新浪微博用户和信息的信用评估
2021-07-24沈家润
王 梅,沈家润
(东华大学 计算机科学与技术学院 上海 201620)
0 引言
随着在线社交网络(Online Social Network,OSN)的流行和发展,社交网络在人们日常交流中发挥的作用越来越大。人们可以在社交网络中发布、获取和传递信息,可以和其他用户交互并构建自己的交际网络,并根据交际网络中获取的信息做出决策。然而,在社交网络中同时存在众多不真实的、误导性的信息,以及不可信的用户。为了甄别可靠信息,建立用户和信息可信度的评估机制具有重要意义。
目前,对于评估社交网络中用户和博文的研究,大都是以如Twitter、Facebook等国外的社交网络平台为研究对象[1-4]。新浪微博作为全球最大的中文社交网络平台之一,在规模、使用人群、发表设置和用户交流模式等方面与国外社交网络存在显著差异。
本文针对新浪微博的环境,在CoRank算法[5-6]的基础上,引入“点赞”这一关系完善该算法,定义了“带有点赞的复合动作”等复杂场景,讨论了这些场景在社交网络模型中所代表的语义以及相应的权重计算方法,针对其中的数据缺失问题提出解决办法,最终提出 SWCoRank(Sina Weibo CoRank)算法。进一步,基于采集到的真实新浪微博数据,对收集到的用户和博客进行信任评估,通过实验验证所提SWCoRank的性能。在实验结果分析中,一方面通过对PageRank[7]和TURank[8]等当前主流方法对相同的数据集进行计算并将结果相互比较分析,证明SWCoRank的有效性。另一方面,通过抽样对样例用户和博文进行分析和说明。
1 相关介绍
1.1 新浪微博与Twitter的区别
虽然新浪微博和Twitter都是在线社交网络,在功能上是相似的,但是他们有很多方面是有区别的,这些区别使得在研究的过程中,会产生诸多的不同和挑战。
1)Twitter的全球化和新浪微博的本地化
虽然 Twitter是一家美国公司,但是 Twitter的用户来自世界各地,超过70%的浏览量是在美国以外的地区发出的[9]。由于Twitter用户的国家、地域和文化有很大的差别,话题分离的现象还是比较普遍的。而绝大多数的新浪微博用户来自中国,其用户在文化上更加相似,在地域上也更加接近。因此,新浪微博的用户在公共议题上,相比Twitter,有更高的共鸣和参与度。
2)粉丝分布的不同
按照Han等人的统计计算[10],对于关注关系,新浪微博中粉丝分布的基尼系数更高。这就意味着,少数几位很受欢迎的新浪微博用户会吸收大量的粉丝。具体来说,Han统计结果表明,有0.1%的新浪微博用户吸引了整个社交网络内50%的粉丝。而Twitter的粉丝分布并没有这么夸张,受欢迎的 Twitter用户也不会吸收像新浪微博那么多的粉丝。
将这两条不同点放在一起分析,在新浪微博中,一个受欢迎的用户或者一条很热门的博文能收到大量的关注和浏览量。考虑到新浪微博更大的规模,这一特征使得部分数据的收集和处理工作变得更加困难。
3)发表设置的差异
