违禁品X光图像检测技术应用研究进展综述
2021-08-19梁添汾张南峰张艳喜袁金豪高向东
梁添汾,张南峰,2,张艳喜,袁金豪,高向东
1.广东工业大学 机电工程学院,广州510006
2.黄埔海关技术中心,广东 东莞523076
X光安检是一项成熟的安检技术,广泛应用于各种公众安检领域。X光能够穿透物体产生透视图像,可清晰看到和检查行李中的物品。目前X光图像违禁品检查还需安检人员对X光图像进行判别[1],但其工作量和工作强度巨大,尤其是人员流动的高峰期,安检人员难以进行快速判别。安检人员安检准确率为80%~90%[2],物体在行李中堆放位置及其角度呈现出高度的不确定性,物体非标准平面图像比标准平面图像识别难度更大,因此自动安检成为安检领域的必然趋势。
近年来深度学习在图像处理方面取得大量成果[3]。基于深度学习的X光图像违禁品研究文献逐渐增加,针对X光违禁品检测应用研究现状,对违禁品检测技术进行归纳与总结,分析该领域内存在的不足与值得关注的方向。首先介绍X光成像相关技术及其特点,然后探讨传统机器学习的X光违禁品检测方法,分析基于深度学习的X光图像违禁品检测算法研究,最后总结现有研究的不足并对未来发展方向进行展望。
1 X光成像技术
X射线由德国物理学家伦琴于1895年发现,其能量很强,波长很短,可穿透物质。X射线在医疗、工业检测、公共安全等领域发挥着极其重要的作用。X光成像技术主要有透视成像技术、背散射成像技术和计算机断层扫描技术(CT)等。
背散射技术利用康普顿散射原理进行成像,X光遇到物体会产生大量散射光子,散射强度与物体原子序数有关,通过散射光子进行探测成像。背散射技术能有效检测违禁物品,特别是液体违禁品、炸药等[4],但其缺点是穿透能力差,成像分辨率低。
CT技术从20世纪70年代问世以来,因其在物质探测方面的优秀性能,广泛应用于医疗诊断、工业检测领域。X光扫描一定厚度的物体断面,然后利用计算机进行三维重建获得物体形状、密度、有效原子序数和质量等信息,但设备价格昂贵,在医疗上使用较多。
目前公共检查领域大量使用X光透视技术进行安检,透视成像分为单能X光透视成像和双能X光透视成像,其中单能X光透视成像最基础,使用时间也最早。单能X光透视成像为灰度图,但单能透视成像无法区分物体的材质,因此目前公共场合通常采用双能X光。双能X光使用高低能两个射线管,根据物体对高低能射线吸收系数不同,将两个不同物质、不同厚度的物体区分出来更便于安检人员对物体进行分辨[5]。
2 传统机器学习违禁品X光图像检测应用
传统机器学习X光图像检测使用手工特征和分类器进行分类,定位信息则由滑窗方式进行获取[6]。在传统X光图像检测中视觉词袋模型(Bag-of-Visual-Words,BOVW)被使用频率最高。图1是视觉词袋模型分类流程。传统机器学习检测方法可分为X光单视图检测和X光多视图检测。

图1 视觉词袋模型分类流程Fig.1 Classification process of BOVW
2.1 X光单视图检测
