基于Capsule Network的数学简答题自动反馈
2021-09-15姚淑佳谭红叶段庆龙
姚淑佳 谭红叶 李 茹 卢 宇 段庆龙
1(山西大学计算机与信息技术学院 山西 太原 030006)
2(北京师范大学未来教育高精尖创新中心 北京 100875)
3(北京师范大学教育技术学院 北京 100875)
0 引 言
自动批阅(Automatic Marking)是指根据参考答案、题目考察点等对学生答案进行自动评分和自动反馈[1],其中自动评分(Automatic Grading)[2]是指根据专家提供的参考答案预测学生答案的分数,目前已经有了较为成熟的研究成果并投入使用。但是在应用中发现,同一个得分错误类型可能不同。例如:同样都是0分,可能是与题目完全无关的答案,也可能是看出了考察点但并没有回答正确。对于这种情况,需要给出更为具体的信息来辅助学习,因此需要提供反馈。
反馈本身是一件很耗费时间的工作,教师在进行反馈的时候需要先判断学生的错误属于什么类型,再根据不同的类型给出不同的意见和建议。对于老师而言,通常需要对几百甚至上千份学生答案进行反馈,耗时耗力,而且存在学生答案错误类别相似,但仍然需要重复给出相似反馈的情况。对于学生而言,由于老师反馈所需要的时间较长,因此学生并不能收到即时反馈[3]。自动反馈[4](Automatic Feedback)为了有效减少老师的工作量,提供即时反馈,提高学生的学习效率。但是不同科目、不同题型的反馈重点不同,例如:英文一般关注时态,短语搭配等;语文一般更注重语义一致,语句通顺等问题。
本文主要研究数学简答题自动反馈,数学简答题是指有阅读材料描述,答案为数学概念的题目,图1所示为一个题目和答案举例。

图1 数学简答题题目及答案举例
本文构建的数据集具有以下特点:(1) 数据量较小。本文所使用的数据来源于真实考试中的学生答案,因此数据量有限,每道题大概有4 000条左右的数据并且有一定的重复率。(2) 答案的类型有限。通过对学生答案的分析将其分为完全正确、概念描述错误、概念不适合这道题目和答案完全错误四类。(3) 答案类型易混淆。例如“同旁内角互余,两直线平行”和“同旁内角互补,两直线平行”只差一个字,但分别属于上述最后两类答案,传统的分类模型很难正确地将其进行分类。此外,在进行自动反馈之前,本文还为每个类型的学生答案定义了一个反馈模板,但是为了使模板具有针对性,模板中的一部分内容是需要通过相似度计算进行填充的,具体如表1所示。

