条,得到新的网络图,线条的粗细也发生了变化,关联程度低的商品不会显示在网络图中。最后,为了达成更为直观的效果,将展示结果用表格的形式输出,继续过滤,只显示消费者ID号以及系统推荐的商品。
综上所述,借助SPSS Modeler软件,采用Apriori算法实现零售商店购买记录数据的关联分析,挖掘出关联规则,并应用到销售过程中,顾客在购买了某种商品后,向他们推荐可能会购买的商品,可通过商品之间的关联关系来设计商品促销方案、商品的陈列方式,促进销售,提高店铺营收。
