融合K-means和RBF神经网络的汉字识别算法∗
2021-08-08黄树成
杨 恺 黄树成
(江苏科技大学计算机学院 镇江212000)
1 引言
随着智能手机、数码相机等电子设备的普及,人们获取图像的手段越来越多。面对海量图像数据,基于图像内容的分析、检索和理解越来越引起人们的关注,汉字识别也变得越来越重要。
为了能够有效定位图像中的文字区域,近代学者提出了很多优秀的文本定位算法,如Kim[1]通过将图像进行分块,然后再结合支持向量机的方法,对文字范围进行划分;Bertini[2]通过计算图像角点特征,并进行深一步地归纳提取,然后区分出图像中的文字范围;Hyeran[3]采用了一种基于数学形态学的方法,通过提取图像形态学特征,来定位出图像中文字所在的范围等。
我国在2000年开始对彩色图像文字分割技术进行研究,如周源华[4]利用颜色边缘来对彩色图像中的文本进行检测提取;郭丽[5]提出了一种基于颜色边缘点和游程平滑的文本文字提取算法等。
但对于自然场景中拍摄的汉字图像,运用上述算法出现了汉字识别效率低下,错误率高等问题,针对这些问题,本文提出了一种融合K-means和RBF神经网络的汉字识别算法,改进了传统神经网络算法不易收敛的缺点,用实验证明了该算法在汉字识别方面具有较高的准确率和识别效率。
2 相关工作
下面将分别介绍传统RBF神经网络算法,K-means算法和减聚类算法。
2.1 传统RBF神经网络算法
径向基函数神经网络(Radial Basis Function Neural Network,RBFNN),是一种特殊的三层前向神经网络。它具有最佳逼近性能和全局最优特性,网络结构简洁明了、训练快速等优点。
RBF神经网络也是典型的前馈式神经网络,由输入层、隐含层和输出层三层神经元构成。图1为RBF神经网络结构图,由图可以明显看出,其结构与简单的BP神经网络相同,都是三层网络结构。
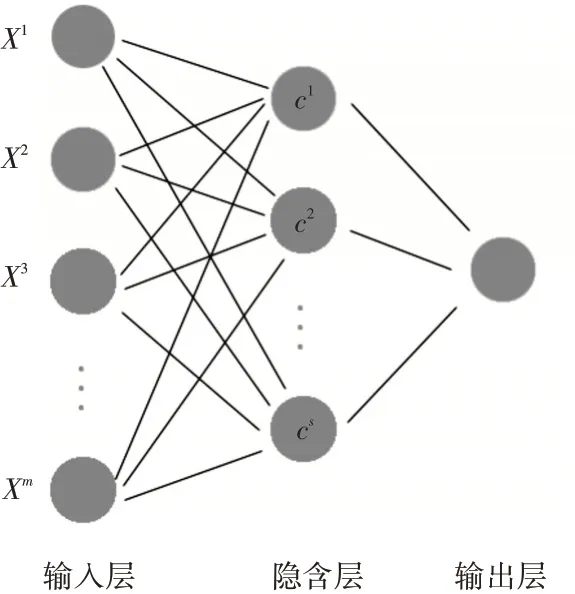
图1 RBF神经网络结构
其中第一层为输入层节点,第二层为隐含层节点,第三层为输出层节点。首先,输入信号通过第一层进入到第二层,然后使用径向基(RBF)函数进行计算,常用的RBF函数有Gauss函数、反演S型函数等,最后第三层利用线性函数计算出结果。
首 先,假 设 训 练 数 据 集 为X={x1,x2,x3,…,xm},其中第i个训练样本为其中,即样本数量为m,特征数为n。如果隐含层节点个数为s,则第i个训练样本xi所对应的隐含层的第j个节点的RBF函数,如式(1)所示:
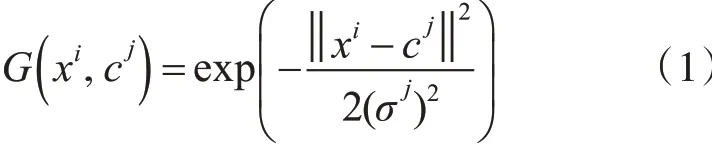
其中cj为隐含层第j个节点的数据中心,σj为该RBF函数的宽度为xi到cj的欧式距离。最后,如果输出层节点的个数为t,输出层对隐含层输出的节点应用线性函数,如式(2)所示:
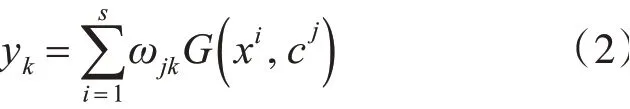
其中k=( )
1,2,3,…,t,s为隐含层节点个数,ωjk为隐含层第j个节点到输出层第k个节点之间的权值。
这里采用Gauss函数作为RBF函数,该函数曲线比较光滑,并且表示形式相对简单,解析性好,有利于对结果进行分析。
在RBF神经网络中,最重要的就是隐含层,具有承前启后的作用。通过确定径向基函数的中心点,就可以确定神经网络输入层与隐含层之间的某种映射关系,这种关系就是构造隐含层的基石。利用该关系可以将输入层的矢量矩阵映射到隐含层空间中,在这其中不需要进行网络调参。然后隐含层将向量从低维度线性不可分,映射到高维度线性可分,并输出线性加权和,在这其中则需要进行网络调参。原来神经网络的输入层到输出层的映射是非线性的,但是通过隐含层的映射,输出层对隐含层有了可调的线性参数。该可调的线性参数即为网络的权值,而权值则可通过线性方程组直接求解出来,这样便极大地提高了神经网络的学习速度,且有效地避免了可能出现的局部极小问题。
