基于深度学习的文本匹配研究综述
2021-08-06曹帅
曹帅
(四川大学计算机学院,成都 610065)
0 引言
自然语言处理是人工智能领域的重要分支,其中包含了很多研究方向:文本分类、信息抽取、机器翻译和问答系统等。其中文本匹配是基础并重要的研究方向,其在问答系统、信息检索和对话系统等很多领域都发挥着决定性的作用。文本匹配在不同场景下的含义略有不同,例如在内容推荐上实质的任务为长文本之间的语义匹配,在这种情况通过使用主题模型,来获取到两个长文本的主题分布,再通过衡量两个多项式分布的距离去衡量它们之间的相似度;又比如在检索式问答系统中,则是通过对比问题和答案之间的相似度来召回最为相关的答案返回给用户。
文本匹配的发展经历着从传统方法到深度神经网络方法的演变。传统方法中主流的是BOW、TF-IDF、BM25等算法,它们在搜索引擎的原理中使用较为广泛。这些算法多为解决词汇层面的匹配问题,如BM25算法通过计算候选项对查询字段的覆盖程度来得到两者之间的匹配得分,得分越高的网页则匹配度越高。而类似TF-IDF这种方法,通过建立倒排索引可使查询变得很快,但实际上解决的只是词汇层面的相似度问题。这些方法实则上有很大的局限,解决不了更深层的语义或知识缺陷。而之后出现的基于深度学习的方法则在一定程度上开始解决这些问题。
研究者将介绍目前在深度学习中主流的三种文本匹配算法:基于向量相似度计算的方法、基于深度神经网络匹配的方法和基于预训练模型匹配的方法。研究者会详细阐述这三种方法的实现方式和原理,并对其各自的优势和局限性进行简要的阐述。最后会在此基础上总结目前亟待解决的问题和未来的研究趋势。
1 基于向量相似度计算的算法
传统方式中文本与文本之间的相似度计算有多种方式:BOW、TF-IDF和N-Gram等,这些算法通过对句子分词之后得到每个词语或词块的表示,之后再对所有表示取平均获取到整个句子的表示。假设两个句子分别为p1和p2,则通过以上方式获取到两个句子的句向量,再对两个向量求余弦相似度则获取到两个文本的相似度:
如果在两个句子中出现了同义词,虽然它们字面不同,但其表达的意思是一样的,传统方法则不能解决这类问题。词嵌入最早是出现于Bengio在2003年提出的NNLM[1]中,其将原始的one-hot向量通过嵌入一个线性的投影矩阵映射到一个稠密的连续向量中,并且通过建立一个语言模型的任务来学习这个向量的权重,而这个向量也就可以看作词向量。后面在2013年出现的Word2Vec[2]以及其他更多的NLP模型都运用到了这种思想。在Word2Vec出现后,基于词向量来做更多的NLP衍生任务也成为了一时的主流。Word2Vec中主要可以利用CBOW和Skip-Gram两种模型来分别学习向量的权重,它们的本质实质上都是对NNLM模型的改进。如图1所示,如果是用一个词语作为输入,来预测它的周围的上下文,那这个模型叫做Skip-Gram模型;而如果是一个词语的上下文作为输入,去预测这个词语本身,则是CBOW模型。

图1 CBOW和Skip-Gram模型
