基于Hadoop技术的物联网资产管理系统性能研究
2021-09-13周少珂张振平邵华徐茹茹张瑛
周少珂 张振平 邵华 徐茹茹 张瑛
摘 要:Hadoop技术的两大核心框架设计是HDFS(Hadoop Distribution File System)和MapReduce。HDFS为Hadoop分布式文件存储系统,MapReduce为分布式计算模型。本文以实训室现运行物联网资产管理系统采集并存储的大数据为基础,利用实训室淘汰的老旧计算机搭建成Hadoop完全分布式集群系统,将物联网系统和大数据Hadoop集群系统加以融合创新,对数据进行格式化处理后在真实集群系统平台中进行测试分析。经验证,Hadoop大数据技术架构下的物联网资产管理系统可以高效地管理数据。
关键词:大数据;Hadoop;集群;物联网;资产管理
中图分类号:TP311.1文献标识码:A文章编号:1003-5168(2021)12-0022-04
Research on Performance of IoT Asset Management System
Based on Hadoop Technology
ZHOU Shaoke ZHANG Zhenping SHAO Hua XU Ruru ZHANG Ying
(Information Engineering School, Henan Technical Institute,Zhengzhou Henan 450042)
Abstract: The two core framework designs of Hadoop technology are HDFS (Hadoop Distribution File System) and MapReduce. HDFS is a Hadoop distributed file storage system, and MapReduce is a distributed computing model. In this paper, based on the big data collected and stored by the current running IoT asset management system in the training room, the old computers eliminated from the training room was used to build a Hadoop fully distributed cluster system, the Internet of Things system and the big data Hadoop cluster system were integrated and innovated, after formatting the data, it was tested and analyzed in the real cluster system platform. It has been verified that the IoT asset management system under the Hadoop big data technology framework can efficiently manage data.
Keywords: big data;Hadoop;cluster;Internet of Things;asset management
Hadoop是Apache基金會的开源项目,具有可靠性、可扩展性的分布式计算存储系统。该项目的两个核心框架是HDFS分布式文件系统和MapReduce分布式计算模型[1]。