早期机器学习违禁品检测研究中使用单视图进行检测较多。视觉词袋模型在X光图像分类上有较好的适应性,可用于减少安检人员的工作量[7]。Turcsany等[8]使用支持向量机(Support Vector Machine,SVM)和SURF(Speeded-Up Robust Features)特征建立视觉词袋模型,通过特征描述符类的聚类得到启动视觉词,并将其用于视觉词袋模型中的图像编码,对双能X光图像中的违禁品进行识别,验证了使用大型和具有代表性的数据集可提升分类任务的效果。基于隐式形状模型(Implicit Shape Model,ISM)对单一视角图像违禁品进行识别也有较好效果[9]。王宇等[10]提出一种基于Tamura纹理特征和随机森林分类方法,对四类违禁品进行特征提取和分类,特征表示分别使用共生矩阵和Tamura特征,分类器使用随机森林、AdaBoost、决策树和贝叶斯网络进行对比,结果显示Tamura特征组合随机森林分类器分类性能最好。Zhang等[11]使用X光图像颜色、纹理、形状和边缘特征等底层特征挖掘图像的高级特征来进行违禁品检测。文献[6]在基于传统手工特征的X光图像分类检测任务上做了大量工作和实验,将多种手工特征进行组合实验,全面展示了传统手工特征在X光图像检测任务上的性能。
2.2 X光多视图检测
由于单视图检测没有考虑多视图间关系对物体检测带来的性能提升,有学者采用多视图对物体的多个角度成像然后进行检测。Franzel等[12]使用SVM组合梯度直方图进行滑窗检测,引入多视角集成方法处理平面物体的旋转,实验证明使用多视图可有效提高检测性能。Bastan等[13]基于视觉词袋模型提出一种综合评价图像分类和目标检测的标准局部特征,然后扩展特征来获取双能X光中额外有用的信息,实验表明使用多视图可提高定位精度,从而提高检测性能。Mery等[14]提出一种基于序列的多视图识别X光图像物体的自适应检测方法,从不同角度采集目标的各个部分,建立多视图几何模型,寻找不同视图间对应关系,同时结合单视图检测和多视图检测分析跟踪物体。该方法可减少由于单视角检测产生的误检,增加算法的鲁棒性。Mery等[15]提出了一种识别方法,将检测应用于单视角图像,寻找感兴趣的目标,然后在多视角X光图像上进行匹配,减少单视图检测时产生的误报。
表1 对单视图检测与多视图检测进行了对比分析。

表1 单视图检测与多视图检测对比Table 1 Comparison of single view detection and multi-view detection
3 深度学习的违禁品X光图像检测应用
3.1 深度学习技术
深度学习使多层非线性网络具有强大的表达能力,在语音、图像、文本等领域发挥重要作用[16]。目标检测是图像处理领域中重要的问题,基于深度学习的目标检测算法可应用于各种检测领域,例如公共场所吸烟检测[17]和病灶检测[18]等。近年来深度学习得到突破性发展,将其应用于目标检测任务也使目标检测领域获得突飞猛进的发展[19]。
2012年Krizhevsky等[20]提出的AlexNet网络在图像分类上取得成功,表明深度学习在图像处理中的优秀性能。在AlexNet取得巨大成功后VGG[21]、GoogleNet[22]、ResNet[23]等各种分类网络相继推出,深度学习的分类性能不断得到提高。目标检测算法可分为单阶段检测算法和两阶段检测算法,两阶段检测算法最经典的模型是R-CNN[24]。R-CNN由Girshick等于2013年提出,模型提取约2 000个候选区域作为输入,经过AlexNet提取特征,使用SVM和回归器进行分类和定位。以R-CNN为基础不断进行改进,SPP-Net[25]、Fast R-CNN[26]和Faster R-CNN[27]等都是改进后的优秀模型。单阶段检测算法与两阶段检测算法不同,其实现端对端训练和检测,因此单阶段检测算法检测速度快,满足实时性要求。单阶段检测算法中有许多优秀的模型,其中YOLOv3[28]、YOLOv4[29]、SSD[30]、FSSD[31]都是检测速度与检测精度平衡的检测模型。