表1 答案类型及反馈模板
本文提出一种分两步进行的数学简答题自动反馈方法,第一步确定学生答案类型,第二步通过相似度计算填充对应的反馈模板。本文使用基于静态路由的胶囊网络用于确定答案类型。Capsule network是2017年Hunter提出的一种方法,用神经元向量代替传统神经网络的单个神经元节点,以动态路由的方式去训练这种全新的神经网络。与传统的卷积神经网络相比,其具有以下特点:(1) 传统分类模型输出类别,但是Capsule network输出的是向量;(2) CNN要得到比较好的结果需要大量的训练数据,而Capsule network因为在胶囊内部进行特征学习,因此较少的数据就能得到更好的结果;(3) CNN池化会丢失一些信息,而每个capsule的都会携带大量的信息;(4) capsule间的传递和运算更符合人脑的思考形式。本文将胶囊层间的连接方式改为静态路由,与动态路由相比,降低了计算的复杂度,提高结果精度,更适合文本分类。
确定答案类型之后,每个类型对应一个反馈模板,但是反馈模板中的一部分内容是需要填充的。因此通过相似度计算对模板进行填充。通过上述方法在已构建数据集上可以达到83.3%以上的正确率。
1 相关工作
Page[5]早在1966年就已经开始进行自动批阅相关研究,但早期的自动批阅主要是使用规则的方法为学生提供一个合理的分数。如Bachman等[6]提出WebLAS方法,根据答案自动生成正则表达式,每个正则表达式与一个分数相关联,因此当学生答案与表达式相匹配就会给出该答案的分数。但是基于规则的方法由于规则表达的有限性,泛化能力较差,随着机器学习的发展,人们开始用文本分类或回归模型来预测分数。Sultan等[7]使用文本相似度、词项权重等特征构建了随机森林分类器,在SemEval-2013评测数据集SCIENTSBANK上进行测试,F1值达到55%。近年来,由于深度学习方法在许多任务上已经达到了最先进的水平,研究人员开始使用词向量和深度神经网络进行评分研究。如Riordan等[8]使用CNN-LSTM构成的神经网络进行自动评分,获得的效果比非神经网络方法好。随着评分技术的日渐成熟,人们发现如果只是给出分数并不能让学生很清楚地认识到自己的不足之处,无法达到智能批阅的真正目的,因此人们开始尝试研究自动反馈。
在自动反馈研究初期,Marvaniya等[9]提出了一种针对于英语填空的自动反馈方法。对于每个空,由老师提前预测每个空的所有可能错误答案,例如动词时态变化、名词单复数形式的变化、短语的固定搭配等。对于预测的每一个答案教师都给出了一个反馈,通过计算学生答案和所有预测答案的相似度,找出和学生答案相似度最高的预测答案,将相对应的反馈提供给学生。通过该方法有效地减少了老师对相似答案重复提供类似反馈的工作量。但是并不是所有题目都可以预测到所有错误类型,而且这项工作需要老师有丰富的教学经验。因此,Brooks等[10]对于从慕课网上收集的学生答案进行度量聚类,老师对于每一类聚类结果给出反馈,使得老师的工作量由几百甚至几千降到几十。但是聚类方法的准确性不高。Zhang等[11]提出了一种基于深度学习+聚类+学生建模的方法,追踪学生的学习轨迹为学生提供反馈。这个方法需要大量的学生学习数据,并不是很容易实现。同时,Dzikovska等[12]提出将答案按照错误类型分类而不是分数,将答案分为正确、部分正确、非领域、不相关、矛盾五类,为本文的反馈提供了思路。
文献[13]发表后,关于胶囊网络的研究受到了许多关注。Afshar等[14]将胶囊网络用于肿瘤图片的分类,通过改变capsule的特征层数来提高精度。Du等[15]提出一种新的基于胶囊的混合神经网络用于情感分类。阿里研究发现胶囊网络应用到投诉文本模型上的整体表现优于原先TextCNN[16]。Zhao等[17]将基于动态路由的胶囊网络用于文本分类任务,在六个经典文本分类数据集上进行实验,其中四个都取得了当前最好的结果。
2 方法设计
本文提出一种分两步进行的数学简答题自动反馈方法。第一步是对学生答案类型进行建模,给定学生答案,通过基于静态路由的胶囊网络判断学生答案类型。该模型的最大的特点是以胶囊的形式进行特征传递,能更好地保留文本内部信息,在小数据集上得到精度更高的分类结果。第二步是通过计算学生答案和正确概念的相似度确定概念属性,将概念属性填充到反馈模版中。这一步的优点是可以较为准确地预测答案类型,同时提供的反馈与学生答案紧密相关。
2.1 基于静态路由的胶囊网络确定答案类型
本文采用一种基于静态路由的胶囊网络确定答案类型,模型架构示意图如图2所示,由输入层、N-gram卷积层、初级胶囊层、卷积胶囊层、全连接胶囊层、输出层六层构成。胶囊能够表示局部实体的属性,并用向量而不是标量来表达语义。

图2 胶囊网络模型架构示意图
模型的输入层是学生答案S∈RL×V,L代表句子长度,V代表词向量维度。
第二层是N-gram卷积层。在这一层用B个大小相同、权重不同的滤波器Wa∈RK×V抽取低级特征,每个滤波器都会生成一个神经元ma∈RL-K+1,这个神经元中的每一个元素按式(1)进行计算。
(1)
式中:Xi:i+K-1代表第i到i+K-1个词的词向量;Wa为宽度K、长度为V的滤波器,目的是在不同位置抽取特征;*代表单元乘法;f为激活函数(本文采用sigmod函数);b代表偏置。对于a=1,2,…,B,一共有B个拥有相同的N-gram尺寸的滤波器,可以生成B个特征映射,如下所示:
M=[m1,m2,…,mB]∈R(L-K+1)×B
(2)
下一层是初级胶囊层,pi∈Rd代表一个胶囊,d代表胶囊的大小。由mi∈RB作为输入,Wb∈RB×d是不同窗口共享的滤波器。窗口的滑动步幅为1,则会产生C个(L-K+1)×d的胶囊,每一个胶囊pi的计算为:
pi=g(WbMi+b1)
(3)
式中:g是Squashing激活函数;b1是胶囊偏置项。对于所有的C个滤波器,生成的胶囊特征映射可以重新排列:
P=[p1,p2,…,pB]
(4)
激活函数具体如下:
(5)
激活函数g既保留了向量的大小,也将向量的模长控制在[0,1)之间。
第四层卷积胶囊层,这一层会自动学习“部分-整体”关系,也就是由低级特征(子胶囊)ui预测高级特征uj|i(父胶囊),如式(6)所示。
(6)

