基于映射规则的数据产品自动生成方法及系统
2021-09-06李子恒叶育鑫曹玲玲刘思培
李子恒 叶育鑫 曹玲玲刘思培
(1.吉林大学a.计算机科学与技术学院;b.符号计算与知识工程教育部重点实验室,长春 130012;2.北方信息控制研究院集团有限公司 总体部,南京 211111)
0 引 言
Google 为了提高搜索引擎回复答案的质量,以及提升用户进行查询时的效率,于2012 正式推出了知识图谱(Knowledge Graph)[1]。在已知的知识图谱中,数据通常是以RDF(Resource Description Framework)三元组的形式进行存储[2],并使用基于RDF的查询语言SPARQL(Simple Protocol and RDF Query Language)[3]对知识图谱进行查询。
笔者利用SPARQL 查询语言,并使用基于模板匹配的查询语句转换算法使用户能直接对知识图谱进行查询,抽取所需的业务子图。抽取到满足条件的数据后,根据制定好的数据产品生成规则生成用户最终需要的数据产品。如使用基于指针生成网络(Pointer-generator networks)模型所提出的KG2TEXT 模型进行自然语言的生成;使用SSRS(Microsoft SQL Server Reporting Services)生成各类型图表;采用OpenXML SDK 创建Word 格式模板,生成报告文档等。
1 知识图谱及相关技术
知识图谱相比其他的知识表示方法具有更优秀的表达能力、更灵活的建模能力,不仅对人类易于识别,而且对机器也易于处理,自身还具备语义信息。利用这些优势,知识图谱在语义搜索、智能问答、个性化推荐和辅助决策等领域都得到了应用,且取得不错的效果。目前国内外的知识图谱应用主要有:互联网知识图谱,如FreeBase、DBpedia、OpenKg、zhishi.me;搜索引擎,如Magi;语义搜索,如百度知识图谱;问答系统,如watson 问答系统;辅助决策,如军事图谱辅助作战指挥、金融反欺诈、信贷审查等。
用户可以利用知识图谱更好更精确地查找到自己所需要的信息。当在知识图谱中查询有关尼米兹号航空母舰这个实体的相关信息时,可以得到如下的子图(见图1)。
知识图谱常以RDF的形式进行存储,RDF 即资源描述框架,可以描述资源之间的关系以及资源具有的特性。W3C 在1999 年提出RDF[4],为应用程序之间在Web 上交换元数据提供一个基础的结构。在知识图谱中称一个RDF 陈述为一条知识,RDF 陈述是指通过属性(Predicate)和对应属性值(Object)对特定资源(Subject)进行描述,如图2 所示。
知识图谱构建一般遵循如下几个步骤:1) 知识获取,采用一系列自动或半自动的技术手段从多源异构数据(结构化的数据库、半结构化的数据日志、非结构化的文本)中抽取知识;2) 知识融合,将抽取出的知识进行融合,保持知识的一致性;3) 知识存储,一般使用图数据库对知识进行存储,将实体视为节点,关系视为边,利用图数据库可以明确清晰地表达实体之间的联系。知识图谱构建完成后,通常使用基于RDF的查询语言对知识图谱进行查询。本系统利用SPARQL 查询所需的业务子图。SPARQL 以RDF 图的三元组匹配为基础,对任意映射到RDF 模型的数据资源进行访问,并成为W3C的推荐标准。
2 映射规则的知识表示和模板定制
2.1 映射规则的SPARQL 表示
SPARQL 是以RDF 图的三元组匹配为基础的查询语言。以尼米兹号航空母舰的RDF 数据为例:
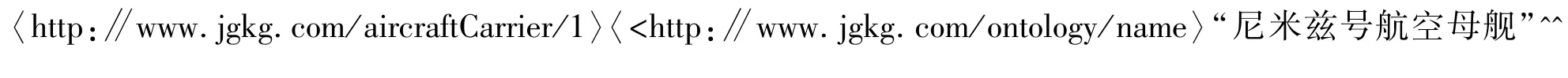

2.2 基于SPARQL 复合查询语句的模板定制
该系统利用SPARQL的查询语言规范部分为查询模板设计SPARQL 查询语句。据2.1 节描述,用户为获得所需要的信息,需要编写特定格式的查询语句,但用户并不具备相应专业知识。为此该系统使用PAROT 架构[5],针对常用的查询语句给出相应的模板规则生成所需的SPARQL 查询语句,使用户能直接利用自然语言进行查询。该方法主要包括以下几个步骤:1) 从自然语言查询中确定目标单词;2) 从自然语言查询中识别出三元组,由于是用户查询,成为用户三元组;3) 将用户三元组转变成本体三元组;4) 构造SPARQL 查询语句。
2.2.1 确定目标单词
给定以自然语言提交的用户查询,首要任务是从查询中确定目标单词。目标单词是一个变量,将直接放置在SPARQL 查询中的SELECT 关键字之后。为了帮助识别用户提交的查询中的目标词,笔者使用了类型依赖解析器,如Stanford typed dependency parser[6]。依赖性解析器提供了用户提交的查询中单词之间存在的语法关系的简单描述。为了在解析的查询中提取目标词,笔者将查询分为两类,即以WH 开始的问题和不以WH 开头的问题。
第1 类:此类别由以WH 开头的查询组成(即:what,when,where,who,whom,which,whose,why,how)。为在此类查询中识别目标词,笔者使用一些规则集,例子如下

