多分支卷积神经网络的FPGA 设计与优化
2021-08-02谢思璞魏榕山
谢思璞,魏榕山
(福州大学 物理与信息工程学院,福建 福州 350108)
0 引言
近年来,神经网络受到了广泛热议,成为了学术界和工业界的热门议题,Google、Microsoft 和Facebook 等科技公司都建立了相关的研究小组,以探索CNN 的新架构[1-3]。通过对CNN 架构上的创新改善CNN 性能,利用空间和通道信息,结构的深度和宽度以及多路径信息处理等方法引起了广泛的讨论。
在众多新型CNN 架构中,基于宽度扩展的多支并行的CNN 得到了国内外学术届的重视。KAWAGUCHI K等人提出网络的宽度是影响网络精度与准确度的一个重要指标[4]。通过在层中并行使用多个处理单元,可以得到比感知器更为复杂的映射。GoogLeNet 中的Inception模块是一种典型的多支网络架构,并使用了不同尺寸的卷积核[5]。2017 年,DEL COCO M 等人[6]利用多分支结构引入了并行的多尺度分析,减小了神经网络的深度,克服了过拟合问题。拓宽网络宽度的多支并行卷积神经网络在图像分割以及识别等任务中,提高了网络在不同尺度上的特征提取能力,受到了国内外研究机构的重视[7-9]。
如今,基于FPGA 的卷积神经网络加速器获得越来越多的关注[10-13],目前大多数都以切片的方式,映射至加速器中逐一计算。如果使用相同配置的加速器对多分支网络进行加速,传统映射多分支网络计算会造成硬件资源的浪费。没有针对各分支网络进行差异化资源分配,多分支卷积神经网络在进行时的并行效率也无法得到保证,这对整体网络模型计算将造成影响。本文分析和探讨了多分支卷积神经网络的性质和特点,并基于屋顶模型进行设计空间的探索[14],设计出一种多分支卷积神经网络加速器。
1 多分支CNN模型及参数
