一种有效的困难样本学习策略
2021-07-01蔡晓东
曹 艺,蔡晓东
(桂林电子科技大学 信息与通信学院,广西壮族自治区 桂林 541004)
哈希学习[1]大致分为非监督哈希和监督哈希。在监督哈希学习中,使用深度神经网络相对于一些手工设计的哈希算法能获得更好的效果。大部分深度哈希算法都采用相似性保留算法,该方法包括单对相似性保留、多对相似性保留、隐式相似性保留。基于单对相似性保留的方法[2-6]通过计算两个样本的距离来学习样本的相似性信息。也有一些通过其他方法[7-10]进行哈希特征学习和量化的工作。基于深度神经网络的单对相似性保留方法在学习过程会产生两个方面的问题。
一方面,存在一些很难被正确学习的困难样本导致模型准确性下降,如何有效地学习到困难样本的特征信息成为一个棘手的问题,在线困难样本挖掘算法[11]是其中一种简单有效的方法。它通过找到困难样本,组成新的训练批次进行训练,但延长了训练时间。相对于文献[11],文献[12]提出了Focal Loss损失函数设计机制,通过给困难样本大权重来控制损失,该机制使用了更少的前向传播次数并进一步提升了训练效率。此机制被用到了深度哈希领域[2],但是该机制在处理不同的问题上缺乏泛化能力[13-14]。
另一方面,在训练样本数量不平衡的情况下,过量的困难样本会造成模型收敛偏移,从而降低模型的准确性[15]。在处理训练样本不平衡的问题时主要有两种方法:一种是改变样本的分布,通过采样(重采样或欠采样)改变训练样本数量或通过数据增强如旋转、镜像、混合训练,或者生成对抗网络等生成伪样本来提高稀少样本的多样性。另一种是修改训练方法,文献[4]分别给正负样本损失函数加权,提高正样本的收敛速度,降低负样本对模型的影响,从而达到学习平衡。但是,这些方法都没有考虑到困难样本对不平衡训练造成的影响。进一步地,文献[16]提出的三元损失函数,每次只选择一组同类样本和一组不同类样本进行训练,真正达到了严格的平衡,算法通过阈值区分困难样本、半困难样本和简单样本。但是,该方法只选择困难样本进行训练,忽略了不平衡分类中困难样本过量带来的噪声问题。