2.2 K-means算法
K-means算法的宗旨是计算出最小类内距离,使聚类域内所有样品到聚类中心距离的平方和最小。算法的具体流程如下。
1)随机选k个样本作为聚类中心,计算其他样本点与它们之间的距离,根据最小类内距离原则将各个样本分配到最近的聚类中心;
2)计算k个聚类结果内各个样本的均值,然后根据均值重新选取聚类中心;
3)把重新选取的聚类中心再继续进行聚类计算;
4)重复上述步骤,直到前后两次聚类后的聚类中心相同时停止。
通过上述步骤可以知道:K-means算法容易受到聚类中心的个数和初始聚类中心的选择影响,造成聚类结果的波动,并且极易陷入局部最优解。
2.3 减聚类算法
为了解决K-means算法的上述问题,引入减聚类算法。Chiu[6]提出一种减聚类算法,将每个样本都认为是潜在的聚类中心,然后计算“峰”函数来确定聚类中心。
该算法可以把计算量与样本个数认为是简单的线性关系,使其与问题维度无关,解决了一般聚类算法中容易出现的“维数灾难”问题。同时该方法还可以为其他聚类方法提供初始聚类中心,故在K-means算法中将其引入。
其具体算法步骤如下。
1)给定数据集X,根据式(3)计算每个样本的密度值,密度值越大则该样本的临近包含其他样本数目越多。
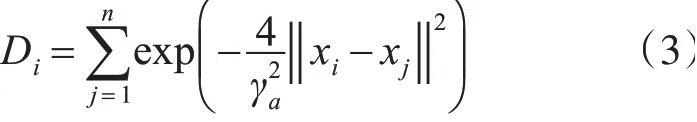
其中,n为数据集X的样本个数,xi为第i个样本,γa∈R+,γa为xi的一个邻域半径。
2)选出步骤1)中最大的密度值Dm1,将对应的样本xm1作为初始聚类中心,再根据式(4)对样本密度值进行更新;
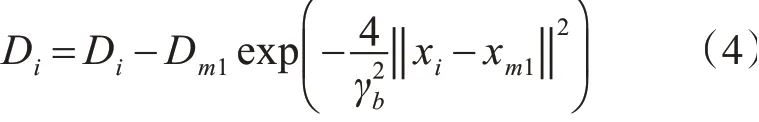
其中:γb=λγa,λ∈R+,γb表示为一个密度指标函数显著减少的邻域,一般λ=1.5。
3)选出步骤2)中最大的密度值Dm2,将对应的样本xm2作为第二个聚类中心,再将Dm2,xm2代入式(4)中,对样本密度值进一步更新,然后选择下一个聚类中心,直到满足式(5)时,终止循环。
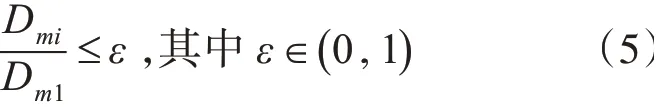
终止循环的物理意义是当前最高密度值与初始最高密度值相比非常小,即当前聚类中心包含极少样本点,则可忽略该聚类中心,结束聚类。
3 融合K-means和RBF神经网络算法
本文的融合K-means和RBF神经网络算法主要是引入减聚类算法来确定K-means算法的初始聚类中心及其个数,再用K-means算法来确定RBF神经网络算法的径向基函数的中心,之后确定径向基函数的宽度以及隐含层到输出层之间的权值,最后输出结果。整体算法框架图如图2所示。

图2 算法框架图
融合K-means和RBF神经网络的汉字识别算法具体步骤如下:
1)使用式(6)对训练数据集进行归一化处理,使样本数据的每一个维度都属于[]

0,1。其中,xmin=0,xmax=255,为彩色图像RGB的最小值与最大值,xij为训练数据集第i个样本的第j个维度数据。
2)通过减聚类算法确定初始聚类中心,具体实现步骤如下:
(1)根据式(3)计算每个数据点的密度值,选取其中最大密度值Dm1的样本点xm1作为初始聚类中心,记s=1;
(2)根据式(4)对数据点进行密度更新,找到当前最大密度值Dmi;
(3)如 果Dmi满 足 式(5),则 转(4);否 则s=s+1,并将具有当前最大密度值的样本点作为第s个聚类中心,转(2);
