基于SOINN的在线物联网设备识别方法
2021-08-06张帅帅祁春阳汪潇文
张帅帅 黄 杰,3 祁春阳 汪潇文
(1东南大学网络空间安全学院, 南京 211189)(2东南大学江苏省计算机网络技术重点实验室, 南京 211189)(3网络通信与安全紫金山实验室, 南京 211111)
随着5G与AI技术的应用和推广,物联网技术得到飞速发展,大量的物联网设备在智慧城市、医疗、工业等领域[1-2]得到广泛应用.根据Statista公司的预测,2025年物联网设备的数量将达到386亿台,而2030年将增加到500亿台[3].然而物联网设备由于结构简单、防御机制不足,成为黑客的主要攻击目标,往往一个设备漏洞便会导致同品牌设备都被攻击.同时由于物联网设备数量庞大,这种攻击的危害可以被成倍放大.2016年,黑客利用Mirai病毒[4]劫持了150万台物联网设备并组成僵尸网络(botnet)发动DDOS攻击,造成美国大规模的网络瘫痪.2017年,LG智能家居设备的漏洞导致大量用户隐私泄露.因此,物联网安全已经成为未来网络发展中亟需解决的关键问题之一.
但是,物联网设备数量庞大,种类繁多,不同类型的设备存在不同的安全漏洞,难以进行统一的安全管理.因此,利用物联网信息搜索技术[5]发现和识别物联网设备是进行安全管理的第一步.Shodan和Censys是业界成熟的物联网搜索引擎,可以提供大量暴露在公网中的物联网设备信息.目前的物联网设备识别方法大致可以分为2类:基于流量特征的识别方法[6-10]和基于标语的识别方法[11-14].
物联网设备的流量特征主要包含2方面:① HTTP、Telnet、RTSP、Modbus等协议的使用情况和协议头部特征值;② 通信流量的行为特征,如通信数据大小、通信对象和通信频率等.Comer等[6]通过分析TCP协议实现方法的差异生成指纹来识别设备.知名扫描工具Nmap、Xprobe2就采用了这项技术.Thangavelu等[7]则通过统计分析DNS、TLS、HTTP等协议的均值方差,生成设备的数字化特征.Miettinen等[8]聚焦小型网络中的设备识别并减少了识别的计算开销.文献[9-10]从设备通信的行为中提取特征,结合机器学习方法识别设备.基于流量特征训练的分类模型识别快、准确率高,但是存在以下缺陷:① 物联网设备品类复杂,采集和标定数据的成本高,无法获得充足的训练数据;② 已训练好的分类模型缺少动态更新能力,无法应对快速变化的物联网环境.
基于标语的识别方法则利用正则匹配和自然语言处理等技术,从采集到的文本数据中直接提取类型、品牌、型号等字段.Li等[11]利用自然语言处理技术提取网页中的文本信息,结合机器学习方法建立分类模型,可以自动发现网络空间中的监控设备.文献[12-13]利用标语信息成功识别了多种工业控制系统.ARE(acquisitional rule-based engine)利用谷歌搜索引擎拓展文本信息,自动生成文本规则来标注和识别物联网设备[14].IoTTracker则综合考虑了设备登陆页面的DOM树结构特征和FTP端口的非结构化的文本特征,通过匹配文本特征库实现了不同类型的设备识别[15].基于标语的识别方法可以直接给出明确的设备品牌和型号结果,但是存在以下缺点:① 识别过程依赖于明确的品牌型号字段,当设备信息中不存在关键字信息或难以提取时就无法识别设备;② 相比于数字向量特征,标语信息构成的文本特征会造成更大的存储开销;③ 每次都需要遍历完整的文本特征库,识别时间长.
为了解决上述问题,本文将增量学习方法与监督学习方法相结合,提出了基于自组织增量学习神经网络(self-organizing incremental neural network,SOINN)的在线物联网设备识别方法.该方法分2步依次识别设备的品牌和型号信息.首先,设计了基于交互页面DOM树的设备品牌特征,将特征转化为数字向量并且特征长度只有26.然后,结合SVM和SOINN[16]构建SOINN-SVM,实现设备品牌分类器的增量学习.借助SOINN网络的压缩数据和增量学习特性,使用少量的数据完成分类模型的快速动态更新,使得品牌分类器可以在识别过程中不断提高识别准确率.接着,使用TF-IDF技术优化正则匹配结果,使得正确的型号字段具有更高的权重值,降低干扰词的影响.最后,结合TF-IDF权重值和Jaro距离计算文本匹配度,实现设备型号的识别.
