多策略融合的俄语文本词语提取方法研究
2021-08-06唐菊香孙怿晖廖晓刘建国于娟
唐菊香 孙怿晖 廖晓 刘建国 于娟


摘 要:俄语是联合国工作语言之一,是俄罗斯等多个国家的官方语言。随着“一带一路”倡议的推进和全球化进程的加快,俄语文本数据成为有关组织管理决策的重要信息来源,俄语文本挖掘也因而成为重要的管理决策支持方法。然而,俄语文本挖掘方法研究目前还远未成熟,尤其是其关键基础——俄语文本词语提取的性能较低,阻碍着俄语文本建模的准确性。因此,文章提出一种多策略融合的俄语文本词语提取方法,结合俄语词性分析、语法规则和串频统计等多种方法,自动提取包含单词和短语在内的俄语词语。在联合国平行语料库和Taiga Corpus语料库上的实验结果表明,文章提出的方法在保证高召回率的同时,达到了85%以上的高准确率,显著优于常用的ngram方法,能够为俄语文本主题发现和文本分/聚类等文本挖掘应用提供有效的词库。
关键词:俄语文本挖掘;词语提取;词性标注;频繁词串
中图分类号:G623.35;H08 文献标识码:A DOI:10.12339/j.issn.1673-8578.2021.03.009
Abstract:Russian is one of the working languages of the United Nations and the official language of many countries including Russia. With the advancement of the Belt and Road Initiative and the acceleration of globalization, Russian text data has become an important information resource for managerial decisionmaking of related organizations and Russian text mining has thus become a significant decisionmaking method. However, Russian text mining methods are still far away from being mature, especially the essential Russian text term extraction method, which affects the accuracy of Russian text modeling. This paper proposes a Russian text term extraction method, which combines multi strategies including Russian POS analysis, grammatical rules and string frequency statistics to automatically extract Russian words and multiword expressions. Experiments on the United Nations Parallel Corpus and the Taiga Corpus show that the proposed method achieves a high accuracy of approximate 85% which is much higher than normal recall rate, such as the ngram method. The proposed method can be used to create lexicons for Russian text mining applications such as text topic discovery, text classification, and text clustering.
Keywords: Russian text mining; term extraction; POS tag; frequent wordstring
收稿日期:2021-05-11
基金項目:国家自然科学基金项目“基于本体学习与本体映射的组织异构数据融合方法研究”(71771054)
引言
