基于深度学习算法的京津冀地区综合干旱评估模型构建*
2021-09-17胡小枫王冬利赵安周刘宪锋王金杰
胡小枫,王冬利,赵安周,3,刘宪锋,王金杰
(1.河北工程大学矿业与测绘工程学院,邯郸 056038;2.邯郸市自然资源空间信息重点实验室,邯郸 056038;3.中国科学院地理科学与资源研究所资源与环境信息系统国家重点实验室,北京 100101;4.陕西师范大学地理科学与旅游学院,西安 710119)
干旱具有发生频率高、持续时间长、影响范围广等特点,常导致作物减产、森林火灾、病虫害加重等事件,严重阻碍社会经济的可持续发展[1]。干旱对农业的影响最大,也最为直接,长期干旱会导致农作物死亡减产,进而影响粮食安全[2]。近20a 干旱对农业生产的影响日益加重[3]。据统计,2017年中国因干旱导致的农作物受灾面积达到98748km2,直接经济损失超过375 亿元[4]。因此,采用先进科学的方法对干旱进行准确评估,及时精确地反映旱情发生的范围和过程对农业生产具有重要意义[5]。
目前国内外常用的干旱评估方法有基于站点数据的干旱评估指数、基于遥感数据的干旱评估指数以及综合干旱评估指数[6-7]。基于站点数据的干旱评估方法已经较为成熟,目前已广泛用于干旱评估,但存在气象站点的数量有限且分布不均,不能对大范围的干旱进行实时有效评估等缺点[8]。相比于基于站点数据的干旱评估方法,遥感评估方法因其高时空分辨率且具有连续性、可实现对大范围干旱事件进行有效评估等优点而在大尺度的干旱评估中得到有效应用,但是仍存在构建模型要素单一、要素之间的关系不清晰等问题[9-11]。综合干旱评估指数主要表现在多源数据的引入和研究方法的革新。如王行汉等[12]利用传统回归多项式方程将归一化植被指数(Normalized Difference Vegetation Index,NDVI)和地表温度(Land Surface Temperature,LST)进行拟合,构建温度增强型植被干旱指数来评估区域干旱。余灏哲等[13]综合考虑干旱发生过程中的大气降水、植被生长和土壤水分盈亏等致旱因子,利用多元回归的方法构建出综合干旱指数对京津冀地区干旱进行时空评估。Brown 等[14]综合考虑降水盈缺、植被生长状况和生态环境参数等因素,将气象干旱评估指标、遥感评估指标和其它生物信息结合构建了植被干旱响应指数,并较为准确地评估了美国中北部7个州的干旱情况。综上,虽然国内外学者已从不同层面对干旱监测开展了一系列研究,并取得了一定的研究成果。然而当前研究多采用单一要素或单一系统要素开展干旱评估研究,其综合干旱评估模型的构建多采用线性模型,无法全面刻画干旱影响要素之间的非线性特征[15]。
京津冀地区是中国重要的粮食产出基地,随着全球气候的变化,该地区干旱频发,对作物生产和全国粮食供应造成了严重影响[16]。鉴于此,本研究利用深度学习框架Tensorflow,从诸多干旱致灾因子中提取影响干旱的主要信息,厘清影响干旱各要素之间的非线性关系,构建京津冀地区的综合干旱评估模型,以期及时对干旱进行预警,为相关部门提供决策支持,进而为指导当地农业生产提供科学的参考依据。
1 资料与方法
1.1 研究区概况
京津冀地区地处36−42.6°N,113.4−119.8°E,总面积21.7×104km2[17],包括北京、天津两个直辖市以及河北的13 个地市(图1)。地势由西北向东南倾斜,北靠燕山山脉,南面华北平原,西倚太行山,东临渤海湾,平均海拔500m 以上[18]。该地区降水量波动较大,70%以上的降水量主要集中在夏季6−9月,冬季受西伯利亚高压的影响,寒冷干燥且少降水,春季多大风,气温上升较快,受地理位置、地形和全球气候变暖的影响,京津冀地区是干旱频发地区,常有“十年九旱”之说[18]。