3.2 X光图像数据集
深度学习目标检测模型的提出及其解决的问题大多是基于光学图像,公开的光学图像数据集获取容易,而且制作成本不高,但X光图像的获取较为困难,必须使用专业设备进行获取。目前适用于违禁品检测的X光数据集有GDXray[32]、SIXray[33]和天池津南数字制造算法比赛数据集[34]。
GDXray是首个公开的X光图像大型数据集,包含8 150张X光行李图像,数据集中有枪支、手里剑和刀片违禁品。GDXray数据集中的数据都是灰度图,其中目标轮廓清晰容易区分,背景简单,物体重叠和遮挡现象较少。
(3)裕固族传统体育的发展与当地的经济、文化教育事业发展步伐不一致,使裕固族传统体育的自身功能衰退,阻碍了裕固族传统体育的发展。
SIXray数据集提供超过100万张X光图像,其中有六类目标分别是枪、刀、扳手、钳子、剪刀和锤子,包含目标的标记图像有8 929张。SIXray数据集中目标物体堆放随机性相当大,图像中背景复杂且其中物体存在严重的重叠和遮挡。
天池津南数字制造算法比赛数据集针对危险品、限制品和特殊物品三大类物品细分出五类目标,分别是铁壳打火机、黑钉打火机、刀具、电池电容和剪刀。该数据集中目标数量多,堆放角度和位置随机性大,背景较杂乱。
3.3 深度学习方法与传统方法对比
深度学习拥有多层神经网络,其分类性能优于传统机器学习算法。深度学习广泛应用于检测领域,在X光图像检测领域也大量使用深度学习。Akcay等[35]首次将深度学习引入到X光图像的行李分类检测,使用迁移学习将AlexNet网络应用于X光图像行李分类的研究;对比传统机器学习,深度学习表现出优秀的检测性能和鲁棒性。Mery等[1]在GDXray数据集上进行实验,使用基于词袋模型、稀疏表示、深度学习和经典模式识别方案进行检测实验。AlexNet和GoogleNet都能达到相当高的识别率,说明使用深度学习方法设计自动的违禁品识别设备的可行性。Akcay等[36]将基于滑动窗口的CNN模型与基于候选区域的检测模型的检测性能进行了对比。Akcay等[37]将深度学习分类网络与视觉词袋模型进行对比,使用多种深度学习分类模型与手工特征处理二分类问题,实验表明深度学习分类性能优于视觉词袋模型,更适合X光图像分类任务。以上文献的研究表明了深度学习在X光图像检测上的适应性和鲁棒性。表2对深度学习方法与传统机器学习方法进行了对比。

表2 深度学习方法与传统机器学习方法对比Table 2 Comparison of deep learning methods and traditional machine learning methods
3.4 小目标检测
安检中行李一般较大,但隐藏在行李中的违禁品很小,例如小刀、枪支部件等,此类小物件给检测造成了一定的困难。提高小目标检测性能方法有使用多尺度特征融合、多尺度锚框以及多卷积模块等,如图2所示。多尺度特征融合可扩大深度学习模型的感受野,同时增加特征复用,将不同深度特征进行融合以提高小目标检测性能。为解决X光图像中小目标漏检误检问题,吉祥凌等[38]在SSD基础上使用多尺度特征融合提高小目标检测效果。在输入模型训练前将图像压缩到固定尺寸,但这会一定程度降低检测精度,改进网络将大图像进行分区域检测可改善上述问题。加入多尺度锚框可增加模型对于不同尺度目标的感应能力。张友康等[39]基于SSD网络进行改进,在该模型中加入小卷积非对称模块、多尺度特征图融合模块等以提升模型对小目标的检测效果。