基于Faster RCNN网络的仓储托盘检测方法
2021-07-28张亚辉杨林白雪
张亚辉 杨林 白雪


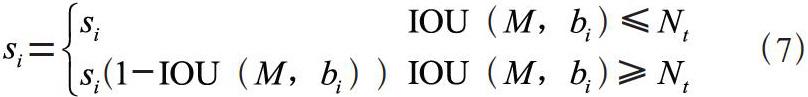
摘 要:为了解决传统仓储托盘检测方法泛化性差,检测精度低的问题。设计了一种基于Faster RCNN深度学习算法的仓储托盘检测模型,对算法模型进行了网络、数据增强处理以及特征提取方面的优化。自主拍摄仓储托盘图片并对其进行数据扩充,使用LableImage平台进行数据标注,在ResNet框架下进行网络训练,通过对比试验,改进后的模型性能高于其他常见目标检测模型,其准确率达到了96.5%,平均检测时间为76.9 ms,表明该方法能够满足工业生产环境中对仓储托盘的检测需求。
關键词:深度学习;仓储托盘;Faster RCNN;目标检测
中图分类号:TP183 文献标识码:A 文章编号:2096-4706(2021)02-0057-07
Abstract:In order to solve the problem that the traditional storage pallet detection method has the low generalization and low detection accuracy. A storage pallet detection model based on the Faster RCNN deep learning algorithm is designed,and the algorithm model is optimized in the aspects of network,data enhancement processing and feature extraction. Which can achieve independently take pictures of storage pallets and make data augmentation on them,use the LableImage platform for data annotation,and conduct network training under the ResNet framework. Through the comparative experiments,the improved model performance is higher than other common target detection models,and its accuracy rate reaches at 96.5 %,the average detection time is 76.9 ms,the results show that the method can meet the detection requirements for storage pallets in industrial production environment.
Keywords:deep learning;storage pallet;Faster RCNN;target detection
0 引 言
随着“中国制造2025”的提出与落实[1],中国的工业发展有了巨大的变化。为了提高工业生产效率,大量的工业机器人被引入工业环境中,代替人工完成大量危险、高强度的工业操作。
目前,仓储行业也在经历一场智能化的大变革[2],目前的仓储环境中常用的货物搬运设备是叉车,一般分为自动乘驾式和电动步行式,都需要人工参与,属于半自动化设备。托盘是现代物流集装的两大构成元素之一,是现代物流装卸、运输的重要载具,相比传统的货物载具,有高效率、低成本、安全便捷的优势[3]。智能叉车机器人是一种货叉式AGV(Automated Guided Vehicle),属于无人驾驶车辆的一种,其机械结构相对于普通AGV更加复杂,能够实现更加多样的功能。目前的智能叉车机器人大多采用机器视觉算法,该类算法对环境的适应性较差,一旦环境发生变化,则需要对原有算法进行重新训练,调整参数,无法满足智能叉车机器人的高适应性要求。
近年来,深度学习被用于许多领域,如人脸识别、对象检测等[4,5]。深度学习可以更好地提取特征,同时随着大数据时代的到来与计算机设备的提升,使得深度学习的应用成为现实。因此本文提出改进的Faster RCNN神经网络算法[6],采用自建的仓储托盘数据集训练模型参数,将模型应用到仓储领域。
1 Faster RCNN算法在智能叉车机器人仓储托盘检测中的应用
1.1 智能叉车机器人的仓储托盘检测
仓储托盘检测主要是目标检测算法Faster RCNN结合深度图像所构成的视觉处理系统,处理流程如图1所示。
使用TOF相机对工业实际场景中的仓储托盘进行拍摄获取深度图像,然后对采集到的深度图进行标注制作数据集;目标检测算法阶段先用改进后Faster RCNN网络对数据集进行离线训练,将训练好模型部署在叉车机器人上实现对仓储托盘的检测。
1.2 Faster RCNN网络框架