上述规则1 和规则2 适用于非关系查询,规则1 适用于查询名词和其他任何名词之间不存在合取的关系,规则2 处理对多个名词进行查询,名词之间以and 等词连接,比如What is the area and population of the most populated state ?,就要同时对area 和population 进行查询。还有其他规则适用于关系查询,它们通过识别用户提交的查询中的处于被动语态的主语标记查询中的目标单词。
2.2.2 识别用户三元组
SPARQL 查询由一组称为图模式的三元组模式(基于RDF)组成,这种图模式可以直接放置在SPARQL 查询中的目标变量之后或WHERE 关键字之后。三元组模式和RDF 陈述相同,其中Subject,Predicate,Object 都可以是变量。本节目的是处理用户提交的查询,以识别出可用于构造SPARQL的潜在三元组。为了从提交的查询中识别用户三元组,将其分类为:基于关系短语的查询和基于非关系短语的查询。
基于关系的用户查询是至少包含连接两个名词的关系短语的查询。连接两个名词的关系短语可以是一个动词,一个直接跟在介词后面的动词,或一个跟在名词、形容词或副词后面以介词结尾的动词。非关系查询是指没有连接任何名词的关系短语的查询。在进行识别用户三元组,遇到复合查询语句,可使用功能checkCompound 评估句子是否为复合句,如果是复合句再利用适合规则将查询拆成两个查询,如上述例子会被拆为What is the area of the most populated state ?和What is the population of the most populated state ?最后再通过GenerateTriples 函数识别用户三元组。
2.2.3 将用户三元组转换成本体三元组
用户三元组中的单词需要映射到对应本体中的实体。例如,用户三元组{State state_of ?x}应转换为本体三元组{State:hasPopulation ?x}。为了达到此目的,本系统构造了一个词典帮助实现由用户术语到本体术语的转换。
2.2.4 构造查询语句
在将用户三元组转换为本体三元组之后,就生成SPARQL 查询语句。SPARQL 查询的一般语法如下:


3 数据产品的生成规则
3.1 查询子图的自然语言生成
一般将自然语言生成分为3 阶段[7-10]。1) 内容规划:要表达什么。2) 句子规划:篇章结构。3) 表层实现:如何表达。该系统通过对应的SPARQL 查询语句查找知识图谱获取语义知识,使用基于指针生成网络(Pointer-generator networks)的自然语言生成技术[11-13],生成相应文字。
该系统使用基于指针生成网络模型所提出的KG2TEXT 模型进行自然语言的生成。该模型集成了多变覆盖损失函数以及有监督注意力机制。其中多变覆盖损失函数会强制模型覆盖实体的每个属性值,因此自动生成的描述语句将尝试包含实体的每个输入属性文字,以避免信息丢失。有监督注意力机制则能显式指导模型的软切换过程,以从源输入生成单词或复制实体的属性值。将SPARQL 查询语句得到的业务子图输入到模型中,即可得到相应的自然语言。KG2TEXT的整体架构图如图3 所示,左边是双向GRU 层编码器端,右边是解码器端。
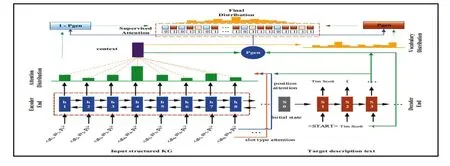
图3 KG2TEXT 模型的整体架构Fig.3 The overall architecture of the KG2TEXT model
3.2 查询子图的图表生成
该系统使用SSRS 报表工具创建各类型图表(表格、图形等)[14],是一种新型报表平台。笔者可以通过SPARQL 查询语言从知识图谱中获取到相应的RDF 三元组并存储到关系数据库中。而且SSRS 还为用户提供了完整的服务、工具和API,任何人都可以轻松地使用SSRS 开发、设计、管理报表(见图4)。通过应用程序编程接口,还可以很容易地将报表以Word 格式导出,并将其内容插入到模板中指定名称的书签位置。

图4 在SSRS 中设计的简单图表Fig.4 Simple diagrams designed in the SSRS
3.3 查询子图的报告文档生成
报告文档生成首先要为特定报告生成对应模板,将特定报告中具有统一格式的部分,比如各级标题及正文的文字的字体、字号、颜色,图片和表格的出现位置、排列方式等等按照用户需要的格式进行编辑,作为该类报告的模板。
该系统采用OpenXML SDK 创建Word 格式模板。OpenXML SDK 是一个托管类库,其中的Wordprocessing Document 类封装了Word 文档,即WordprocessingML 文件。要对Word 文档进行操作,需要先实例化此类。
在OpenXML SDK 中WordprocessingML 元素与Wordprocessing Document的类属性对应如表1 所示。利用表1 中的各类元素,可以生成特定的Word 格式模板,实现图文报表的快速生成。图文报表示例如图5 所示。

表1 WordprocessingML 元素与Wordprocessing 类元素对应表Tab.1 WordprocessingML elements and Wordprocessing class elements correspondence table

图5 关于军事目标识别的可视化展示平台的图文报表Fig.5 Graphic reports on the visual display platform for military target recognition
4 结 语
该系统实现了以知识图谱为数据源,根据实际业务需求制定业务数据抽取与组织规则,利用制定的对应的SPARQL 模板从知识图谱中抽取符合规则的子图。同时根据笔者指定的数据产品生成规则,从抽取的子图中生成数据产品。当需要生成文本时,利用从子图中提取到的语义知识,通过基于指针生成网络的自然语言生成方法生成语言流畅,语义正确的文本;当需要图表时,通过SSRS 报表工具创建数据报表,并且很容易开发设计图表及导出;当需要生成报告文档时,采用OpenXML SDK 对Word 格式文件进行操作,只需给定好文档模板,给定各类文档中图表及文本对应的位置,最后能快速自动生成一个报告文档。本系统能大幅度减少人为工作量,提高效率。
