快照引起虚拟化业务中断的思考
2021-09-23李守龙
李守龙
(苏州市立医院北区,江苏苏州 215031)
0 引言
随着各行各业对信息化的依赖程度越来越高,同时也对信息化服务的可靠性、安全性、便捷性提出了更高的要求[1]。虚拟化技术能够在整合资源的同时提高可靠性和安全性,因此在医疗行业得到了广泛的发展。我院也利用VMware vSphere虚拟化技术搭建了非核心业务平台,经过一段时间的使用,虚拟化平台总体稳定、可靠,但是也存在着一些风险因素。
1 我院虚拟化平台基础架构
我院虚拟化平台采用VMware vSphere产品构建,并与微分段分布式防火墙结合增强虚拟化平台安全防护措施。底层架构中各虚拟化主机基于FC SAN存储交换机与存储连接,存储设备自身采用双活架构的方式与虚拟化平台结合,保证底层存储和上层虚拟机的高可用性。服务器端的管理与业务网络基于低延迟的万兆光交换机接入,保证了整体网络环境的带宽传输性能与效率。服务器操作系统使用ESXi 6.7,使用VCSA 6.7集中管理主机与集群。虚拟化集群启用故障转移功能当某一个节点出现故障,系统遵循对应的规则转移失效节点的业务虚拟机,以免节点失效对业务运行带来影响[2]。为了更进一步加强虚拟化平台的数据保护,采用专业虚拟机和数据库备份平台对虚拟机和数据库进行定时备份。拓扑结构如图1所示:
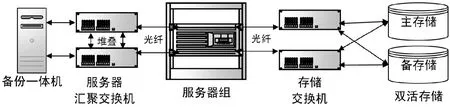
图1 拓扑结构图Fig.1 Topological structure diagram
2 事件回顾
某日凌晨4点接到影像系统故障报修,报错信息提示为数据库连接错误。登录数据库服务器发现有意外断电事件,手工启动ORACLE服务。PACS系统可以正常登陆,但无法调取患者影像。初步怀疑网络或存储问题,针对性的进行虚拟服务器、光纤交换机和影像存储的排查,除了操作系统有意外重启事件外,没有其他明显异常。通过虚拟化管理平台(VMware vCenter)发现有物理服务器未响应情况,而且有大批量的虚拟服务器自动迁移记录,并且每隔20分钟就有一台物理主机发生未响应情况,最终集群中所有物理主机均发生未响应情况,包括虚拟化管理平台在内的所有业务中断,启动应急预案。
进入机房查看硬件设备,发现物理主机处于宕机状态,立即逐一进行重启操作,业务逐个得到恢复。密切关注虚拟化管理平台动态,物理主机未响应情况再次出现,每隔一定时间就有几个业务系统受到影响。最终通过不断的观察和分析发现是因为物理主机CPU资源耗尽而导致了宕机。故障发生后故障转移机制发挥作用,把宕机的物理主机上的虚拟服务器自动迁移到集群中的其他主机,进而引起其他主机的CUP资源的耗尽,直至集群中所有主机宕机。经讨论决定同时开启所有物理主机,锁定第1台宕机的物理主机,分析运行在其上的虚拟服务器,逐一关闭这些虚拟服务器,找出有嫌疑的虚拟机。经过验证发现承载体检业务的虚拟服务器有重大嫌疑,立刻将体检系统划分到一个新的集群中,同其他业务分开,独享一个集群资源,并对资源进行阈值限定,等同于对该虚拟服务器进行隔离,该集群中的故障不会转移到其他集群。
至此其他集群中的主机未再出现宕机情况,除Pacs系统外的其他业务均得到了恢复。Pacs系统虚拟服务器因发生自动迁移导致注册和授权信息不一致,应用程序无法启动提供服务,紧急联系厂商进行总部授权,耗费约3小时,虽然启动了应急预案,但是未达到满意的预期。
体检集群中物理主机仍然循环宕机,体检业务系统无法使用,着手新建虚拟服务器并搭建软件运行环境及数据恢复,预计耗时5小时。同时仍然不放弃问题的排查,基本排除病毒、木马、网络问题等原因,重点进行虚拟化平台和虚拟服务器的检查,通过对比分析区别于其他虚拟服务器的是该虚拟机上存在快照。快照是虚拟服务器的备份文件,用于虚拟服务器出现故障时快速还原到快照建立的时间点。为了尽快排查到问题将快照删除,删除后集群中主机未再发生宕机,故障得到修复,解除所有应急预案,组织科室人员进行应急期间的数据处理。
之后所有业务运行正常,信息科对快照事件进行追溯。事件发生前一日在日常巡检中发现体检系统虚拟服务器磁盘空间需要扩容,向服务提供商提出进行磁盘扩容。工程师在当日夜间23时进行磁盘空间的扩容,扩容完成后为确保安全对虚拟服务器建立了快照,次日凌晨出现本次事件。
事件发生一周后在测试环境中无论是对克隆的体检业务虚拟服务器,还是对新建的虚拟服务器进行磁盘扩容和建立快照,均未能复现当时的故障。总结本次事件原因为:虚拟服务器磁盘空间扩容后建立了快照,快照的存在引发了虚拟化软件的某项BUG。未在相关文献中查到类似问题,定性本次事件是快照引起的偶发意外事件,未对相关公司、人员进行追责。