在新浪微博与Twitter这两个平台中,部分动作的语义和功能是不同的。以“评论”这个动作为例,Twitter用户可以使用评论的动作来完成分享、传播评论内容的目的,而在微博环境下,评论的功能不能满足Twitter环境下分享的功能,在微博中,这个功能被部分地用“转发”所替代。基于这一差异,新浪微博的转发行为具有部分Twitter中评论回复的功能。
4)字数限制
Twitter有这样一个规则:每一条博文的字数不能超过280个字母,因此,其鼓励用户们发送短信息。新浪微博则取消了字数的限制,允许一条博文包含丰富的信息。因此,两个平台的交流模式、传递的信息量和用户的交互频率是不一样的。
将以上两点结合在一起,一些使用在Twitter上的算法和一些使用到发表、转发和评论的关系的模型,将这些算法和模式直接使用在新浪微博上面,是存在歧义和不合适的。
1.2 CoRank算法
CoRank算法[5-6]是目前较为先进的社交网络信用评估算法。其针对Twitter环境,通过关注、评论、转发、推文发表、推文被发表和@的关系,对Twitter中的用户和推文进行信用评估,其算法过程如图1所示。

图1 CoRank算法的过程Fig.1 Process of CoRank
整个CoRank分为四个阶段:
1)矩阵构建。构建的 U、M、N、T四个矩阵分别代表用户之间的关系、博文对用户的动作、对博文动作、博文之间的关系。U矩阵是|U|×|U|大小的矩阵,|U|是样本用户的数量,使用用户之间的关注关系,如果用户样本中用户uj关注了用户ui,那么在U矩阵的第i行j列填充权重wfi。T矩阵是|T|×|T|大小的矩阵,|T|是样本博文的数量,使用博文之间的评论、转发关系,如果博文样本中博文bj是博文bi转载贴,或者博文bj是博文bi评论贴,那么在T矩阵的第i行j列填充权重wr或者wc。M矩阵是|U|×|T|大小的矩阵,使用博文对用户的“@”和“被发表”的关系,如果博文bj@了用户ui,或者博文bj是用户ui的作品,那么在M矩阵的第i行j列填充权重wmi或者wp′。N矩阵是|T|×|U|大小的矩阵,使用用户对博文发表的关系,如果用户uj发表了博文bi,那么在N矩阵的第i行j列填充权重wp。CoRank算法没有使用到点赞这一关系,点赞动作是从用户发起,指向博文的动作,应将点赞的权重放入N矩阵中,本文所做工作的重点之一,就是将点赞动作加入到模型中,进而改造N矩阵。
2)向量计算。用P、Q向量表示用户样本和博文样本的信任值(trust value),P、Q向量的维度分别是为|U|和|T|。通过公式:

表示下一代的Pi′+1、Qi′+1向量是由上一代的iP、Qi向量与四个矩阵加权求和得到,α和β为常数,[6]中取α=0.2,β=0.6。通过这两个公式,在每次计算中,用户和博文所对应的信任值在网络模型中通过有向边传递给对应的节点,使信任值在网络模型中互相流动。
3)函数映射。上一阶段计算得到的P′、Q′向量需要经过Sigmoid函数

的计算得到新的P、Q向量,k和x0是常数,是通过实验效果自行调整的。映射函数使用的目的是将用户和博文的信用度估计值映射到 0到 1的范围之内,防止用户和博文的信任值差距过大,信任值分布过于不平衡。
