基于自适应粒子群的SVM参数优化研究∗
2021-08-08姜雯吴陈
姜雯吴陈
(江苏科技大学计算机学院 镇江212000)
1 引言
支持向量机(Support Vector Machine,SVM)是Cortes和Vapnik于1995年提出的,SVM在解决小样本,非线性以及高维模式识别中有着显著的优势[1~3]。在支持向量机模型中,惩罚因子C和核参数γ是影响分类结果的主要因素[4]。人工智能算法为启发式算法,即不用去遍历解空间里的所有位置,就可以寻找到问题的最优解,因此能够高效地寻找到最优的SVM参数。传统的人工智能算法有遗传算法[5]、粒子群算法[6]、蚁群算法[7]等。本文采用粒子群算法来优化SVM参数,从而提高SVM的分类性能。粒子群算法是一种基于种群的全局优化方法,具有算法简单,易于实现以及收敛速度快的优点。由于粒子群算法在演化过程中很容易过早收敛并陷入局部最优,目前已经有很多学者提出对粒子群算法进行优化[8~11]。针对传统的粒子群算法在优化支持向量机时存在着易陷入局部最优,分类精度低以及早熟收敛的缺点,本文采取两种方式对粒子群算法进行优化,利用改进后的算法找到最优SVM参数,提高SVM的分类精度。
2 支持向量机
支持向量机的原理是建立一个最优分类超平面,使得该超平面在正确分开不同类别的样本的同时,还能使得分类间隔最大化。假设训练样本集为
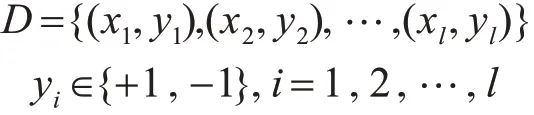
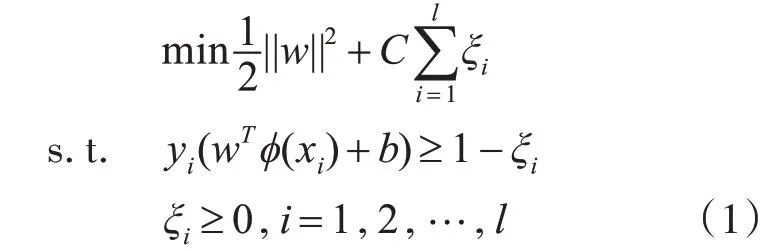
可求得最优分类超平面为其中,w为超平面法向量;ξi为松弛因子;C为惩罚因子;xi为第i个样本的特征;yi为类别标签;φ(xi)为映射函数;
利用Lagrange函数,可得到该问题的对偶形式:
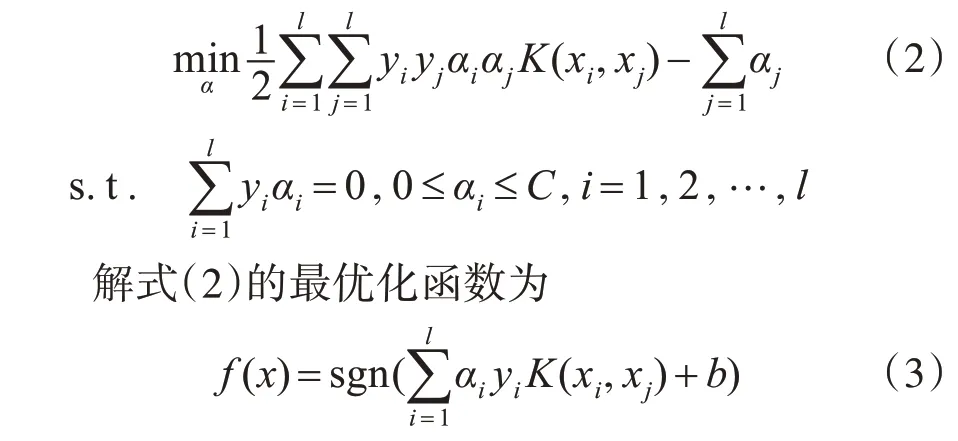
其中,αi为Lagrange乘子;K(xi,xj)∈Rn为核函数,本文采用高斯核函数[12]作为SVM模型中的核函数,其数学形式为
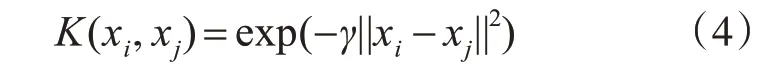
其中,γ为核参数。
3 对粒子群算法进行优化
3.1 经典粒子群算法
粒子群算法是由Eberhart和Kennedy在1995年提出的一种群智能优化算法,它是源于对鸟类觅食行为的研究。粒子群算法具有收敛速度快,算法简单以及效率高的优点。在粒子群算法中,每个粒子具有位置和速度两个属性,粒子的位置表示某个可行解,粒子的速度则表示与下一个可行解的差值。每个粒子可以根据已经寻找到的最优解和整个粒子群的最优解不断调整自己的速度,以此来寻找到更优的解。
假设所求解问题的空间是d维,种群大小为m,种群中的每个粒子代表一个可行解,则第i个粒子的位置和速度分别为Xi=(xi1,xi2,…,xid)和Vi=(vi1,vi2,…,vid)。记第i个粒子经过的最好位置为Pbest=(ppbest,1,ppbest,2,…,ppbest,d),整个种群经过的最优位置为gbest=(pgbest,1,pgbest,2,…,pgbest,d)。在迭代过程中,粒子可通过个体极值pbest和群体极值gbest来进行更新自己的速度和位置,即:
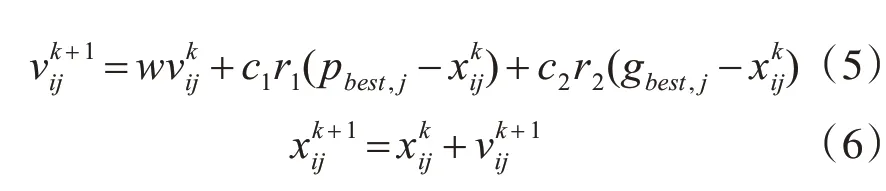
其中w为惯性权重;c1,c2为学习因子,为常数;r1,r2为[0,1]区间内的随机数;k为进化的代数,1≤i≤m,1≤j≤d。
3.2 改进惯性权重的粒子群优化算法
在粒子群算法中,惯性权重w的大小影响粒子群算法寻找最优解的能力[13~14]。若w较大,则有利于提高粒子的全局最优能力,使得算法跳出局部最优点;若w较小,则会提高粒子的局部最优能力,使得算法趋于收敛。本文采用自适应权重来取代惯性权重,从而平衡粒子的全局和局部最优能力:
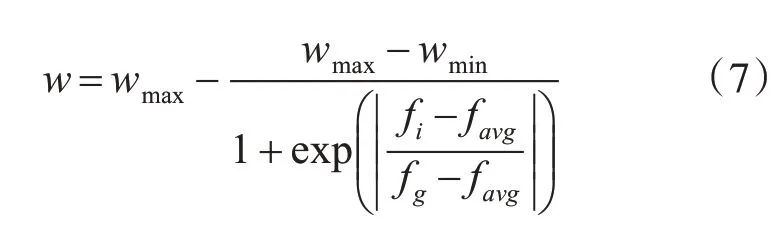
其中,wmax为权重的最大值,wmin为权重的最小值,通常取wmax=0.9,wmin=0.4;fi为第i个粒子的适应度值,favg为种群平均适应度值,fg为种群最优适应度值。
3.3 引入自适应变异的粒子群优化算法
本文将粒子群中的每个粒子位置变量设定为二维,两个分量为x(i,1)和x(i,2)。其中,x(i,1)的范围为(Cmin,Cmax),x(i,2)的范围为(γmin,γmax),分别对应SVM的惩罚因子C和核参数γ,用粒子的适应度值来评价粒子所处位置的好坏程度。
本文采用自适应变异对粒子群算法进行优化,赋予部分粒子一定的变异概率,从而增强粒子的种群多样性[15~16],在一定程度上跳出局部最优解,达到全局最优。具体变异算法如下:
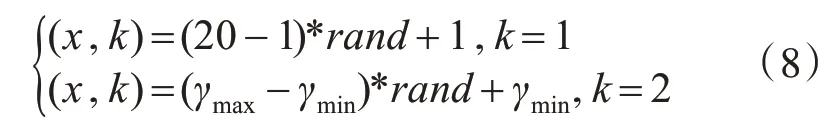
其 中,k=ceil(2*rand),rand的 范 围 为(0,1),
改进后的粒子群算法具体步骤如下:
步骤1:初始化PSO的相关参数。在一定范围内随机生成粒子的初始位置。
步骤2:计算粒子的适应度值。利用台湾林智仁教授开发的LIBSVM工具箱里的svmtrain函数来计算各个粒子的适应度值。将每个粒子的位置分量x(i,1)和x(i,2)代入适应度函数中得到适应度值,计算过程如下:
教学的意义在于使学生拥有终身发展,并且适应社会的知识储备以及能力。利用网络的发展与高中物理教学相结合,能够有效提升学生对于社会科技发展的敏感度,这对于学生个人未来发展具有重要意义。同时,多样化的网络技术也产生了各具风格和内涵软件平台,可以有效改善一些现实的限制,诸如试验的设备等,也可以增强教师与学生和家长的联系,使教学活动范围从局限于学校,到建立真正的学校家庭学习体系,更重要的是教师可以从新利用这些平台,实现对学生多方面能力的综合培养。
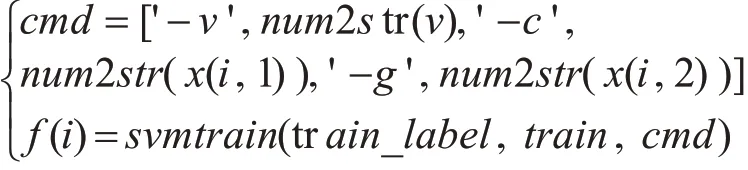