之前的NNLM模型其实存在比较严重的问题,就是训练太慢了。即便是在百万量级的数据集上,借助了40个CPU训练,NNLM也需要数周才能给出一个稍微靠谱的结果。Word2Vec中引入了两种优化算法:层次Softmax和负采样来加速训练,两者的本质分别是将N分类问题转变成log(N)次二分类和预测总体类别的一个子集。在词嵌入领域,除了Word2Vec之外,还有基于共现矩阵分解的Glove[3]等词嵌入方法。鉴于词语是NLP任务中最细粒的表达,所以词向量的运用很广泛,不仅可以执行词语层面的任务,也可以作为很多模型的输入,执行句子层面的任务。
使用Word2Vec这种词向量作为每个单词的表示之后,能够更好地解决之前所说的同义词问题。这种对每个词语取平均的方式是获取句子向量的最简单方式,但实质上其并没有很好地解决句子主题含义相似的问题,虽然两个句子字面可能很相似,但主题意思却完全相反。之后出现的很多研究人员提出了例如Sentence2vec和Doc2vec之类的方法,也有像Sentence-Bert[4]这样结合孪生网络和预训练模型获取句子向量的方式。由于目前神经网络的参数越来越多,在每次推测的过程中通过神经网络会消耗很多时间,而在实时性要求很高的情况下例如搜索引擎,将候选项文本都转化为向量存储起来,再做向量之间的相似度计算,并不会消耗很多的时间,所以怎么在这个方向提高效果是研究人员一直都在努力的方向。
2 基于深度神经网络匹配的方法
随着深度学习在近几年的蓬勃发展,很多研究开始致力于将深度神经网络模型应用于自然语言处理任务中。利用词向量来进行文本匹配计算,简洁且快速,但是其只是利用无标注数据训练得到,在效果上和主题模型技术相差不大,本质上都是基于共现信息的训练。为了解决短语、句子的语义表示问题,和文本匹配上的非对称问题,陆续出现了很多基于神经网络的深度文本匹配模型。一般来说,它们主要分为两种:表示型和交互型,下面将一一探讨。
2.1 表示型深度文本匹配模型
表示型匹配模型更侧重于对文本表示层的构建,会在表示层就将文本转化成一个唯一的整体表示向量,其思路基于孪生网络,会利用多层神经网络提取文本整体语义之后再进行匹配。其中表示层编码可使用常见的全连接神经网络、卷积神经网络、循环神经网络或者基于注意力机制的模型等,而匹配层交互计算也有多种方式:使用点积、余弦矩阵、高斯距离、全连接神经网络或者相似度矩阵等。一般会根据不同的任务类型和数据情况,选择不同的方式。
开创表示型匹配模型先河的是微软所提出的DSSM[5],它的原理是通过搜索引擎中的问题和标题之间的海量点击曝光日志,用深度神经网络将两者表达为低维的语义向量之后,再利用余弦距离来计算两个语义向量的相似度,最终训练出语义相似度的模型。这个模型不仅可以用来预测两个句子的语义相似度,又可以获得某个句子的低维语义向量表达。之后在DSSM的基础上又出现了一系列的模型,例如CDSSM[6]、MV-LSTM[7]和ARC-I[8]等,这些模型大体上的结构都是图2所示,只是将表达层或者匹配层换成了更复杂、效果更好的模型结构。
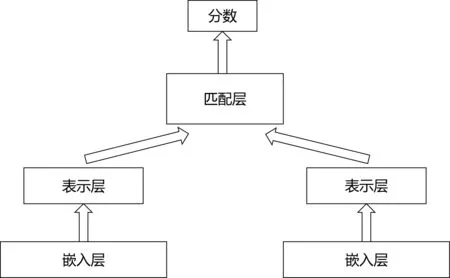
图2 表示型匹配模型
