基于知识蒸馏的分布式神经网络设计
2021-07-09郑宗新
郑宗新
(重庆师范大学计算机与信息科学学院,重庆 401331)
0 引言
随着深度学习的发展,深度学习在生活中的应用越来越广泛。面对复杂的任务场景,深度学习的运算量也随之增大。现有关于神经网络的分布式研究多是关于训练阶段的,关于神经网络推理阶段的分布式研究较少。推理阶段运算量较大的解决方法一方面是通过优化网络结构[1-4],设计高效简洁的模型来减少运算量;另一方面通过分布式架构使得多设备协同工作增加运算力。在推理阶段的分布式研究主要是通过不同的设备间(边缘节点和云服务器、边缘节点和边缘节点)的相互协助,加快边缘节点推理速度。
基于动态卸载的分布式[5-7]网络设计通过分析神经网络的层的运算量,把神经网络模型纵向划分为两部分,运算量较大的卷积层部分放在云服务器运算,利用云服务器计算速度快的特点,在云服务器计算后将计算数据发送到边缘设备继续另一部分运算量较小的计算,将计算延迟和通信延迟进行平衡,得到最优化的计算速度。另一种方法是通过将特征图进行区域的划分[8-9],将输入数据横向划分为不同的区块发送给不同的设备进行运算,最后一层时进行拼接。每个设备的运算量都较普通运算减少了,因此运算速度获得提升。国内的相关的研究主要是通过动态卸载,将不同阶段的运算放置于不同的设备,从而并行计算[10]。
以往的分布式推理研究主要在提升运行速度方面,容错率较低,一旦通信中断便无法完成推理。在无人机、自动驾驶等方面是无法接受的。对此本文提出一种基于知识蒸馏的神经网络设计方法,与其余设备协同运算时具有较高的准确率,当通信不稳定时可离线运行,有着可以接受的准确率。
1 分布式神经网络设计
1.1 知识蒸馏
知识蒸馏(Knowledge Distillation,KD)[11]是通过将训练数据输入一个训练好的、高准确率的教师模型,得到教师模型的输出结果,学生模型根据输出结果进行学习。教师模型输出为软标签(soft-target),其中包含了教师模型本身的信息,相比于训练集原有的硬标签(hard-target)信息量更大,因此训练时效率更高。

表1 硬标签和软标签
1.2 网络剪枝与优化
网络剪枝(Network Pruning)通过去除重要性较低的连接,降低神经网络模型的运算量。网络剪枝对于一个连接的重要程度的评价,一般是通过这个连接的参数绝对值的大小[12]、滤波器中位数[13]等信息来判断。现有网络剪枝方法多是依据参数自身信息进行判别[14],而忽略了其他信息。因此在裁剪较大的时候,准确率下降严重。如图1 所示。

图1 删除不同比例的连接后的准确率
一个连接的参数绝对值越大,一般来说对准确率的影响就越大。若一个模型中参数值的分布较为均匀,每个连接都对准确率的影响差距不大,删除小部分连接会导致准确率大幅下降。对于这个问题,本文提出一种促进参数中较大值的训练算法(Promote Maxi⁃mum Weight SGD,PMW-SGD),通过在反向传播时,根据参数的绝对值进行排序,根据相对大小来对应不同的学习率。公式如下:
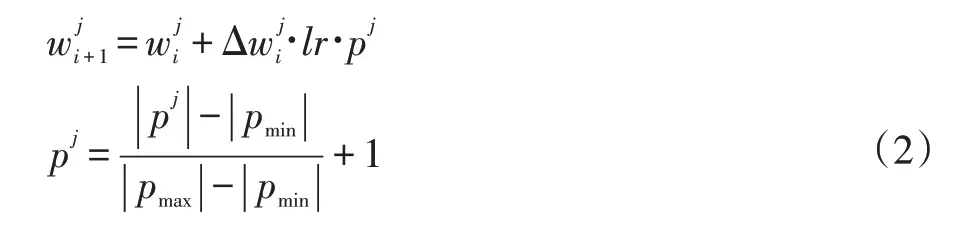
其中w为模型参数,Δw为更新的梯度,p为与参数绝对值大小相关的量。
通过将模型中参数值较大的一部分变得更大,使得这小部分连接对准确率的贡献较大,在删除大部分连接后模型仍然有较高的准确率。
1.3 模型分解
使用网络剪枝删除部分全连接层参数,通过删除不同比例的参数从而得到不同的子模型;不同子模型参数数量不相同,一般参数越多的子模型准确率越高,如图2 所示。在本文中,使用上一小节中经过PMWSGD 训练后的模型,按照参数的权重绝对值进行排序,剪枝掉大部分权重绝对值较小的连接,根据剪枝的比例不同,得到不同准确率的子模型。

