基于网格技术的分布式大数据混合云存储方法研究
2021-09-10庄银霞
庄银霞






【摘 要】 为提升分布式大数据的存储能力,实现大数据的定向迁移与应用,提出基于网格技术的分布式大数据混合云存储方法。采用网格技术设计Hadoop型云框架、大数据调度模块、信息互感平台,完成分布式存储结构搭建。在此基础上,通过划分大数据存储关系,定义混合云存储的具体格式,实现分布式大数据混合云存储方法设计。实验结果表明,与传统分级信息存储方法相比,研究方法的大数据定向迁移速率达到4.5×107 T/h,存储容量的上限也明显提升,能够充分满足分布式大数据存储需求。
【关键词】 网格技术;分布式大数据;混合云存储;调度模块;互感平台;存储依赖度;定向迁移;
Research on Distributed Big Data Hybrid Cloud Storage Based on Grid Technology
ZHUANG Yin-xia
(Quanzhou University of Information Engineering,Quanzhou 362000,China)
【Abstract】 In order to improve the storage capacity of distributed big data and realize the directional migration and application of big data, a hybrid cloud storage method based on grid technology is proposed. Using grid technology to design Hadoop cloud framework, big data scheduling module, information mutual inductance platform, to complete the construction of distributed storage structure. On this basis, through the division of big data storage relationship, the specific format of hybrid cloud storage is defined to realize the design of hybrid cloud storage method for distributed big data. The experimental results show that compared with the traditional hierarchical information