郭守向等[40]在YOLOv3的基础上将其主干网络改为两个DarkNet组合而成的新骨干网络,引入6层卷积的特征增强模块增强小目标的检测效果。对于Faster R-CNN模型对小目标不敏感问题,康佳楠等[41]对Faster R-CNN进行改进,将原本单卷积层提取特征提升为三层,同时提出多通道区域建议网络提高小目标检测效果。在网络中加入多种卷积模块也可一定程度提高小目标检测性能,Zhang等[42]在FSSD的基础上添加空洞卷积和残差模块提高模型对小目标的检测效果。
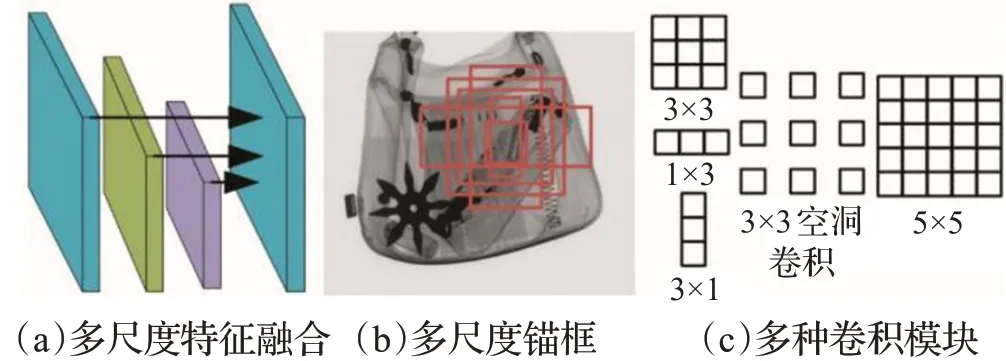
图2 小目标检测策略Fig.2 Small object detection strategy
3.5 特征提取策略
由于X光特殊的成像原理,其成像存在细节信息丢失和颜色信息丢失以及物体重叠等问题,针对这些特点优化算法可提高模型的性能。Liu等[43]针对X光图像前景和后景的亮暗差别明显特点,基于X光特定的颜色信息提出一种前景-后景分割方法,分割后可将大部分无用的后景去掉以提高检测性能,但其背景划分方法简单,泛化性能不足。X光图像可获取丰富的物体轮廓信息,Hassan等[44]利用X光图像中物体的轮廓信息经过级联结构张量技术生成一系列张量,然后导出目标建议,再经过基于轮廓和建议提取目标的卷积神经网络进行目标检测。该改进措施可提升深度学习模型的检测精度,但舍弃了图像的细节纹理信息。对于遮挡问题,张友康等[39]提出空洞多视野卷积模块,使用不同尺度的卷积核、不同膨胀率的空洞卷积以及直联卷积,增强模型在全局视野下对遮挡目标的学习。此外,加入注意力模块也能有效解决遮挡问题,Li等[45]将语义分割网络与Mask R-CNN组合成双阶段CNN模型,使用语义分割网络的结果作为Mask R-CNN软注意掩码,以改善X光图像中物体重叠导致的性能下降问题。利用双能X光图像的特性,将有机物和无机物进行分离更有利于违禁品检测。Zhang等[46]提出XMC R-CNN模型,首先利用X射线材料分类器算法以及有机剥离和无机剥离算法解决重叠X光行李图像中的违禁品检测问题,然后进行目标检测。
3.6 异常分类
违禁品在正常情况下出现的概率很小,因此可将违禁品出现作为异常。基于对感兴趣区域定位的思想,Gaus等[47]提出一种双CNN结构的两阶段检测方法。第一阶段在X光图像上找出感兴趣区域提供定位信息给第二阶段,第二阶段获得定位信息后采用SqueezeNet、VGG16以及ResNet进行异常分类,但该方法总体结构复杂,第二阶段异常分类精度不够理想。对于异常样本远远少于正常样本的问题,Akcay等[48]提出一种新的编码器-解码器-编码器模型,用于条件生成对抗网络,捕获图像和潜在向量空间中的训练数据分布,检测出X光图像中的异常类,但该方法对一些相似形状的目标难以区分。为解决X光违禁品分类效率低和准确度不足问题,吴海滨等[49]提出将X光图像进行高低频分解,使用八度卷积来替代传统卷积,同时引入注意力机制双向门控循环单元神经网络,有效提高了模型分类速度和准确度。
3.7 模型可转移性