3 事件思考
(1)信息系统难免发生故障,为了第一时间能作出高效、有序应急响应,各单位都会制定自己的应急预案。应急预案是紧急情况下的行动指南,对医疗秩序的维持发挥着至关重要的作用。因此应急预案的制定要有多部门的参与,并充分考虑各种情况,有依有据、切实可行。预案完成后要进行相应的培训和多部门演练,根据演练情况不断改善和改进流程,才能在灾难发生时从容应对,最大程度的减少对患者和医护人员的影响,保障正常的就医秩序。一旦应急预案启动各部门要执行预案,不得以系统故障为由,推辞患者,损害患者就医权利。
(2)在虚拟化建中要从各个方面整体、充分考虑安全性。我们在建设中多注重对硬件故障的保障,忽视了软件层面的问题。通常情况下,网络安全设备和审计系统均部署于物理服务器的外部,无法过滤物理主机上各虚拟服务器的外部,无法过滤物理主机上各虚拟服务器之间的通信数据,这样就会产生安全隐患[3]。需要考虑和虚拟化相结合、针对性的软硬件安全产品。虚拟化平台本身是高级服务器管理软件,是软件一定存在漏洞,如近期发现的VMware vSphere Server远程代码执行漏洞,同操作系统一样要定期升级版本和更新补丁,保障虚拟化本身的安全性和稳定性。
(3)虚拟化的管理不能完全依赖服务提供商,培养日常运维的队伍尤其重要。只有日常的运维加上服务商的定期专业化巡检才能最大程度的保障平台安全。同时虚拟化平台权限要细化,不同人员按级别分配不同的管理权限,一定程度上可以减少误操作的发生。内、外部运维要通过堡垒机进行实施,所有实施都要有电子化的记录,便于事件追溯和事后分析。虚拟化平台是一个整体性的平台,日常运维和升级都可能影响到业务系统的使用,因此可能影响业务系统运行的操作要审批、备案,经科室同意并在有回退方案和应急预案的情况下,方能进行相应的调整。
(4)机房中虚拟化相关的(交换、存储、服务器)设备标识要准确、简明扼要,并张贴在设备显著位置,一旦监测到虚拟化设备故障可以快速定位。可以把虚拟化拓扑结构张贴在运维区域,也可以把物理主机上运行的虚拟服务器标识在主机上,定期进行相关信息的更新,做到对虚拟资产的掌控,运维也更加的便捷。
(5)所有资源划分在一个集群中,在抵抗硬件故障上优势明显,理论上在N-1台服务器同时故障的情况下依然可以保障服务的可用性,但在特殊情况下可能会引起整个虚拟化平台的不稳定。通过本次事件我们重新审视资源的分配问题,根据业务系统划分不同的集群。集群划分时尽量选择同品牌型号的物理主机,可以在一定程度上避免虚拟服务器故障转移中出现业务系统授权信息不一致导致的不可用问题。每个集群中要有4台以上的物理主机,要有紧急程度不一的信息系统,尽量避免两个及以上重要业务系统在同一个集群中,避免主备虚拟服务器在同一个集群中。
(6)虚拟化的技术越来越成熟完善,在故障发生时会按照一定策略进行故障的转移,保障虚拟服务器的可用性。虚拟服务器的可用不意味着业务的持续。不同的厂商在部署应用时均有自己的加密机制,发生故障转移后,物理主机的不同可能会导致软件厂商识别到未授权的部署,从而导致系统无法提供服务。重新授权往往耗费时间长,对医疗业务的影响大。可以通过测试环境手动迁移虚拟服务器进行授权问题检查,如果出现相应问题需要和厂商一起制定一套备用授权机制,以备紧急情况下的临时使用。
(7)及时更新操作系统补丁可以增强安全性,避免漏洞被恶意利用。本次事件中有10台以上运行Windows Server 2008 R2操作系统的虚拟服务器无法引导进入操作系统,为当日事件雪上加霜。原因均为未进行补丁测试就进行了补丁的更新,并在更新后未进行重启操作。吸取本次教训,更正补丁策略,不再集中进行补丁的更新。划分各种版本操作系统虚拟服务器,专用于补丁更新测试。测试通过后制定更新计划,分批分类进行更新,更新后制定重启计划,逐台进行重启验证。新建虚拟服务器不再使用官方已停止更新的版本,有计划的对正在使用的老旧操作系统进升级,保障操作系统的安全性和可靠性。
4 结语
随着医院的信息化程度越来越高,临床业务也越来越依赖信息系统,信息系统的安全和稳定关系民生。一旦发生安全事件,经济损失事小,给患者和社会带来的负面影响事大。虚拟化平台相比传统的服务器模式有着安全优势,作为医疗信息行业的从业者,我们不能麻痹大意,要从各种事件中吸取教训,优化各种安全策略,保障安全事件不发生或发生后有快速的应急或恢复措施。