1 在线物联网设备识别框架
图1为本文提出的在线物联网设备识别方法的整体框架图,主要由3部分组成:训练数据生成模块、品牌识别模块和型号识别模块.在训练数据生成模块中,利用ARE[14]方法从网络中采集数据并打上标签作为品牌识别和型号识别的训练数据.图1中的数据预处理模块会根据品牌识别和型号识别所需的不同特征采取不同的数据处理方法.品牌识别模块需要使用基于页面DOM树结构的特征训练SVM分类器.型号识别模块需要利用正则匹配提取文本中的关键字,并计算TF-IDF权重生成型号特征库.原始数据经过数据预处理后得到带标签数据,接着2个识别模块利用带标签数据进行离线训练,初始化品牌分类器和型号特征库.
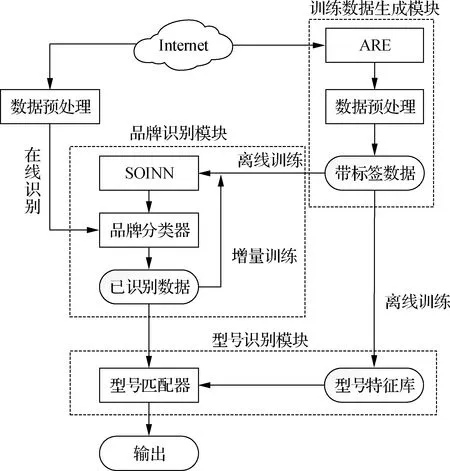
图1 在线物联网设备识别框架
在品牌识别模块中,带有品牌标签的训练数据先经过SOINN网络进行压缩,压缩后的数据称为原型数据,它们可以代表完整数据的拓扑分布.接着利用原型数据训练SVM品牌分类器,相比于使用完整的原始数据训练,该方法可以大大减少模型训练的时间.训练好的SVM品牌分类器可以在线识别新的设备.已识别数据会再次作为训练数据进入SOINN网络进行增量训练.原型数据将获得更新调整,并重新训练SVM品牌分类器,使得分类器性能在识别过程中不断提高.因此本文方法中的品牌分类器具有在线学习的能力.
在型号识别模块中,型号匹配器会根据品牌识别的结果,加载对应品牌的型号特征库并计算文本相似度,与待识别设备具有最高相似度的型号将作为型号识别的结果.与其他方法的区别是,该方法只需要遍历一种品牌的型号特征库,而不是完整的型号特征库,因此减少了识别的时间.总体来看,本文提出的物联网设备识别框架具有以下3个优点:① DOM树结构特征和关键字特征结合使用,可以识别更多设备;② 利用SOINN-SVM使得品牌分类器具有在线学习能力;③ 更低的计算和存储开销.
2 基于页面代码结构特征的品牌识别方法
2.1 特征提取
为了提供便捷的远程控制功能,大部分物联网设备都会运行HTTP协议,通过交互页面向用户提供设备状态信息和控制接口.不仅不同厂家页面的特征差异性大,而且页面代码被写入设备固件中,在设备使用周期内基本不会改变,这确保了DOM树结构特征的独特性和稳定性.DOM树结构特征提取自页面代码的结构,与文本信息无关,即使页面中的部分重要字段缺失或者被更改,利用结构特征依然可以识别设备品牌.
交互页面都是由HTML代码生成的,原始代码都可以被转换成DOM树结构,如图2所示.图中,左侧为源代码,右侧为转换后的DOM树结构,每个节点都是一个HTML的标签元素.页面代码的书写方式不同,在DOM树中每个节点的分叉情况也会不同.
IoTTracker中DOM树结构特征的提取方法是记录所有节点,这导致每条特征十分冗长,存储和计算开销很大.本文通过分析不同标签的作用,精简和统一了特征长度,设计了如表1所示的26个特征值.

图2 交互页面代码转换为DOM树结构

表1 交互页面DOM树结构特征
1) 特征Ⅰ(特征1~7)是对〈head〉标签下代码的分析.在HTML文档中,〈head〉标签用来定义文档的头部,描述了文档的各种属性和信息,包括文档的标题、全局属性设置以及脚本调用等.在头部使用的标签元素有:〈link〉、〈meta〉、〈script〉、〈title〉等.对于这些标签,将它们的使用次数作为特征值.