图1 京津冀地区地理位置、高程与气象站点分布Fig.1 Geographical location,elevation and distribution of meteorological stations in Beijing-Tianjin-Hebei region
1.2 数据来源及处理
1.2.1 遥感数据
2007−2017年研究区MODIS-LST(地表温度)和NDVI(归一化植被指数)数据来源于NASA 数据网(http://serach.earthdata.nasa.gov)。NDVI 数据为MOD13A3 的植被指数数据,空间分辨率为1km,时间尺度为月;地表温度数据是以8d 为时间分辨率的MOD11A2 数据集,空间分辨率1km,以相应月份中所有影像在该月中的有效天数所占比例作为权重对其进行加权平均相加复合成月数据,其具体合成方法见文献[19]。
2007−2017年高分辨率逐月降水数据来源于文献[20],该数据集基于Delta 降尺度方法,在CRU TS v4.02 空间尺度下进行降尺度处理得到,具有较高的精度,空间分辨率为1km。DEM 数据来源于中国空间地理数据(http://www.gscloud.cn/sources/)的STERM 90m 分辨率的数字高程模型(Digital Elevation Model,DEM)。采用双线性插值方法将此数据进行重采样到1km 与MODIS 数据进行空间匹配。将上述遥感数据进行标准化计算,用于干旱评估模型的构建。
1.2.2 站点实测数据
京津冀地区22 个气象站点2007−2017年逐月降水量和平均气温数据来源于中国气象数据共享网(http://www.nmic.cn/,图1),主要用于SPI 和SPEI指数计算。
2007−2013年研究区内9个农业气象站点中的旬土壤湿度数据来源于中国气象数据共享网,主要用来进行模型验证(表1)。

表1 土壤湿度验证台站信息Table 1 The information of soil moisture verification sites
该资料集来自于《中国农作物生长发育和农田土壤湿度旬值数据集》中的土壤湿度数据,其中详细记录了作物名称,以及10cm、20cm 和50cm 土壤相对湿度、从播种到本旬末的日平均气温等数据。将反映作物生长状况的10cm深度旬土壤相对湿度数据采用算术平均值的方法计算成月时间尺度数据,并用来对本研究所构建的综合干旱评估模型进行验证[15]。
1.2.3 其它数据
中国土壤粒度分布数据集从中山大学(http://globalchange.bnu.edu.cn/)网站获取,并采用简化的土壤有效持水量计算方法,计算京津冀地区1km 空间分辨率的土壤可利用持水量(Available Water Capacity,AWC)分布。京津冀地区2016年的气候概况、干旱和暴雨等灾害情况来自于《2016年河北省气候公报》和《2016年中国气象灾害年鉴》,这些数据主要用于干旱空间分布的验证。
1.3 模型输入变量计算方法
1.3.1 标准化距平值
将归一化植被指数(NDVI)、降水和地表温度的距平值进行标准化处理后作为模型的输入变量,具体方法为

式中,stXα为标准化距平指数,其中包括植被指数的标准化距平指数(aNDVI)、标准化降雨距平指数(aPRE)和标准化陆地表面温度距平指数(aLST);Xi代表这些指数的某年某月的值,为这些指数研究时间段内多年的月平均值,σ 为研究时段内多年的指数标准偏差。stXa越大代表指数的变异程度越大,其中aNDVI 和aPRE 数值越小代表干旱程度越严重,而aLST 则相反,数值越大代表干旱越严重。
1.3.2 由土壤质地决定的可利用持水量(AWC)
土壤可利用持水量为由土壤质地特点决定的可存贮在土壤中并能被植被所利用的水量,它是土壤的一种固有物理属性,是衡量排水良好的土壤对植被供水能力的可靠指标,对干旱信息的提取具有重要意义[21−23]。其简化计算式为[24]
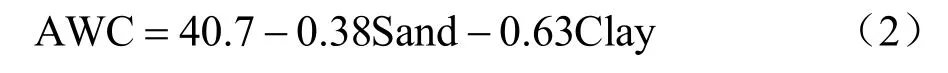
式中,Sand 为土壤沙粒含量(%),Clay 为土壤黏粒含量(%)。
利用式(2)估算京津冀地区逐像元空间分辨率为1km 的AWC 分布,结果如图2 所示。

图2 由土壤质地决定的可利用持水量(AWC)分布Fig.2 The distribution of Available Water Capacity(AWC)based on soil texture in the Beijing-Tianjin-Hebei region
1.3.3 DEM 数据归一化
为保证输入模型的数据质量,以22 个气象站点的经纬度为中心像元,向外扩展8 个像元,并从DEM数据中求取中心像元所在位置周围3×3 个像元的平均值作为该站点的参量值。由于京津冀地区地形起伏较大,需要对提取出来的DEM 数据进行归一化处理后作为模型的输入变量,计算式为

式中,X 为交互式数据语言(Interactive Data Language,IDL)根据各气象站点所在经纬度提取出来的高程(DEM)值,Xmin和Xmax分别为DEM 最小值和最大值,Y 为经过归一化处理的DEM 值。
1.3.4 SPEI 的计算
根据京津冀22 个气象站点的降水和气温数据,计算2007−2017年各站点的SPEI,将其一个月尺度的SPEI-1 作为综合干旱评估模型的目标变量来训练模型,其具体计算方式见文献[25]。SPEI 的计算步骤为
(1)采用 Thormthwaite 公式计算潜在蒸散(PET),即