本文将以应用于HEVC 视频编码的帧内划分的多分支卷积神经网络ETH-CNN 为例,分析与探究多支卷积神经网络在参数差异影响下的硬件资源优化问题[15]。如图1 所示,该网络由三支卷积神经网络协同工作,各分支的卷积神经网络经过降采样层、卷积层和全连接层后输出。
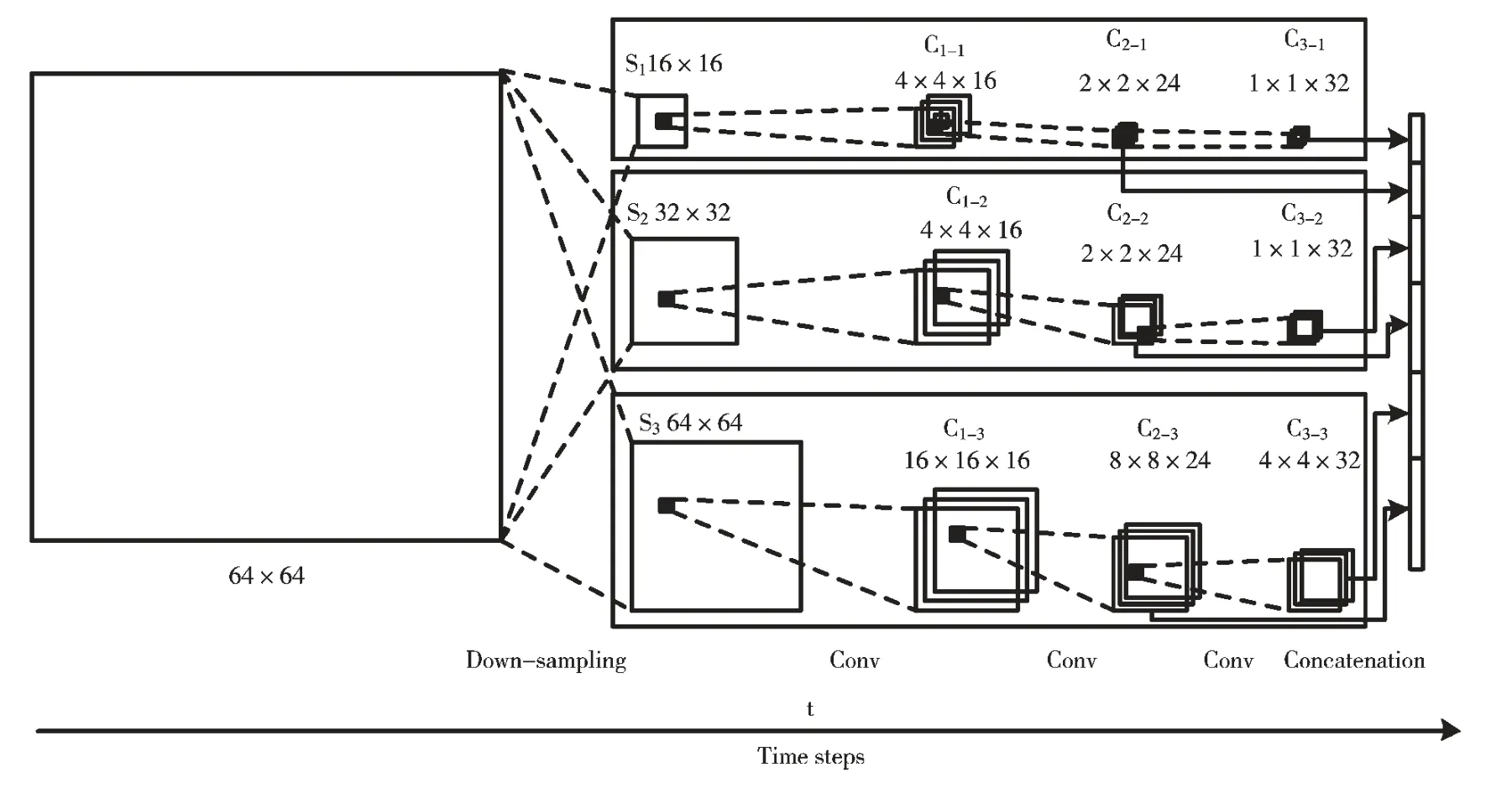
图1 ETH-CNN 图示
由于各分支卷积层的输入特征图尺寸不同,那么各分支网络卷积层的计算量也不同。以ETH-CNN 的各分支网络参数(如表1 所示)进行比较,经计算后的结果可以看出各分支的操作数相差甚大,各分支网络在进行并行计算所需的I/O 带宽以及硬件资源的分配需求不一样。使用相同的加速器对多分支网络进行加速,各卷积层将依次调用加速器进行计算,由于支与支之间卷积存在数据依赖,这将对整体网络模型计算造成影响。为了提升整体算力,为多分支并行卷积神经网络专门定制一种加速平台提供高性能计算是非常有必要的。
2 多分支CNN 加速器设计
2.1 CNN 加速器设计
本文将选择在卷积核的输入输出尺度上进行循环拆分,拆分的因子为Tm、Tn。外部的循环则负责调度,主要的作用是控制数据从外部DDR 加载至FPGA 的BRAM 缓冲区,将BRAM 数据写入外部DDR,同时控制数据的复用。内部的循环则负责生成FPGA 卷积计算单元。设计的卷积计算单元的并行度为Tm×Tn,并行Tm计算单元,每个计算单元中进行Tn输入数据与权重的乘累加操作,累加操作中采用加法树结构进行累加。在本设计中利用卷积计算在输入通道和输出通道之间的独立性,采用流水线操作,进一步加大系统的吞吐量。
为了实现高并行度,神经网络加速器通常在大量计算单元之间重用数据。在本设计中,将数据路由到不同的计算单元,从而降低系统计算延迟,为此采取了“前-后-前”的调度模式,从而使输入数据可以获得更大的数据复用机会。原先输入数据读取遵循切分先后,调整后的访问的次数将比原先少(Tn-1)次,从而可以减小数据的冗余访问。