2) 特征Ⅱ(特征8~16)是对〈body〉标签下代码的分析.标签〈body〉定义了网页的主体,包含网页的所有内容(如文本、超链接、图像、表格、列表等).在这些标签中,〈div〉标签用于将文档分割成独立、不同的块结构.同时它们又可以继续通过〈div〉标签被细分为更小的块.块结构的不同分布是不同品牌交互页面之间的主要区别.因此,可以统计标签〈div〉的数量以及子标签的深度并作为特征值.标签〈table〉也有划分页面结构的作用,同样统计〈table〉标签的个数以及最大行数列数并作为特征值.
3) 特征Ⅲ(特征17~26)是DOM树的层次结构信息.利用宽度优先搜索算法搜索〈body〉部分的树结构,将每层的子节点个数作为特征值.记Scur为当前节点,|Scur|为当前节点的子节点的个数,取|Scur|作为一个特征值,然后在Scur的所有子节点中找到具有最多子节点数的节点,令其为Scur,再将新的|Scur|记为下一个特征值.如此搜索10层DOM树结构并记录每层的最大子节点数,最后得到特征17~26.
2.2 增量式监督学习算法SOINN-SVM
2.2.1 简化的SOINN算法
自组织增量学习神经网络(SOINN)是一种基于竞争学习的双层神经网络,通过神经元的调整来保存已经学习过的知识,实现增量学习.本文将简化后的SOINN与SVM算法相结合,提出了增量式监督学习算法SOINN-SVM.
经典的SOINN算法采用双层网络,不仅计算复杂,而且在训练过程中难以判断何时停止第1层学习进入第2层学习.为了降低SOINN的计算复杂度,本文采用单层SOINN结构[17],而Furao等[18]已经证明单层结构的SOINN学习能力和双层结构一样.简化后的SOINN算法流程如下.
输入:数据集F,最大边年龄amax,去噪周期λ.
输出:神经元集合N,边集合C.
① 初始化神经元集合N={c1,c2},c1、c2的权重Xc1、Xc2∈F,是数据集合F中的2个随机样本,初始化边集合C⊆N×N为空集.
② 输入一个新的数据样本ξ.
③ 基于欧式距离查找N中与样本最近的2个神经元s1和s2,s1称为获胜神经元.
s1=argminξ-Xττ∈N
s2=argminξ-Xττ∈N{s1}
(1)
④ 计算神经元s1和s2的相似度阈值Ts1和Ts2.
(2)
式中,Nτ为神经元τ的所有邻居集合.若Nτ不为空集,则将与邻居神经元的最大距离作为阈值;否则,寻找与τ最近的神经元,并将两者的距离作为阈值.如果ξ-Xs1>Ts1或者ξ-Xs2>Ts2,那么为样本ξ生成新的神经元r,令N=N∪{r},Xr=ξ,然后返回步骤②.
⑤ 若s1和s2不存在连接关系,则为两者建立边连接关系,C=C∪{(s1,s2)}.
⑥ 更新获胜节点s1与邻居神经元节点连接的边年龄a(s1,k),即
a(s1,k)=a(s1,k)+1k∈Ns1
(3)
⑦ 更新获胜神经元s1权重,即
(4)
式中,m为神经元成为获胜神经元的次数.
⑧ 每学习λ个样本数据,进行一次去噪过程.检查C中所有边,若a(i,j)>amax,则移除该边,C=C{(i,j)}.同时,将孤立的神经元删除.如果神经元i的Ni=∅,则N=N{i}.返回步骤②.
最后得到神经元集合N和连接关系C.神经元的权重集合{Xk,k∈N}就是原型数据,是原始数据的压缩,代表了原始数据的拓扑分布情况.原型数据将被用来训练SVM分类器.
2.2.2 增量式监督学习流程
增量式监督学习算法SOINN-SVM的具体流程如下.
① 将ARE采集到的带标签数据按品牌分类.
② 每一类品牌数据各自经过一个SOINN网络进行数据压缩,每个网络都保留和更新对应类的原型数据.
③ 利用原型数据训练SVM分类器.
④ 利用SVM分类器进行识别.如果SVM分类器给出的概率结果大于阈值θ1,判为结果有效并输出结果;否则,判为可信度太低,无法识别.每有效识别δ条数据,就将它们作为带标签数据输入到SOINN网络中更新模型,进入步骤②.