storage method, the directed migration rate of big data of the research method is 4.5×107 T/h, and the upper limit of storage capacity is also significantly improved, which can fully meet the requirements of distributed big data storage.
【Key words】 grid technology; distributed big data; hybrid cloud storage; scheduling module; mutual inductance platform; storage dependency; directional migration;
〔中圖分类号〕 TP393 〔文献标识码〕 A 〔文章编号〕 1674 - 3229(2021)01- 0000 - 00
0 引言
网格是一种具备超强存储能力与处理能力的新型IT网络,能够应对云环境下所有临时信息存储请求。在共享网络的支持下网格可直接统计不同连接处的计算机从属关系,从而建立完全虚拟化的超级计算机系统。在数据处理过程中,网格将各个计算机的多余处理器结合在一起,不仅提升了信息处理效率,也避免了复杂信息间套叠关系的出现[1]。网格技术以TCP/IP协议作为核心,与其它信息互联手段相比,这种方法可以在构建网格映射关系的同时,定义标准服务环境下的数据关系,不仅增强了计算机系统中对象管理效果,也解决了因不良网络服务而造成的信息干扰问题。
随着网络环境中待处理信息总量的提升,如何定义大数据的定向迁移与应用关系,已经成为了一种亟待解决的问题。为实现上述目标,传统分级信息存储手段在无监督自动数据清洗指令的支持下,分析大数据之间的逻辑权重关系,再借助DeepDive平台完成已存储大数据的定向迁移与处置。但在既定存储空间内,这种方法存储容量相对较低,且很难在单一方向上实现关联大数据的高效率转移。基于此引入网格技术,联合Hadoop型框架、信息互感平台等多个硬件设备,设计一种新型的分布式大数据混合云存储方法,并通过对比实验的方式,验证这种方法的实际应用价值。
1 基于网格技术的分布式存储结构
基于网格技术的分布式存储结构由Hadoop型云框架、大数据调度模块、信息互感平台三部分共同组成,具体搭建方法如下。
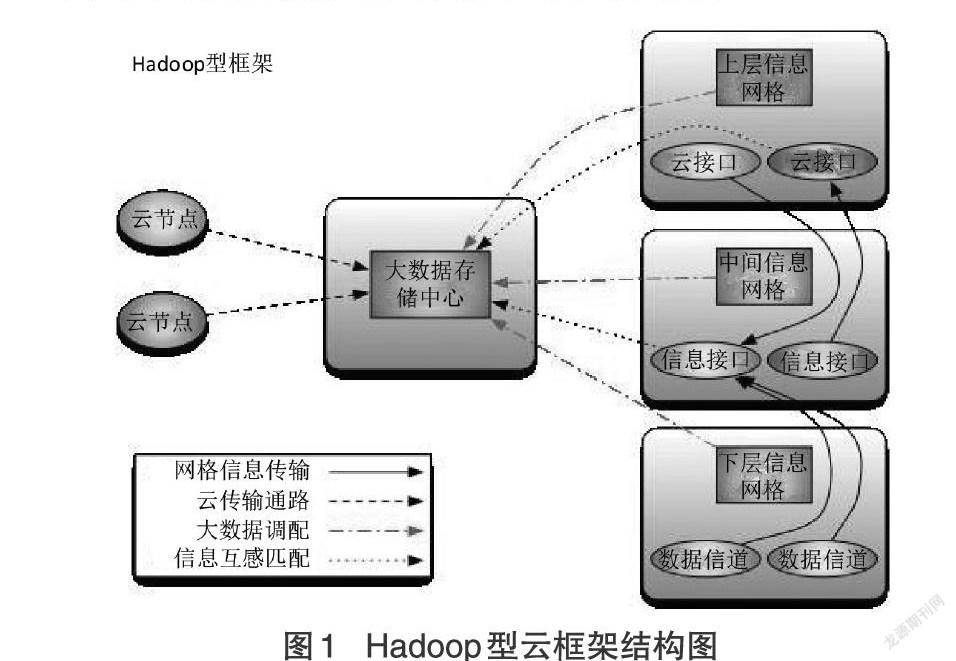
1.1 Hadoop型云框架