随着大数据时代的到来,数据尤其是文本数据呈现出爆炸式增长的态势,各个领域和组织都积极利用数据挖掘方法对所积累的数据进行分析。与此同时,“一带一路”倡议的推进和全球化进程的加快,使得单语言信息资源挖掘不能满足管理决策的需求,多种语言信息资源的挖掘逐渐成为实现全球知识发现和共享的关键技术。因此,从多种语言的文本中发现有用信息和知识成为迫切需要。
俄语是联合国工作语言之一,是俄罗斯和哈萨克斯坦、吉尔吉斯斯坦等多个国家的官方语言,使用人数约占世界人口的5.7%。并且,俄罗斯作为我国邻国,与我国的贸易合作日益密切,中俄经贸关系在两国均占据着重要位置。俄语文本分析研究及相应的文本挖掘方法研发有助于为有关组织的业务分析和管理决策提供有力的支持,对中俄贸易合作起到推动作用。
但目前国际上针对俄语文本挖掘的研究还不够成熟,尤其是俄语文本词语提取方法研究。俄语词语提取是俄语文本挖掘的基础和关键步骤,其结果显著影响俄语文本分析和挖掘的效果。俄语词语可以分为单词和短语两类。其中,单词是指由空格隔开的俄语基本书写单位,是组成俄语词语的基本单元;短语是指由两个或两个以上的俄语单词构成的,具有句法和语义单元特征,且其确切含义不能直接从其组件得出的单词序列。在常用词汇中,短语和单词的出现频率在同一数量级上[1]。相较于单词,短语具有更丰富的内涵,自动提取的方法更为复杂。因此,俄语短语提取是俄语文本词语提取方法研发的重点。
虽然目前已有较多针对中文和英文词语提取的相关研究[2-5],但针对俄语文本词语提取的研究较少。因此,准确且高效的俄语文本词语提取方法依然是俄语文本挖掘领域的一个难题[6]。为了弥补俄语文本词语提取研究的不足,本文提出一种多策略融合的俄语文本词语提取方法。该方法既可以提取俄语单词,又可以提取不受长度限制的俄语短语,能够为俄语文本挖掘工作提供完备的词库,进而更好地支持组织管理决策。
本文第1节介绍俄语文本词语提取的研究现状,第2节介绍本文的方法框架,第3、4、5节详细介绍本文方法的实现过程,第6节通过实验分析本文方法的性能,第7节给出结论。本文的词语提取方法是针对俄语文本的自动处理,若无特殊说明,后文中的“文本”均指“俄语文本”;“词语”均指“俄语词语”,包含俄语单词和俄语短语。
1 研究现状
在俄语单词提取研究方面,俄语作为印欧语系语言,文本中的单词以空格作为分隔符且单词具有丰富的屈折变形形态,因此,俄语单词提取需要进行词形还原(lemmatization)。词形还原是指把一个任何形式的单词还原为其一般形式,结果是一个能够表达完整语义的单词。国内外已有较多针对俄语词形还原的研究[7-9],并基于词典、规则、统计和多策略融合的方法开发出多个俄语词形还原工具,如MyStem[10-11]、Pymorphy2[12-13]等。
在俄语短语提取研究方面,相较于中文和英文短语的提取,俄语短语提取的研究较少,且多集中在双词短语提取的研究上[4,14]。已有的短语提取方法研究可以归纳为3类:基于规则的方法、基于统计的方法和多策略融合的方法。
基于规则的方法,使用词性及词法模式等语言知识从语料中自动提取词语。单纯使用基于规则的方法进行俄语文本词语提取的研究较少。代表性文献对已有术语的构成进行归纳并扩展出73条术语构成规则,研发了FASTER系统实现医药领域的术语自动提取[15]。基于规则的方法能高效地提取低频短语,具有较高的精度;但需要人工挖掘特定领域的构词规则,耗时耗力,且不同领域的规则存在差异,因此规则的通用性不足。
基于统计的方法,使用词语在语料库中的分布统计属性提取词语。常用的统计方法包括互信息[16]、对数似然比[17]等。文献[18]使用统计方法从包含10亿个单词的大型新闻语料库中总结出英文短语的特征。文献[19]提出英文短语提取的LocalMaxs算法。文献[20]提出一种基于词序列频率有向网的短语抽取算法,借鉴人类的认知心理模式识别中文短语。文献[21]基于左右熵联合增强互信息算法和SVM分类器,构建上下文和词向量特征,用于提取中文短语。基于统计的方法可以自动且高效地提取词语,能有效节约人工成本,但该方法利用的是概率信息,要求语料库足够大,并且无法提取低频词。
多策略融合的方法,结合使用基于规则和基于统计的两种方法来提取词语。多策略融合的短语提取方法研究較多,方法多样化。文献[22]提出Cvalue参数,减少英文短语提取中被嵌套词语的提取,提高词语提取的效果。文献[23]结合重复串、左右邻接熵、内部关联度、多词嵌套、停用词等方法提取中文短语。文献[24]使用BLSTMCRF模型抽取中文专利文本的短语。文献[25]提出带约束合并的代替FPGrowth算法生成中文短语。文献[26]使用词频、文档频率、卡方分布和Tseng算法生成英文短语。文献[27]结合改进的二叉树技术和内聚性指数实现无监督的关键短语提取。文献[28]借助维基百科等外部资源,结合固定词性搭配规则和MRR排名指标实现俄语双词术语的提取。多策略融合的方法能整合多种方法的优势,且一定程度地避免单一方法的不足。