在步骤③中,原型数据的数量远远小于输入的带标签数据.与直接使用完整的带标签数据训练SVM分类器相比,利用原型数据训练SVM分类器大大降低了训练的时间复杂度.
物联网设备种类繁多,更新快速,难以收集到完整的训练数据集.所以步骤④中将SVM识别后的数据继续输入到SOINN网络中,通过更新原型数据和重新训练分类器,不断提升品牌识别的准确率.
考虑到在真实网络环境中总会遇到未经过训练的新品牌设备,在步骤④中设定了可信度阈值θ1.步骤④中的δ如果取值较小可以提高模型更新速度,但会增加计算量;如果取值较大则会减少计算量,但同时也会降低模型更新速度.因此,根据不同的需求可以取δ值为100、500或者1 000.
3 基于文本相似度的型号识别方法
3.1 Jaro距离
Jaro距离用来表示2个字符串之间的相似度.对于2个字符串u1和u2,它们之间的Jaro距离计算公式为
(5)
式中,J为Jaro距离;l为2个字符串中相互匹配的字符数量;|u1|和|u2|分别表示2个字符串的长度;t为匹配字符中需要换位的个数.定义匹配阈值φ为
(6)
当u1和u2中的2个字符相同,并且它们的相对位置小于φ时,就认为这2个字符是匹配的.
本文利用Jaro距离计算型号关键字之间的相似度.Jaro距离取值在0~1之间,越接近1,表示2个字符串越相似.比如“WR740ND”比标准的型号字段“WR740”多了2个字符,它们之间的Jaro距离为0.905,而“WR740ND”和 “WR841”的Jaro距离只有0.676.可见Jaro距离具有较强的模糊匹配能力,少量无关的字符变动不会影响正确的匹配结果.
3.2 TF-IDF技术
TF-IDF是常见的用于挖掘文本关键词的方法,包含2个部分:词频TF(term frequency)和逆文本频率IDF(inverse document frequency).记文本集合为D,其中的单个文本为d,Dij为第i个文本的第j个词,那么定义词Dij的词频为
(7)
式中,nij为第i个文本的第j个词在该文本中出现的次数;ni为第i个文本中的单词总数.定义逆文本频率为
(8)
式中,|D|表示文档总数;|k:Dij∈dk|表示含有该词的文档数目.最后,定义该词的TF-IDF权重为
ωij=fijgij
(9)
可见,文本中的一个词出现的次数越多,而在其他文本中出现的越少,那么该词对这个文本就越重要.
引入TF-IDF可以增加正确的型号字段在匹配过程中的权重.型号字段通常都是字母加数字的组合,可以利用正则表达式([A-Z][A-Za-z]*-*[0-9]+-*[A-Za-z0-9]*)从文本数据中抓取型号关键词.但是在实际过程中正则匹配的结果会包含许多干扰词.比如词“′Win32NT”、“Ver-1”、“Oct2015WebViewer”,都是字母数字的组合形式,但都不属于型号字段.通过观察较多设备的文本数据发现,正确的型号词只会出现在该型号设备的文本数据中,而干扰词会在多个型号的文本数据中出现.因此,正确型号词的TF-IDF权重值会高于其他的干扰词.如表2所示,利用正则匹配从D-LINK路由器DIR868的文本数据中提取型号词,匹配结果包含了一些干扰词.然后结合D-LINK所有型号的词库进行TF-IDF计算,得到各个词的权重.从表2中发现,正确的型号词“Dir868”的权重为0.67,明显高于其他干扰词.将这种权重值引入匹配度计算中可以提高正确型号词对匹配的作用,从而提高匹配的准确率.