Hadoop型云框架是大数据分布式存储结构的建立基础,由大数据存储中心、上层信息网格、中间信息网格、下层信息网格共同组成。在在云节点呈现数据流持续输出的情况下,大数据存储中心可直接提取分布式数据库中的待处理数据参量,再借助信息互感匹配通路,将所有大数据传输至下级应用平台中。上层信息网格、中间信息网格、下层信息网格按照从上至下的顺序排列,待存储的大数据首先经由调配通道进入顶层云接口中,再按照网格化应用需求,将满足信息利用条件的大数据传输至中层接口,最后联合所有未存储数据参量,完成由分布式大数据到网格化结构体的转化[2-3]。Hadoop框架是一种上下两端高度对称的云存储结构,可在满足网格信息分级应用需求的同时,实现数据参量的同步整合与调度。
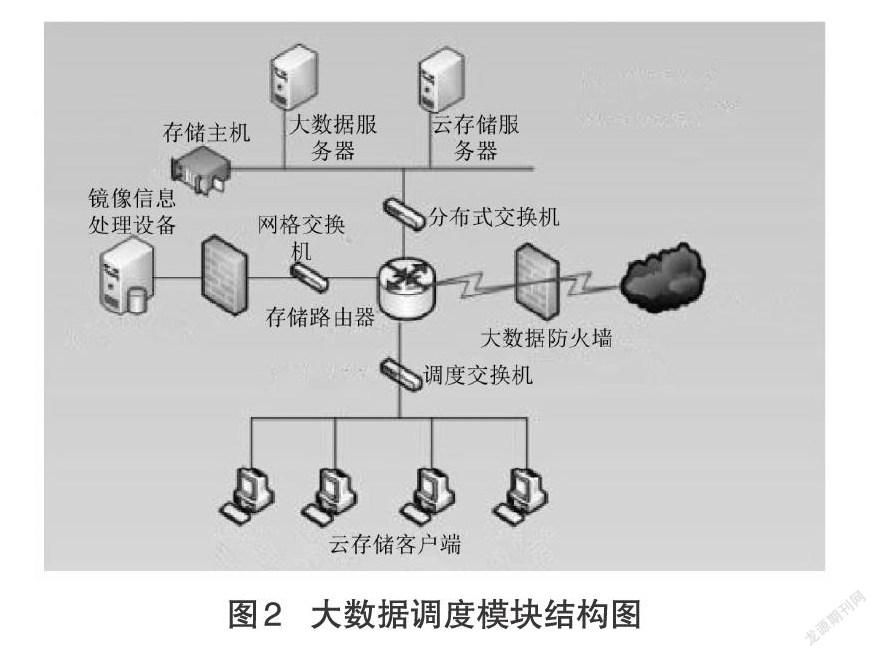
1.2 大数据调度模块
大数据调度模块作为Hadoop型云框架的下级附属模块,由服务器层、交换处理层、客户端层三个网格单元组成。其中,服务器层包含大数据服务器、云存储服务器两个核心设备,前者能够直接感知混合型大数据的随机变化,再将符合需求的大数据传输至顶层存储主机中;后者作为大数据存储指令的既定生成元件,可接收来自大数据网格的所有应用信息,并将其转化为镜像式信息结构体[4]。交换处理层包含镜像信息处理设备、网格交换机、分布式交换机、存储路由器、大数据防火墙五类元件。其中,镜像信息处理设备负责接收云存储服务器中的镜像式信息结构体,在存储路由器的支持下,将待存储的分布式大数据信息首先转换成“H型”存储结构、再转换成“R型”存储结构,且在整个执行处理过程中,网格交换机与分布式交换机始终保持着连接状态[5-6]。大数据防火墙具备较为稳定的防入侵能力,也是执行云存储指令的安全性保障元件。客户端层包含一个调度交换机和多个底层云存储执行设备,前者仅负责接收与信息结构体相关的调度处置指令,而后者作为指令执行者必须时刻与分布式大数据节点保持相同的变化趋势。
1.3 信息互感平台
信息互感平台与大数据调度模块直接相连,向上接收来自Hadoop型云框架的网格数据参量,向下执行由混合数据库定义的应用调度指令,以Query table芯片和Capacity table芯片作为核心设备。其中,Query table芯片作为上层分级元件,可借助云存储信道建立与客户端的连接。在大数据调度模块保持着连续大数据输出的情况下,信息互感平台立刻进入连接状态,然而随着大数据调度速率的增加,芯片所承载的传输压力也会不断提升,直至信道内的所有网格数据存储完成后,互感平台才会接受再次连接申请,保证传输的稳定性[7]。Capacity table芯片作为下层分级元件,借助云传输通路与混合数据库建立连接。通常情况下,Hadoop型云框架不会影响信息互感平台内的信息传输速率,而该结构在功能方面与数据存储调节器类似,只能缓解因信息处理不及时而造成的数据堆积情况,并不能从根本上增强平台内部元件的互感共通能力。