在输出复用的调度中,由于输出的结果数组与输入通道循环没有相互依赖性,因此可以将写入外部DDR 的输出结果操作置于输入通道循环外。此时,计算单元无需先从外部DDR 读取上次的输出结果。输出结果的中间值直接存储在片上的BRAM 上,本次计算无需上一次的计算结果,直接从BRAM 上读取数据进行累加,从而可以将输出数据的访问次数减少。
在本设计中,还将采用双缓冲机制,两块片上的缓存以乒乓机制进行数据的读取,从而可以让数据的传输时间被计算单元的计算时间所覆盖,使计算单元一直处在工作状态,提高系统的吞吐率。
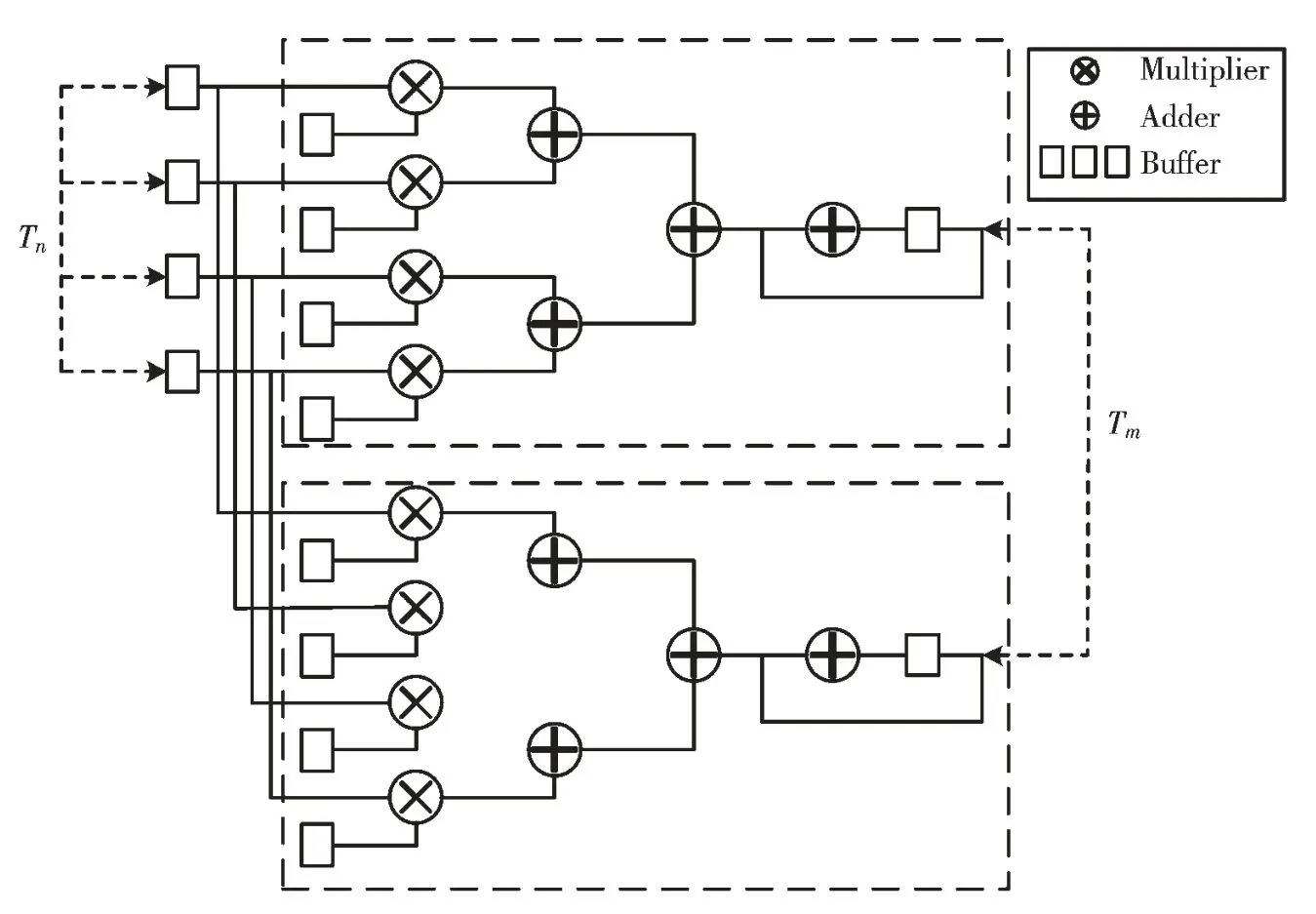
图2 加速器计算单元

图3 双缓冲机制
2.2 设计空间探索
由于多支卷积神经网络计算是同时进行的,计算和存储访问行为将变得更加复杂。在加速器的设计中,可以利用屋顶模型来解决多支网络模型和硬件平台相关的优化问题。为了并行化循环的执行,将循环展开,在硬件上并行化计算单元。硬件上并行化的参数称为unroll参数。展开参数选择不当可能会导致严重的硬件未充分利用。以单循环为例,假设循环的循环边界为M,并行度为m。硬件的利用率受的限制。
多支卷积结构已在先前给出。本文为三支CNN 都设计了并行度不同的计算单元。在进行一层计算时,三个计算单元同时并行执行,而对层与层之间的计算,则共用同一加速器,即加速器中含有三个并行的加速单元,分别对应三支的CNN,而这个加速器是层与层之间的共用模块。根据上文设计的卷积计算单元,分别对应三支CNN 输入输出通道的拆分因子〈Tm,Tn〉进行讨论。从整个系统层面上来看,每次卷积的执行周期与分支网络中执行周期最大的一支密切相关。