4)判断收敛。在得到新的Pi+1、Qi+1向量后,与上一轮得到的iP、Qi向量进行比较,判断是否收敛,判断方法是使用斯皮尔曼等级相关系数(The Spearman's rank correlation coefficient,SRCC),它已被广泛用于测量两个集合之间的差异[11],其公式为:

其中xi和yi是用户ui或者博文ti的前后两代不同的排名结果,N为样本集合的总数。由此得到一个数据集内用户和博文的信任值。若当前的Pi+1、Qi+1向量与上一轮的Pi、Qi向量用 SRCC计算得到的系数uρ和tρ,都大于设置的阈值uє和tє,则整个迭代结束,退出循环,否则进入下一轮迭代,P、Q向量更新。
2 SWCoRank算法
如上所述,在新浪微博与Twitter平台中,部分动作的语义和功能是不同的。对于一篇博文来说,它可以接收到来自其他用户的三种类型的互动:点赞、转发和评论,我们可以通过用户们对一篇博文所做的行为来判断此博客的可信程度。特别是“点赞”这一行为可以清楚地反映博文的互动者对于博文的信任程度,信任度较高的博文会受到更多的点赞,信任度较高的博文也会通过被发表的关系使得博文的作者也值得信任。当“点赞”与同一交互者发起的其他两个动作(评论和转发)结合在一起时,信任传递的值应该会更大。按照此想法,我们定义了如下权重机制。
2.1 单一行为与复合行为权重
一个用户对于一条博文的行为被划分为“单一行为”和“带有点赞的复合行为”。“单一行为”指的是一个用户对博文进行的“点赞”,或“评论”,或“转发”的动作,权重用符号wl、wc、wr表示。以下是三种“带有点赞的复合行为”情况,分别是同一个用户对一条博文进行“点赞+评论”,“点赞+转发”和“点赞+转发+评论”的情况。对于这三种关系所代表的权重,分别用wl&c、wl&r、wl&c&r表示。
按照“点赞更能反映出用户对于博文的信任”的假设,我们对“单一行为”的权重设置:

带有点赞的复合动作的权重应该大于在单独时行动的权重之和,用来表示一个用户对于博文较高的信任,用公式可描述为:

2.2 N矩阵改造
在对N矩阵经过改造后,N矩阵中的元素
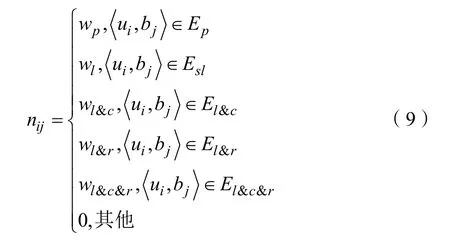
wp表示发表关系的权重,Ep、Esl、El&c、El&r、El&c&r分别表示所有博文发表关系的集合、所有“单一点赞”(single like)关系的集合、所有单个用户对一条博文“点赞+评论”、“点赞+转发”、“点赞+评论+转发”关系的集合,当用户ui对于博文tj没有以上提到的关系时,所属的元素位置值为0。
由于在构建N矩阵时,一个用户的评论和转发如果和点赞出现在一起,他(或她)的评论和转发就被合并到“带有点赞的复合动作”一起,其关系权重被算入N矩阵中,所有T矩阵中,存放的是独立的转发和评论动作,T矩阵的元素为:
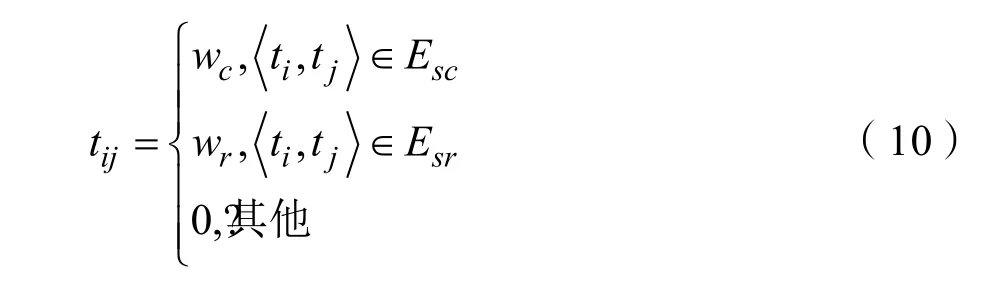