综上可见,相较于中、英文词语提取,专门针对俄语文本词语提取的研究较少,已有的俄语文本词语提取体现在术语提取、关键词提取等研究的过程之中,如文献[29-31]等,且词语提取的效果不够理想。从所提取词语的长度上来看,已有俄语文本词语提取的研究多集中在俄语单词以及双词短语的提取上,对更长长度的词语提取的研究较少。为此,本文提出一种融合多策略的俄语文本词语提取方法,改善俄语文本提词的效果,构建待分析的俄语文本和语料的词库,支持大规模俄语文本的自动分析。
2 方法框架
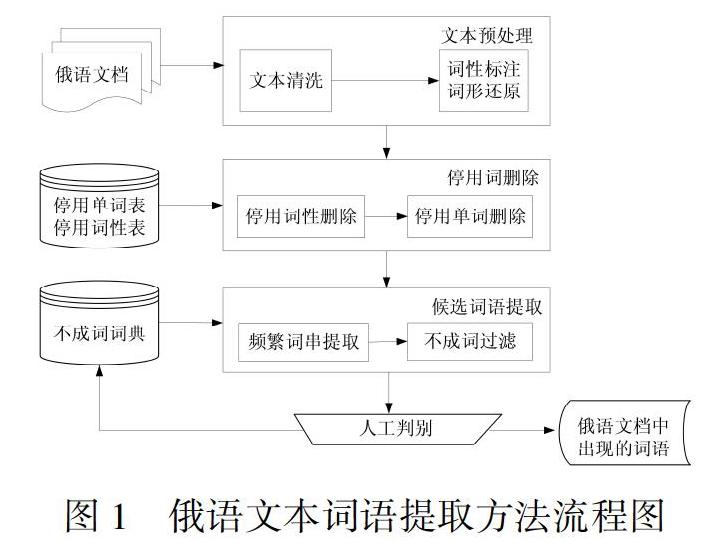
本文结合词性分析、俄语规则和串频统计等多种词语提取方法,实现俄语文本词语的自动提取,包括俄语单词和俄语短语。本文方法主要包括文本预处理、停用词删除、候选词语提取和人工判别四个模块,流程如图1所示。
对图1的说明:
(1)文本预处理模块的输入是一个或多个俄语文档,输出是适用于词语提取的标准化的文本。其中,俄语文档是包含Web网页、Word文档、文本文档等在内的俄语自然语言电子语料。该模块的处理方法详见本文第3节。
(2)停用词删除模块,删除前一模块输出的标准化文本中的俄语停用单词和停用词性词,得到删除停用词后的单词串集合。其中,停用单词和停用词性规则是本文基于大量的文本词语提取实验总结得出。该模块的处理方法详见本文第4节。
(3)候选词语提取模块,采用统计方法处理前一模块输出的单词串集合,提取频繁词串,筛掉其中不成词的词串之后,将剩下的频繁词串输出为候选词语集合。该模块的处理方法详见本文第5节。
(4)人工判别模块,由俄语专业人士人工判定前一模块输出的候选词语,选取最终的词语集合用于后续的文本挖掘等应用。同时,人工判定不成词的候选词语被加入不成词词典,以提高后续的俄语文本词语提取效果。该模块的处理方法易于理解,后文不再赘述。
3 文本预处理
文本预处理模块将输入的俄语文档处理为适用于词语提取的标准化文本,包含语料清洗、词性标注和词形还原2个步骤。不同语言的文本预处理方法存在差异。
3.1 文本清洗
该步骤对输入的俄语Web网页、Word文档、文本文档等文本执行清洗操作,即去除文本集中如导航栏、图片、注释等与文本分析无关的信息,将不同类型的文本处理为纯文本,然后统一转化为utf8编码格式。图2为一段俄语文本示例,其中,左侧的俄语文本是一段随机选取的介绍数据挖掘的百科文本,不具有特殊性;右侧为与左侧文本相对应的中文文本。
3.2 词性标注与词形还原
该步骤遍历文本,采用现成工具标注每个单词的POS(partofspeech)词性并还原词形。其中,词性标注是指确定每个单词的词性为动词、名词、形容词或其他词性的过程。词形还原将一个任何形式的单词还原为其原形,例如,名词алгоритмов(algorithms)原形为алгоритм(algorithm),动词найденных(found)原Перед использованием алгоритмов добыча данных необходимо произвести подготовку набора анализируемых данных. Aнализируемые данные с одной стороны должны иметь достаточный объём, чтобы эти закономерности в них присутствовали, а с другой — быть достаточно компактными, чтобы анализ занял приемлемое время. Наблюдения делятся на две категории — обучающий набор и тестовый набор. Обучающий набор используется для обучения алгоритма добыча данных, а тестовый набор — для проверки найденных закономерностей.