加速器的峰值性能的计算公式如式(1)所示。其中total operations 为多分支卷积神经网络计算总操作数,execution cycles 为加速器的执行周期,而在多分支CNN加速器中,卷积层的总执行周期与分支网络中执行周期最大的一支密切相关。CTC Ratio 是单位内存访问可以执行的操作数,total data access 为片上计算的外部数据访问量。在多分支CNN 加速器中,可以通过之前介绍的数据复用设计,降低对片外访存的次数,从而提高系统的CTC Ratio。

确定了多分支网络的并行策略后,要针对各项因素设立约束条件。由于加速器的计算峰值受到FPGA 片上DSP48E 计算资源的限制,因此其设计空间的限制条件为式(3)。此外,加速器的CTC Ratio 受到FPGA 片上BRAM的限制,所以其存储空间的限制条件为式(4)。

此外,也需要对循环展开的利用率进行约束,避免系统运行时出现过多的硬件资源处于空闲状态导致了硬件平台的资源浪费,对系统执行效率造成负面影响。为此,对各分支网络的循环展开利用率进行阈值约束,设α 为循环展开利用率,为其设定循环展开利用率阈值,舍去利用率值低的循环展开因子。
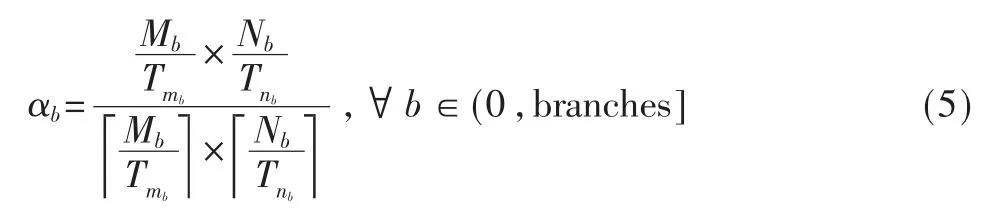
而在多分支卷积神经网络执行过程中,虽然整体系统的执行周期以各分支中执行周期最长的卷积神经网络为基准。但是,为了协调各分支卷积神经网络层与层之间的计算与数据的交换,对分支网络各卷积层的执行时间进行约束。根据式(6)可知,可以通过各分支计算操作数与展开因子作为评估条件,控制各分支网络中最快执行周期与最慢执行周期的卷积神经网络差值,保证整体执行效率处于最优效果。
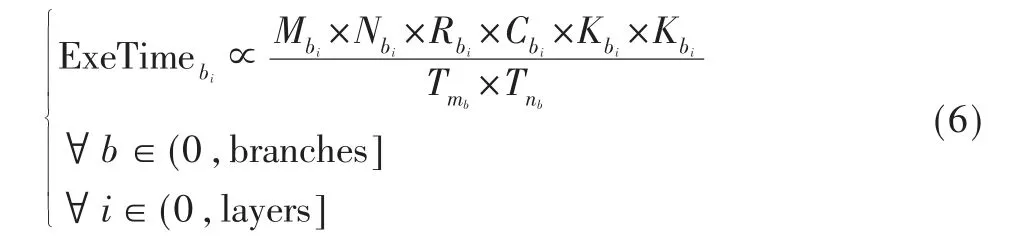
通过以上提出的峰值和CTC 率的计算方法,可以在屋顶模型中对不同的拆分因子〈Tm,Tn〉对系统造成的影响进行量化以及比较,采用枚举算法可以直观地在屋顶模型中看到设计的性能优劣。图4 中的每一个点都代表三组拆分因子〈Tm,Tn〉,在FPGA 有限的资源和设计空间限制下对所有的合法的设计进行了枚举,从图中可以直观地看到每个设计所能达到的计算峰值、CTC 率以及当前系统各分支并行度,每个点代表的是各分支网络潜在展开因子。所有的设计被FPGA 平台所能提供的计算峰值和带宽所限制,即图中的计算屋顶和带宽边界。