Esc表示所有“独立单一的评论”(single comment)关系的集合,Esr表示所有“独立单一的转发”(single repost)关系的集合,如果博文uj对于博文ti没有以上提到的关系时,所属的元素位置值为0。
2.3 数据缺失问题
一方面,部分微博用户和博文的粉丝数量和互动数量都比较大,在建模时不能全部纳入计算。另一方面,由于反爬机制,不能得到完整的用户和博文的信息。具体来说,如果博文的评论数超过20条,最多只能获取到20条评论的信息,但评论的总数可知。如果用户的粉丝超过4 000人,最多能获取到4 000人的信息,同样粉丝总数可知。
用wf′来表示对关注的权重wf在调整过后的权重,用公式
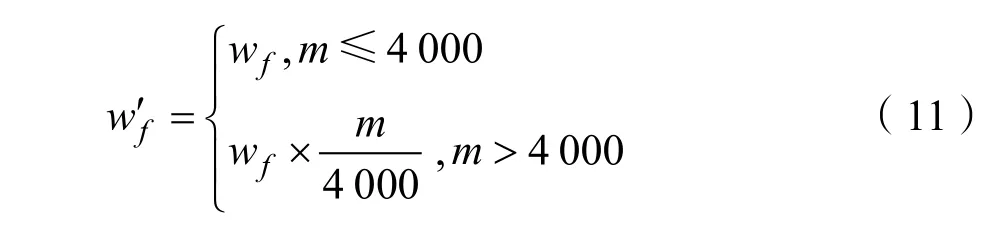
表示,m是粉丝的总数。
若想得到用户对博文的“点赞+评论”的合理的权重,用wl′&c来表示对wl&c调整过的权重,用公式
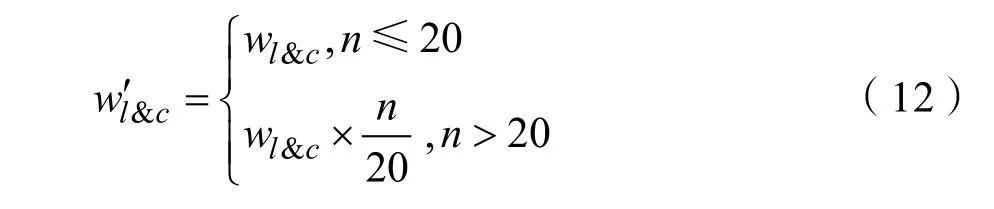
表示,n是评论的总数。
从上述公式,获取权重数据,根据权重生成矩阵,调用公式(1)得到用户的信用评估,公式(2)得到博文的信用评估,并经过1.2节中函数映射步骤,反复迭代直至信任值收敛。
3 结论
3.1 实验1
编写爬虫对微博用户和信息进行数据收集,抽样出10 000个用户以及他们发表的55 392条博文作为数据集,对用户和博文使用SWCoRank进行信用评估。
选取四个入度相似的用户,出于隐私考虑,使用A、B、C、D来分别表示这四个用户。如表1所示,是用户A、B、C、D的排名结果,排名的数值越小,表示用户的信任值越大,用户的排名越靠前。用户C和用户D收到了很多的关注和互动的连接,而用户B发表了很多博文。虽然与这四个用户相关的节点总数相似,但这四个用户的排名却截然不同。

表1 用户A、B、C、D的排名结果Tab.1 The ranking Results of Users A, B, C, D
对这四个用户信息的具体分析,如图2所示。
如图 2(a)所示,四个用户的粉丝根据他们的排名结果被分成了五个排名级别,每一个排名级别的粉丝数都是不一样的。比如,用户A的粉丝中,有293人的排名在10 000个用户的样本中,是在前2 000名内的,有120人的排名是在前4 000名到前2 000名内的。
将用户A和用户B比较,他们的粉丝数相似,但用户B的粉丝有更多高信任值、排名靠前的粉丝,而用户A的粉丝们的排名分布比较分散,换句话说,用户B的高信任值的粉丝占比高于用户A的高信任值的粉丝占比,这一结果影响了用户A、B的排名。将用户A和用户D相比,他们两人的粉丝排名分布的趋势是大致相同的,但是用户D的粉丝数在每一个级别都比用户A多,这也是用户D的排名要靠前于用户A的因素之一。
如图 2(b)所示,四个用户发表的博文也根据它们的排名结果被分成了六个排名级别。将用户B和用户C的博文排名分布进行比较,用户C发表的总博文数要略微少于用户B发表的,但用户C发表的大多数博文都属于排名级别最高的一组,这是用户C的排名比用户B更靠前的因素之一。将用户A和用户D比较,他们博文的排名分布趋势大致相同,但用户D发表的博文数要多于用户A发表的博文数,这也影响了是用户A、D的排名。