式中,B 为根据气象站点纬度计算的修正系数;Ti为月平均温度;H 为年热量指数;A 为以H 为基础的系数。
(2)计算逐月降水与蒸散的差值Δ。

式中,Pi为逐月降水量;PETi为月潜在蒸散发量(mm)。
(3)采用带有三个参数的log-logistic 概率分布来拟合所构建的数据序列Δ。
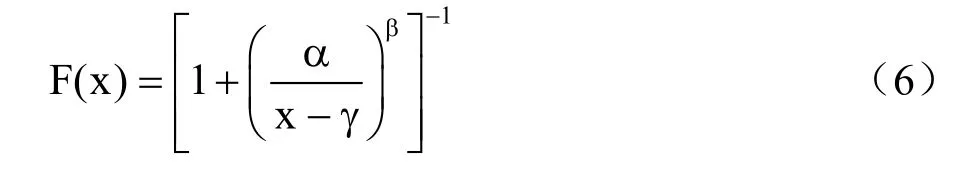
其中,α,β ,γ 采用文献[26]的L−矩估计方法获得。
(4)对累积概率密度进行标准化,获得相应的SPEI 值。

当累积概率P≤0.5 时,则

当P>0.5 时,P 取值为1−P,即

式中,a0=2.515517;a1=0.802853;a2=0.010328;b0=1.432788;b1=0.189269;b2=0.001308。
1.4 模型验证方法
从气象干旱、农业干旱和典型干旱事件空间分布三个方面对综合干旱评估模型进行验证。首先根据京津冀气象站点的逐月降水数据计算一个月尺度的SPI-1,SPI 的计算过程与SPEI 类似,其具体计算方法见文献[25]。将计算出来的SPI-1 与综合干旱评估模型输出的CDI 指数按月进行验证,以表征模型具有一定的气象干旱信息获取能力;将能够反映农作物生长状况的10cm深度土壤相对湿度与CDI按站点进行验证,以表征模型对区域农业干旱评估的适用性。最后将CDI 计算出京津冀地区2016年3−7月的典型干旱事件结果与实际情况相比较,从空间上对综合干旱评估模型进行验证。
2 结果与分析
2.1 深度学习算法综合干旱评估模型的构建
2.1.1 建模原理
构建综合干旱评估模型需考虑多种致灾因子,因为干旱不仅与土壤水分胁迫、植被生长状况有关,还与地貌类型、可用含水量和地表温度状况有密切关联[27]。分别采用标准化植被距平指数、标准化降水距平指数和标准化地表温度距平指数来代表植被异常信息、降水异常信息和地表温度异常信息,将AWC 作为土壤水分胁迫因素,用归一化的DEM 数据作为地形影响因子,最后采用1 个月尺度的SPEI-1来代表气象影响因子,并作为模型的因变量与前面的多种干旱影响因素一起输入模型,参与综合干旱评估模型构建(图3)。

图3 深层神经网络结构Fig.3 Structure of deep neural network
2.1.2 建模流程
将标准化处理后的归一化植被指数(NDVI)、降水和地表温度的距平值、土壤可利用持水量和DEM 数据,以京津冀22 个气象站点的经纬度为中心,利用IDL编程语言将站点的经纬度信息转换成相应的行列号信息,以站点所在的像元为中心向外扩展8 个像元,并求取站点所在位置周围3×3 个像元的平均值作为该站点的参量值,构成输入模型的自变量数据。同时将根据气象站点计算出的一个月尺度SPEI-1 作为因变量,与自变量数据一起输入模型,构建综合干旱评估模型(CDI)。模型具体构建过程见图4。

图4 综合干旱评估模型(CDI)构建流程Fig.4 Flowchart for constructing the comprehensive drought evaluation model(CDI)
因为京津冀地区在不同季节的降水量、植被生长状态以及干旱状况差异较大,鉴于此,按月份构造模型,将按不同月份构造好的数据集划分成训练数据集和测试数据集。将2007−2016年的数据集作为训练数据集,2017年的数据作为测试集。深度学习是Hinton 等[28]提出的一种基于机器学习的方法,其性能优于其它机器学习方法[29],该算法在构建干旱监测模型时可以从大量的干旱因子中提取更多有用的信息。利用基于 Python 语言的 TF(Tensorflow)框架来搭建京津冀地区的综合干旱监测模型。该框架是一种基于数据流程图进行数值计算的开源软件库,节点一般用来施加数学操作,线表示节点之间的输入/输出关系[30],模型搭建的详细参数见表2。

表2 综合干旱评估模型构建参数Table 2 Construction parameters of comprehensive drought evaluation model
模型网络层类型为全连接层,网络层数定为4层,模型结构主要分为3 部分,分别为输入层、隐藏层和输出层,同时为防止模型出现过拟合,在模型输入和隐藏层之间加入了Dropout 层,其工作原理见图5。该层在模型训练时,通过随机舍弃一些节点,由此抑制节点之间的协同适应性,使得网络获得较好的泛化性能,是公认的解决过拟合问题的有效方式[31]。