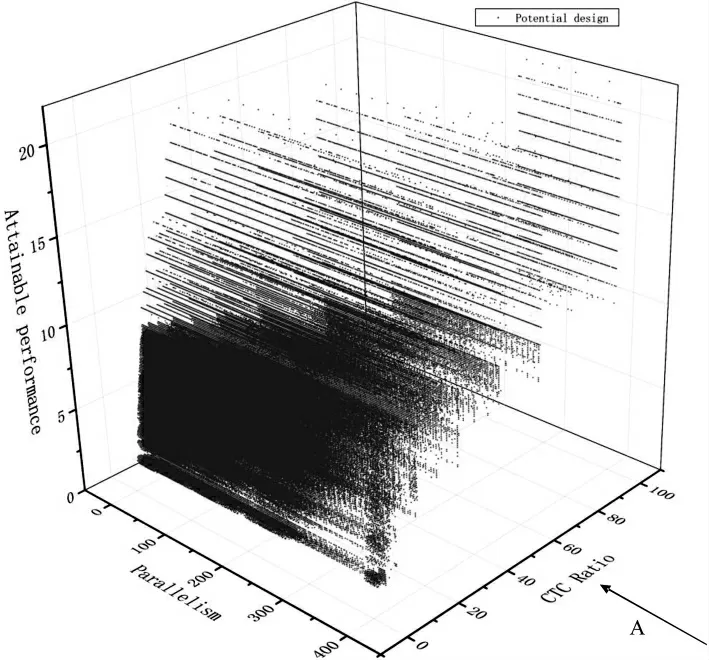
图4 枚举模型
由于本次设计的卷积计算单元是各卷积层之间通用的,即各分支的卷积层重复调用其特定的计算单元,因此需要统一的拆分因子。根据以上提出的方法,表1中列出了对于每个层来说最优的解。根据执行的周期数,在本设计中对所有的有效设计进行了枚举以找到优化的全局拆分因子。

表1 每层最优解及统一拆分因子
3 系统架构
图5 是所设计的基于FPGA 的多支卷积神经网络加速器系统。由于FPGA 芯片的片上SRAM 不足以存储所有权重及输入输出数据,因此采用DDR 和片上存储器的两级存储器层次结构,DDR4 DRAM 作为外部存储器,用来存储CNN 的输入输出数据及权重。
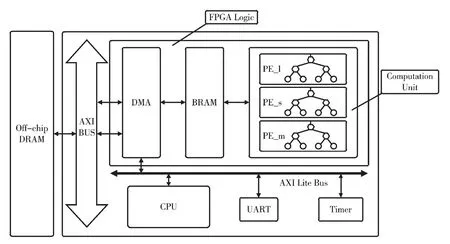
图5 加速器整体架构
通用CPU 用于初始化基于FPGA 的加速器和执行时间的测量,通过AXI4Lite 总线配置FPGA 逻辑中的DMA,从而调度加速器的运行,控制数据传输的大小与格式。FPGA 中的DMA 则通过AXI4 总线读取外部存储DDR中的数据。为了提高数据的传输速率,DMA 与加速器之间的接口为FIFO,进行数据的顺序访问,无需地址的判断。由于是三支网络同时进行计算,因此并行了三个计算单元,UART模块将加速器返回的结果传送到主机。
4 实验结果