文献[35]将深度学习引入到X光检测领域时就使用了迁移学习。迁移学习可加快模型收敛速度,但迁移学习是有限制的,要保证训练域与目标域有相似性[50],将光学图像数据集训练出来的权重直接应用到X光检测中会限制模型的性能[1]。Galvez等[51]基于YOLOv3使用迁移学习和从零开始学习进行对比实验。从零开始训练的损失比迁移学习的损失更小且平均精确度更高,从零开始训练的性能明显优于迁移学习。在不同X光数据集中训练的模型可转移,但模仿违禁品的金属物品容易被检测为违禁品[52]。由于不同X光成像设备的成像方式、成像质量以及穿透能力等方面具有差异性,这种差异性导致不同域数据集进行检测时会出现检测精度下降问题。为了解决这个问题,何彦辉等[53]提出一种基于上下文的透射率自适应域对齐方法,使用注意力机制解决不同域数据的颜色差异问题,再将多分率特征对齐,最后使用上下文向量作为对抗训练的正则化,利用邻域信息提高检测精度,但小目标、颜色相近物体重叠,容易出现误检。
3.8 语义分割
深度学习目标检测算法能提供目标的位置和分类信息,但不能提供目标的形状信息,若能将目标形状划分出来将更有利于违禁品的检测工作。Xu等[54]提出将图像分割和注意力机制结合来获取违禁品位置、类别、形状信息,但其定位精度不高,检测速度也相对较慢。语义分割将图像中的每一个像素都进行分类,因此不仅可提供目标的位置信息,还能提供目标的形状信息。An等[55]将语义分割算法应用在违禁品检测任务中,提出一种通道注意和空间注意结合的双重注意分割网络。双重注意的使用能有效提高平均交并比(mean Intersection over Union,mIoU)。该方法能获得精确的分割结果,但其分割速度较慢,多目标检测受限。苏志刚等[56]使用语义分割算法进行违禁品检测,使用空洞空间金字塔卷积模块和注意力机制提升模型的特征提取能力,同时使用1×1卷积轻量化模型,提升模型的效率,分割网络有效地将X光图像中的多目标分割出来。Chouai等[57]提出CH-Net,将深度卷积网络与对抗式自编码器结合起来,其中编码器通过压缩图像产生一个潜在空间,该潜在空间中的所有特征都不相关,使得每个特征都捕捉到输入图像的一个独特的、特定的特征,有效提高语义分割的效果。对于颜色信息不丰富的X光图像,加入灰度通道进行训练也能提高训练效果。Kim等[58]在U-Net的基础上提出O-Net,加入灰度图像,使用两个编码器和两个解码器分别处理彩色图和灰度图,使神经网络的输出性能最大化,其分割得到的目标检测精度优于YOLOv3,但模型结构更复杂,参数更多。
3.9 数据增广
深度学习模型效果与数据的丰富度有极大的相关性,在一定程度上可认为数据决定模型可发挥的最优性能。X光图像的获取十分困难,但是单单使用实验收集到的数据不足以让深度学习模型充分学习图像特征,因此数据增广也是极为重要的一环。X光图像在进行数据增广时需要考虑其特性、图像数量以及多样性才能获得理想的效果[59]。Saavedra等[60]基于X射线的吸收定律叠加不同层的违禁品,使用孤立的违禁品和无违禁品图像合成极为真实的违禁品X光图像,同时使用GAN模型生成X光图像,然后再进行图像合成,但仅对单能X光图像进行实验。使用GAN模型生成的图像来扩展数据有利于目标检测模型发挥更好的检测性能[61]。使用GAN进行图像增广时不仅需要考虑增广的数量,还要考虑增广的数据多样性。Yang等[62]利用空间直角坐标系对获得的项目图像进行姿态分类,利用GAN生成具有新形状、颜色或姿态的X光图像,但生成的图像存在扭曲、失真等情况。利用普通光学图像与X光图像的映射关系进行图形增广能更有效地丰富数据增广后的多样性。Zhu等[63]提出了一种基于Cycle GAN将物品自然图像转换为X光图像的方法,丰富新图像的多样性,包括物品的形状和姿态,然后生成的违禁品图像与背景图像结合,合成新的X光安检图像,但是生成的图像会出现扭曲变形。