图5 Dropout 层算法示意Fig.5 Dropout schematic
在模型构建中,采用Adam 作为梯度更新的优化算法,Adam 是2015年由Diederik 等提出的一种优化算法,它结合了Momentum 和AdaGrad 等算法的优点,是近年来深度学习领域中最常用的优化算法之一[32]。用均方根误差(Root Mean Square Error,RMSE)作为模型的损失函数来反映目标值与模型输出值的差值。模型中的迭代次数(Epochs)选为1000,模型指标(Metrics)也采用RMSE 来监视模型在测试集的表现。为了提高模型的泛化能力,在模型每个网络层之间加入了非线性的LeakyRelu 激活函数[33]。学习率是模型构建过程中一个重要的超参数,它决定了模型参数梯度更新的速率,其选取的结果直接影响模型的性能,经过多次实验,最终将学习率取值为10−4。
将划分好的训练集输入综合干旱评估模型中对模型进行训练,其基本过程为将训练样本经过输入层的神经单元输入到网络模型,再经过隐藏层神经单元的处理将信息传递给输出层,从而完成一次前向传播过程,得到输出值(CDI),将输出值与目标值进行比较得到误差,当两者误差没有达到要求时,通过模型设定好的Adam 更新算法,将误差从输出层反向一层层传播到输入层,并在此过程不断修正各层网络神经元之间的连接权值,从而使模型的输出与目标值的误差减小,进而完成一次梯度更新。基于上述原理,通过对信息在经过不断的正向和反向传播时进行梯度更新的反复训练,使模型的输出结果不断向目标值靠近,当达到设定好的误差阈值或训练次数时,模型即停止训练,完成模型训练过程。最后利用训练好的模型输入预测数据集得到输出值及CDI 指数。
2.1.3 模型的测试
采用均方根误差(RMSE)和决定系数(R2)作为模型精度评定标准,在不同月份上对模型在预测数据集和测试集的表现进行评估。其中RMSE 和R2的详细计算方法见文献[34],模型测试结果见表3。由表可知,模型在不同月份上的训练集和测试集R2均大于0.5,且训练集和测试集RMSE 相差都较小,说明模型不同月份上的测试表现均较好。其中在11月的表现最优,该月训练集与测试集的RMSE 在所有月份中最小,最小值分别为0.14 和0.25,两者差值也较小,为0.11,说明模型在11月份表现稳定。训练集和测试集的R2在11月份最高,最高值分别达到0.92 和0.89。
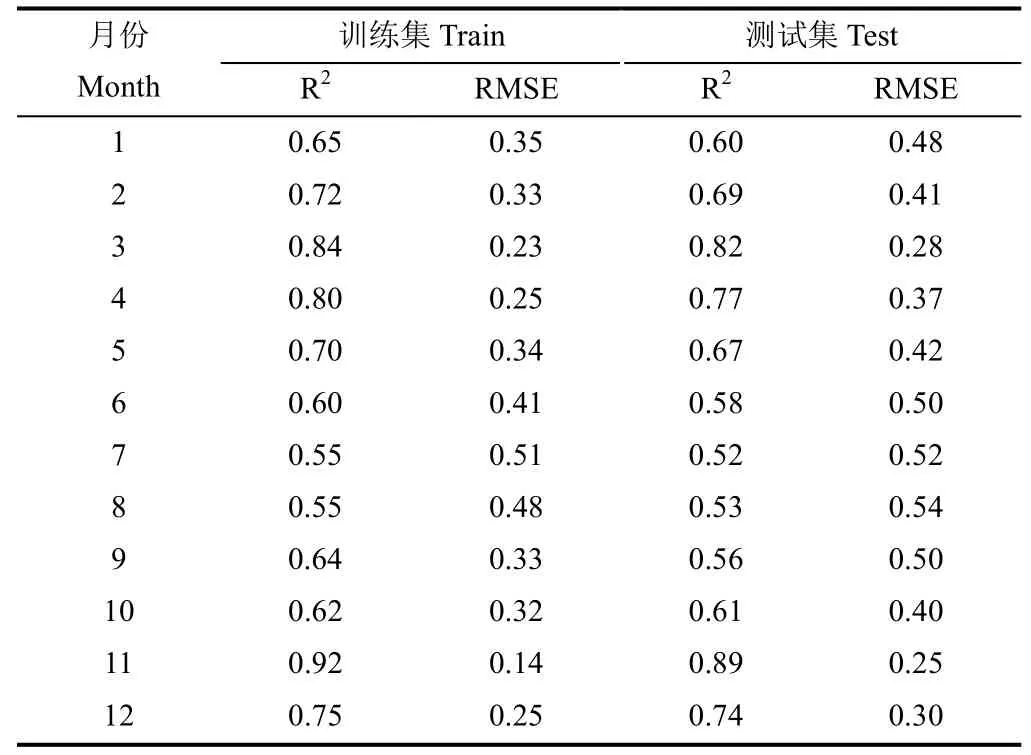
表3 综合干旱评估模型测试结果Table 3 Test results of comprehensive drought evaluation model
2.2 综合干旱评估模型的模拟效果
2.2.1 CDI 与气象干旱指数的相关分析
基于密云气象站统计2007−2017年月尺度的SPI-1、SPEI-1 和模型输出的月尺度CDI 值,由图6可知,2007−2017年月尺度CDI 与SPEI-1 和SPI-1较为接近,变化趋势基本一致,并且在京津冀地区,SPI、SPEI 已被证明是能够有效准确地评估和监测干旱的气象干旱指数[35],因此,认为CDI 是评估和反映该地区干旱的有效指标。

