基于弱监督学习的目标检测研究进展
2021-08-19权冀川梁新宇王中伟
杨 辉,权冀川,梁新宇,王中伟
1.陆军工程大学 指挥控制工程学院,南京210007
2.中国人民解放军73658部队
目标检测算法的研究有着近二十年的历史,由最初检测线段,逐步发展到检测人脸、行人等常见目标,到现在检测复杂的、形态各异的目标。近年来,由于目标检测技术的不断完善,计算机硬件设备的不断发展,目标检测已经逐渐应用到人们的生产生活中,例如在视频监控[1]、自动驾驶系统[2]、人脸识别系统[3]、医学图像目标检测[4]等领域具有非常多的应用。
传统的目标检测算法主要由三步骤组成,区域选择、特征提取和分类器设计。首先是在图像上选择候选区域,得到多个大小不一的候选框,再对每个候选区域进行特征提取,然后将提取到的特征放入分类器中进行类别判断和回归处理,得到最终的检测结果。这种检测算法的效果并不理想,检测效率低,计算复杂度高。
2014年文献[5]将深度学习方法用在目标检测任务中,相比于传统目标检测算法,该方法取得了惊人的效果。此后,基于深度学习的目标检测算法逐渐成为主流的方法。然而,该类模型的检测结果严重依赖于候选区域的数量和质量,检测速度较为缓慢。针对这个问题,文献[6-9]提出了相应的算法,在很大程度上提高了检测速度。近几年,YOLO[10-13]、SSD[14]、RetinaNet[15]等一阶段算法也在不断发展,进一步提高了检测速度,但是检测精度有所降低。
尽管上述强监督目标检测算法已经取得了很好的效果,但强监督目标检测算法模型需要在大规模标注精度高的数据集上进行训练,检测结果严重依赖于数据集标注的精度。目前的数据集标注工作主要是靠人工完成,而人工标注在很大程度上容易受人的主观因素影响,很难获得大规模的且标注精度高的数据集。同时,很多特殊领域也很难获得大规模的数据集,例如军事领域。若采用强监督算法实现这些领域的目标检测任务,则很难训练出检测效果好的模型。目前,数据集标注的成本越来越高,如何在低成本标注的数据集上取得良好的检测结果已成为研究的热点。大量学者开始研究基于弱监督学习的目标检测算法。弱监督目标检测算法只需要带有图像级标签的数据集就能实现目标检测。因此,与强监督目标检测算法相比,弱监督目标检测算法具有更强的适应能力。
本文对算法进行详细介绍,并分析对比了各类算法的检测性能。在此基础上,进一步对弱监督目标检测算法的发展方向进行了总结与展望。
1 弱监督目标检测算法框架
目前主流的弱监督目标检测算法都是在卷积神经网络的基础上实现的,算法流程如图1所示。按照不同的特征处理方法可以将基于卷积神经网络的弱监督目标检测算法归为以下四类:基于多示例学习的弱监督目标检测算法;基于类激活图的弱监督目标检测算法;基于注意力机制的弱监督目标检测算法;基于伪标签的弱监督目标检测算法。

图1 弱监督目标检测算法流程Fig.1 Weakly supervised object detection algorithm flow
1.1 基于多示例学习的弱监督目标检测算法
目前针对弱监督目标检测任务,主流的方法离不开多示例学习(Multi-Instance Learning,MIL)的思想。在多示例学习[16]中,可以把每张只带有图像级标注的图片看作一个包,把图片中的分割区域看作一个示例,包由多个示例组成。若包中至少有一个示例包含目标物体,则该包为正包,否则该包为负包。该算法仅需对包进行类别标注,而不需要对更细粒度的示例进行类别标注,最终目的是对新的包或者新的示例给出类别和位置预测,其算法流程如图2所示。

图2 MIL算法流程Fig.2 MIL algorithm flow