为了评估本文的优化策略,通过前面介绍的ETH-CNN模型在FPGA 平台上构建多分支CNN 加速器,并在FPGA上实现。系统设计使用Xilinx 公司的ZCU102 开发板进行验证,芯片型号为XCZU9EG-2FFVB1156,FPGA 的工作频率为200 MHz。作为对比,PC 平台使用的是Intel i5-8300H CPU,主频为2.3 GHz,并采用相同的网络结构及测试数据进行仿真验证。实验结果如表2 所示。

表2 计算时间对比
最终的多分支CNN 加速器包含3 个加速单元,各单元并行计算不同分支的卷积输出。输入数据、输出数据以及权重数据的接口综合为使用基于AXI 总线的HP 高性能接口,采用的是Scatter-gather模式的DMA。当三支并行加速时,总的资源利用率如表3 所示。
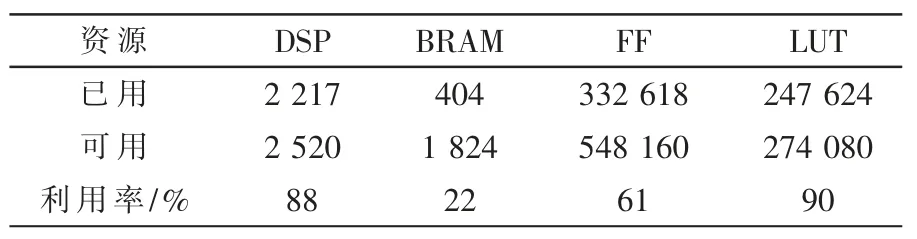
表3 多分支卷积神经网络加速器FPGA 资源利用率
此外,由于ETH-CNN模型较小,运算量约为0.56 MOP,因此在FPGA 上实现的吞吐量有限。因此,也通过GoogLe-Net 的Inception3a 结构来评估本文提出的多分支加速器映射方式,并与先前工作进行了比较。LCP[18]通过模型参数和数据位置差异将其按层簇的方式进行划分,并行于FPGA 的不同分区实现加速。本文方法以支为界限划分,将不同分支的卷积神经网络映射至FPGA 上并行执行,通过资源互补,采取不同的展开因子来配比各分支网络。从表4 中可以看出,在32 bit 的测试基准下,本文的工作取得了更有效的优化,取得了257.01 GOPS 的性能表现,性能为先前方法的1.31 倍。

表4 性能评估
4 结论
本文提出了一种基于FPGA 的多分支CNN 加速器的综合设计及优化方法。在给定多分支CNN模型和FPGA 平台下,鉴于加宽CNN 的结构导致的计算量增大,数据流更为复杂,针对并行网络进行更仔细的优化以及调度。利用屋顶模型进行了设计空间的探索,充分运用FPGA 中的资源,进行并行性设计和流水线设计。实验结果表明,本文的工作相比先前方法进一步提升了31%,取得了更有效的优化。