图6 2007−2017年密云站上本模型输出的月综合干旱指数CDI 与月标准化降水指数SPI-1(1 个月尺度)、月标准化降水蒸散发指数SPEI-1(1 个月尺度)的比较Fig.6 Comparisons of comprehensive drought index(CDI)output from this model with one-month scale standardized precipitation index(SPI-1)and one-month scale standardized precipitation evapotranspiration index(SPEI-1)in Miyun site during 2007−2017
以模型输出的2007−2017年逐月综合干旱指数(CDI),与同期月尺度标准化降水指数(SPI-1)进行相关性分析,结果见图7。由图可见,2007−2017年各月CDI 与SPI-1 均呈现极显著正相关关系,相关系数均在0.7 以上,其中7月相关系数最小(0.70),11月最大(0.93)。据调查,研究区主要种植作物为冬小麦和夏玉米,两种作物的生育期分别为11月−翌年6月和7−10月,而模型获得的CDI 指数与这些粮食作物生长期内的气象干旱指数SPI-1 具有显著的正相关性,说明CDI 指数在气象干旱的评估中具有良好的潜力。
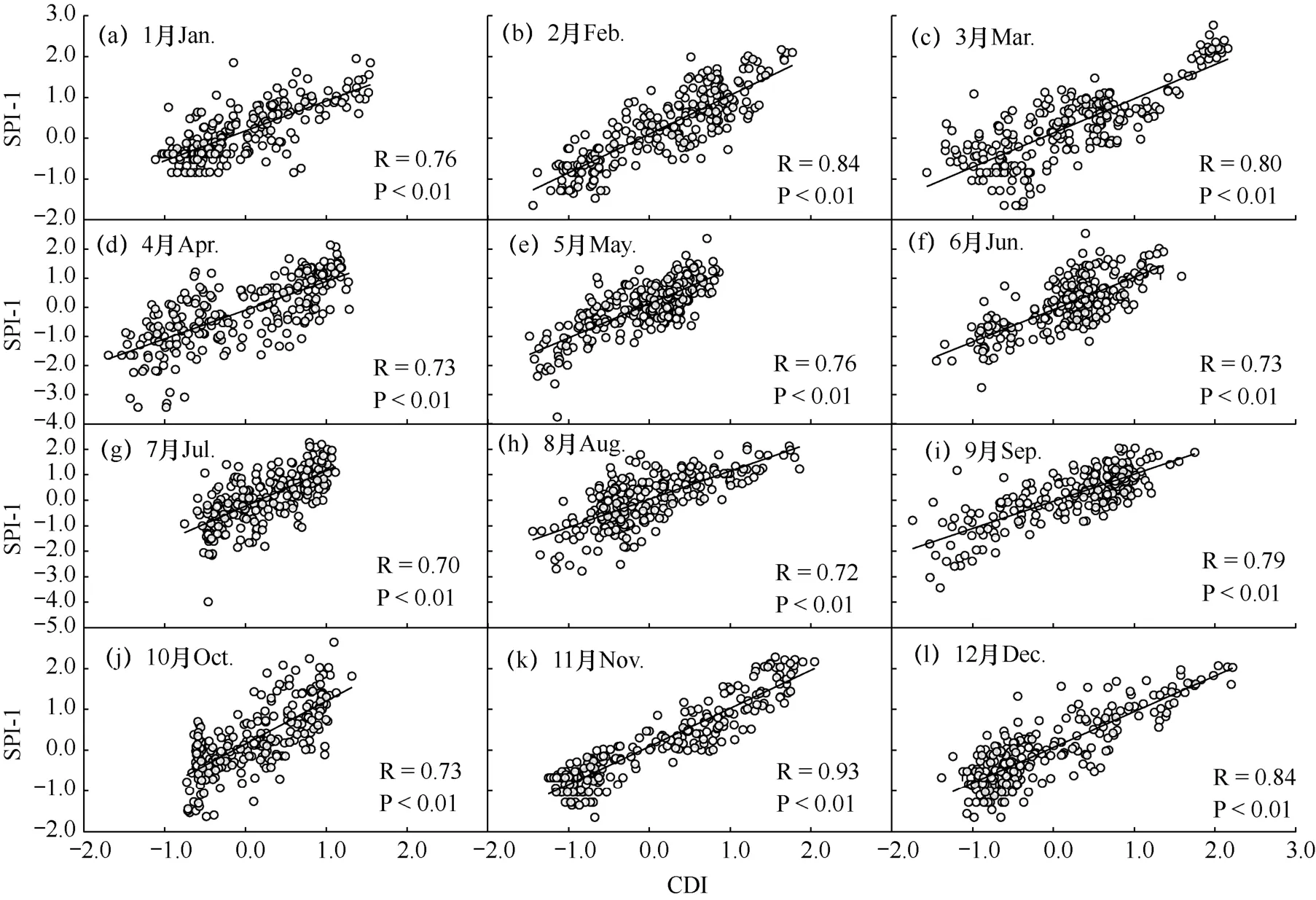
图7 2007−2017年各月标准化降水指数(SPI-1)与模型输出的综合干旱指数(CDI)散点图Fig.7 Scatter plot of SPI-1 vs. CDI for each month from 2007 to 2017