尽管多示例学习的方法能够在标签信息不足的情况下实现目标检测,但多示例学习的效果依赖于潜在变量的初始化情况。如果潜在变量没有被正确初始化,模型将陷入局部最优解,从而影响模型的检测性能。为了缓解模型陷入局部最优解的非凸性问题,可以采用空间正则化[17]、上下文信息[18-19]和渐进细化[20-22]等方法。
文献[17]提出了一种基于Clique的最小熵模型作为正则化器,以减轻多示例学习过程中的局部随机性。同时,提出了一种递归学习算法,将图像分类和目标检测结合起来,然后逐步优化分类器和检测器。在文献[18]中,上下文模型通过降低目标具有显著特征部位的置信度,提高目标其他区域特征的置信度,以此来提高多示例学习的检测精度。文献[19]提出具有周围分割上下文的紧密框挖掘算法(Tight box mining with Surrounding Segmentation Context,TS2C),利用弱监督分割方法获得周围分割上下文来抑制交并比(Intersection-Over-Union,IOU)低的候选框,并提高候选框的IOU。通过这种方法,可以发现IOU高的候选框,从而学习更好的目标检测器。文献[21]将在线示例分类器精化算法与多示例学习网络集成在一起,提出一种生成候选框集群的方法,通过迭代过程学习形成精炼的示例分类器。同一集群中的示例在空间上相邻并且与同一目标相关联,这样可以避免网络的注意力集中在目标的一部分而不是整个目标上。
也有学者从以下几方面对上述问题进行优化。Wan等[23]提出了连续多示例学习(Continuation Multiple Instance Learning,C-MIL)算法。该算法引入了延拓方法,通过平滑损失函数并将其转化为多个更容易的子问题来解决复杂的优化问题,将其转化为多示例学习,从而创建延拓多示例学习,目的是以系统的方式缓解非凸性问题。Chen等[24]提出了一种空间似然投票(Spatial Likelihood Voting,SLV)模块,在没有任何边界框注释的情况下使目标定位的过程得以收敛。同时,也提出用于多任务学习的端到端的训练框架,让分类和定位任务相互促进,提高检测性能。Ren等[25]提出一个示例感知和聚焦上下文的统一框架,引用“Concrete Drop-Block”的参数空间缺失模块,通过最大化检测目标,使整个框架聚焦上下文信息而不是专注最有区别的部分,进而提高检测精度。Zhang等[26]提出了一种之字形学习策略,采用平均能量累积得分(mean Energy Accumulation Scores,mEAS)的标准,自动测量和排序包含目标物体的图像的定位难度。首先让模型训练简单的图像,使模型获得一定的学习能力后再训练困难的图像,从而获得检测能力更强的模型。Lin等[27]提出了一个端到端的目标示例挖掘(Object Instance Mining,OIM)框架来解决这个问题。该框架基于两个假设:具有最高置信度的候选框和与其高度重叠的候选框属于同一类别;同一类别的物体具有很高的外观相似度。在框架形式上,构建了空间图和外观图,并用于挖掘图像中所有可能的目标示例。其中,空间图旨在对最高置信度候选框与其周围候选框的空间关系进行建模,而外观图旨在捕获与最高置信度候选框具有高度相似外观的所有可能的目标示例。
1.2 基于类激活图的弱监督目标检测算法