使用數据挖掘算法之前,需要先准备一组分析数据。分析数据一方面应足够大,以确保这些模式出现在其中;另一方面应足够紧凑,以使分析花费的时间可接受。观察数据分为两类:训练集和测试集。训练集用于“学习”数据挖掘算法,测试集用于验证找到的模式。
目前主流的俄语词性标注和词形还原工具包括Mystem[8]、Pymorphy[10]、TreeTagger[32]等,已有研究[31]表明,由著名俄语搜索引擎Yandex开发的Mystem无论是在俄语词性标注还是词形还原上效果皆为最佳,因此本文采用Mystem工具进行俄语词性标注和词形还原。图3为图2中的文本进行词性标注与词形还原的结果。为了便于结果展示,本文实验结果使用“
”标记表示换行符。
需要说明的是,Mystem对专有名词的大小写和单复数的词形还原处理会导致专有名词提取错误。例如,“Организации Объединенных Наций(联合国)”因被Mystem还原为“организация объединять нация(组织团结国家)”而失去原义。因此,本文对非句首的首字母大写单词不执行词形还原操作。
4 停用词删除
停用词是指广泛使用的、无实际意义的或不具有区分性的词,这些词一般不参与构成短语。本文通过实验总结了俄语停用词性表和停用单词表,据此删除文本中的停用词,输出单词串的集合。
4.1 停用词性删除
停用词性是指一般不参与短词构词的词性。本文基于大量词语提取实验的结果,结合俄语构词与中文、英文构词的异同,计算各个俄语词性的构词率,将构词率低的词性作为停用词性。其中,构词率是指包含该词性单词的词串是短语的概率[2]。表1列举了各俄语词性的构词率。
表1中的副词和介词的构词率计算仅考虑那些参与构词的副词和介词。由于俄语的部分副词和介词也参与构词,如副词нетто(净)、дешево(轻易地)、особенно(特殊地)、плотно(努力地)、долго(长时间地),介词с(with/and/from/of)、об(about/of)、о(of/about/against)、из(from/of/in)等,本文将副词和介词设为停用词性,但保留那些参与构词的副词和介词。这样可以保证所提取词语的完整性以及词语提取结果的召回率。
4.2 停用单词删除
本文参考NLTK[33]的俄语停用单词表,并通过大量词语提取实验总结出俄语停用单词表。图4为对图3中的文本删除停用词性词和停用单词后所形成的单词串集合。
5 候选词语提取
候选词语提取模块,统计频繁共现的单词串,并依据不成词词典和不成词规则筛选频繁词串,输出候选词语集合。
5.1 频繁词串提取
该步骤以单词为步长提取频繁词串。其中,频繁词串是指共现频次超出阈值的单词序列。由于一些频繁词串仅作为子串出现,没有单独成词,所以本文在串频统计的基础上执行子串删除操作。频繁词串提取的基本思想是:频繁共现的单词串可能成词;仅作为子串出现的频繁词串比其父串的成词可能性小。频繁词串提取算法如图5所示。
对图3中的文本,将频繁词串提取算法中的频次阈值设为2,可以提取出6个频繁词串,如表2所示。其中,子串删除操作删除了9个词串,包括:仅单独出现1次的“данные(数据)”“набор(集合)”和仅作为子串出现的“алгоритм(算法)”“добыча(挖掘)”“анализировать(分析)”“обучать(训练)”“тестовый(测试)”“алгоритм добыча(挖掘算法)”和“добыча данный(数据挖掘)”。
输入:俄语单词串集合和频次阈值
输出:频繁词串
(1) 对俄语单词串集合中的每一单词串WS,切分得到WS的所有子串,长度优先统计每一子串的出现频次,将频次大于阈值的词串及其频次加入Candidates;