2.2.2 CDI 与土壤相对湿度的相关性
在研究区内选取9 个分布均匀且时序较长的土壤湿度站点,对综合干旱评估模型的可靠性进行验证。将站点2007−2013年3−11月逐月10cm 深度的土壤相对湿度数据与模型输出的逐月CDI 指数按站点进行相关分析,结果如图8 所示。由图可见,各站点 CDI 与土壤湿度均成极显著正相关关系(P<0.01),相关系数在0.44~0.62,其中蔚县和南宫站相关系数最大(0.62),霸州站相关系数最小(0.44),表明构建的CDI 与10cm 深度土壤相对湿度具有良好的相关性,能够较好地反映土壤水分的变化。土壤水分是农业干旱的决定性因素[36],因此CDI对农业干旱具有一定的评估能力。
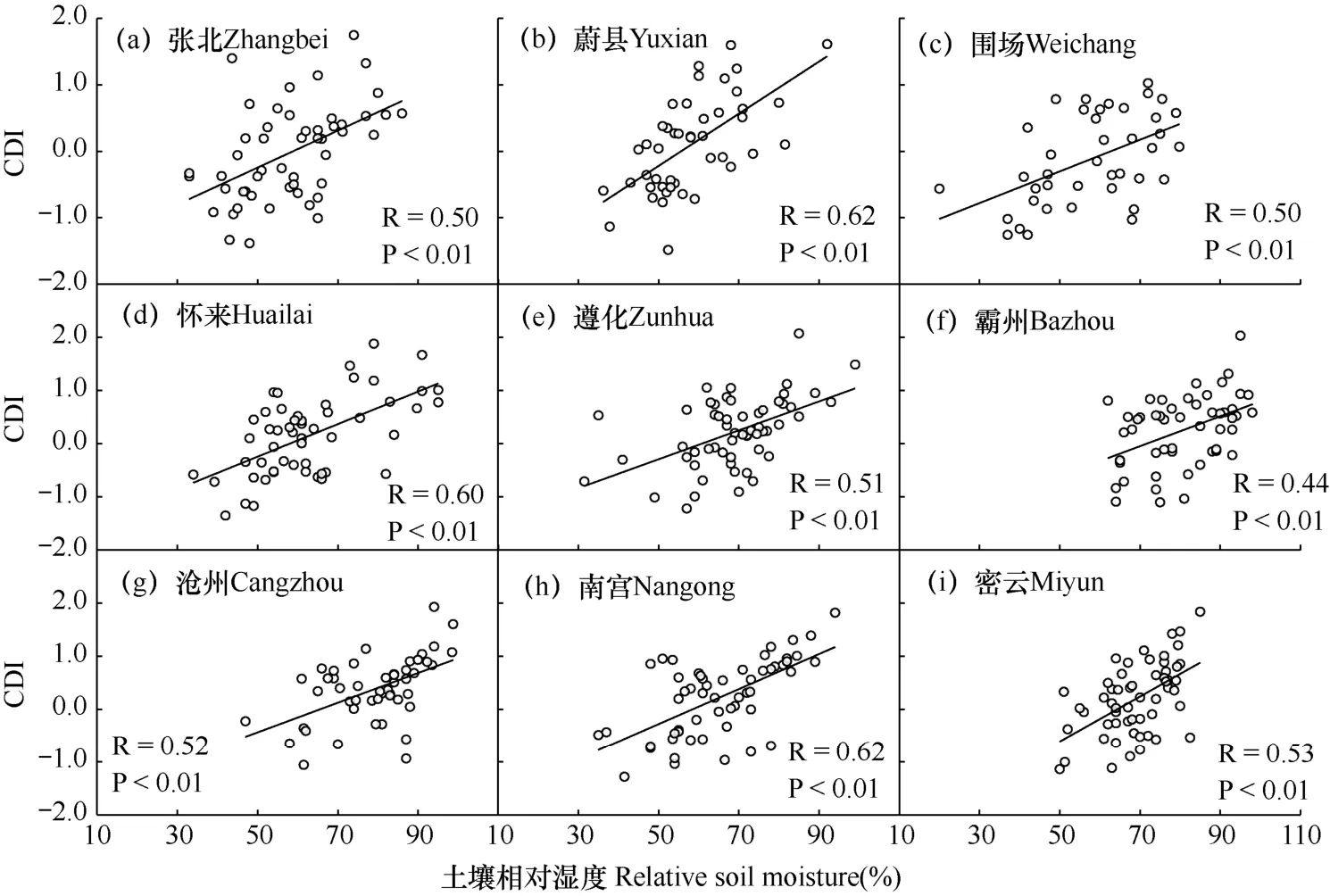
图8 各土壤湿度验证台站上模型输出的综合干旱指数(CDI)与10cm 深度土壤相对湿度间散点图Fig.8 Scatter diagrams of CDI output from the model vs.the relative soil moisture at 10cm depth in each soil moisture verification sites
2.2.3 典型干旱年份旱情发展空间分布验证
为进一步验证CDI 在空间上的合理性,选取典型干旱年份分析京津冀地区干旱的空间分布特征。参照刘高鸣等[19]关于SPI、SPEI 等级划分标准,将CDI 指数模型划分为5 个等级,具体如表4 所示。