Faster RCNN算法是在RCNN[7]和Fast RCNN的基础上改进而来的,其网络结构如图2所示。Faster RCNN算法的创新点主要有两个:第一个创新点是提出了RPN(region proposal networks)网络,用来提取候选区域,代替Selective Search算法;第二个创新点是RPN网络与ROI Pooling层共享卷积层参数,加速了网络训练,且减少了网络参数量。Faster RCNN算法之前的RCNN算法都采用Selective Search算法来进行候选区域的提取,实验表明,通过Selective Search算法提取一张图片的所有候选区域需要大约2 s,但是改进后的RPN算法提取候选区域仅需要10 ms,大大提高了网络运行速度。传统卷积神经网络[8,9]提取候选框的方法有很多,如不同种类的目标候选框、CPMC等。
1.3 锚框机制
锚框机制是RPN算法的核心,RPN算法的原理是利用滑动窗口的方式在卷积神经网络层的最后输出的特征图上滑窗生成候选区域,即将经过卷积神经网络层生成的特征图作为RPN网络层的输入,然后在特征图上利用锚框机制生成推荐候选区域,如图3所示。
具体来说就是把Faster RCNN网络卷积层的最后一层所生成的特征图作为RPN网络的输入,然后用窗口大小是3×3,步长(padding)是1的卷积核在特征图上进行卷积操作。卷积核在特征图上滑动到每一个位置,则该卷积核中心在原图的映射点就称之为锚点,然后以锚点为中心,生成3种大小(1282,2562,5122)和3种长宽比(1:1,1:2,2:1)共9个锚框,然后针对每个锚框产生k组参数,包括2k个置信度参数(判断锚框中有无物体)和4k个坐标参数(当前锚框到预测框的变换参数)。
1.4 非极大值抑制
非极大值抑制(Non-Maximum Suppression,NMS)是目标检测后处理的一个经典算法,最早由Neubeck A提出,用来对两阶段目标检测算法的重复预测框进行去重并保存最佳预测框。NMS算法首先过滤掉小于阈值的候选框,然后不断以最大分类置信度的预测框和其他预测框做交并比(Intersection Over Union,IOU)操作,过滤掉IOU值大于预设交并比阈值的候选框,然后通过迭代这一过程寻找局部最优预测框。
2 改进的Faster RCNN算法
2.1 自适应锚框
自适应锚框生成网络包括两个分支,第一个分支是位置预测分支,第二个分支是形状预测分支,对于一个输入图片I,使用特征提取网络得到特征图Ni,在特征图上,位置预测分支能够产生一个目标存在位置的概率图,形状预测分支则是根据预先在数据集上利用K-means算法,对目标框进行聚类分析得到的目标框推荐尺寸。结合位置和形状预测的结果,当位置预测概率大于设定阈值的时候,网络会产生一系列高质量的预测框。
2.1.1 锚框位置预测
位置预测分支的任务是预测锚框的中心点坐标。对于一个输入图片I,使用特征提取网络MuRes-FPN得到特征图Ni,然后位置预测分支通过一个1×1大小的卷积将特征图Ni转换成一个位置得分图,根据这个得分图利用Sigmoid函数将得分图转换成位置概率图P(·|Ni),其中概率值表示目标中心在这个位置的概率。基于这样的概率图将整个特征图分为正样本区域、忽略区域和负样本区域,通过设定阈值 和 ,当概率值大于阈值的称为正样本区域,小于的称为负样本区域,中间的称为忽略区域。
根据概率图,将概率值大于阈值的称为正样本区域视为目标可能存在的区域,这种方法可以过滤掉90%的区域,保证较高的召回率。如图4所示,只在目标附近密集产生候选区域,其余区域都被过滤掉。该方法在几乎不增加计算量的同时产生了高质量的目标中心推荐区域,相比原始遍历产生候选区域的锚框推荐算法,极大的减少了计算量。
针对每一个特征图产生一个标签图,通过设定阈值和 ,其中参数 设为0.5,参数 设为0.2。如图5所示,当概率值大于,标签值为2,表示当前位置有锚框,区域内的像素作为正样本用来训练;当概率值小于 时,标签值为0,表示没有锚框,区域内像素作为负样本参与训练;介于两者中间时,标签值为1代表当前位置为忽略区域,不参与网络训练。在本文中,当得到输入图片的预测值之后,结合聚类产生的锚框尺寸,可以得到推荐的候选区域,用于网络训练。
2.1.2 锚框形状预测
在确定了锚框的位置之后,利用K-means算法聚类产生的候選框尺寸,结合位置信息生成预测框推荐。原始的Faster RCNN算法中是利用卷积神经网络生成的特征图进行预测的,锚框预设值为三个规定尺度{8,16,32},预设比例为{1:1,1:2,2:1},特征图上的每个位置都会产生9个锚框。根据式(1)和式(2)可以得到每个锚框映射到原图的区域范围:
其中stride表示某个锚框的预设尺度,s为锚框预设尺度,r为锚框的预设比例,heightij、widthij为锚框的高和宽。表1是原始Faster RCNN算法的感兴趣区域大小,可以看到覆盖面积大约是90像素到724像素。