卷积神经网络各层的卷积单元实际上都充当着目标检测器的角色,尽管在卷积层中具有定位目标的显著能力,但是当使用全连接层进行分类时,此功能会丧失[28]。针对该问题,Zhou等[29]提出全局平均池化层的优势超出了仅作为正则化器的范围,只需稍做调整,卷积神经网络就可以保留其卓越的定位能力。文献[29]使用类似GoogLeNet算法[30]中的网络体系结构,网络主要由卷积层组成,在最终输出层之前,采用全局平均池化层代替全连接层,并将卷积特征图输入分类器进行目标分类。通过这种连通性结构,可以将输出层的权重映射到卷积特征图上确定图像区域的重要性。该技术称为类激活映射,使用该技术进行目标检测的方法属于基于类激活图的弱监督目标检测算法,其算法流程如图3所示。

图3 类激活图算法流程Fig.3 Class activation map algorithm flow
使用类激活图(Class Activation Map,CAM)可在仅有图像级标签的数据集上实现目标检测。CAM方法作为弱监督方法被广泛应用。早期的基于CAM的目标检测算法检测精度不高,只能定位到目标具有显著特征的部位。
为了提高该类算法的检测精度,大量学者在该方向做出了贡献。Cheng等[31]结合SSD算法和Dense-Net[32]算法的思想,提出层次显著图检测网络。该算法包括层次类激活图(Hierarchical-Class Activation Map,Hierarchical-CAM)和层次空间金字塔显著图(Hierarchical-Spatial Pyramid Saliency Map,Hierarchical-SPSM)。层次显著图用于在输入图像中定位目标,与CAM或SPSM相比,可以提高定位精度。Benassou等[33]利用网络的泛化能力,并使用干净的示例和对抗性示例训练模型以定位整个目标对象。对抗性示例是添加了扰动的图像,通常用于训练鲁棒模型。经过对抗性示例训练的CNN可以检测到更多的可区分目标的特征。同时,将信息熵应用于网络生成的CAM,以在训练过程中对其进行指导。Diba等[34]提出一种两阶段级联CNN(2-Stage Cascaded CNN)算法。第一阶段提取特征并创建类激活图,以便为每个目标示例创建一些候选框。第二阶段在候选框中选择最佳边界框,以通过多示例学习损失来学习目标分类。该算法在一定程度上提高了弱监督目标检测的性能。
由于图像级标注的数据不存在真实框,通过选择性搜索生成的候选框的IOU值较低,进而导致训练得到的模型检测精度不高。为了解决此问题。Cheng等[35]将选择性搜索与梯度加权的类激活映射(Gradient-weighted Class Activation Mapping,Grad-CAM)技术相结合,可以比基于贪婪搜索的方法生成更多高IOU的候选框。在候选框选择时,对于每一个目标类别,选取尽可能多的正样本的同时,只选择类别明确的困难负样本。通过上调损失,在训练中关注更具判别性的负候选框,提高训练效果,得到检测精度更高的模型。Du等[36]针对分类器的细化在开始时高度依赖于初始候选框质量的问题,提出了一种弱监督目标检测分类器细化方法。该方法可以获取目标的高质量特定类的激活图,并在激活图的最大响应点生成钉盒,以抑制错误的细化方向。在多次迭代训练后得到精炼的分类器,从而提高目标检测的性能。
当前的CAM方法存在以下三个基本问题:全局平均池化层偏向将较高的权重分配给具有较小激活区域的通道;目标区域内部的负加权激活;由于使用类激活图的最大值作为阈值参考产生不稳定性,从而导致只能定位到目标对象的小部分区域。针对此问题,Bae等[37]提出了三种简单但有效的技术来缓解此问题,包括阈值平均池化、负权重夹紧和百分位数作为阈值标准,该方法大幅度提高了检测性能。
1.3 基于注意力机制的弱监督目标检测算法