表2 DIR868文本中各词权重值
3.3 文本相似度计算方法
令待识别设备的品牌识别结果为b,那么在型号识别时就加载品牌b的型号特征库.型号特征库包含了利用正则匹配得到的词集合Wb(含有干扰词和正确的型号词)和所有词的TF-IDF权重值集合Mb,待识别设备的正则匹配结果为词集合Q.那么,待识别设备和特征库中型号p的相似度定义如下:
(10)
式中,Wb,p,i为b品牌p型号的第i个词;Mb,p,i为该词的TF-IDF权重值;Qj为待识别设备词集合的第j个词;J(Wb,p,i,Qj)为2个词的Jaro距离.计算特征库中的每个词与集合Q中词的Jaro距离,取最大值,并乘上该词的权重Mb,p,i.式(10)中,正确的型号词具有更大的权重值,对Υp的作用更大.但是每个型号的词库Wb,p的词数量不一定相同,需要对累加的相似度Υp进行归一化处理,得到归一化的相似度值,即
(11)


4 实验与结果分析
4.1 实验环境与数据采集
首先介绍实验环境,操作系统为Windows10,编程语言为Python3.6,编程工具为PyCharm,CPU为Intel i5-7500 3.4 GHz,内存为8 GB.使用Python脚本从IPv4网络中采集设备的80、443等端口数据,并打上品牌和型号标签.最终得到实验数据9 688条,包含30种不同的品牌和441种不同的型号.采用精确率P(precison)、召回率R(recall)和综合评分F1值来评估分类器的性能.定义如下:
(12)
式中,LTP表示预测为正的正样本数;LFP表示预测为正的负样本数;LFN表示预测为负的正样本数.精确率P反映了分类器预测结果的准确性,P值越高,预测为正的样本中实际为正的样本比例越高.召回率R反映了分类器的灵敏度,R值越高,所有正样本中预测为正的样本比例越高.
4.2 算法复杂度
本节将依次分析本文算法的时间复杂度和存储开销.
品牌识别模块中的算法是SOINN-SVM.在训练阶段,所有训练样本数据需要输入SOINN网络.SOINN每学习一个样本数据都要遍历所有的原型数据,因此SOINN的时间复杂度为O(nhv),其中n为输入样本数,h为原型数据的数目,v为特征长度.然后利用得到的原型数据训练SVM分类器,由于原型数据和SVM训练后得到的支持向量数属于同一个数量级,训练SVM分类器的时间复杂度为O(h2v)[19].因此,品牌识别模块在训练阶段的总时间复杂度为O(h2v+nhv).在识别阶段,测试数据经过SVM分类器识别设备品牌,时间复杂度为O(hv).
型号识别模块中通过计算匹配度识别型号.在训练阶段,需要计算各型号文档中词语的TF-IDF权重值来生成型号特征库.时间复杂度为O(nb(npx)2),其中nb为品牌数目,np为每个品牌的平均型号数目,x为每个型号通过正则匹配得到的平均词数目.在识别阶段,需要计算待识别设备与各型号的匹配度,时间复杂度为O(npx2).
算法的存储开销方面,品牌识别部分存储的是支持向量和原型数据,故该部分的存储开销为O(hv).型号识别部分的特征库包含了关键字段和对应的权重值,故该部分的存储开销为O(nbnpx).
本文通过精简特征长度和压缩训练数据,降低了特征长度v和原型数据数量h的值,从而减少了品牌识别模块中训练SVM分类器的时间复杂度.同时,h值和v值的变小,也减少了存储开销.在型号识别模块中,匹配度的计算只需遍历单品牌的型号特征库,将计算匹配度的复杂度从O(nbnpx2)降低至O(npx2).
4.3 性能对比
实验中比较了4种方法的存储开销、识别时间和准确率,实验结果如表3所示.实验中忽略了阈值θ1和θ2对实验结果的影响,即所有的识别结果都是可信的.第1种方法是IoTTracker,其他3种方法是在本文的品牌识别模块中分别采用SVM[20]、ISVM[21]和SOINN-SVM,其中ISVM是一种具有增量学习能力的SVM算法.从9 688条数据中选取70%的数据用于训练品牌分类模型,30%的数据用于测试,选取完整的型号文本数据生成型号特征库.表3中的存储开销包含了分类模型和型号特征库.

表3 四种设备识别方法实验结果比较
存储开销方面,IoTTracker的特征记录了DOM树中每一个节点的信息,所以该方法的特征库存储开销最大,为603 KB.SOINN-SVM利用数据压缩减小了分类模型的大小,存储开销为40 KB.基于SVM的3种方法的模型大小主要由学习到的支持向量数目决定,支持向量越少,存储开销越小.图3展示了3种SVM方法的支持向量数目随学习次数变化的曲线.这里将完整训练数据平均分为10份,依次输入学习.SVM每次使用已学习过的所有数据,ISVM和SOINN-SVM每次使用单份的数据进行增量学习.随着学习次数的增加,三者的支持向量数据都是增加的.其中ISVM和SVM的结果相似,学习所有数据后SVM的支持向量有407个,ISVM的有409个.而SOINN-SVM的支持向量最少,只有198个.这表明SOINN-SVM可以通过数据压缩减少模型的存储开销.