下一层是全连接胶囊层,卷积胶囊层的胶囊被放入了一个胶囊列表中,并输入到全连接的胶囊层中,胶囊与胶囊乘以变换矩阵Wd∈RE×d×d,通过路由协议产生最终的胶囊vj∈Rd及其概率aj∈R。
接下来通过比较胶囊层间的不同的连接方式选出适合文本分类的连接方式。
2.1.1动态路由
Sabour等[13]指出,胶囊网络通过动态路由过程更新耦合系数cij的权重,并确定低级特征和高级特征之间的匹配程度。耦合系数由正确高级特征和预测的高级特征的的相似度决定,计算式如下:
(7)
式中:i∈[1,a];j∈[1,k];k代表总的类别数;bij是由子胶囊和父胶囊的相似程度决定的;cij在每次迭代过程都会根据bj|i进行更新。具体如算法1所示。
算法1动态路由算法
procedureROUTING(uj|i,aj|i,r,l)
初始化耦合系数的logits
bj|i=0
forriterationsdo
for all capsuleiin layerland capsulejin
layerl+1
cj|i=aj|i·leaky-softmax(bj|i)
for all capsulejin layerl+1:
for all capsuleiin layer l and capsulejin
layerl+1:bj|i=bj|i+uj|i·vj
returnvj,aj
2.1.2静态路由
与基于动态路由的胶囊网络相比,静态路由主要有以下两个优势:(1) 降低了计算复杂度;(2) 提高计算精度。Zhao等[17]首次将胶囊网络用于文本分类时采用的是动态路由的连接方式。这是直接借鉴Hunter在图像上的两个胶囊层之间的连接方式通过静态路由决定,在图像上考虑到实体间的空间结构是合理的,但是在语言中,文字的表达方式有很大不同,因此,本文提出静态路由的方式将子胶囊和父胶囊进行连接:
(8)
2.2 自动反馈
确定答案类型后不同的类型有不同的模板,本文通过相似度计算的方法进行反馈模板填充。在进行反馈模板填充之前,本文人工构建了初中数学概念库,包含了初中阶段所有用到的数学概念184条。概念库中的概念以表2所示的形式存在。概念库构建完成之后,进行模板填充。本文的答案类型包括完全无关、概念错误、概念不适合这道题目、回答正确四类。通过字重叠确定相似度最高的概念,将对应的概念属性填充进模板,完成自动反馈。

表2 概念库举例
3 实 验
3.1 数据集及评价指标
本文所使用的数据集来源于某中学八年级数学试卷的三道数学简答题,每个题目有两个空,每个空的答案数量分别为3 632、3 632、4 290、4 290、4 913、4 913。由于学生答案有一定的重复和空白,因此对数据进行去重之后进行统计,数据集的具体信息如表3所示,其中Math2重复率最高,Math1次之,Math3最低。