图2(c)显示了给用户A、B、C、D的博文点赞的用户的排名分布,同样将这些用户根据他们的排名结果分成五个排名级别。将用户 A、用户B和用户D的数据相比,给用户B博客点赞的用户超过半数都位于信任级别最高的那一组,这是用户B的排名相对用户A更高的因素之一。尽管给用户D博文点赞的用户要远多于用户B的,一方面是由于上述提到用户 B、D的粉丝和发表博文的数量和排名分布的因素,另一方面,给用户B的博文点赞的用户中高信任值的用户的数量也是一个影响因素。将用户A和用户D的数据相比,我们可以看到,除了用户分布,互动用户的数量也是影响结果的因素。
图2(d)显示了为用户A、B、C、D的博文评论和转发的用户的排名分布。比较用户A和用户B,或者用户A和用户D的用户分布,给博文评论和转发的用户的排名分布和数量是两个重要的因素。但对于用户C来说,相比其他样本用户,他(或她)没有收到高级别用户的转发和评论,也没有很多的用户对他(或她)的博文转载和评论,但是用户 C的最终排名是四个用户中最高的。一方面,是由于评论或者转发关系在整个模型构建中,我们并没有给予这两种关系很高的权值,使这两种关系发挥过大的作用。另一方面,一些单个的关系的影响是有限的,最终结果是由多种关系和因素或多或少、或强或弱的共同作用的结果。
3.2 实验2
将相同的数据集用 PageRank[7]和 TURank[8]计算。PageRank只使用到了关注关系。TURank使用到的数据关系有关注、发表、被发表和转发。SWCoRank使用除此之外的点赞、@、评论等关系来构建用户网络和博客网络,用户和博客之间由发表、被发表、点赞和@的关系耦合而成。经过三个方法的计算得到的结果后,每组方法得到的前100名用户中,有56位用户是重合的,说明三种方法在对用户进行评估时,都具有一定的科学性和趋同。
从表2,表3可以得到结论:由于PageRank只考虑了关注关系,TURank不考虑点赞、@和评论的关系,使得部分用户的排名结果与SWCoRank得到的结果存在较大的差异。在社交网络中,更多关系的加入使得用户和信息的评估更加客观。
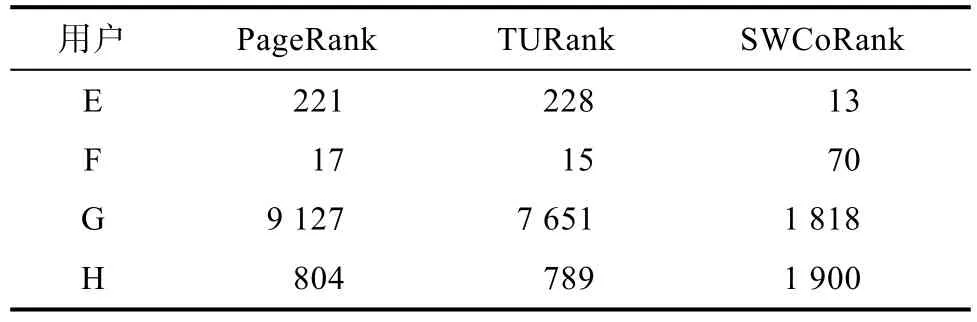
表2 四位用户的PageRank、TURank和SWCoRank排名Tab.2 Ranks of Four Users by PageRank,TURank and SWCoRank
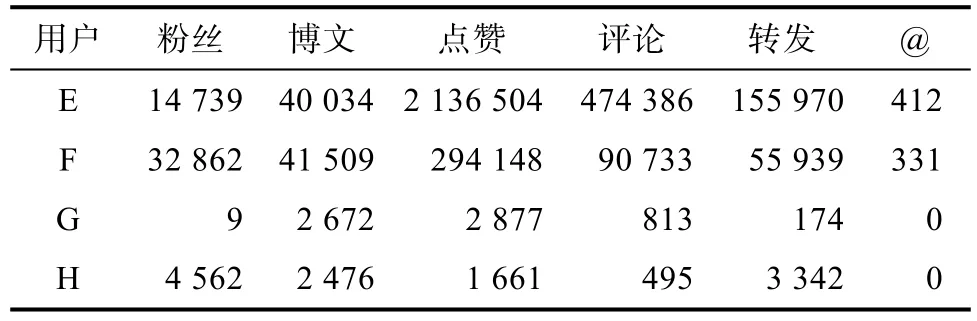
表3 四位用户的各类数据关系及统计Tab.3 Statistics of Four Users
3 结论
本文针对新浪微博环境,提出SWCoRank算法,对微博中的用户和信息进行信用评估,并通过实验验证,得到SWCoRank的特性。接下来的研究中,将会对文本内容进行评估,使用基于图结构分析为主,基于文本内容分析为辅的混合方法,对微博用户和信息进行信用评估。