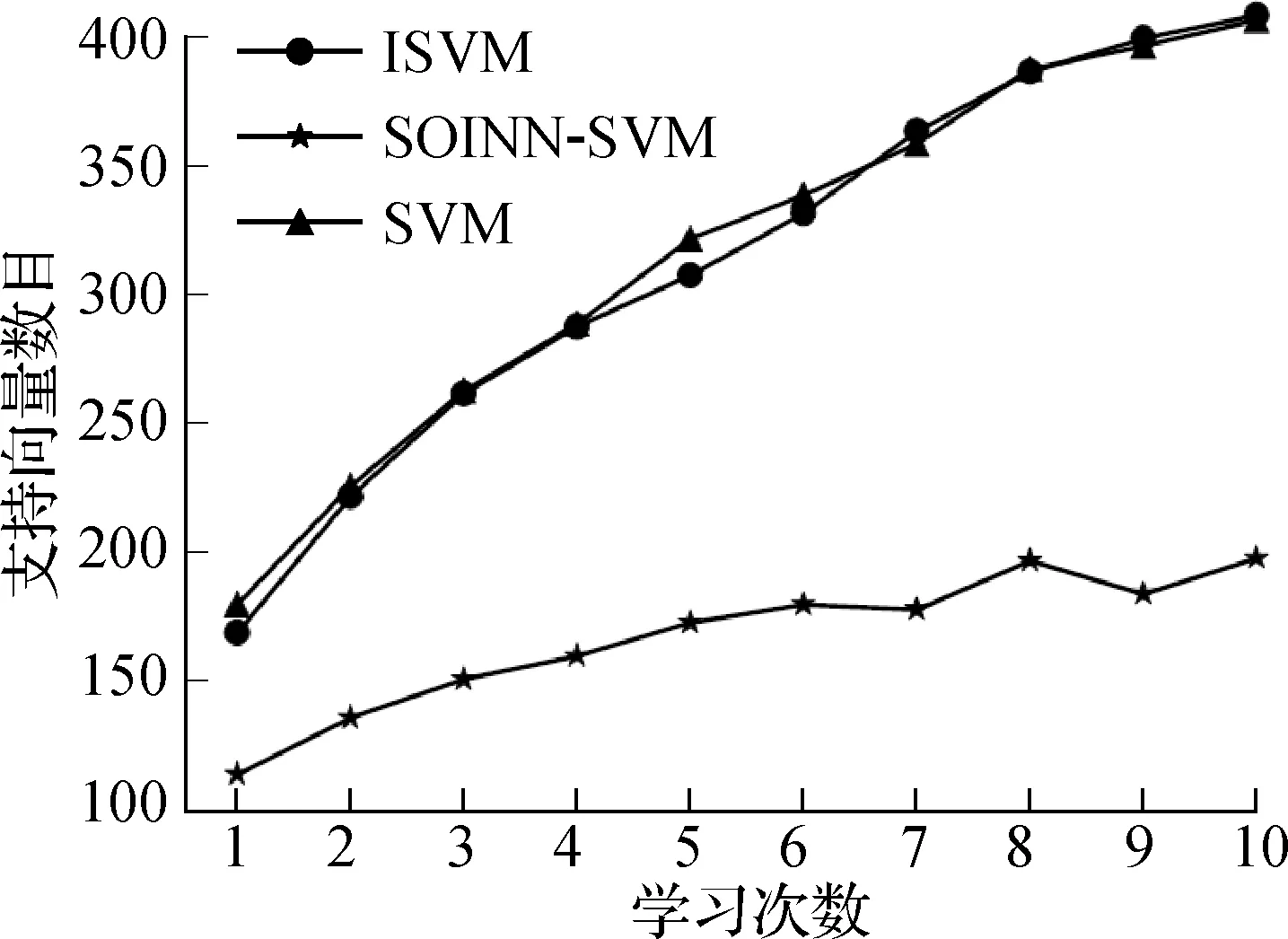
图3 支持向量数目变化曲线
在识别时间上IoTTracker耗时最多,达到了43.28 s,而其他3种方法都在0.37 s左右.因为IoTTracker每次识别都需要遍历完整特征库计算相似度,造成了大量的时间消耗.随着特征库的扩大,IoTTracker的识别时间会持续增加,而本文的分类器识别时间是稳定的.识别准确率上SVM方法最高,因为它的训练采用了完整的数据集.本文方法的准确率为95.9%,虽然略低于SVM方法,但具有更小的时间存储开销以及增量学习能力.