样本的损失表示该样本被网络模型正确识别的程度,可以很好地区分出困难样本,从而调整网络模型的反馈梯度,对困难样本进行深度学习。根据这种思路,笔者提出一种通用的困难样本特征学习策略——损失到梯度,包括两种具体方法:① 一般情况下,提出一种非均匀梯度归一化方法,依据困难与整体样本损失的比例,对整体样本反向传播梯度进行加权计算,提高模型对困难样本的深度学习能力;② 对存在过量困难样本的情况,设计了一种加权随机采样方法,根据损失值对样本排序后进行加权欠采样,对被采样的样本保持原有的梯度,其余样本的梯度置零,从而既可以降低噪声干扰,又可以保留少量的困难样本,提高了模型的准确性。
1 损失决定梯度策略
在处理哈希特征学习问题时,文中采用与文献[6]方法相同的网络框架,包括5个卷积层和3个全链接层,全链接层输出后连接tanh激活函数,将神经元的值域映射到(-1,1),经过激活的特征称为哈希特征,公式表达为U={u1,u2,…,uk},k表示特征序列的维数。通过成对损失函数和量化损失函数进行特征学习。然而,在原框架中这两个损失函数导致模型对困难样本的学习能力不足,其中成对损失函数还存在训练样本数量不平衡的问题。
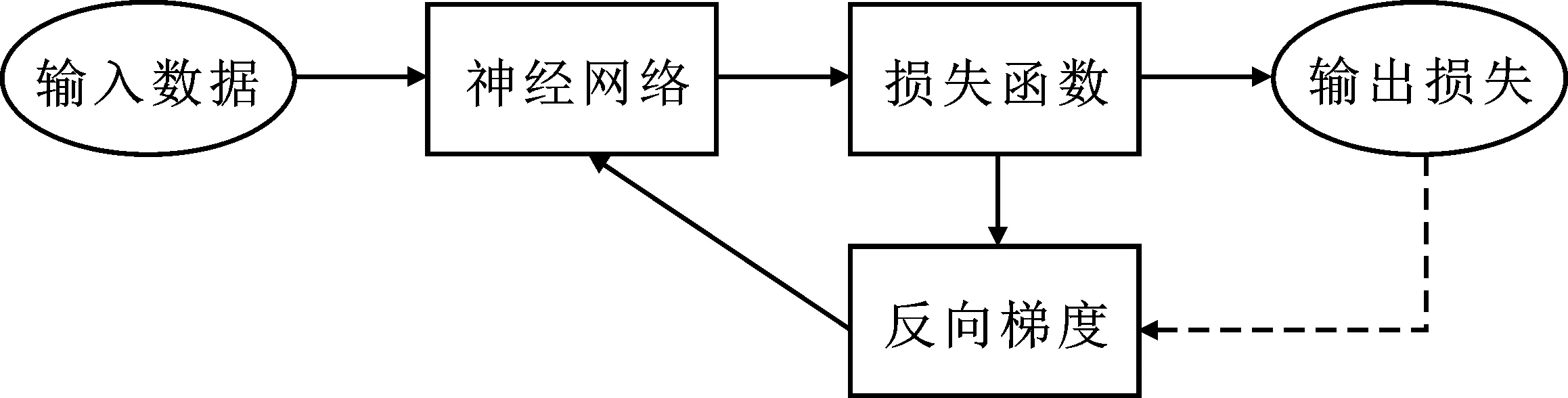
图1 损失决定梯度策略示意图:由虚线表示
传统神经网络使用梯度下降法将训练样本的损失最小化,这是一种梯度到损失的过程;然而这个过程只对整个网络进行优化,无法对个别困难样本进行优化。为了通过对困难样本特征的学习提升网络的性能,基于困难样本的损失值较大的特点,笔者提出一种通用的特征学习策略,称为损失决定梯度策略,如图1所示。它与传统的梯度到损失的策略相反,通过损失进行动态的梯度调整,实现对困难样本的学习。将该思想应用于文献[6]方法中的这两个损失函数的优化。
1.1 非均匀梯度归一化
为了让网络更加容易收敛,损失函数在计算每个样本反向梯度时,通常会对梯度进行归一化处理。定义损失函数为
Li=L(Xi),
(1)
(2)
其中,Xi表示输入神经元的值,Yi表示神经元Xi的反馈梯度值,Li表示神经元Xi损失值,ω表示该损失函数在网络该损失函数训练时的权重,1/B表示归一化项,B表示当前批次的大小。
由于归一化项的存在,在网络收敛之后,简单样本虽然可以被很好地量化,损失值接近于0。但是每个批次都会或多或少地存在一些没有被很好量化的困难样本,它们的损失值依旧很大,梯度也被当前批次里面的大多数简单样本稀释,导致模型错误地认为当前批次的所有样本都得到了良好的处理。文中提出一种改进的非均匀化梯度归一化方法,具体方法如下:
(1) 计算每个样本损失值在整体损失中的占比,得到样本m的损失率
(3)
其中,Xim表示第m个样本的第i个神经元的值,m∈[1,B],i∈[1,K],K表示哈希特征的位数。
(2) 定义样本的权重项公式为
(4)
其中,γ>1,表示网络对样本m的关注程度,γ越大,该样本被反馈的梯度越多。困难样本在训练过程中有较大的Lim,对应的W(Xm)也较大。
(3) 使用权重项W(Xm)替换梯度归一化项1/B,得到新的梯度计算公式为
(5)
根据上述方法,对简单样本和困难样本的权重W(Xm)进行非均衡增加处理,这使得网络模型减弱了对简单样本的学习,增强了对困难样本的学习能力。
1.2 加权随机采样
在训练样本数量不平衡的情况下,负样本中大量的困难样本给训练带来了噪声,影响分类效果;如图2所示,三角形和圆形代表两类样本。决策线随着噪声样本的增加产生偏移,最终产生了与平衡分类情况下不一样的决策结果。
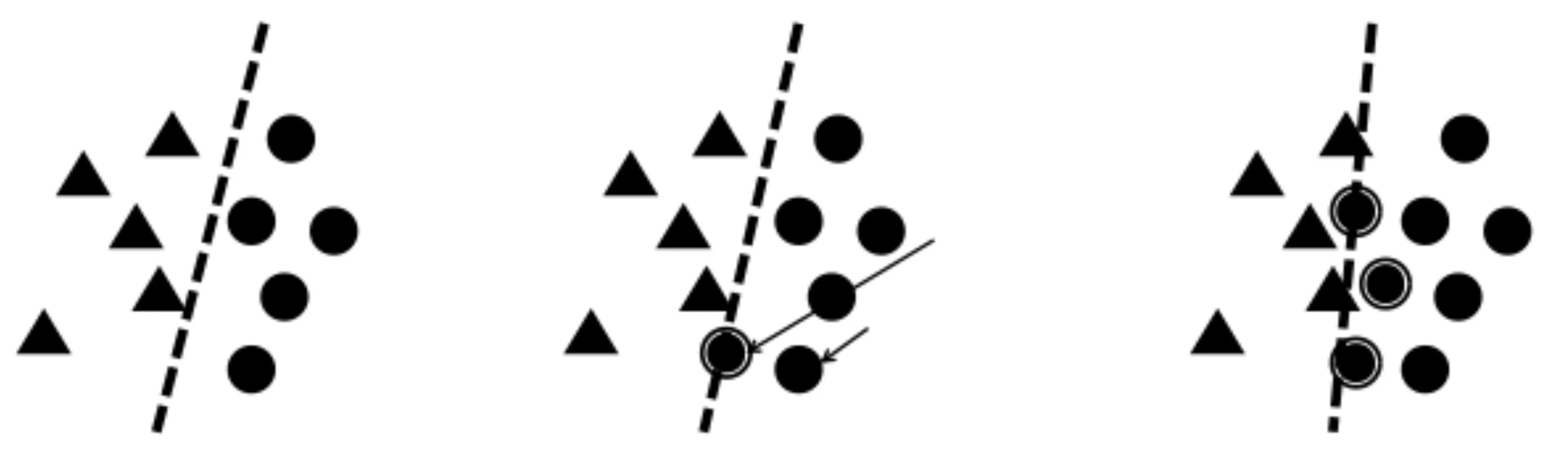
(a) 平衡分类情况 (b) 困难样本增加 (c) 过量的困难样本
为了排除不平衡分类中噪声样本对模型的干扰,笔者提出一种加权随机采样的方法,分别降低和提高负样本中噪声样本和正常样本的采样比例,同时保留少许困难样本,避免简单样本过拟合,提高模型的准确性。具体方法如下。
(1) 假设存在样本集合Ω,可表示为
(6)
Ω表示成对损失函数中产生的异类样本集。式中,nb表示样本集数量,nb=(B2-na),B表示一次迭代的训练样本数量,na表示同类样本数量,na远远小于nb。
(2) 通过成对损失函数计算Ω中所有样本的损失值,并对计算结果进行从小到大排序。在这里,一个样本表示两张图片p与图片q的哈希特征Up与Uq的点积。
(3) 定义采样函数为
(7)
其中,δ为狄拉克函数。在文中,定义采样函数的目的是从nb个负样本中挑选na个样本作为正常的训练负样本,将其余负样本的损失与反向梯度置零。
(4) 定义随机采样函数为
(8)
其中,rand(0,1)表示随机生成一个0到1的浮点型小数,int表示向上取整操作。随机采样函数能等比例地在Ω内进行均匀采样,但这会带来噪声样本的干扰。
(5) 定义加权随机采样函数为
(9)