表3 数据集统计
本文采用准确率P作为实验评价指标。假定a表示被正确分到某类的文档数,b表示错误分到该类的文档数。则准确率计算如下:
(9)
3.2 实验参数设置
在参数设置上,本文使用Skip-gram训练维度为60维的字向量和词向量,通过对词级别和字级别的句子长度进行统计发现(包括学生答案+参考案),词级别的最大长度为15,字级别为40。因此本文输入为15×60和40×60的矩阵,在N-gram层,采用64个3-gram的卷积层抽取低级特征。胶囊的维度d=6,答案类别设为四类,共享滤波器的窗口维度为2。
3.3 实验结果及分析
3.3.1实验结果
为了说明本文方法的有效性,本文分别采用传统机器学习模型SVM和深度学习模型CNN作为基线模型,同时和最近在各个任务上都表现优异的Bert进行了对比实验。
SVM[15]是一个进行文本分类的经典模型,使用N-gram来提取输入特征,使用SVM作为分类器,得到答案类型的分类结果。
CNN[16]是目前应用范围最广的神经网络模型之一,许多学者利用其解决多种NLP任务并获得很好效果。本文分别使用字级别和词级别的特征作为输入,得到答案类型的分类结果。
Bert[17]是2018年Google提出的通用预训练语模型,目前在许多文本分类任务上都取得了比传统方法更好的结果。
表4列出了基于动态路由的Capsule network(CPN_d)和基于静态路由的Capsule network(CPN_s)和上述模型的对比结果。
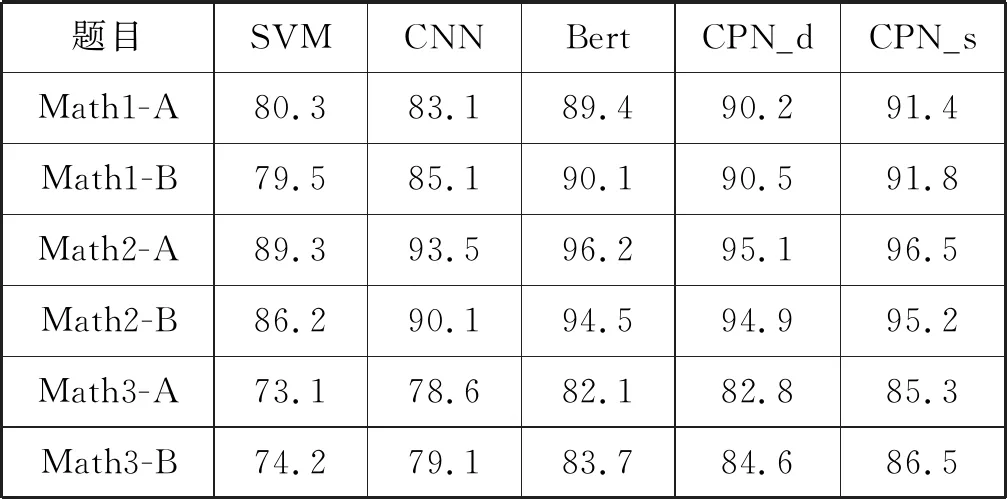
表4 各模型准确率对比(%)
可以看出,CPN_s在三道题上表现均为最优,Bert和CPN_d的实验结果在三道题上的结果都明显高于SVM和CNN,但稍低于CPN_s。在Math1上两种胶囊网络的结果均优于Bert,准确率达到了91.4%和91.8%。在Math2上胶囊网络的准确率为96.5%和95.2%,是三道题里最高的。可能是由于题目难度较低,学生答案重复率较高。在Math3上Bert的表现稍优于CPN_d。实验结果表明在文本分类任务上胶囊形式优于单个的神经元,且静态路由优于动态路由。
3.3.2数据去重
由表3对数据的统计发现数据的重复率较高,通过对题目的分析发现和题目难度呈正相关。本文为了证明模型的有效性在去重数据上重新进行了实验,实验参数与之前一致。实验结果如表5所示。

表5 数据去重后各模型准确率(%)
通过对去重后的实验结果进行分析发现,去重之后三道题的准确率均有大幅下降,在Math2上的准确率下降幅度最大,Math1次之,Math3最小,准确率与数据重复率成正相关。
3.3.3不同级别特征
为了检验不同级别的特征对实验结果的影响,本文使用字向量在CNN和基于静态路由的Capsule network上进行对比实验,具体如图3所示,其中:t(token)代表字级别的特征,w代表词级别的特征。

图3 不同级别特征在CNN和CPN_s上的结果
通过对图3观察发现,不论是CNN还是CPN_s,字级别的实验结果都优于词级别的实验结果。
4 结 语
本文首先构建了数学简答题数据库,然后提出将数学简答题的自动反馈分为两步进行,通过基于静态路由的Capsule network确定答案类别。为了证明该方法的有效性,与SVM、CNN、Bert进行了对比实验。确定答案类型后,不同的类型有不同的模板,本文通过相似度计算的方法进行反馈模板填充。但是该方法的反馈模板需要手动定义,答案类别也并没有细分,因此只能给出较为概括性的反馈。下一步计划通过构建数学概念知识图谱为学生提供更细致的反馈。