(2) 按所包含单词的个数多少降序排列Candidates中的词串;
(3) 对Candidates的每一词串CWS,从头遍历Candidates中CWS之前的每一词串FWS,若FWS包含CWS,则更新CWS频次=CWS频次FWS频次;//减去作为子串出现的频次
(4) 删除Candidates中频次小于阈值的词串;//子串删除
(5) 按字母顺序输出Candidates。
5.2 不成词过滤
该步骤通过不成词规则和不成词词典两种方式过滤频繁词串,得到候选词语集合。所谓不成词是指经俄语专业人士判定不是词语。不成词规则是本文总结的俄语频繁词串不成词的规则。如本文4.1所述,为了保证召回率,本文在删除停用词时保留了部分介词。这导致部分频繁词串以介词开头或结尾,如“об оценка(about evaluation)”“о мера(about measure)”“из число(from the number)”“от имя(of the name)”等,这些候选词语显然是不成词的。因此,本文设置了2条不成词过滤的规则,包括:
(1)删除以“об”(about/of)或“о”(of/about/against)开头或结尾的频繁词串,增加去除开头或结尾的“об”或 “о”之后的子串作为频繁词串;
(2)删除以“из”(from/of/in)或“от”(from/of/for)开头的频繁词串,增加去除开头的“из”或“от”的子串作为频繁词串。
不成词词典是经俄语专业人士判定为不成词的频繁词串,该词典将随着人工判定工作的积累而不斷扩充。随着不成词词典的丰富,本文的俄语文本词语提取方法的准确率将逐步提高。
频繁词串经不成词过滤之后即得到了候选词语集合,可用作文本挖掘应用的文本建模阶段的词库。若需要精准的词语提取结果,则把候选词语集合交由俄语专业人士进行人工判定,选取最终的词语集合,并把人工判定不成词的候选词语加入不成词词典。
6 实验分析
目前,俄语文本词语提取方法研究还没有标准的实验分析语料或评价指标,为了说明本文方法的性能,采用两个不同类型的语料库对比本文方法与常用的ngram俄语文本词语提取方法,分别计算两种方法的成词数目与准确率。
6.1 实验语料
本文采用两种题材不同的文本语料库进行实验:联合国平行语料库(The United Nations Parallel Corpus)[34]和Taiga Corpus语料库[35]。对于联合国平行语料库,随机选取2014年的俄语文本200篇,内容为涉及科技、经济等多个主题的联合国会议记录。对于Taiga Corpus语料库,本文选用20Nplus1语料中2016年12月到2017年1月的文本共280篇,内容为涉及科学、数学等主题的杂志文章。
6.2 评价指标
文本挖掘方法的常用评价指标是准确率和召回率。其中,衡量文本词语提取方法的准确率是指候选词语中经人工判定成词的比例。召回率是指经人工判定成词的候选词语占文本中出现的全部词语的比例。由于目前尚没有经过人工精确标注的语料库,无法确定语料中出现的全部词语数量,因此,本文采用正确提取词语的数目来代替召回率评价指标。
为了提高人工判别的准确性,请两名俄语专业人士分别独立判别候选词语是否成词,然后对判别结果不同的候选词语进行第二轮人工判别,直至消除异议。其中,第一轮人工判别阶段出现异议的情况约为1.5%。可见,在自动提取得到的候选词语是否能够成词方面,俄语专业人士的共识度是很高的。
6.3 实验分析
为了验证本文方法的有效性,实验采用本文方法和俄语文本词语提取常用的ngram方法分别对两个实验语料做词语提取的对比分析。由于俄语短语提取的性能决定着俄语文本词语提取效果,因此本文实验结果的准确率仅考虑俄语短语的提取。