注意力模型(Attention Model,AM)[38]最初用于机器翻译,现在已成为神经网络领域的一个重要概念。注意力机制作为神经网络结构的重要组成部分,在自然语言处理、统计学习、语音处理和计算机视觉等领域有大量的应用。深度学习中的注意力机制和人类的选择性视觉注意力机制类似,核心目标都是从众多信息中选择出对当前任务目标更关键的信息。注意力机制在强监督目标检测算法中已得到广泛应用,且取得了很好的效果。同样,注意力机制也可以用于弱监督目标检测算法,其算法流程如图4所示。
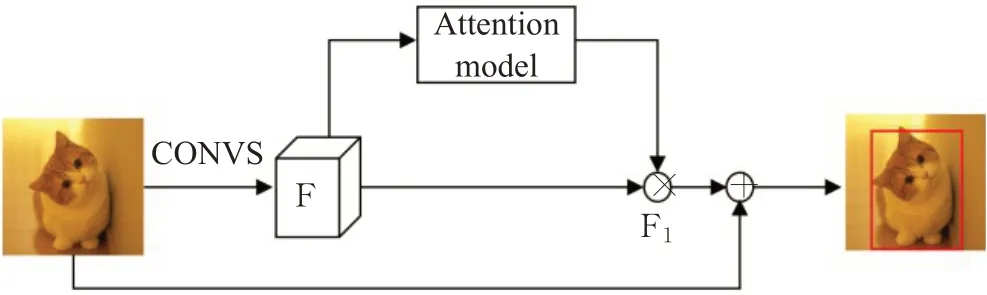
图4 注意力机制算法流程Fig.4 Attention mechanism algorithm flow
注意力机制分为软注意力机制和硬注意力机制,在软注意力机制中每个权重的取值范围为0到1之间,在硬注意力机制中每个权重的值取0或1,也就是网络只注意某几个特定的点,且权重均为1。常用的注意力机制为软注意力机制,其从原理上可分为空间注意力模型、通道注意力模型、空间和通道混合注意力模型三种。
空间注意力模型只注意和任务相关的区域,比如在分类任务中,模型就是寻找网络中最重要的部位进行处理。通道注意力机制通过建模确定各个通道的重要程度,然后针对不同的任务增加或抑制不同的通道。空间和通道混合注意力模型分别学习了通道的重要性和空间的重要性,该模块可以很容易地嵌入到任何已知的框架中。
因为空间和通道混合的注意机制不仅可以注意到图像中重要的部位,还可以给重要通道分配更大的权重,所以该注意力机制在弱监督目标检测中被广泛利用。本文所列举的基于注意力机制的弱监督目标检测算法中所用的注意力模型都是空间和通道混合的注意力模型。The等[39]提出了一种注意力网络的神经网络架构。给定图像中的一组候选区域,注意力网络首先计算每个候选区域的注意力得分。然后将这些候选区域与它们的注意力得分组合在一起,形成整个图像的特征向量。该特征向量用于对图像进行分类,并通过注意力得分实现目标定位。Yang等[40]提出了单一的端到端弱监督目标检测网络,该网络可以共同优化区域分类和回归。同时,加入指导分类的注意力机制模块增强特征学习的定位能力,从而显著提高目标检测的性能。Choe等[41]提出了一种基于注意力的丢弃层(Attentionbased Dropout Layer,ADL)方法,利用自我注意机制来处理模型的特征图,去除目标对象中最具区分性的部分,让模型能够学到目标对象其他的特征。该方法包括两个关键部分:在模型中隐藏最有区别的部分,以捕获对象的整体范围;突出有用信息的区域,以提高模型的识别能力。Gao等[42]提出了一种考虑网络注意力和全局上下文信息的端到端弱监督目标检测算法。该算法采用轻量级的级联注意丢弃模块(Cascade Attentive Dropout Module,CADM)帮助网络学习更全面的特征。同时,引入改进的全局上下文模块,以更有效的特征融合方式增强学习能力,从而共同优化区域分类和定位。
1.4 基于伪标签的弱监督目标检测算法
当数据集中存在大量未标注的数据时,可以采用基于伪标签的弱监督目标检测算法来改善检测效果。首先对图像级标注的数据集提取特征,形成相应的伪标签,然后将带有伪标签的数据反向传入卷积神经网络,最后训练得到目标检测模型,实现目标的定位与分类,其算法流程如图5所示。
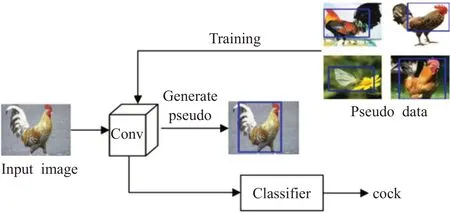
图5 伪标签算法流程Fig.5 Pseudo algorithm flow
