基于Flask和爬虫的书籍循环平台的设计与实现
2021-09-14李岳松郭史进刘浩宇
燕 妮,李岳松,郭史进,刘浩宇
(中国矿业大学(北京)机电与信息工程学院,北京100089)
阅读是人类进步的阶梯,在新时代倡导全民阅读,建设书香社会已经成为一项必不可少的文化战略。随着近些年高校不断扩招,教学需求不断增长以及社会呼吁环保理念,新旧二手书的循环利用已经迫在眉睫。基于此,本次课题基于Python的Flask框架和爬虫技术手段,开发了一款公益性质的书本循环平台,为供需双方搭载了联系的纽带,学生们可以把闲置图书上传到这个平台,也可以在平台构建自己的心愿书单。此次课题让空闲的书本循环再利用,改善了资源的浪费情况,培养了学生们勤俭环保的优秀美德。
1 需求分析与系统设计
1.1 书本循环平台的需求分析
书本循环平台的用户主要分为三大类,包括管理员、登录用户和游客。书本循环平台主要实现了以下功能:登录功能、书本总览功能、详情信息展示功能、赠送清单功能、心愿单功能。登录功能包括注册、登录和注销;书本总览功能在首页展示了一部分图书;详情信息展示功能可以查看到本书的作者、出版年月日和书本简介等信息并另一侧推送相关书目。赠送清单功能展示了用户可以赠送的书本清单,本平台区别于其他平台的地方是不需要拍照上传等复杂工序,而是采用搜索书名或者ISBN编号实现快速录入赠送清单,极大提升了用户的体验;心愿单功能可以列出用户想获得的书本信息,同样采取搜索方式,点亮书本下方的小爱心就可添加至心愿清单。当用户访问平台时可以选择注册登录或者游客身份,游客身份只能看到首页展示的书目总览及登录后可查看自己的可赠送清单和心愿单。系统总用例图如图1所示。
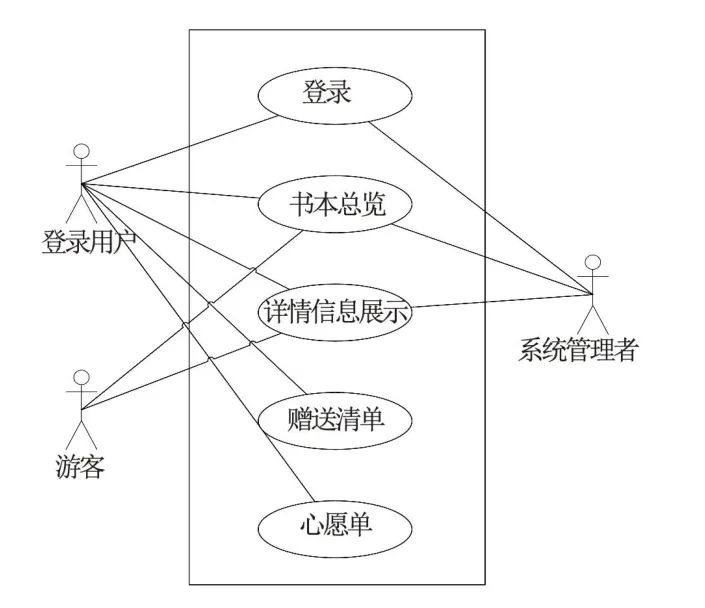
图1 总用例图
1.2 书本循环平台的系统设计
1.2.1 书本循环平台的概要设计
前后端都使用经典的MVC设计模式[1]。MVC模式分离了视图层和模型层,并通过控制层相连接。View层主要负责后台数据的输出、页面的呈现和人机交互工作。Controller层用来处理系统业务,翻译用户输入的信息,并按照用户输入生成操作模型传送给Model层,以此满足用户需求。Model层负责管理行为和数据,行为表示更新来自Controller的状态,数据与数据库相连接,根据请求加载后台数据,完成业务逻辑,对页面进行渲染。
本课题设计的MVC书本循环平台工程目录结构图如图2所示。

图2 书本循环平台工程目录结构图
common文件包括libs和models文件,存放公共使用的函数和类[2];config文件是整个工程不同环境的配置文件,例如基础配置、本地配置和生产环境配置;controllers文件内放置用户登录和书目信息管理代码;interceptors是对运行过程中异常处理的编写;jobs文件夹主要存放爬虫代码,包括定时爬虫和保存从html中获得的信息;static文件是静态文件,包括前端所需的CSS、JS等文件;templates是模板存放文件夹;application对全局变量类管理;manager是入口文件,启动整个工程;requirement.txt说明这个工程所用到的库,方便后期维护和管理;www文件是路由核心文件。本MVC框架符合Web开发的需求和特点,它对项目进行了合理分工,保证各个模块同时启动,互不影响,开发效率显著提高,节约了人力和时间成本。在开发Web项目时,使用MVC框架便于后期运营和维护,方便系统化管理项目[3]。
1.2.2 书本循环平台的数据库设计
数据库设计是后端管理必不可少的一步,好的数据库设计在特定的应用环境里可以起到事半功倍的效果。将有效的数据存储到数据库中,以此满足用户的各项需求。本次课题采用Mysql数据库服务和navicat可视化工具,主要设计了两个表单:登录注册功能需要的user表单和书目管理所用到的book表单。登录注册模块的数据库设计,表名为user。字段包括id序号主键、nickname昵称、login_name登录用户名、login_pwd登录用户密码、login_salt登录密码随机字符串、status状态(0:无效,1:有效)、updated_time最后一次更新时间、creatd_time插入时间。
书目管理系列用到的数据库如表1所示,表名为book。