公平起见,两种方法采用相同的文本预处理和停用词删除操作,且本文方法提取得到的候选词语未经不成词词典的筛选。对于联合国平行语料库,频繁词串提取阶段的频次阈值设为3;对于Taiga Corpus语料,频次阈值设为2。本文方法与ngram方法在两个语料上的实验结果如表3所示。
对表3的说明:
(1)表中“自动提词数目”为自动提取所得到的候选词语的数目,“成词数目”为候选词语中由俄语专业人士人工判断为成词的数目。
(2)由于本文方法自动提取所得的候选词语的最大长度为12(包含单词的个数),因此,将ngram的n设为2至12。而已有研究中,因为n的不确定性,常把n设为2或3,大大减少了自动提词的数目,因而召回率远低于本文方法。
(3)将n设为2至12时,ngram的提词结果即为本文方法中未经子串删除的频繁词串集合。这些仅作为子串出现的词串,不仅成词可能性比其父串小,而且可能影响后续的文本挖掘结果。如图2,文本中的“добыча данный(数据挖掘)”仅作为“алгоритм добыча данный(数据挖掘算法)”的子串出现,前者不仅不成词,还可能因出现频次更高而比后者更易成为代表文本的特征词(关键词/主题词),但显然后者更适合作为文本的特征词。因此在人工判别阶段,将ngram提词结果中仅作为子串出现的频繁词串皆判定为不成词。
(4)本文方法在Taiga Corpus语料上的准确率略低于联合国平行语料,主要原因在于本文方法的性能受停用单词表完善程度的影响。后续随着停用单词表的补充,本文方法的性能将进一步提高。
由实验可知,在俄语文本词语提取方面,本文方法的准确率远高于ngram方法,且本文方法克服了ngram方法需要人工指定n的缺陷,比ngram的自动化程度更高。本文方法较优的主要原因是:①删除仅作为子串出现的词串;②根据俄语语法设置不成词规则,删除部分频繁词串。被删除的这两类词串不是独立出现,成词率低,且不适宜作为文本的特征词。可见,本文方法不仅能够提高俄语文本词语提取的准确率,还将提高后续文本挖掘的效果。
7 结论
随着“一带一路”倡议的推进和全球化进程的加快,俄语文本数据挖掘成为有关组织管理决策的重要方法。俄语文本词语提取是俄语文本挖掘的关键基础,前者的结果直接影响后者的准确性。针对当前国际上专门的俄语文本词语提取方法研究较少的现状,本文研究了一种融合多策略的俄语文本词语提取方法,用于自动提取待分析俄语文档中的词语集合,构建文本建模阶段所需的词库,支持俄语文本主题发现和俄语文本分/聚类等文本挖掘应用。
本文方法结合俄语词性分析、语法规则和串频统计等多种策略,实现俄语文本词语的自动提取。该方法首先将输入的俄语文档预处理为适用于词语提取的标准化文本,接着基于实验总结的俄语停用词性和停用单词表将文本切分为俄语单词串集合,然后结合串频统计和子串删除的统计方法提取频繁词串,并根据不成词词典和俄语语法的不成词规则进一步过滤,所得到的候选词语集合可直接用作文本挖掘应用的词库。
对不同题材的语料库进行词语提取的实验结果表明,本文提出的俄语文本词语提取方法在保证召回率的同时,准确率远高于ngram方法;克服了ngram方法需要人工指定n的缺陷;且本文方法提取得到的词语集合更适用于文本挖掘应用。但是,本文方法的词语提取结果受到停用单词表完善程度的影响,因此,未来还需通过实验进一步总结和丰富停用单词表。
参考文献
[1] JACKENDOFF R, CYNX J. The architecture of the language faculty[J]. Quarterly Review of Biology, 1997, 7(74): 1-8.