HDFS具有高容错性,并且经常部署在低廉的硬件上,其组件主要用于解决海量数据的存储问题,主要模式为“一次写入、多次读取”,其处理的对象为离线数据,而非实时性数据[2]。MapReduce组件主要解决数据的计算问题,其运行建立在HDFS的基础上,它能够对海量存储的数据进行统计分析和计算,按照计算要求在大数据平台中输出最终的结果[3]。
随着大数据技术的不断发展,企业使用的Hadoop项目不断革新。目前,常用的Hadoop组件有:HDFS分布式存储、MapReduce分布式技术、Yarn模型、Zookeeper一致性模型、HBase列式数据库、Hive数据仓库等[4]。
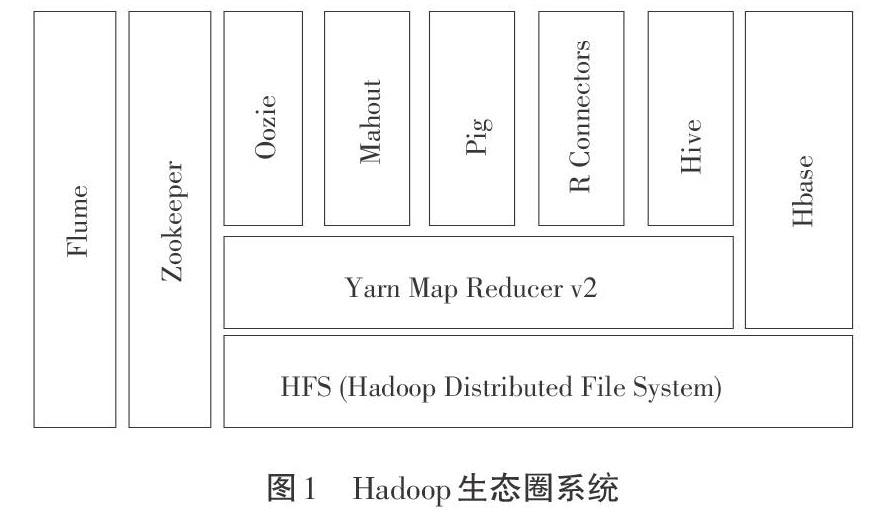
1 Hadoop生态圈系统
2006年2月,Apache Hadoop项目正式启动,经过十几年的发展,从最初的1.X到2.X,再到Hadoop-3.4.X版本,其不断推出新版本。Hadoop源于Google公司开发的GFS、MapReduce和BigTable三款产品[5]。经过不断发展,Hadoop现已有稳定的生态系统,包含各种服务。如图1所示,其最重要的两项服务组件为HDFS和MapReduce[6]。
ZooKeeper组件的功能是高效开发和维护分布式应用协调服务[7];Hive组件是建立在Hadoop体系结构上的数据仓库基础架构,可将结构化的数据文件映射为一张数据库表,并提供完整的查询语言,把SQL语句转化成MapReduce程序提交给Hadoop集群进行处理[8];Hbase组件是一个分布式的面向列的开源数据库,由Google公司发表的论文BigTable演变而来[9];Pig组件是一种大规模数据分析平台,自身提供SQL-Like语言,编译器会把类SQL数据分析请求转化为一系列经过优化处理的MapReduce运算语言[10]。
2 Hadoop分布式集群部署
2.1 Hadoop集群部署
Hadoop分布式集群的部署模式可分为三种:单机版搭建、伪分布式集群搭建、完全分布式集群搭建。如图2所示,本文使用21台淘汰的老旧实训计算机,部署Hadoop-2.7.6版本完全分布式集群,为分析和研究物联网系统采集的大量数据做好环境准备。
原XP系统的实训计算机通过U盘启动模式安装Linux操作系统(CentOS6.5版本),每台计算机的硬盘大小为250 GB,内存大小为2 GB,CPU核数为2核,其间需要对21臺计算机进行操作系统配置。由于Hadoop集群系统需要使用Java环境,因此首先对21台主机分别进行JDK环境变量的配置,JDK环境变量使用1.8(包含)以上版本,系统稳定性较好。本文使用JDK 1.8版本进行配置,如图3所示。
整个分布式集群系统中,1台计算机承担NameNode节点工作任务,1台计算机承担SecondaryNameNode节点工作任务,其余19台计算机承担DataNode节点工作任务。如图4所示,整个集群配置过程中,21台计算机采用同样配置,以保证数据的一致性。
在完全分布式集群部署过程中,系统需要配置6个核心文件。一是hadoop-env.sh文档,环境变量路径要正确导入export JAVA_HOME=$JAVA_HOME;二是core-site.xml文档,服务页面默认的是9000端口号;三是yarn-site.xml文档;四是mapred-site.xml文档,配置MapReduce框架;五是hdfs-site.xml文档,配置存储数据的dfs.replication副本数默认为3;六是Master-Slave文档,最后一项配置文件需要添加所有DataNode数据节点的主机名。