Zhang等[43]提出了一个从弱监督到强监督的框架,采用伪标签真实性挖掘(Pseudo Ground-truth Excavation,PGE)算法从图片的每个示例中挖掘伪标签。此外,采用伪标签真实性调适(Pseudo Ground-truth Adaptation,PGA)算法,进一步从PGE中提高伪标签的真实性。最后,使用这些伪标签训练一个强监督的检测器。Zhang等[44]提出了一种伪标签挖掘(Pseudo Ground Truth Mining,PGTM)算法,在训练数据中自动找到未标记实例的缺失边界框。然后,结合挖掘到的伪标签和标记注释共同训练强监督目标检测器。同时,提出了一种增量学习(Incremental Learning,IL)框架,逐步合并经过训练的强监督检测器的结果,以提高缺少边界框的物体的检测性能。
Zhang等[45]提出伪监督对象定位算法(Pseudo Supervised Object Localization,PSOL),证明弱监督的目标定位应该分为两部分:与类无关的目标定位和目标分类。对于与类无关的目标定位,应该使用与类无关的方法生成带有噪声的伪标签,然后在没有类别标签的情况下对它们执行边界框回归。Zhong等[46]提出了知识迁移(Knowledge Transfer)框架,借助外部带有标签信息的源数据集提高弱监督目标检测的准确性。该算法通过一类通用检测器(One-Class Universal Detector,OCUD)迭代地从源域迁移知识,并用于学习目标域检测器。同时,目标域检测器在每次迭代中挖掘的伪标签可有效改善OCUD。两者相互作用,从而提高了检测精度。为了从可区分的局部目标对象部分中发现完整的目标区域,Zhang等[47]提出一种顺序搜索策略,构建了基于深度强化学习(Deep Reinforcement Learning,DRL)的完整区域搜索模块实现弱监督目标检测任务,并建立了弱监督的增强搜索代理学习(Reinforcement Searching-Agent Learning)框架,使用特征一致性分析和特征激活映射生成伪标签,学习所需的搜索代理。
综上所述,表1总结了四类弱监督目标检测算法的机制,并对每类算法的优点和缺点进行了比较。
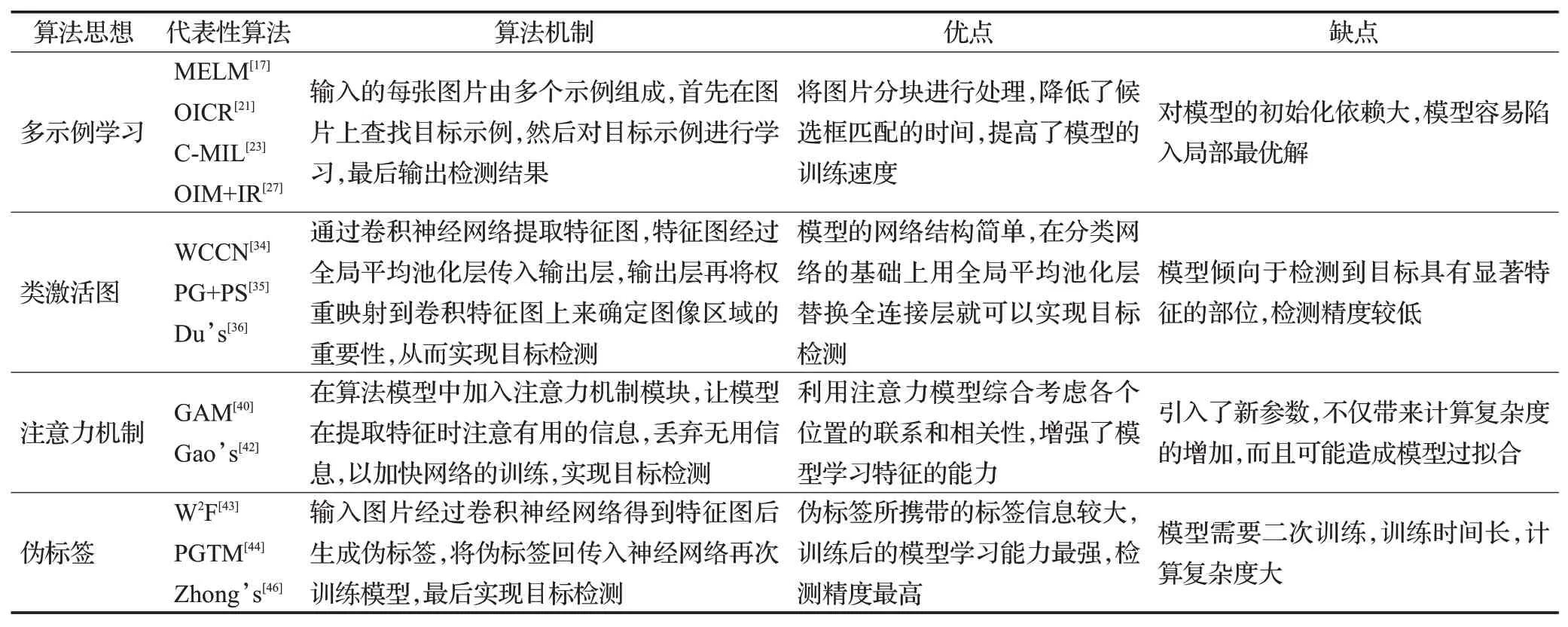
表1 弱监督目标检测算法优缺点比较Table 1 Comparison of weakly supervised object detection algorithms
2 实验分析
2.1 数据集
当前通用目标检测任务中流行的数据集有PASCAL VOC 2007[48]、PASCAL VOC 2012[49]、ImageNet[50]、MS-COCO[51]等。
PASCAL VOC数据集常用于图像分类、图像分割、目标检测等任务,其中PASCAL VOC 2007数据集和PASCAL VOC 2012数据集主要用于目标检测。它们包含20个对象类别,例如人、自行车、鸟、瓶子、狗等。
ImageNet数据集用于图像分类、目标检测和场景分类等任务,包含约1 420万张图片,22 000个类别。对于目标检测任务,它是一个具有200个对象类别的重要数据集。
MS-COCO数据集用于目标检测、语义分割、人体关键点检测和字幕生成等任务。对于目标检测任务,它是挑战性最大的数据集之一。该数据集的目标大部分来自于自然场景,包含日常复杂场景的图像,而且使用更加严格的评估标准,要求算法具有更精确的定位能力。
表2 从类别、训练集、验证集、测试集四方面对上述数据集进行了对比。
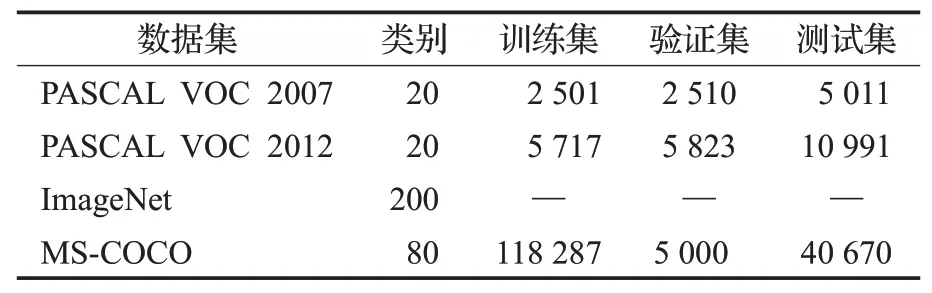
表2 数据集对比Table 2 Data set comparison