在表示型模型上做研究,主要基于以下两个方向:①加强编码表示层的模型结构,获取到更好的文本表示。②加强匹配层的计算方式。而基于第一点则出现了各种各样的模型。表示型模型可以对文本预处理后,先构建索引,这样就可以大幅度地降低在推理时候的计算耗时,但是其缺点也是显而易见:因为需要对两个句子分别进行编码表示,这样就会失去语义的焦点,从而难以衡量两个句子之间的上下文重要性。
2.2 交互型深度文本匹配模型
如图3所示,交互型模型和表达型模型是不同的思路,其摈弃了先编码后匹配的思路,在输入层就对文本先进行匹配,并将匹配了的结果再进行后续的建模。交互型模型的思想是先捕捉到两个文本之间的匹配信息,将字词之间的匹配信息再作为灰度图,然后进行后续的建模抽象,获取到最后它们的相关性评价。其中交互层主要是通过以注意力机制为代表的结构来对两段文本进行不同粒度的交互,然后再将各个粒度的匹配结果给聚合起来,得到一个表示这种信息的特征矩阵。而这里可采用的注意力方式也有很多,根据不同的注意力机制可得到相应的效果。之后的表示层则负责对得到的特征矩阵进行抽象表征,也就是对两个语句之间得到的匹配信息再进行抽象。

图3 交互型匹配模型
基于交互型的经典匹配模型有:MatchPyramid[9]、DRMM[10]和ESIM[11]等。之后的一些基于注意力机制的模型,在将模型变得更深同时交互层变得更复杂外,其实很多模型都只是在一两个数据集上搜索结构将分数提升了上去,导致这些模型在某个场景效果很好,但是到了另外的场景就效果不佳了。
交互型的文本匹配模型很好地把握了语义焦点,随着更深的结构和更复杂的交互出现,也能捕捉到更深层的语义信息,能对上下文重要性更好的建模。但也像上文所说,其实在预训练模型出现的很多复杂的交互型匹配模型,虽然结构复杂,也用到了很多复杂的注意力机制,但实质上在很多普遍的场景下,其实最简单的基于卷积神经网络或者循环神经网络的结构就能得到可靠的结果。交互型模型的缺点是其忽视了句法、句间对照等全局性的信息,从而无法由局部信息刻画出全局的匹配信息。
3 基于预训练模型匹配的方法
2018年谷歌公司所推出的BERT[12]模型大放异彩,在11项自然语言处理任务上都达到了最好的效果,并且远远地甩掉了之前的模型,从而将自然语言处理的研究带入了预训练模型时代。自注意力机制提出后,加入了注意力机制的自然语言处理模型在很多任务都得到了提升,之后Vaswani等人提出的Transformer模型,用全注意力的结构代替了传统的LSTM,在翻译任务上取到了更好的成绩。而BERT模型就是基于Transformer的,它主要创新点都在预训练的方法上,即用了Masked LM和Next Sentence Prediction两种方法去分别捕捉词语和句子级别的表达,并且在大规模的无监督语料下进行训练,从而得到训练好的模型。之后再利用预训练好的语言模型,在特定的场景和数据下去完成具体的NLP下游任务,由于Next Sentence Prediction这个训练任务是句子与句子之间构成的问题,所以利用BERT来做文本匹配是有天然的优势。