近年来基于深度学习的X光图像检测研究大幅度增加,深度学习在该领域表现出不错的性能。研究者们在网络改进、引入新的模型、提出针对X光图像特点的方法等方面做出巨大贡献。表3从异常分类、目标检测、语义分割、数据增广方面对已有关于深度学习的X光图像违禁品研究工作做出总结。

表3 深度学习的违禁品X光图像检测应用总结Table 3 Summary of applications of X-ray image detection of prohibited item based on deep learning
4 总结和展望
X光安检技术为公共安全提供重要保障,但其巨大的工作量使自动安检成为研究热点。基于深度学习的检测技术有效推动了X光图像违禁品检测的发展。目前X光图像违禁品检测领域正处于快速发展阶段,越来越多的研究将深度学习算法应用于X光图像违禁品检测并取得大量成果。本文首先介绍X光成像特点和传统机器学习检测方法,详细介绍深度学习模型在X光图像违禁品检测中的应用,接着对X光违禁品检测技术进行分析总结。结合目前X光图像目标检测与深度学习的发展方向,总结出未来值得关注的研究点。
(1)模型部署
目前学术上的研究成果很多,从分类、目标检测、语义分割、数据增广等方面取得大量成果,但是在模型部署上的研究却极少。主要原因在于目前的研究一般是在自制或公开的少量数据集中进行的,没有应用于真实的公共场所中,用于训练的数据集中的违禁品种类和类型远远少于现实中可能出现的违禁品。深度学习模型对没有训练过的数据难以识别,同时X光图像训练数据少而目前的深度学习模型层数已相当深,导致训练时容易出现过拟合现象。现阶段将深度学习模型部署到真实环境中进行违禁品检测仍相当有难度,有大量难题需要在部署过程中克服,但模型部署是最后也是真正体现模型价值不可缺少的环节,因此在模型部署上需要进行大量的研究和实验。
(2)针对X光图像设计模型和训练模式
大多数算法是在已有模型上进行改进,这些模型设计时针对的对象是光学图像,但是X光图像和光学图像有较大差异,仅改进模型结构难以获得突破性的进展。如何针对X光图像背景复杂、遮挡严重、颜色细节信息少、轮廓信息明显等特点,设计有针对性的特征提取算法与深度学习检测模型还需更进一步地研究。此外,目前的研究中大部分都使用了从光学图像中预训练好的权重进行迁移学习,但迁移学习会限制模型的检测性能[1,51]。从零开始学习可更有效发挥模型性能,应研究有效的从零开始学习模型或开发适用于X光图像的预训练权重提高目标检测性能。
(3)结合大数据技术建立数据库
X光图像不像普通光学图像那么容易收集,而且违禁品的类型和种类繁多,难以使用实验的方法进行收集,虽然目前可用图像变换和生成对抗网络进行数据增广,但其数据多样性通常低于训练数据集多样性。目前大数据技术已得到广泛的应用,如何将大数据技术部署于公共场所建立庞大现实数据库,并将其中每一种违禁品进行标记以推动X光图像违禁品自动检测领域的发展是值得研究的问题。(4)结合更先进的X光技术
X光透射技术可轻易获取物体的形状信息,但其特别的成像原理导致成像容易出现细节特征信息丢失、颜色信息丢失、重叠和遮挡等现象,给多目标检测带来阻碍。CT技术可获取物体形状、原子序数、密度等有用信息,使用先进的静态CT技术可实现高速安检[64],多能、多角度X光设备可采集更多有用信息,这些信息有利于违禁品检测,如何结合先进的X光技术准确快速检测是值得关注的重点问题。