2 分布式大数据混合云存储方法设计
在分布式存储结构的支持下,按照大数据存储关系划分、混合存储格式定义、已存储信息格式有效性计算等过程,完成基于网格技术的分布式大数据混合云存储方法的设计。
2.1 大数据存储关系划分
大数据存储关系划分是在分布式存储结构的支持下,确定特征网格节点的从属执行能力,从而计算分布式数据库的处理能力。在不考虑分布式信息网格干扰的前提下,大数据存储关系中的最大处理能力也被称为云参量的上限存储极值条件,主要受到起始分布式权限与混合信息标度参量的影响[8-9]。假设起始分布式权限常用[r1]表示,在既定存储时间内,开放权限可加快大数据的传输速率,对云参量上限存储极值条件起到正向促进作用。起始混合信息标度参量常为[i1],可作为评估大数据结构体存储有效性的物理指标,在网格技术的影响下,始终与起始分布式权限系数保持相同的物理作用。大数据存储关系中的最小处理能力也叫云参量的下限存储极值条件,受到终止分布式权限与结束混合信息标度参量的同时作用影响。终止分布式权限为[r2],在既定存储时间内,终止权限则不能实现大数据的传输调度,对云参量平均存储数值水平起到反作用。终止混合信息标度参量为[i2]。联立上述物理量,可将大数据存储关系表述为:
[q=0∞r12χ1×yi1dyq=0∞i2r2χ2×udu] (1)
其中,[χ1]代表分布式大數据的起始传输速率,[χ2]代表分布式大数据的终止传输速率,[y]代表网格数据信息的一般存储条件,[u]代表已存储大数据信息的平均转化条件。
2.2 混合存储格式定义
大数据混合存储格式分为并列型、联合型、递进型、交互型四类。
(1)并列型大数据存储格式指的是起始节点与终止节点类型完全相同的信息结构体,在分布式网格中,可在无互感节点配合的情况下,实现由散点信息到束状结构体的转化[10]。
(2)联合型大数据存储格式指的是起始节点质量明显高于终止节点质量的信息结构体,在分布式网格中,这类信息结构体的传输速率始终保持在2000bit/s-2500 bit/s之间,也只有在互感节点的配合下,才能实现由散点信息到束状结构体的转化。
(3)递进型大数据存储格式指的是终止节点质量明显高于起始节点质量的信息结构体,在分布式网格中,这类信息结构体的传输速率始终保持在2500bit/s-3000 bit/s之间,有无互感节点配合,都能实现由散点信息到束状结构体的转化。
(4)交互型大数据存储格式指的是起始节点与终止节点类型完全不相同的信息结构体,在分布式网格中,这类信息结构体的传输速率极慢,低于2000 bit/s,必须在互感节点配合的情况下,才能实现由散点信息到束状结构体的转化[11-12]。完整的混合存储格式定义原理如表1所示。