配置6个核心文件后,人们需要对整个Hadoop集群系统进行格式化,其间仅对NameNode节点下达 bin/hadoop namenode -format命令即可。此时还需要使用Service iptables stop命令关闭防火墙功能,使系统服务组件不受防火墙的影响。最后使用start-all.sh命令启动集群。
2.2 Hadoop集群测试
系统集群成功配置后,人们可以使用两种方式对该集群进行测试。一是系统命令方式:使用JPS、hadoop fs–ls/、hdfs dfs–put等本地系统文件路径和分布式系统文件路径的命令,如图5所示。二是图形界面方式:在谷歌浏览器中输入http://hadoop01:50070,进入HDFS分布式存储组件服务;输入http://hadoop01:8088,进入MapReduce分布式计算组件服务,如图6所示。
本文通过后台系统hadoop fs–mkdir/a命令,在该分布式集群根目录下创建/a目录,如图7所示。
3 Hadoop数据测试
智慧化资产管理的实训机房中,各实训室和中心服务机房均有物联网系统对监控设备进行不间断的数据采集、存储和日志记录,一旦出现问题,就可以随时查找日志和数据。面对大量数据,管理员在总结和查找问题数据时耗费大量时间,而且数据的内在规律性和精准度有待提高。
鉴于此,研究人员对河南应用技术职业学院实训室淘汰的老旧计算机进行集群部署,将该集群各IP地址与物联网资产管理系统服务器纳入同一网络,其通过同一接口成功接入物联网资产管理系统,如图8所示。物联网实时采集数据(数据格式有.txt、.csv、.xlsx)并将其存储到HDFS文件系统中,若数据量以MB(或更大单位)为单位,则建议使用.csv文档格式。
研究基于Hadoop技术的物联网资产管理系统时,要选定系统采集并存储的相同数据,使用控制变量法进行对比研究。针对物联网采集的相同数据(如1.1 GB大小数据,40 000 000行),使用基于PC(个人计算机)的传统数据分析软件和Hadoop分布式集群系统,读取数据行数,记录行读取的平均时间(不考虑程序优化给时间带来的影响),其性能分析结果如表1所示。
根据表1分析结果,使用传统数据分析软件读取大量数据时,由于硬件的限制,计算机容易出现卡顿和宕机现象,而且数据读取需要耗费大量时间;使用Hadoop分布式集群系统读取数据时,受内部工作机制的影响,其读取数据的耗时较短,整个过程没有出现卡顿和宕机的现象。
上文基于大量相同数据(以GB为单位)进行了对比研究,鉴于此,有必要单独对两种方式进行详细研究,并多次重复相同试验步骤,取其平均值。
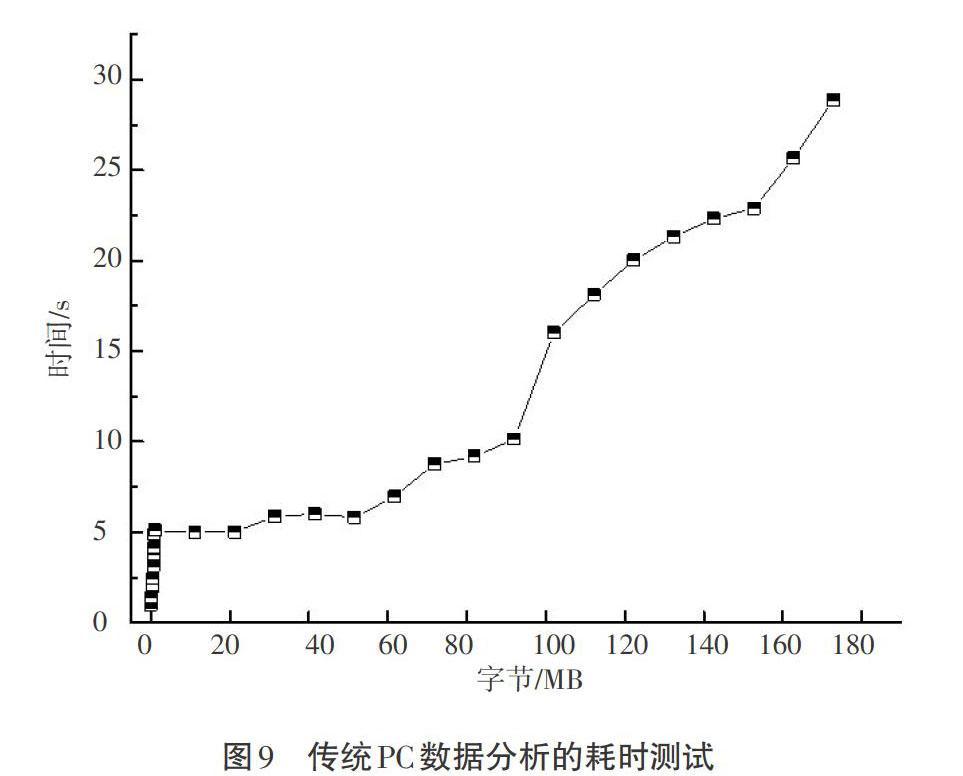
计算机是传统数据分析软件的基础平台,压力测试表明,随着数据容量的增加,其软件性能变化如图9所示。当数据大小不足兆字节容量时,数据分析软件记录行读取所耗的时间均保持在1~5 s;当数据大小超过兆字节容量时,数据分析软件记录行读取所耗的时间快速上升,最终,随着数据的不断增大,数据分析软件出现卡顿和宕机的现象。
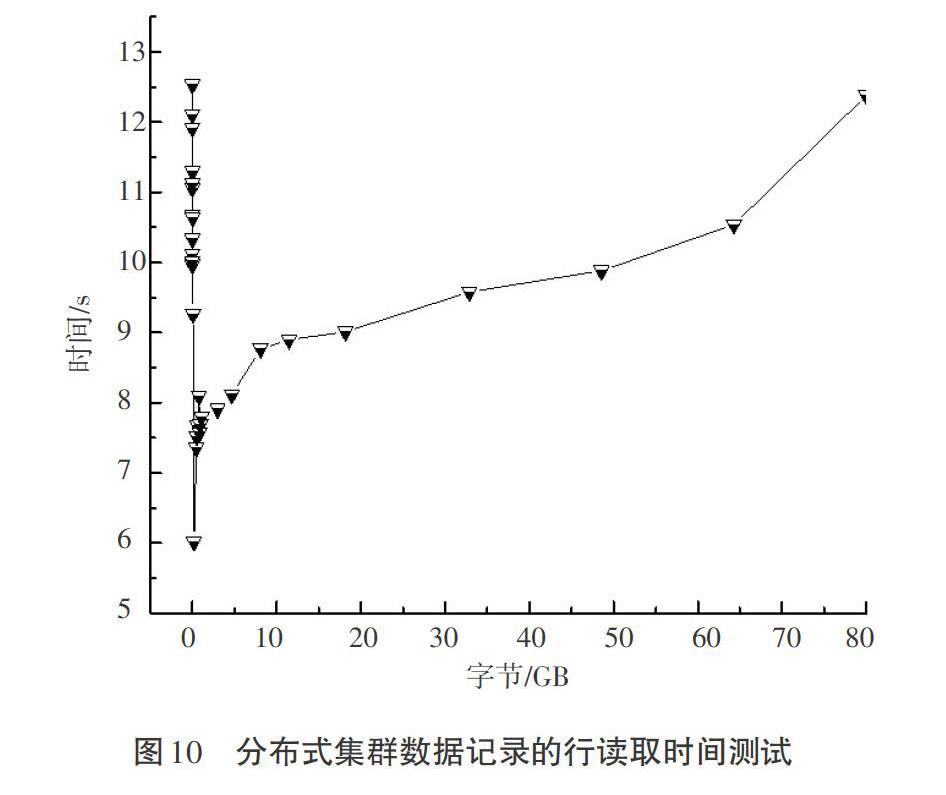
下面以Hadoop集群为基础,针对物联网资产管理系统采集与存储的数据,进行数据记录的行读取时间测试。集群运行期间不考虑程序代码编写优化程度对数据读取时间的影响,重复性测试结果如图10所示。
Hadoop分布式集群系统可以有效读取数据文件。通过图9、图10测试结果分析可知,当数据块文件不大于180 MB时,随着数据块文件容量的增大,所需读取时间逐渐减少;当数据块文件大于180 MB时,随着数据块文件容量的增大,其数据记录的行读取时间增加,但整体增加缓慢;当数据块文件容量接近80 G时,其整体读取时间不超过30 s,再次证明Hadoop分布式集群系统适用于大数据文件的读写。大数据集群系统主要用于快速读取海量数据,当对小文件进行读取分析时,其会耗费较多时间,并不能充分发挥快速读取的功能。