表4 CDI 干旱等级划分Table 4 CDI classification of drought levels
据2016年《河北省气候公报》和《中国气象灾害年鉴》对京津冀地区干旱灾害描述可知,2016年京津冀地区平均温度比常年较高且发生过阶段性干旱,春旱尤为严重。从3月中下旬开始,气象干旱范围不断扩大,进入4月态势加重,干旱开始向西南方向蔓延,东部地区出现中等以上干旱。5月初,研究区北部出现过一次大范围降水,旱情得到缓解,但中南部旱情持续发展,其中邯郸、衡水、保定和张家口等地区还存在轻中程度气象干旱。进入6−7月,研究区遭受大范围暴雨侵袭,其中河北省更是出现了“7.19”特大暴雨,大范围降水使得旱情进一步得到缓解,至7月下旬京津冀地区旱情全面解除。
将研究区2016年3−7月作为典型干旱事件,对CDI 的空间分布进行验证。图9 显示,SPEI 与CDI对研究区2016年3−7月发生的干旱的评估结果基本一致,其中在3月和5月评估结果稍有差别。对于3月,SPEI 将张家口市的东南部、保定市的北部和承德市的大部分区域都评估为重旱,而CDI 将这些区域评估为中旱,据河北省气候公报对干旱描述,河北省在3月大部分区域处于中旱,进入3月末和4月初气象干旱的发生范围和情况才逐渐加剧,因此SPEI 对这些区域旱情存在高估的情况。至于5月,CDI 在张家口市和唐山市评估出SPEI 未评估出的旱情,而据河北省气候公告记载,虽然5月研究区北部旱情得到了极大缓解,但在5月底唐山市大部分地区和张家口仍存在轻中程度气象干旱。因此,可以得出CDI 对研究区干旱的空间分布情况评估效果更好。
统计CDI 在2016年3−7月对研究区旱地受灾的评估情况,由表5 并结合图9 可知,3月京津冀地区67.31%的面积处于中等程度干旱,其中研究区东部部分地区呈现重旱以及特旱,重特旱面积占比达到26.72%。4月气象干旱态势加重,开始向西南方向蔓延,京津冀地区重度等级干旱占比达50.18%,仅研究区北部地区张家口和承德市大部分面积为中度干旱,中旱面积占比达到49.74%。进入5月,研究区旱情得到极大缓解,京津冀北部地区旱情已基本解除,但西南部分地区的干旱还在持续发展,张家口、邢台、邯郸等地还存在着轻度等级干旱,受旱比例为44%左右。6月,京津冀地区旱情基本解除,研究区受旱面积比例仅10%左右。7月,京津冀受旱面积占比仅2%左右,旱情已全面解除。CDI 对此次旱情的空间分布和发展过程评估结果与实际情况基本一致,因此,CDI 可以较好地对研究区的典型干旱事件进行有效评估。
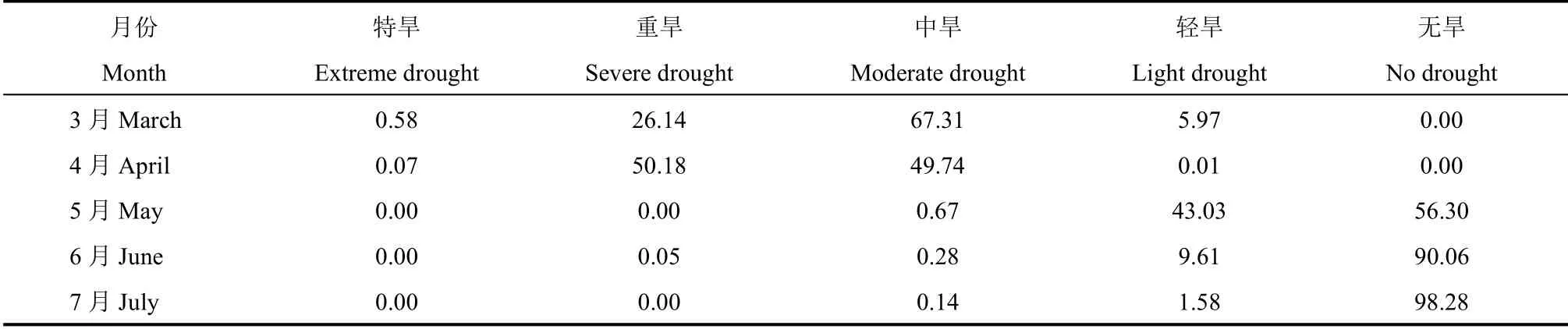