如图4,利用BERT来完成文本匹配任务的话,首先是需要将在首部加入[CLS],在两个句子之间加入[SEP]作为分隔。然后,对BERT最后一层输出取[CLS]的向量并通过MLP即可完成多分类任务。使用预训练好的BERT模型在很多文本匹配任务例如MNLI、QQP、MRPC、QNLI等上都达到了SOTA效果。
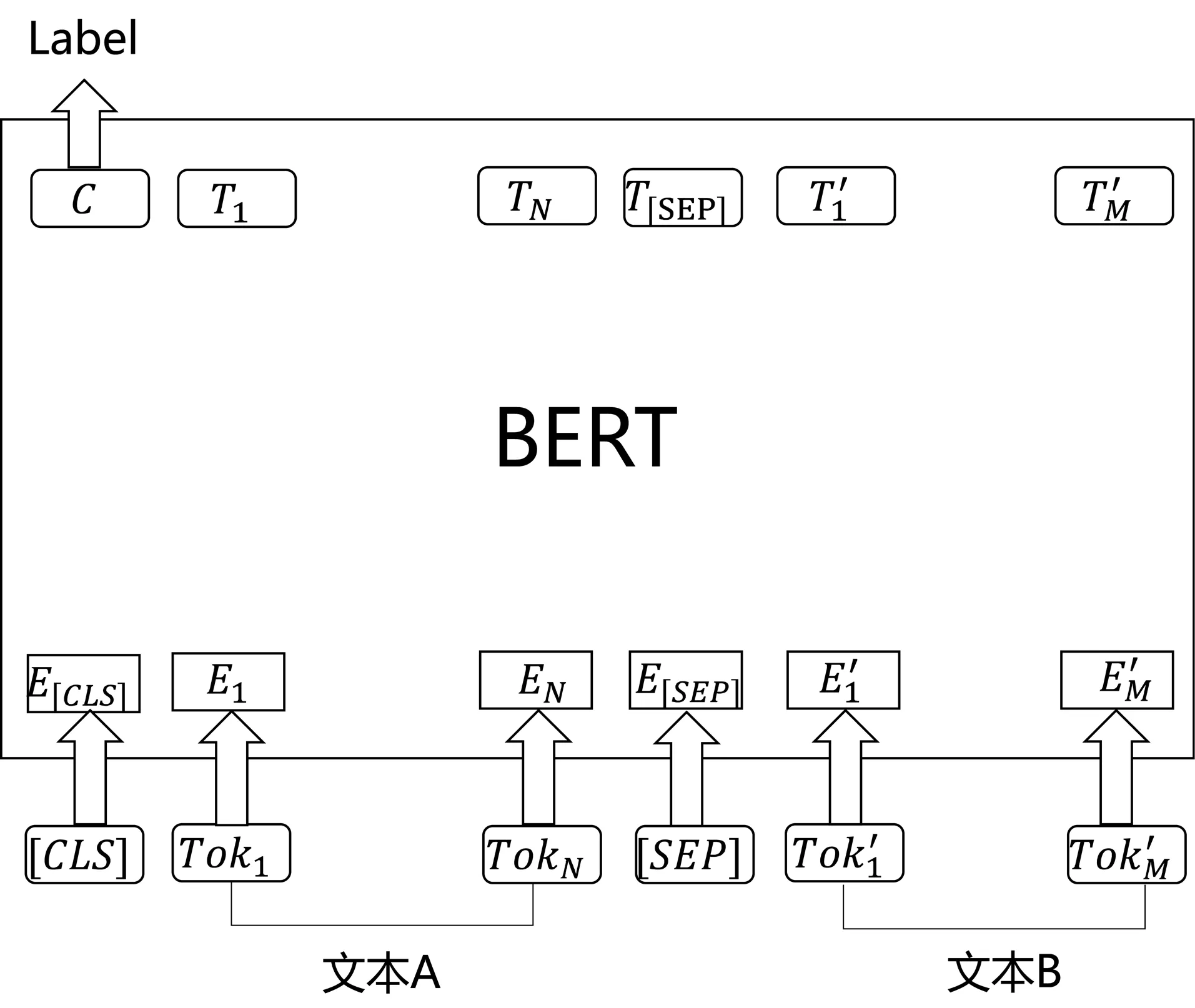
图4 使用BERT进行文本匹配
预训练好的BERT模型也可以直接拿来取最后一层输出作为句向量,但这样的效果甚至不如词向量,直接拿[CLS]特征的效果最差,可见BERT模型暂时只适合在特定的任务下微调,之后使用微调后的BERT模型来预测,这样才能得到最佳的效果。后续出现的Sentence-BERT,利用孪生网络的优势,可以利用训练后的BERT取的效果较好的句子特征,但依然没有直接使用微调后的BERT效果好。
BERT是最新的自然语言处理SOTA模型,后续也出现了很多类似于BERT或者在BERT上改进的预训练模型,其抛弃了传统的RNN结构,全面使用Transformer,可以并行训练,加快了训练速度,同时也能捕捉到更长距离的依赖信息。之前也出现过GPT[13]这样的预训练模型,但BERT捕捉到了真正意义上的双向上下文信息。当然BERT也有一些缺陷:例如超多的参数和超深的网络,导致BERT在预测时候其实速度很慢,对于实时性要求较高的文本匹配任务稍显吃力,BERT之后研究者们也在这方面做了很多工作。同时BERT在预训练中[MASK]标记在实际预测中不会出现,所以训练时用过多的[MASK]其实会影响到模型的实际表现。
4 结语
研究者探讨了深度学习时代以来出现过的可用于文本匹配的算法。基于向量相似度计算的方法是最为高效的方式,在以毫秒级严格要求的工业界,也是最容易被广泛运用的一种方法。但是如何将语句的语义含义、主题意义等更深于字面的信息嵌入到向量表示中,目前看来还是一个大研究方向。而基于深度神经网络的匹配方法,不管是基于表示型还是基于匹配型,其简单的思想和复杂的结构也对应了自然语言处理的发展趋势,但是目前很多模型其实都只是在一两个数据集上表现好,而在普遍的任务上泛化能力还不强,同理复杂的参数也是让想要应用这些模型到实际应用中的研究者望而却步,实际上工业界用到最多的还是最先提出的基于DSSM的改进模型,因为其简单、速度快,而且在大规模数据上训练之后效果也还不错。
随着BERT模型的出现,基于预训练模型的文本匹配算法也开始逐渐走上大舞台。这些预训练模型由于在超大规模的无监督语料上训练,同时拥有着千万级的学习参数,所以效果也远远地超过了之前的一些模型。但同样的问题是如何将这些大模型运用到实际生活中,也是一项很大的挑战。所以最近,已经有很多研究者开始不再纠结于去提高预训练模型的效果,而是研究如何蒸馏模型,让小模型也能学到同样多的知识。同时,BERT之类的预训练模型虽然能够利用已经学到的东西,去判断两个文本间的匹配度,但是对于一些外部知识却无法解决,所以一些研究者也开始尝试将诸如知识图谱之类的外部知识引入到预训练模型中。
文本匹配是自然语言处理中的一项重要任务,这三类算法也是研究者们在探索的长河中提出的重要代表而已,相信不久的将来将会有新的算法来将这项任务推到更高的高度。