图3 权重函数中参数a的图示
其中,w(x)称为权重函数,w(x)=xa,a称为稀疏度。通过调整a的大小,可以控制算法对Ω特定区域的采样比例。如图3所示是a=2时的情况。以x∈(0,0.5)为例,函数y=x对应的值域为(0,0.5),而函数y=x2对应的值域为(0,0.25),这意味着对(0,1)的范围进行随机采样时,函数y=x有50%的概率采样到前50%的样本,而函数y=x2有50%的概率采样到前25%的样本,y=x2相比于函数y=x采样比例更向前集中。通过这个特性,算法可以减少对噪声样本的采样比例。噪声样本通常具有较大的损失值,所以噪声样本排在样本序列的尾端,当a∈(1,+∞)时,算法有大概率采样到样本序列的前面部分,减少对末端的采样,从而达到减少噪声样本干扰的目的。
2 实验结果与分析
实验使用的深度学习框架为Caffe,操作系统是Ubuntu16.04 LTS,硬件配置为Intel®CoreTMi5-6400 CPU @ 2.70GHz×4,GeForce GTX 1070/PCIe/SSE2,测试代码编译环境为Qt creator。
2.1 数据库
文中使用CIFAR10和SVHN图像数据库进行实验,并使用ImageNet数据库进行预训练。样本图像训练时被缩放到256×256像素,并随机裁取227×227像素大小的图像进行训练,每个训练周期需要对训练样本进行乱序。
CIFAR10数据库共60 000张图片,图片大小为32×32像素,共10个属性。笔者在每类属性中随机选取100张图片作为检索图片,共1 000张,再选取500张图片作为训练样本,共5 000张,剩下的54 000张图片作为被检索的数据库。
SVHN数据库共分成3个部分:训练库、测试库、额外库,共640 440张图片,图片大小为32×32像素,共10个属性。文中只使用训练库和测试库,共105 289张图片;每类属性随机选取100张图片作为检索图片,共1 000张;角类属性再选取500张图片作为训练样本,共5 000张;剩下的99 289张图片作为被检索的数据库。
2.2 测试结果与分析
笔者通过计算哈希特征值的汉明距离来评价图片之间的相似度。为了保证算法评价的客观性,实验采用与文献[6]相同的评价标准,包括平均精度均值(Mean Average Precision,MAP),精度召回曲线(Precision-Recall curves,PR),汉明距离为2的精度曲线(Precision curves within Hamming distance 2,P@H<=2),以及不同顶部召回样本数的精度曲线(Precision curves with respect to different Number of top returned samples,P@N)。笔者将提出的新策略应用在文献[6]框架上,并将最终结果与文献[2]、文献[4]、文献[5]、文献[6]等目前流行的深度哈希方法进行比较。
如表1所示的是不同哈希特征长度在CIFAR10与SVHN数据库上的平均精度值对比。可以看到,在CIFAR10上,笔者提出的方法在文献[6]框架的基础上,分别约提高了2.2%、4.7%、4.6%、4.8%,在SVHN上,笔者提出的方法在文献[6]框架的基础上,分别约提高0.1%、0.3%、1.8%、3.4%。
如图4、5所示是另外3种评价标准在3个数据库上的测试结果。可以看到,在P@H<=2的评价标准中,笔者提出的方法都处于较高水平。在PR标准中,各种方法的差距不是太大,但不同数据库下不同方法的效果也不同,笔者提出的方法处于中间水平。在P@N标准中,笔者提出的方法在CIFAR10上与文献[2]方法相似,在SVHN上处于较高水平。
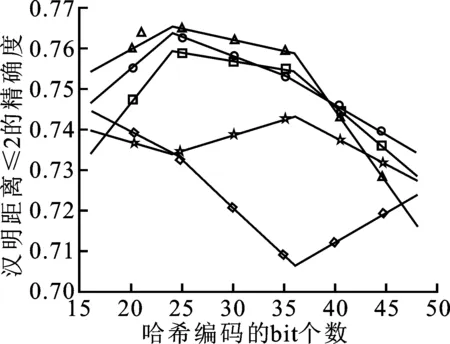
(a) P@H≤2