分布式大数据云存储可根据大数据参量的上下限划分关系,确定已存储信息格式有效性,并以此为依据,进行大数据云存储[13]。在不考虑数据过量迁移行为的情况下,云存储效果受到网格作用系数、分布式信息量化条件的影响。设网格作用系数为[β],具备明显的时间行为特性,在既定存储周期内,该项物理指标会随大数据传输总量的增加而不断上升。分布式信息量化条件为[f],具备较强的承载稳定性,在大数据存储空间[[q,q]]内,该项物理指标始终保持不变。联立公式(1),可将云存储结果表示为:
[ε=2βk2-k1+qqf⋅lx2lnD2D1] (2)
其中,[k2]代表大数据指标的最大化表现行为量,[k1]代表大数据指标的最小化表现行为量,[l]代表分布式大数据的混合存储周期,[x]代表待存储信息的分布描述参量,[D2]代表最大量化处理系数,[D1]代表最小量化处理系数。
3 实验设计与结果分析
为突出说明基于网格技术的分布式大数据混合云存储方法的实际应用价值,设计如下对比实验。截取两段波长相同、频率相等的大数据作为实验对象,分别以搭载研究方法和传统分级信息存储手段的分析主机作为实验组、对照组,在既定时间内,根据指标数值的走向趋势,研究大数据的定向迁移速率与数据储存容量的具体变化情况。
3.1 实际检测环境搭建
将两段大数据信息分别导入不同的分析主机中,在相同实验环境下,根据显示器中指标参量的实际变化,绘制实验指标变动曲线。
3.2 定向迁移速率
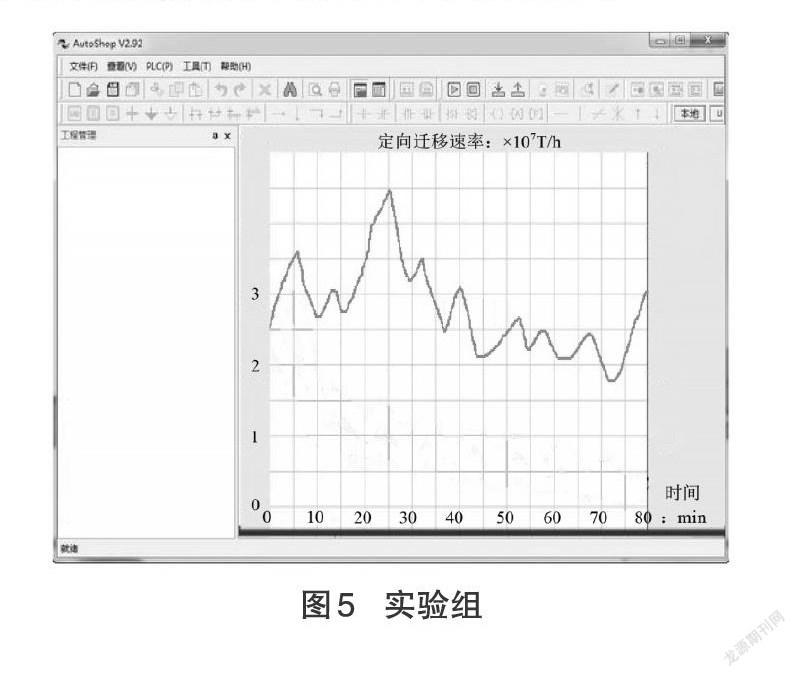
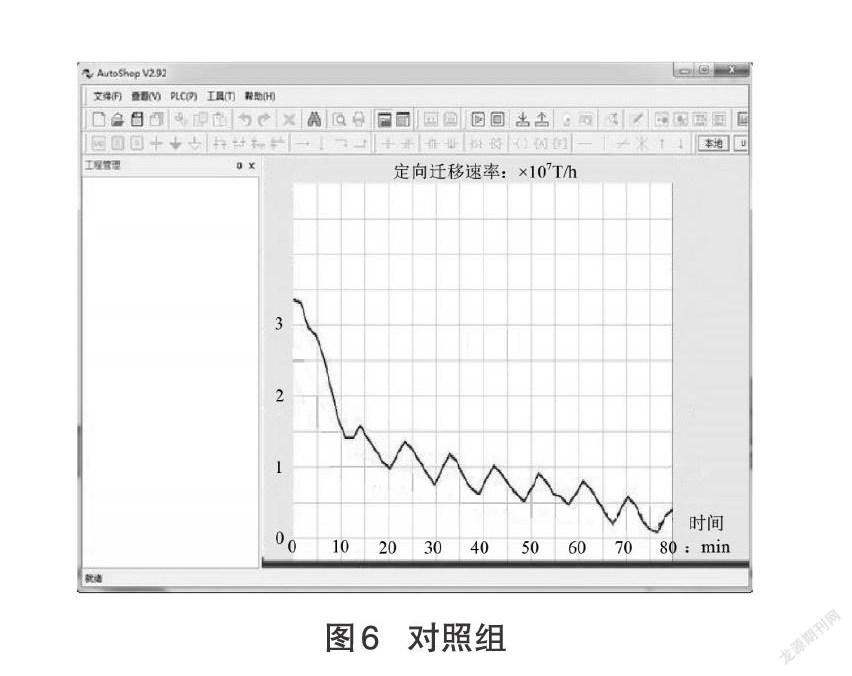
以80 min作为既定检测时长,分别记录在该段时间内,实验组、对照组大数据的定向迁移速率的具体变化情况,实验详情如图5、图6所示。
对比图4、图5可知,在整个检测过程中,实验组关联信息的定向迁移速率基本保持上升、下降交替出现的变化趋势,对照组关联信息的定向迁移速率在大幅下降后,开始小幅度的波动式下降,前者最大值达到4.5×107T/h,而后者最大值仅达到3.8×107T/h,低于实验组数值水平。综上可知,应用基于网格技术分布式大数据混合云存储方法,可实现提升关联信息定向迁移速率的目的。
3.3 数据存储容量
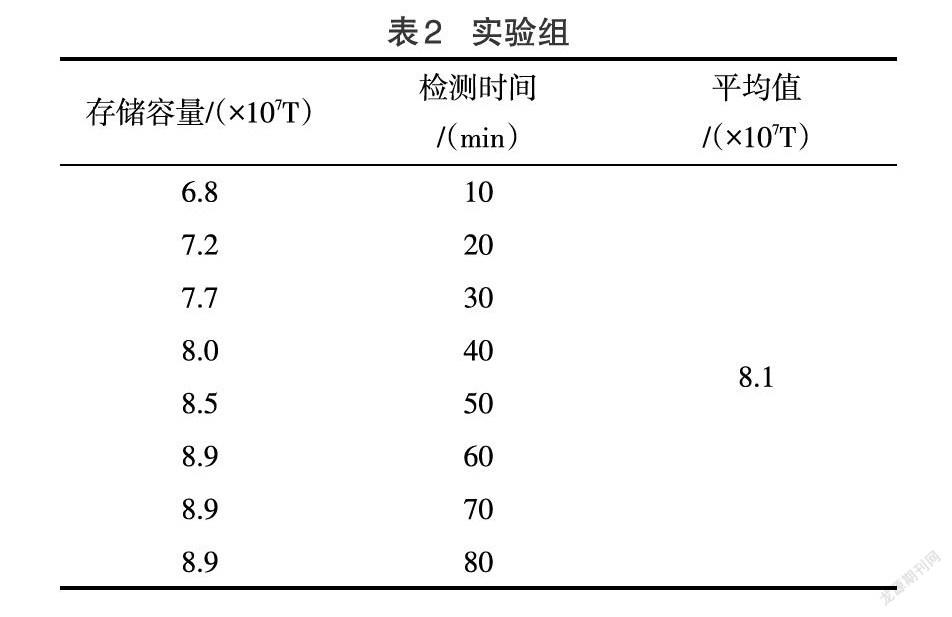
下表反应了80min的检测时间内,实验组、对照组数据存储容量的具体变化情况。
对比表2、表3可知,在整个检测过程中,实验组数据存储容量保持先上升、再稳定的变化趋势,对照组数据存储容量前期始终保持稳定,后期开始大幅下降,前者最大值达到8.9×107T,而后者最大值仅达到4.3×107T,远低于实验组。综上可知,应用基于网格技术分布式大数据混合云存储方法,能够从根本上解决数据扩展空间不达标的问题。
4 结束语