[2] FIROOZEH N, NAZARENKO A, ALIZON F. Keyword extraction: Issues and methods [J]. Natural Language Engineering, 2020, 26(3):259-291.
[3] VILLAVICENCIO A, IDIART M. Discovering multiword expressions[J]. Natural Language Engineering, 2019, 25(6): 715-733.
[4] 于娟, 党延忠. 结合词性分析与串频统计的词语提取方法[J]. 系统工程理论与实践, 2010, 30(1): 105-111.
[5] HASAN K S, NG V. Automatic keyphrase extraction: A survey of the state of the art [C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics,ACL 2014. Baltimore, Maryland, USA:ACL Press, 2014: 1262-1273.
[6] LOUKACHEVITCH N, PARKHOMENKO E, LOUKACHEVITCH N. Evaluating distributional features for multiword expression recognition [C]//21st International Conference on Text, Speech, and Dialogue, TSD 2018. Brno, Czech Republic: Springer, Cham, 2018: 126-134.
[7] 李峰, 易綿竹. 面向俄文NLP的形态自动分析研究与实现[J]. 中文信息学报, 2011, 25(5): 68-75.
[8] GOLDSMITH J. Unsupervised learning of the morphology of a natural language[J]. Computational linguistics, 2001, 27(2): 153-198.
[9] ЛАПШИН С В, ЛЕБЕДЕВ И С. Метод полуавтоматического формирования словаря морфологических описаний слов[J]. Научнотехнический вестник информационных технологий, механики и оптики, 2012, 5(81): 104-107.
[10] Yandex. MyStem [EB/OL]. [2021-01-07]. https://yandex.ru/dev/mystem.
[11] SEGALOVICH I. A fast morphological algorithm with unknown word guessing induced by a dictionary for a Web search engine[C]//International Conference on Machine Learning Models. DBLP, 2003. Las Vegas, Nevada: Springer, Cham, 2003:273-280.
[12] KOROBOV M. pymorphy2 [EB/OL]. [2021-01-07]. https://pypi.org/project/pymorphy2.
[13] KHACHAY M Y, KONSTANTINOVA N, PANCHENKO A, et al. Morphological analyzer and generator for Russian and Ukrainian languages [C]//International Conference on Analysis of Images, Social Networks and Texts. Yekaterinburg, Russia:Springer, Cham, 2015: 320-332.
[14] ЛУКАШЕВИЧ Н В, ГЕРАСИМОВА А А. Определение устойчивых словосочетаний методом ассоциативного эксперимента [J]. Вестник Московского университета. Серия 9: Филология, 2018(1): 23-42.
[15] JACQUEMIN C. Recycling terms into a partial parser [C]//Fourth Conference on Applied Natural Language Processing. Stuttgart, Germany: Association for Computational Linguistics, 1994: 113-118.
[16] CHURCH K W, HANKS P. Word association norms, mutual information, and lexicography [J]. Computational linguistics, 1990, 16(1): 22-29.
[17] DICE L R. Measures of the amount of ecologic association between species [J]. Ecology, 1945, 26(3): 297-302.
[18] CHOUEKA Y. Looking for needles in a haystack or locating interesting collocational expressions in large textual databases[C]//Proceedings of the RIAO Conference on UserOriented ContentBased Text and Image Handling, 1988, Cambridge, Mass, 1988: 609-623.