图2 完整模型分解为三个子模型
2 实验结果与分析
本文通过PyTorch 框架,在ResNet18 和LeNet 模型及CIFAR10 数据集上进行算法有效性验证。
2.1 PMW-SDG算法
首先将训练好的ResNet18 模型作为教师模型,LeNet 作为学生模型,进行知识蒸馏,先采用minibatch SGD 梯度下降算法训练。在初步经过50 次迭代训练后采用PMW-SGD 梯度下降算法对全连接层的参数进行知识蒸馏的训练,参数分布如图3 所示。
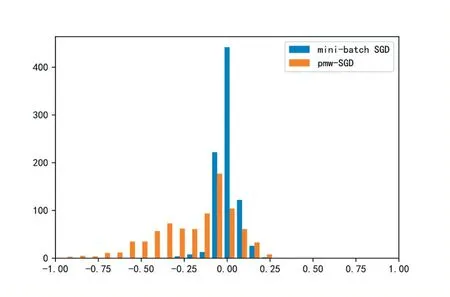
图3 mini-batch SGD和PMW-SGD训练算法训练后的参数分布
在使用PMW-SGD 算法后全连接层中的参数绝对值较大的一部分变得更加大,对应节点的重要性变高,对于准确率的贡献因此变大。在删除部分全连接层的参数时,保留的节点主要为权重绝对值较大的,因此准确率较mini-batch SGD 算法高。如图4 所示。

图4 mini-batch SGD与PMW-SGD训练后的模型删除不同比例参数后的准确率
2.2 知识蒸馏
首先通过网络剪枝将上小节中训练好的ResNet18模型全连接层参数进行剪枝,按照参数权重的绝对值进行排序,从小到大将全连接层剪枝95%得到子模型A;剪枝85%得到子模型B。从而将ResNet18 分解为两个子模型A 和B;其中A 模型中节点较少,因此准确率相对较低;B 模型节点较多,准确率较高。详细信息如表2 所示。
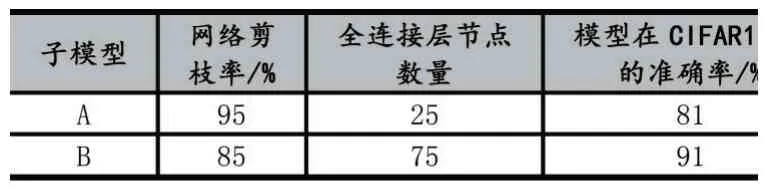
表2 两个子模型的信息
基于LeNet 构造两个模型,分别为LeNetA 和LeNetB;其全连接层节点数分别25 和50 个。使用知识蒸馏让LeNetA 模型全连接层节点学习子模型A 中全连接层节点的输出;LeNetB 模型全连接层节点学习子模型B 中去掉子模型A 中的25 个节点后的全连接层节点的输出;最后将两个模型作为一个整体进行微调训练。
然后将上述方法中的LeNetB 模型换成更加复杂的EfficientNet 模型,在模型中添加节点总数为50 的全连接层。进行与上述相同的训练过程。
普通数据集训练LeNetA 模型、知识蒸馏训练LeNetA 模型和本文方法训练后结果如图5。

图5 不同训练方法下的准确率变化
其中普通训练和知识蒸馏训练LeNetA 模型的准确率分别为:74.4%和74.3%。在本文训练方法中第一阶段训练LeNetA 模型的准确率为69.3%,在第二阶段LeNetB 模型加入训练后准确率为77.8%;在最后一阶段整体微调后,准确率达到78.1%。用EfficientNet 模型替换LeNetB 模型后准确率为83.4%,微调后准确率的84.9%。结果如表3 所示。
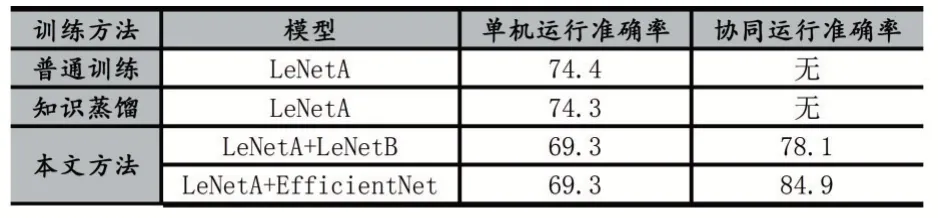
表3 不同训练方法下的准确率
3 结语
可以看出,通过本文方法设计的分布式神经网络与多个设备协同计算时,使用更加复杂的神经网络模型进行协同运算时可达到的准确率较高,对此适用于通信条件良好时通过与云服务器协同运算达到较高的准确率;通信情况一般时通过与附近的边缘设备协同运算,有良好的准确率。协同运算的准确率都比原始模型较高;在出现干扰等情况无法与其他设备协同计算时,单机运算的准确率较原始模型稍低,仍在可接受范围内。