本文所列举的弱监督目标检测算法大多采用PASCAL VOC 2007数据集和PASCAL VOC 2012数据集作为算法的数据集,仅少数算法采用了MS-COCO数据集中的部分数据作为算法的训练数据集。主要原因是PASCAL VOC数据集中物体种类较少,数据集相对简单。MS-COCO数据集中物体种类多,且小目标物体所占数量大,数据集较为复杂。同时,主流的强监督目标检测算法在MS-COCO数据集上的检测精度都较低,平均检测精度一般不超过50%。而弱监督目标检测算法的检测精度远低于强监督目标检测算法,在MS-COCO数据集的检测精度非常低,平均检测精度一般不超过20%。下文详细比较与分析了四类弱监督目标检测算法中主流的算法在PASCAL VOC 2007数据集上的检测结果。
2.2 评价指标
常用的目标检测评价指标包括精确率(Precision)、召回率(Recall)、平均精确率(Average Precision,AP)、mAP(mean Average Precision)、定位准确率(CorLoc)等。
假设用P表示精确率,其计算公式如下:

式(1)中,TP(True Positives)是正样本被正确识别为正样本的数量,FP(False Positives)是负样本被错误识别为正样本的数量。
假设用R表示召回率,其计算公式如下:

式(2)中,TP(True Positives)是正样本被正确识别为正样本的数量,FN(False Negatives)是正样本被错误识别为负样本的数量。一般来说,召回率越高,精确率越低。
AP通常用于计算平均的检测精度,衡量检测器在每个类别上的性能好坏;而mAP则更多用于评价多目标的检测器性能,衡量检测器在所有类别上的性能好坏,即得到每个类别的AP值后再取所有类别的平均值。
CorLoc值为正确定位的图像数量占所有图像数量的百分比,其计算公式如下:

式(3)中,TP、FP和类别无关,只和位置有关。
本文主要选取mAP值和CorLoc值。因为目标检测模型中的分类和定位都需要进行评估,并且每个图像都可能包含不同类别的不同目标,所以图像分类问题的标准度量不能用于目标检测问题上,故选用mAP值。此外,对于弱监督学习,因为在标注时没有给出目标的边界框,所以采用CorLoc值作为衡量检测结果的重要标准。
2.3 对比实验结果
本文选取了当前主流的弱监督目标检测算法,在PASCAL VOC 2007数据集上进行了比较。为了确保算法在特征提取过程中的一致性,所有算法均采用在ImageNet数据集上进行过预训练的VGG16[52]算法作为特征提取的主干网络。在特征处理阶段各个算法的处理方式不同,导致算法在参数设置上面存在较大差异。其中OCIR、MELM、C-MIL、OIM+IR属于基于多示例学习的弱监督目标检测算法;WCCN、Du’s、PG+PS属于基于类激活图的弱监督目标检测算法;GAM、Gao’s属于基于注意力机制的弱监督目标检测算法;W2F、PGTM、Zhong’s属于基于伪标签的弱监督目标检测算法。表2列出了弱监督目标检测算法对数据集中所有物体目标检测的平均精确率。基于多示例学习算法的检测结果在50%左右;基于类激活图的算法检测最好的结果为51.1%;基于注意力机制的算法检测结果一般不超过50%;而基于伪标签的算法检测结果在52%~60%之间。前三类算法直接在只带有弱标签的数据集上对模型进行训练,导致模型无法学习较为完整的知识,学习能力较弱,影响模型的检测精度。而基于伪标签的弱监督目标检测算法针对弱标签数据集首先生成带有伪标签数据,并将伪标签数据回传到卷积神经网络中再次训练,从而可使模型学习到更多的信息,提高了模型的学习能力。因此,基于伪标签的弱监督检测算法的检测精度比前三类算法都高。