其中,v表示交叉验证数,c表示惩罚因子C,g表示核参数γ,f(i)表示第i个粒子在当前位置的适应度值,算法中用fi表记。train_label表示训练数据集标签,train表示训练数据集。
步骤3:根据粒子初始适应度值,可得到粒子的个体极值pbest和群体极值gbest。
步骤4:根据式(7)更新权重;根据式(5)和式(6)更新粒子的速度和位置。
步骤5:根据式(8),对部分粒子进行变异。
步骤6:计算粒子当前适应度值,并更新粒子个体极值pbest和群体极值gbest。
步骤7:判断是否达到最大迭代次数,若满足则转至步骤7,否则转至步骤2。
步骤8:输出种群最优位置(对应SVM的惩罚因子C和核参数γ)。
步骤9:输入最佳SVM参数,进行分类。
4 实验结果与分析
本文采用UCI标准数据集(Seeds,Wine,Iris)对改进的算法进行验证分析。其中,实验参数设置如下:在SVM中,惩罚因子C的范围为0.1~100,核参数γ的范围为0.01~10;在粒子群算法中,进化次数为200,种群数目为20,学习因子C1=1.5,C2=1.7,惯性权重wmax=1.5,wmin=1.7。
Seeds数据集有三个类别,共计210个样本。每个类别有70个样本,将每个类别随机抽取40组作为训练集,30组作为测试集,测试集共计90组。分别用PSO-SVM和本文改进的算法GPSO-SVM进行试验,实验结果如表1所示。实验结果表明,改进后的算法(GPSO-SVM)可纠正5个错分样本,分类精度提高了5.56%
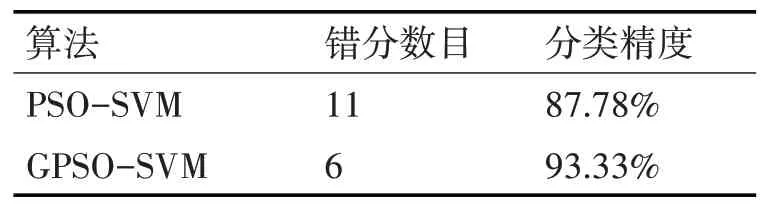
表1 Seeds数据集实验结果
Wine数据集一共有三个类别,共计178个样本。随机抽取108组作为训练集,70组作为测试集。实验结果如表2所示。实验结果表明,改进后的算法(GPSO-SVM)可纠正5个错分样本,分类精度提高了7.14%。

表2 Wine数据集实验结果
Iris数据集一共有三个类别,共计150个样本。将每个类别随机抽取30组作为训练集,剩下来的作为测试集,测试集共计60组。实验结果如表3所示,实验结果表明,改进后的算法(GP⁃SO-SVM)可纠正4个错分样本,分类精度提高了6.67%。
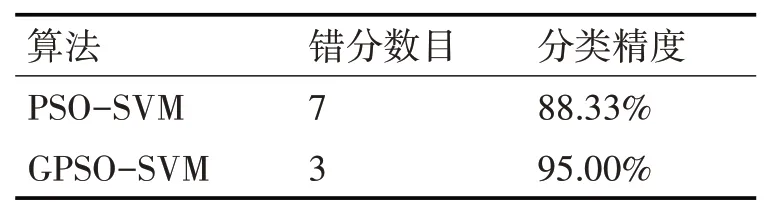
表3 Iris数据集实验结果
实验结果表明,改进后的算法的分类精度明显优于PSO-SVM算法,改进后的算法不仅能有效地避免粒子陷入局部最优,更增强了粒子的种群多样性,具有较高的分类精度。
5 结语
本文针对粒子群算法在优化支持向量机分类时易陷入局部最优,早熟收敛的问题,利用自适应权重和引入自适应变异对粒子群算法进行改进,使得粒子的全局搜索能力和局部搜索能力能够达到良好的平衡,从而达到全局最优。本文使用UCI标准数据集对改进后的算法进行实验论证。实验结果表明,改进后的算法提高了算法的分类性能。在今后的研究中,不仅要寻找更好的改进方法来优化粒子群算法,更要从效率和精度两方面提高分类的性能。