表1 书目管理系统的数据库
2 系统实现
2.1 书本循环平台的实现环境
书本循环平台的整体框架[4]如图3所示。

图3 书本循环平台整体架构图
Python计算机编程语言自20世纪90年代诞生以来,凭借其简洁、规范、可读性强已经被广泛运用于脚本编写和Web开发等领域[5],Python语言既支持面向对象编程也支持面向过程编程,它不仅有丰富的准库还拥有很多第三方库,这使得开发人员使用Python可以便捷地解决系列融合问题,使互联网产品易于维护和迭代。本次课题主要的编译器是Pycharm,其自带的调试功能、自动整理代码格式、历史提交回滚等功能帮助开发人员提高了开发效率。开发框架选择的是Flask框架,是一个轻量级Web开发框架,功能强大且兼容其他库来实现开发需求,它灵活且可扩展性强[6],Werkzeug和模板引擎Jinja是Flask的核心应用。先将Flask实例化,接受一个name参数,用户在浏览器前端做出指令,发送HTTP请求,将请求传送回服务器,Flask用werkzeug做出路由分发,为每个Url找到对应的视图函数,接着Flask调用视图函数进行相应操作,再将响应结果返回客户端,并将数据渲染到页面上,以此完成一次程序运行。
Nginx是轻量级Web服务器,适用于高并发连接且内存消耗少,可供跨平台多个开发系统使用[7],是本次课题服务器选择方面的不二法门。由于windows系统不支持uwsgi插件,因此需要tornado插件来配合部署高并发架构。在Flask框架中,路由的设置需使用route属性,这种方式是默认使用get请求,如果需要post请求则需要在列表容器methods中特别设定。当项目较大时,需要的视图函数会很多,此时需要使用蓝图Blueprint来区分模块,这样也有利于后期的代码维护。
前端部分采用bootstrap前端开发框架,可使前端开发更加迅速简单。toC比较注重交互,前端采用bootstrap响应式布局,以及骨架图初始化呈现未加载数据页面,响应式布局对页面缩放拖拽特性友好,页面应该有能力去自动响应用户的设备环境,同时会考虑一些不同浏览器之间的兼容性。另一方面使用模版引擎渲染技术,利用正则表达式分解出普通字符串和模板标识符,将模版表达式替换为浏览器语言表达式,模版引擎将数据和页面分离,可以通过变量更新页面,提高代码复用扩展能力,并且可以在页面中写入一些具体逻辑,方便渲染。网页调试工具可以采用chrome插件类产品,可以发送所有类型请求的postman进行接口测试工作。
书籍清单主要依靠爬虫技术和正则表达式获得。一只爬虫可以从目标网页的html中提取开发者的需求内容,以及和网页进行交互。本次课题使用的是BeautifulSoup库,用来解析html,但在代码编写时要注意查看源码的编码方式,加以解码[8]。之后将爬到的数据按标准化格式传递给model业务逻辑层,逻辑层使用正则表达式和第三方库对数据进行清洗与封装,并存储到数据库中。设计好的数据库将用于存储用户的账号密码,并使用md5加密[9]保护用户的隐私性。书单查询、修改和新增等操作也是基于数据库进行的。
2.2 书本循环平台的模块实现
登录模块主要分为注册和登录两部分,点击注册按钮会跳转到注册页面,用户输入信息会判断其完整度和格式标准度,给用户相应的反馈,如图4所示。

图4 注册模态框
书籍总览和书本详情信息数据来源:通过封装的Hook函数以及Ngnix定时任务,从一些开放式网站定时爬取最新的数据,并将其存放到数据库中。整体页面通过模板引擎渲染,当用户访问不同页面时,浏览器会根据请求发送信息到Nginx服务器,并发访问视图函数,将需求信息呈现出来。效果如图5所示。

图5 书籍详情展示效果图
3 总结
本文基于Python的Flask框架,结合爬虫技术设计了一款书籍循环平台,该平台设计美观大方,交互灵活且人性化,代码段内聚性高耦合性低且可读性强,便于后期维护,同时巧妙利用浏览器的cookie机制,改善服务器的负荷压力,提高页面响应性能。平台旨在实现书籍再利用,有效缓解了高校书籍浪费现象,为推动节约型环保社会奉献了一份力量。