由表3可知,在aero、bus、car、train、tv等物体目标上往往会取得较好的检测结果,其平均精确度一般在60%以上;而在bottle、person等物体目标上的检测精度较低,一般不超过30%。造成这一现象的主要原因是,由于前一类物体目标在图像中所占像素区域较大,经过卷积神经网络多次下采样后仍然可以提取到特征;而后者均属于小尺度目标物体,在图像中所占像素区域较小,经卷积神经网络多次下采样后很难再提取到特征。通过比较发现,不同类别的算法对于小尺度目标物体的检测精度也有较大差别。例如,Du’s基于类激活图的弱监督目标检测算法对于person目标检测的平均精确率为29.5%,比基于多示例学习的弱监督目标检测算法高出15个百分点左右。因为该算法通过多次迭代训练得到了更精炼的分类器,从而提高了对小尺度目标的检测精度。Zhong’s基于伪标签的检测算法也可在很大程度上提高对bottle、person等小尺度目标的检测精度,该算法检测的平均精确率为59.8%。主要原因是,生成的伪标签数据可以有效减少小尺度目标在池化过程中的信息丢失。

表3 主流算法在VOC 2007数据集上的mAP对比Table 3 mAP comparison of mainstream algorithms on VOC 2007 dataset %
表4 列出了上述目标检测模型定位准确率CorLoc的比较结果。基于多示例学习算法的定位准确率在60%~68%之间;基于类激活图算法的定位准确率不超过70%;基于注意力机制算法的定位准确率在70%左右;基于伪标签的弱监督目标检测算法的CorLoc数值均在70%以上,高于其他类别的算法。
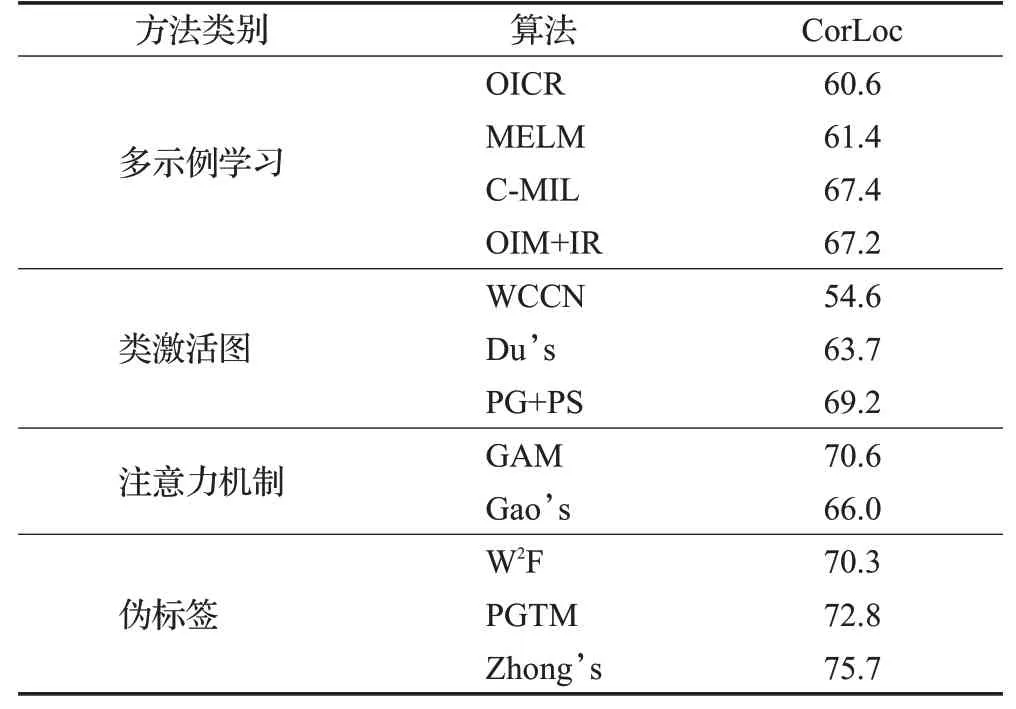
表4 主流算法在VOC 2007数据集上定位准确率的比较Table 4 Comparison of CorLoc of mainstream algorithms on VOC 2007 dataset %
结合表3的结果,基于伪标签的弱监督目标检测算法不仅具有最高的检测精度,而且具有最高的定位精度,因此该类算法的总体检测效果最好。
表5 列出了主流的强监督目标检测算法与弱监督目标检测算法在数据集PASCAL VOC 2007上mAP值的对比,本文主要选取了C-MIL、PG+PS、Zhong’s三种弱监督目标检测算法。另外,选取了Faster R-CNN[8]和SSD两种强监督目标检测算法。
从表5中可以看出,弱监督目标检测算法的mAP值都在60%以下,而强监督目标检测算法的mAP值在70%左右。尽管弱监督目标检测算法降低了算法对数据集标注的要求,但是其检测精度远远低于强监督目标检测的检测精度。同时,Zhong等人提出的弱监督检测算法在bus、car、cat等物体(此类物体在图片中所占像素比例大)上的检测精度与强监督目标检测算法的检测精度非常接近,该算法在只有图像级标注的弱标签上生成了标签信息更强的伪标签数据,再利用生成的伪标签数据训练模型。此方法不仅减少了标注的成本,也没有降低模型在大目标物体上的检测精度。总而言之,尽管弱监督目标检测算法已经取得了不错的成绩,但是与强监督目标检测算法还存在较大的差距,其依然有很大的提升空间。

表5 弱监督目标检测算法与强监督目标检测算法的比较Table 5 Comparison of weakly supervised object detection algorithm and strongly supervised object detection algorithm %