(4)聚类结束,确定s个初始聚类中心。
3)运用K-means算法进行文字特征类提取。计算所有数据点与聚类中心的距离
k中总的数据个数。
6)如果ck'≠ck,转到3),否则K-means聚类结束,转到7)。
7)根据已知聚类中心之间的距离,通过式(7)来确定RBF神经网络算法隐含层节点的径向基函数的宽度σk。
其中,样本集合gk满足:
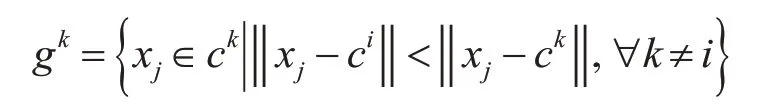
8)确定RBF神经网络隐含层到输入层的权值ωjk。权值可通过梯度下降法来计算得到。
首先记式(8)为RBF神经网络误差函数:
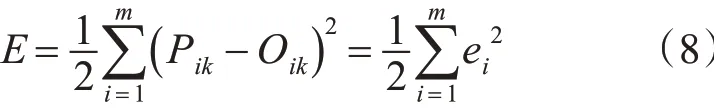
其中Pik为第i个输入节点在第k个输出节点时的实际输出值,Oik为第i个输入节点在第k个输出节点时的期望输出值。
然后采用式(9)确定权值:
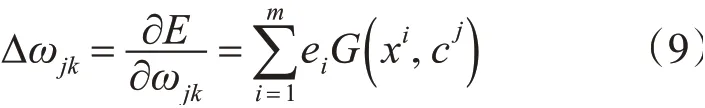
权值ωjk的修正公式为
其中ωjk为第j个隐含层节点与第k个输出层节点之间的权重,ξ为学习率,本文取ξ=0.008。
9)当隐含层节点过多的时候,需要精简隐含层节点。当隐含层节点cj的输出权值满足式(10)时,可以删除该节点。

其中ωmin为最小的临界权值。
4 实验及结果分析
本文选取的数据集为ICDAR 2019大会中,美团联合国内外知名科研机构和学者主办的“中文门脸招牌文字识别”比赛的公开数据集(ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboards,ICDAR 2019 RRCRCTS)。该数据集共25000张图片,每张图片是由完全独立的不同个人、采用不同设备、在不同地点和不同时间和不同环境下所拍摄的不同商家的门脸招牌图片。
该数据集以中文文字为主,标注内容比较完备,每张图片均标注了单个字符的位置和文本,以及各字符串的位置和文本。在这25000张图片中,选取2000张图片用于训练,200张用于验证,300张用于测试。所有实验均采用python语言实现,实验 环 境 为Windows10,python3.6,CPU主 频 为2.70GHz,8G内存,256G固态硬盘。
融合K-means和RBF神经网络算法来进行文字识别,通过对数据集图像中文字部分进行单字划分,然后对单字图像进行特征提取,再匹配训练样本库。本次实验中,准确率为所有单张图片的识别准确率之和的均值,识别效率为单位时间内识别出的正确汉字个数,具体的测试结果如表1所示。
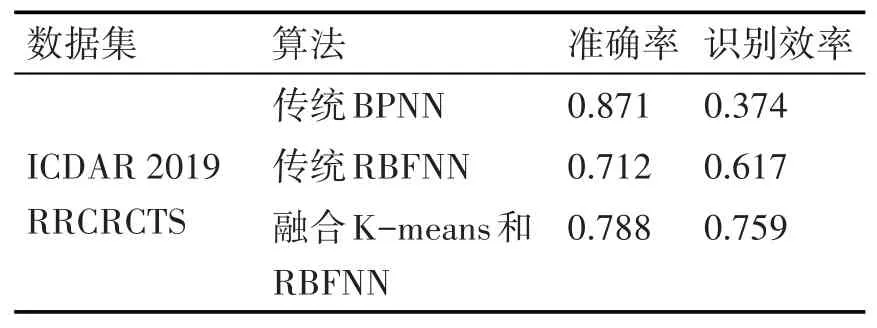
表1 三种神经网络算法识别结果统计
从表1可以看出,在数据集ICDAR 2019 RR⁃CRCTS上,传统BP神经网络算法虽然准确度很高,但识别效率非常低下,而本文的融合K-means和RBF神经网络算法相比于传统的RBF神经网络算法而言,其准确度与识别效率均高于后者。初步实验证明,融合K-means和RBF神经网络算法有着较高的准确率,能有效地提高汉字识别效率,具有一定的实用价值。
5 结语
本文研究了传统RBF神经网络算法和传统K-means算法,在面对传统RBF神经网络算法中分类精度不高和传统K-means算法对初始聚类中心敏感等问题,提出了融合K-means和RBF神经网络的汉字识别算法。首先用减聚类算法改进K-means算法,消除它对初始聚类中心的敏感,防止聚类结果的波动,再用优化后的K-means算法构造RBF神经网络的隐含层节点,提高计算速度。为了验证该算法,本文采用ICDAR 2019 RRCRCTS数据集进行实验,实验结果表明该算法有着一定的优势和实用价值。