指定锚框尺寸和比例超参数的方式过于死板,一旦数据集中有大量的目标尺度不符合预设尺度,如数据集中存在过大或过小尺寸的目标,如图6所示,那么此时的预测框感受野将不能够提供有效检测目标所需要的信息,导致模型检测精度大大降低。为了提升模型推荐预测框的合理性,使用K-means聚类锚框来生成训练所需的锚框形状。
2.1.2.1 K-means算法
K-means算法是对于给定数据集,按照样本之间距离的大小,将样本聚类为K个簇,算法的原理是使簇内的点距离尽可能小,使簇间的点距离尽可能大。假设划分簇为(C1,C2,…,CK),目标是最小化平方误差E,如式3所示:
其中μi为簇Ci的均值向量,x为数据集中的样本点,表达式如式4所示:
K-means算法先在数据集中产生K个随机初始点,然后再自行迭代K个簇。流程图如图7所示。
2.1.2.2 基于K-means的锚框形状预测
原始K-means聚类采用的是欧式距离作为聚类指标,可是这会导致尺度大的目标相对尺度小的目标更容易受到误差影响,考虑到后续筛选预测框与交并比有关,所以这里选择利用交并比作为聚类尺度,如式(5)所示。
其中d为目标框与当前聚类中心的距离,box为目标的标签框,center为当前聚类中心。
算法的计算流程不变,这里以PASCAL VOC数据集为例,对数据集目标框进行聚类,聚类产生的锚框如图8所示。
2.2 候选区域筛选策略
本文使用改进的Soft-NMS代替原来的NMS算法,Soft-NMS与NMS算法的流程大致相同,但是在处理重叠框的时候,Soft-NMS对于IOU大于设定阈值的重叠框不是直接滤除,而是降低重叠框的置信度得分,最终得到分数达到置信度阈值的候选框。Soft-NMS每次选择得分最高的候选框,抑制周围的候选框,周围的候选框与得分最高的候选框之间的IOU值越大,被抑制的程度就越大,这样就能够保留周围其他目标的候选框,抑制同一目标的候选框。Soft-NMS和NMS算法流程为:
伪代码中上方方框表示NMS的处理步骤,下方方框表示Soft-NMS的处理步骤。Soft-NMS通过降低置信度si,而非直接滤除bi,线性函数si表示为式(7):
由式7可以得到,IOU(M,bi)的值越大,对置信度的抑制程度就越大。此外除了线性函数si可以用于抑制重叠框置信度得分之外,Soft-NMS还提供了一个高斯权重函数来抑制重叠框的置信度得分。Soft-NMS将与最大得分的候选框重叠度大于给定阈值的候选框的分值与一个高斯权重函数相乘,高斯权重函数会降低重叠框的置信度得分值,重叠程度越高,得分衰减越严重,高斯权重函数表示如式(8)所示,实验中,参数σ设为0.5。
3 数据预处理
3.1 数据采集
仓储托盘检测网络模型训练所使用的数据集是一个自制数据集,在深度图像采集阶段,由叉车机器人使用TOF相机在仓库实地采集现场图片,为了使模型拥有更好的适应性,利用多种背景作为干扰因素;为了避免网络出现过拟合现象,所以对原始数据集采使用水平翻转、高斯滤波、亮度增强、高斯噪声、椒盐噪声等策略扩充数据集,由于深度图不利于观看,所以下面会给出数据增强处理后的原始深度图以及对应的伪彩色图片。具体如图9所示。
3.2 数据标注
训练Faster RCNN模型之前需要对数据集进行标注,采用LabelImg数据标注工具,设置托盘标签类别为pallet。标注后的标注信息保存为XML格式的文本文件,即PASCAL VOC的标准文件格式,由于我们的原始数据集为采集的深度图,不利于标注,所以这里先将数据增强后的深度图转换成对应的伪彩色图片,通过读取标注后的标注框信息对应到原始深度图,来完成我们的数据集标注。标注后的数据集共有10 568张图片,从中随机选取7 398张作为训练集、2 114张作为验证集、1 056张作为测试集(训练集:验证集:测试集=7:2:1),要求训练集、验证集和测试集之间无交集现象。
4 实验与分析
4.1 实验环境配置
深度学习网络模型通常对训练平台的配置有着较高的要求,Faster RCNN网络可以在CPU或者GPU上进行模型的训练,由于GPU的并行计算能力远超CPU,所以为了节约时间成本,选择在GPU上训练。将已经标注好的托盘数据集作为训练样本,Faster RCNN网络模型的训练平台具体配置信息如表2所示。
网络模型的训练框架为TensorFlow深度学习框架,其关键训练参数设置如表3所示。
网络训练参数bitchsize(每次并行计算的图像数)为128,动量值为0.9,权重衰减系数为0.000 5,训练集图片总数为7 398,总迭代次数为22 000,初始学习率为0.001。
4.2 模型评估
4.2.1 损失值
损失值是训练过程中样本的预测值和真实值的误差,由损失函数计算得到,损失值越小,则代表模型的预测结果越好。网络训练过程中保存损失值的训练日志,并根据日志信息进行可视化绘图,结果如图10所示。
由图可知,随着网络迭代次数的增加,损失值减少,在网络训练迭代到20 000步之后,損失值值已经趋向于0了,在0.1附近波动,说明网络模型训练效果良好。
4.2.2 测试结果