随着网格应用技术的不断普及,传统分级信息存储手段虽能明确大数据结构之间的逻辑权重关系,但始终难以实现分布式大数据的定向迁移与应用。为解决该问题,本文提出基于网格技术的分布式大数据混合云存储方法,通过设计Hadoop型云框架、信息互感平台等多个硬件设备,在划分大数据存储关系,定义混合云存储的具体格式后进行数据云存储,不仅大大提升了大數据的定向迁移速率,也充分扩展了额定空间内的数据存储容量,具有较高的实际应用价值。
[参考文献]
[1] 王海涛,李战怀,张晓,等. 一种基于LSM树的键值存储系统性能优化方法[J]. 计算机研究与发展,2019,56(8):1792-1802.
[2] 徐晓霞,姜春茂,黄春梅. 一种基于三支决策的移动云任务节能卸载方法[J]. 南京理工大学学报(自然科学版),2019,43(4):447-454.
[3] 任晓莉,杨建卫,李乃乾. 云计算中基于动态虚拟化电子流密码的安全存储[J]. 计算机科学与探索,2019,22(8):1331-1340.
[4] 季一木. HOS:一种基于HBase的分布式存储系统设计与实现[J]. 南京邮电大学学报:自然科学版,2019,39(5):63-71.
[5] 杨茜. 基于盲数BM模型的配电网谐波数据存储安全控制方法[J]. 电网与清洁能源,2019,35(12):43-48.
[6] 金光. 基于IFC4的电气化铁路接触网BIM数据存储标准研究[J]. 铁道标准设计,2018,62(8):132-137.
[7] 韩文军,余春生. 面向输变电工程数据存储管理的分布式数据存储架构[J]. 沈阳工业大学学报,2019,41(4):366-371.
[8] 徐毅,王建民,黄向东,等. 一种基于最大流的分布式存储系统中查询任务最优分配算法[J]. 计算机学报,2019,25(8):1858-1872.
[9] 温振蕙,樊永生,余红英. 基于Thrift的HBase数据存储机制优化[J]. 科学技术与工程,2019,19(6):185-189.
[10] 吴灿强,芮晔,潘东梅. 基于YAFFS2文件系统的分区管理对载荷数据存储效率的研究[J]. 电子设计工程,2018,26(23):42-47.
[11] 王平,杜永成,杨立,等. 基于重叠网格技术和VOF模型的潜艇热尾流浮升扩散规律的数值与实验研究[J]. 红外与激光工程,2019,18(4):38-46.
[12] 孙健飞,李岩松,韩东,等. 基于多重网格技术的含蜡原油管道析蜡速率三维数值模拟研究[J]. 工程热物理学报,2019,14(8):1913-1920.
[13] 王启明,车爱兰. 基于CT探测技术的不良地质构造三维网格模型重构方法[J]. 岩石力学与工程学报,2019,38(6):1222-1232.