表5 图9 中基于CDI 评估的不同等级干旱面积百分比统计结果(%)Table 5 Statistic results of percentage of different grades dry areas by using CDI in Fig.9(%)
3 结论与讨论
3.1 结论
(1)基于标准化降水、地表温度、归一化植被距平指数、DEM 地形因子、土壤可用含水量AWC 和气象干旱指数SPEI 等多源数据作为输入因子,考虑到各因子之间的非线性关系,利用深度学习框架Tensorflow 对京津冀地区2007−2017年按月构建综合干旱评估模型,并输出月尺度的综合干旱指数CDI。
(2)密云站2007−2017年逐月CDI 与月尺度的SPEI-1、SPI-1 较为接近,变化趋势基本一致,京津冀2007−2017年各月CDI 与同期SPI-1 的相关系数在0.70~0.93,均通过了0.01 水平显著性检验,具有较好的气象干旱评估潜力。
(3)9 个土壤湿度站点2007−2013年各月CDI与逐月10cm 土壤湿度的相关系数在0.44~0.62,均通过了0.01 水平的显著性检验,最高值出现在蔚县和南宫站(0.62),最低值在霸州站(0.44),表明CDI可以表征农业干旱情况。
(4)典型年份干旱空间分布验证表明,CDI 相比SPEI 对京津冀2016年3−7月干旱空间分布情况评估更为准确,并且CDI 能较为准确地评估研究区2016年春旱的开始、发展及结束过程。
3.2 讨论
综合干旱评估指数(CDI)与土壤相对湿度验证结果相关性略低于气象干旱指数,可能原因为模型输出的CDI 的空间分辨率为1km,而在此空间尺度上,土壤湿度的空间异质性通常大于降水,导致站点提供的土壤相对湿度无法完全替代1km 像素尺度下的土壤湿度,这在一定程度下削弱了土壤湿度验证结果的相关性;此外人为因素的影响(如在干旱条件下对农田进行灌溉)会造成土壤相对湿度的波动,降低利用土壤相对湿度进行干旱模型验证的可靠性[37]。CDI 对京津冀地区2016年春旱的空间分布情况及旱情发展过程进行了评估,其评估结果与余灏哲等[13]对于京津冀2016年春旱的干旱监测结果基本一致。
虽然本研究基于深度学习的方法,利用多源数据构建出能够较好评估京津冀地区干旱事件的综合干旱评估模型,但仍存在一定局限性。首先长时序较高精度的土壤湿度数据难以获得,本研究获取的站点土壤湿度数据截止时间为2013年,且存在数据缺失的现象,这会对利用土壤湿度数据对模型精度验证的可靠性产生一定影响。其次构建的综合干旱评估模型时间尺度为月,难以反映前期降水和土壤墒情对干旱发展的影响,不具备实时评估监测的能力。最后,干旱对农作物和植被具有时滞性[38],这对干旱的评估具有一定的影响,而模型构建时缺少植被时滞信息。因此,下一步研究应考虑干旱的时滞效应,构建旬尺度等时空尺度更为精细的综合干旱评估模型,以期对干旱能够更为准确地评估。