目标检测算法的主要度量方法有准确率(Precision)、召回率(Recall)和平均精度(mean average precision,mAP)等。以Recall为横轴,Precision为纵轴的曲线简称P-R曲线,P-R曲线下的面积称为精度均值AP(average precision),所有类别的精度均值的平均值为mAP,值越大,代表网络模型越好,准确率和召回率的计算如式(9)和式(10)所示:
其中,TP为被预测为正类的正类;FP为被预测为正类的负类;FN为被预测为负类的正类。
测试集图片总共为1 056张,用测试集测试网络精度,得到的P-R曲线如图11所示,其精度均值AP为96.5%,模型性能较优。
4.2.3 对比分析
为了验证本文算法(改进的Faster RCNN)的有效性,将本文算法与改进前的Faster RCNN算法以及目标检测经典算法YOLO v3和SSD在模型的准确率以及模型测试一张图片所需要的时间两个指标来测试算法性能,对比结果如表4所示。
由表4可知,改进后的Faster RCNN与改进前的Faster RCNN、SSD和YOLO v3相比,mAP值分别高出1.3%、4.9%和2.8%;FPS相比改进前提升了10帧/秒,虽然相比SSD和YOLO v3依然还有差距,但是改进后的算法已经满足了实时性要求。
4.2.4 检测效果
为了验证改进后的Faster RCNN模型的可行性,及其实时检测能力,将模型移植到叉车机器人实验检测平台,采用主板为英伟达TX2工控板,CPU为i7-9700k,主频为3.6 GHz,GPU为NVIDIA Pascal GPU,拥有8 GB的运行内存和32 GB的物理内存。使用工业相机TOF SR-4000在线实时获取仓储托盘的图像,实时检测仓储环境中仓储托盘的位置,由相机实时采集的图像并完成的效果如图13所示。
由上图可知,该模型能够实时在线完成仓储托盘的检测任务,其准确率达到96.5%,平均检测时间为76.9 ms,能够满足仓储环境中对仓储托盘的实时检测任务。
5 结 论
本文给出了一种基于Faster RCNN深度学习网络的仓储托盘检测方法,自主采集和标注仓储托盘图片,利用图像扩充策略来增加数据集的多样性,然后将数据集用于Faster RCNN、SSD、YOLO v3和我们改进后的Faster RCNN等网络进行训练,具有较高的检测精度,改进后的算法准确度达到96.5%,平均检测时间为76.9 ms。由于改进后模型参数依然庞大,改进后的模型勉强达到实时性要求,后续工作重点将在保持模型高精度的同时进一步提升模型的检测速度,以增强模型的实时性。
参考文献:
[1] 胡迟.制造业转型升级:“十二五”成效评估与“十三五”发展对策 [J].经济研究参考,2016(49):3-27.
[2] 徐翔.仓储行业正经历一场智能化大变革 [J].中国储运,2020(10):50-51.
[3] LYU Z J,ZHAO P C,LU Q,et al. Prediction of the Bending Strength of Boltless Steel Connections in Storage Pallet Racks:An Integrated Experimental-FEM-SVM Methodology [J/OL].Advances in Civil Engineering,2020:[2020-10-22].https://doi.org/10.1155/2020/5109204.
[4] PARKHI O M,VEDALDI A,ZISSERMAN A. Deep Face Recognition [C]//Proceedings of the British Machine Vision Conference.Swansea:BMVA Press,2015:41.1-41.12.
[5] LIU W,ANGUELOV D,ERHAN D,et al. SSD:Single Shot MultiBox Detector [J/OL].arXiv:1512.02325 [cs.CV].(2016-12-29).https://arxiv.org/abs/1512.02325.
[6] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[7] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[8] 卢宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述 [J].数据采集与处理,2016,31(1):1-17.
[9] ERGUN H,SERT M. Fusing Deep Convolutional Networks for Large Scale Visual Concept Classification [C]//2016 IEEE Second International Conference on Multimedia Big Data(BigMM).Taipei:IEEE,2016:210-213.
作者簡介:张亚辉(1994—),男,汉族,河南平顶山人,硕士研究生在读,研究方向:数据挖掘与人工智能。