4 结论
近年来,物联网技术快速发展,而高职院校实训室物联网资产管理系统实时采集并存储大量数据。若工作人员使用传统的数据分析方法对数据进行筛选,所需时间较长,工作效率较低。本研究利用21台配置较低且实训室淘汰的老旧计算机,部署Hadoop分布式集群,并通过物联网资产管理系统实现分布式集群系统的网络对接,使物联网采集的数据时时存储在Hadoop分布式集群的HDFS文件中。该集群充分利用空闲硬件CPU、内存、硬盘等资源,通过资源的再次整合,更好地提供数据的存储、统计、分析等服务。
本文将物联网技术和Hadoop技术相结合,在真实的环境和数据库集群中进行创新性研究,根据测试数据生成的图表,验证发现,Hadoop技术架构下的物联网资产管理系统可以高效地管理数据。今后的工程应用和技术研究将以已经搭建的Hadoop分布式集群环境为基础,通过详细数据进一步优化上层软件的程序算法。
参考文献:
[1]夏靖波,韦泽鲲,付凯,等.云计算中Hadoop技术研究与应用综述[J].计算机科学,2016(11):6-11.
[2]尹乔,魏占辰,黄秋兰,等.Hadoop海量数据迁移系统开发及应用[J].计算机工程与应用,2019(13):66-71.
[3]李校林,杜托,谢勇.基于Hadoop的大数据频繁模式挖掘算法[J].微电子学与计算机,2018(9):14-19.
[4]MO H,ZHANG Y J,LI H F.A Performance Comparison of Big Data Processing Platform Based on Parallel Clustering Algorithms[J].Procedia Computer Science,2018(139):127-135.
[5]黃华林,庞欣婷.基于Hadoop的数据资源管理平台设计[J].计算机应用与软件,2018(7):329-333.
[6]王谟瀚,翟俊海,齐家兴.基于MapReduce和Spark的大规模压缩模糊K-近邻[J].计算机工程,2020(11):145-153.
[7]吴颖,李晓玲,唐晶磊.Hadoop平台下粒子滤波结合改进ABC算法的IoT大数据特征选择方法[J].计算机应用研究,2019(11):3297-3301.
[8]WU Q H,WANG H H,YAN X S,et al.MapReduce-based adaptive random forest algorithm for multi-label classification[J]. Neural Computing and Applications, 2018(31): 8239–8252.
[9]SHAIKH T A,ALI R.Big data for better Indian healthcare[J].International Journal of Information Technology,2019,(4):735-741.
[10]FRANCISCO G,ANTONIO C,LUIS I,et al.Improving Distance-Join Query processing with Voronoi-Diagram based partitioning in SpatialHadoop[J].Future Generation Computer Systems,2020(111):723-740.