3 结束语
随着深度学习理论和方法的发展,强监督目标检测算法在通用数据集上取得了较好的效果。但基于弱监督学习的目标检测问题本身仍面临很多困难和挑战,其检测精度与强监督算法相比还有很大的差距。总结前面对各种弱监督目标检测算法的讨论分析与实验结果可见,在弱监督目标检测问题上已经出现了一些很有价值的研究方向,具体包括:
(1)基于伪标签的弱监督目标检测算法。在上述四类弱监督目标检测算法中,基于伪标签的弱监督目标检测算法取得了最好的效果。目前,该类算法生成的伪标签数据与人工标注的标签数据存在一定的差距。如何获取真实性更高的伪标签数据,进一步提高该类算法的检测精度是未来研究的重点。可首先让网络生成伪标签数据,其次用伪标签数据训练模型,再把原始数据输入训练后的模型得到真实性更高的伪标签数据,最后用新的伪标签数据再次训练模型,以此来提高模型的检测精度。
(2)强监督与弱监督结合的目标检测算法。如何缩小弱监督目标检测算法与强监督目标检测算法之间的检测精度差距是未来研究的热点。可以重点研究强监督与弱监督相结合的协同学习[53]方法。将强监督学习网络和弱监督学习网络集成到端到端的架构中作为两个子网,在前后迭代中共同学习的方法就是协同学习。文献[53]将弱监督学习网络和强监督学习网络连接成为一个整体网络,通过一致性损失(Consistency Loss)约束强监督和弱监督学习网络使其具有相似的预测结果,通过强监督学习网络和弱监督学习网络间部分特征共享保证两个网络在感知水平上的一致性,从而实现强监督学习网络和弱监督学习网络的协同增强学习。此方法不仅可以提高弱监督目标检测算法的检测精度,也可用于提高强监督目标检测算法的性能。
(3)中小尺度目标的弱监督目标检测算法。弱监督目标检测算法在大尺度目标上已取得较好的检测精度,但是在中小尺度目标上检测精度还很低,提高弱监督目标检测算法在中小尺度目标上的检测精度是未来需要解决的问题。可以借鉴强监督目标检测算法中提高小尺度目标检测精度的方法。①在检测算法模型中加入多尺度特征融合网络。卷积神经网络的多层结构可以自动学习不同层次的图像特征,低层特征图保留了图像边缘、轮廓、纹理等局部细节信息,有利于目标定位;高层特征图则包含更加抽象的语义信息,有利于目标分类。多尺度特征融合网络通过自上而下的横向连接将低层特征与高层特征相互融合,构建具有细粒度特征和丰富语义信息的特征表示,融合后的特征具有更强的描述性,有利于小目标检测。②在算法模型中加入注意力机制模块。注意力机制的本质是快速找到感兴趣区域,忽略不重要的信息。通过注意力机制重点关注中小尺度目标物体区域,使模型更好地学习中小尺度目标物体,以此提升小目标的检测效果。
(4)面向小样本数据集的弱监督目标检测算法。在军事、医疗等领域很难获得大规模的数据集,而样本数量不足会严重影响训练效果或者导致训练出来的模型泛化能力不足,最终导致弱监督目标检测算法的精度降低。因此,如何解决数据集规模过小的问题是弱监督目标检测面临的重大挑战之一。①采用数据增广的方法扩大数据集的规模,主要是增加训练数据集,使数据集尽可能多样化,使训练的模型具有更强的泛化能力。目前常用的数据增广方法主要包括水平或垂直翻转、旋转、缩放、裁剪、平移、对比度调整、色彩抖动、增添噪声等。②采用小样本学习中的元学习[54](Meta Learning)方法。元学习的思想是利用大量跟目标任务相似的任务来训练一个元学习器(Meta Learner),然后作用到目标任务上获得一个不错的模型初值,从而能够仅利用目标任务的少量数据对模型进行快速适配。