4.4 阈值确定
在实际的扫描过程中,会存在未发现过的新设备,本文分别设置阈值θ1和θ2来检测出未训练过的新品牌和新型号.当分类结果的可信度大于阈值时,结果被认可;否则,判为未发现的设备.品牌识别模块中以SOINN-SVM分类器的概率结果作为可信度,型号识别部分以文本相似度作为可信度.
完整的实验数据含有30种不同品牌的设备数据,该实验中选择20个品牌的数据进行模型训练,测试数据中加入未训练的10种品牌数据.阈值对分类性能的影响如图4所示.图4(a)是品牌分类性能与阈值关系曲线,图4(b)是型号分类性能与阈值关系曲线.随着阈值逐渐接近1,召回率R逐渐下降,准确率P逐渐上升.高阈值使得识别结果的可信度更高,但是会导致召回率降低,因此需要综合考虑准确率和召回率来选取阈值.图4(a)中,品牌识别的准确率最高可以达到98.7%,此时召回率只有92.1%.为了平衡2种性能指标,阈值选取在曲线交叉点处,此时θ1为0.95,准确率和召回率都达到了94.7%,综合分类性能达到最优.图4(b)中,随着阈值从0.9增加到1.0,型号识别的准确率逐渐上升,召回率逐渐下降.当阈值大于0.98时,准确率和召回率基本维持稳定,故选取θ2为0.98,此时型号识别的准确率为91.8%,召回率为95.6%.

(a) 品牌

(b) 型号
4.5 在线学习能力
本文提出的方法具有在线学习的能力,可以在识别设备的过程中不断提升分类器的分类性能.将9 688条数据平均分成10份.第1份数据作为带标签数据集训练SOINN-SVM分类器,剩余9份数据模拟数据流的形式依次输入SOINN-SVM分类器进行分类.每一份数据在识别后按照品牌类别输入SOINN网络.
图5是SOINN-SVM在多次学习中准确率P、召回率R以及F1值的变化情况.从图中可以看出,在仅用一份数据训练时,识别准确率只有88.0%,召回率只有84.1%.随着在线学习的次数增加,3项评价指标整体趋势都是上升的.在第4次学习后,分类性能略有下降,这是由于SOINN网络在更新和调整神经元节点时可能删除了部分学习结果,但继续保持学习分类性能逐渐上升.当学习到第10次时,各项性能指标达到最优,准确率达到94.8%,召回率达到96.3%,F1值达到95.4%.

图5 SOINN-SVM增量学习能力
4.6 IPv4空间探测
与基于文本特征匹配的识别方法相比,本文方法可以识别出更多设备.本节中利用真实网络的设备数据进行识别实验.考虑到IPv4空间太大,无法在短时间内完成全部探测,所以实验中缩小了搜索的网络空间规模.首先对69.x.x.x—71.x.x.x、131.x.x.x和132.x.x.x这几个大网段进行探测采集,网络空间地址共8 388万个,最终发现的在线并且可以采集到完整数据(包括各端口标语信息和交互页面代码信息)的设备终端为435 326个.分别利用ARE和本文方法识别数据,识别结果如表4所示,表中展示了数量最多的前5种设备品牌.

表4 识别出的不同品牌设备数量对比
从表4中发现,本文提出的方法可以识别出更多的设备,经计算总体上比ARE方法多识别出37.05%的设备.这表明基于交互页面DOM树结构的特征覆盖设备范围广,识别能力强.而传统基于文本特征的方法在标语信息缺失或者变化时就无法正确识别设备.
5 结论
1) 为了提升物联网设备识别方法的灵活性和准确性,本文将增量学习与监督学习相结合,提出了一种具有增量学习能力的在线物联网设备识别方法.利用SOINN-SVM方法训练品牌分类器,可以动态更新分类模型,同时又降低了运算存储开销.
2) 利用TF-IDF优化型号字段的正则匹配结果,结合权重值和Jaro距离计算与型号特征库的匹配度,降低了干扰词的影响.型号识别是在品牌识别结果上的二次分类,对单品牌型号特征库的遍历缩短了识别时间.
3) 实验结果表明,本文方法的识别准确率达到了95.9%.相比其他方法,可以多识别37.05%的设备,并且识别时间和存储开销更小.