(b) PR

(c) P@N

(a) P@H≤2

(b) PR

(c) P@N
2.2.1 非均匀梯度归一化方法扩展实验
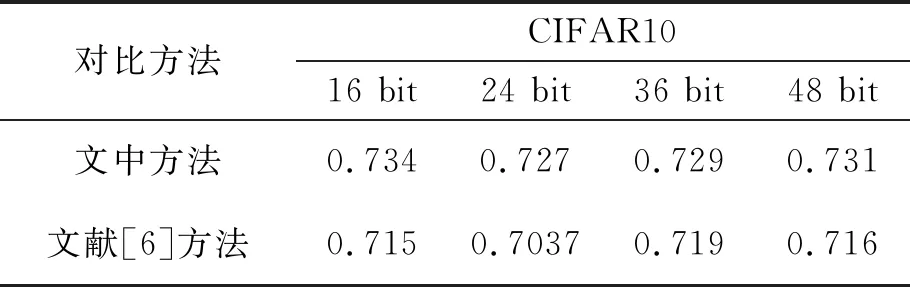
表2 非均匀梯度归一化对哈希特征学习的影响
为了证明非均匀梯度归一化方法的有效性,单独测试了该方法对实验结果的影响,如表2所示是在文献[6]框架的基础上只增加该方法,对应不同哈希特征长度在CIFAR10数据库的平均精度值。实验表明,该方法能给文献[6]框架带来约1.9%,2.3%,1.0%,1.5%的平均精度值提高,说明该方法在处理困难数据学习问题是有效的。

表3 非均匀梯度归一化对分类学习的影响
同时,为了证明非均匀梯度归一化的通用性,文中将该方法应用在图像分类问题上。使用文献[6]的网络模型,使用Softmax损失函数学习图像特征。在CIFAR10和MNIST数据库中随机选取5 000张训练集样本和1 000张验证集样本。如表3所示,可以看到,增加该方法后,网络的验证平均精度在CIFAR10和MNIST上分别约提高了1.9%和0.6%。将MNIST特征数据映射到二维平面,10个数字的分布如图6所示。可以看到,普通的Softmax损失函数,类内距离比较大。在Softmax损失函数中应用该方法后,类内特征分布更加密集,说明该方法在常用损失函数中也能起到提升作用。

(a) 基于传统Softmax的手写字体分类

(b) 文中改进后的手写字体分类
2.2.2 加权随机采样方法扩展实验

表4 加权随机采样对哈希特征学习的影响 (平均精度)
为了证明加权随机采样方法的有效性,文中单独测试了该方法的效果,并对比该方法与其他几种采样方法在处理不平衡数据采样时的效果。如表4所示,在文献[6]框架的基础上增加了该方法后,不同哈希特征长度在CIFAR10数据库的平均精度。结果显示,该方法在文献[6]效果的基础上,分别提高了1.9%,4.8%,2.9%,3.6%,说明它在处理不平衡数据问题上的有效性。文献[4]方法是仅保留不平衡数据处理机制的方法。文中方法比文献[4]方法的AP分别高出0.6%,2.0%,1.2%,0.6%,说明有针对性地减少丰富类困难样本数量,比降低整体丰富类样本权重更有效。

表5 不同采样方法对检索效果的影响
为了证明加权随机采样中“加权”的必要性,文中对几种不同采样方法进行测试。这些方法分别是:在不平衡训练样本集中,对丰富类样本进行全为简单样本采样、全为困难样本采样、随机采样、加权随机采样。表5所示是CIFAR10数据库上特征长度为48 bit的哈希特征检索平均精确度。实验表明,仅使用困难样本训练,模型平均精度会维持原来的。相反,仅使用简单样本训练,模型不会收敛,平均精度很低。使用随机采样样本训练,正负样本数据平衡,能得到比原始模型更好的效果;在此之上,使用加权随机采样,减少对困难样本的采样,能进一步提升模型准确率。
3 结束语
针对深度哈希算法中困难样本不收敛、产生噪声干扰等问题,笔者提出了基于损失决定梯度的困难样本学习策略。通过计算样本的损失值控制困难样本的反馈梯度,提高模型对困难样本的学习能力。同时,通过损失值排序对不平衡数据中的样本进行加权采样,构造均衡的训练数据集。实验表明,相比于目前流行的深度哈希算法,笔者提出的改进算法在图像检索效果上有明显的提高,为困难样本学习问题提供了新的思路。如何自适应地选取困难样本与简单样本的训练比例,达到最佳的模型效果,将成为下一步的研究目标。