[19] SILVA J F D, LOPES G P, TORRE Q D, et al. A local maxima method and a fair dispersion normalization for extracting multiword units from corpora [C]//Sixth Meeting on Mathematics of Language. Orlando, USA, 1999: 369-381.
[20] 陈建超, 郑启伦, 李庆阳, 等. 基于词序列频率有向网的中文组合词提取算法[J]. 计算机应用研究, 2009, 26(10): 3746-3749.
[21] 龚双双, 陈钰枫, 徐金安, 等. 基于网络文本的汉语多词表达抽取方法[J]. 山东大学学报(理学版), 2018, 53(9): 40-48.
[22] FRANTZI K,ANANIADOU S.Extracting nested collocations[C]//Proceedings of the 16th Conference on Computational Linguistics.Copenhagen,Denmark,1996:41-46.
[23] 唐亮, 李倩, 許洪波, 等. 基于多策略过滤的汉日多词短语抽取和对齐[J]. 山东大学学报(理学版), 2015, 50(9): 21-28.
[24] 马建红, 姬帅, 刘硕. 面向专利的主题短语提取[J]. 计算机工程与设计, 2019, 40(5): 1365-1369.
[25] 刘晨晖,张德生,胡钢.基于Kert的中文主题关键短语提取算法[J].计算机应用,2019,39(1):245-249.
[26] RAHAMAN M M, AMIN M R. Language independent statistical approach for extracting keywords[C]//2017 4th International Conference on Advances in Electrical Engineering (ICAEE). Dhaka, Bangladesh: IEEE Press, 2017: 205-210.
[27] RABBY G,AZAD S,MAHMUD M,et al.TeKET:a TreeBased Unsupervised Keyphrase Extraction Technique[J].Cognitive Computation,2020,12(6):811-833.
[28] DOBROV B V, LOUKACHEVITCH N V. Multiple evidence for term extraction in broad domains[C]//Recent Advances in Natural Language Processing, Hissar, Bulgaria, 2011: 710-715.
[29] WESTLING A, BRYNIELSSON J, GUSTAVI T. Mining the web for sympathy: the pussy riot case[C]//2014 IEEE Joint Intelligence and Security Informatics Conference. The Hague, Netherlands: IEEE, 2014: 123-128.
[30] LAGUTINA K, LARIONOV V, PETRYAKOV V, et al. Sentiment classification of russian texts using automatically generated thesaurus [C]//Proceedings of the 23rd Conference of Open Innovations Association FRUCT. Bologna, Italy: IEEE Press, 2018: 13-16.
[31] ХРАМЦОВ Н С. Проблематика оценивания алгоритмов автоматического извлечения ключевых слов [J]. Новые информационные технологии в автоматизированных системах,2019(22):199-203.
[32] SCHMID H.TreeTaggerunimuenchen.de[EB/OL].[2021-03-31].https://cental.uclouvain.be/treetagger.
[33] BIRD S, KLEIN E, LOPER E. NLTK [EB/OL]. [2020-04-13]. http://www.nltk.org.
[34] ZIEMSKI M, JUNCZYS M, POULIQUEN B. The United Nations parallel corpus [C]//Language Resources and Evaluation in Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC16), Portoro, Slovenia,2016.
[35] SHAVRINA T, SHAPOVALOVA O.Taiga Corpus [EB/OL]. [2020-06-14]. https://github.com/TatianaShavrina/taiga_site.
作者簡介:于娟(1981—),女,博士,福州大学经济与管理学院教授,中国系统工程学会数据科学与知识系统工程专委会委员,主要研究领域为数据挖掘、信息与知识管理系统,先后主持和完成多项国家自然科学基金和国家社会科学基金项目。通信方式:yujuan@fzu.edu.cn。
唐菊香(1996—),女,福州大学经济与管理学院硕士研究生,研究方向为数据挖掘与商务智能。通信方式:1767365964@qq.com。
