复杂背景下无锚框手势检测网络的构建
2021-06-28程志宇徐国庆
程志宇,徐国庆+,许 犇,罗 京
(1.武汉工程大学 计算机科学与工程学院,湖北 武汉 430205;2.武汉工程大学 智能机器人湖北省重点实验室,湖北 武汉 430205)
0 引 言
传统的基于人工提取特征加分类的手势检测方法[1-4]在复杂环境背景干扰情况下对精度影响较大,而基于外部穿戴硬件设备的检测方法[5,6]在手部细节提取上复杂繁琐,存在抖动和不稳定的现象,因此,如何提升手势检测的效果对计算机视觉交互技术研究具有重要的意义。现阶段,基于深度学习方法在手势检测中应用广泛,将深层卷积神经网络用于手势目标的检测和识别,如利用基于DSSD的静态手势识别方法[7],以及将Faster R-CNN算法应用于手势识别[8]实验等。但该类基于锚框算法的模型对手势目标检测受限于人工预先设定的不同候选框的数量和尺度范围。近年来,基于无锚框的手势检测方法正逐渐成为检测领域的研究热点,有Extremenet[9]、FCOS[10]、Cornernet[11]等。其中基于关键角点检测的算法取得出色的检测效果,适用于形状复杂多变的手势目标,通过优化训练的损失函数和网络模型结构来增强模型的表达能力,使得模型能够达到优异的检测性能。
本文针对手势检测识别应该具有的速度快和精度高特性,采用centernet网络[12]搭建手势检测的模型,算法框架用改进的shufflenetv2网络作为特征提取模块搭建而成。手势检测的实现是通过对原始输入图像进行目标中心点预测,检测识别手部区域。综合不同网络模型比较检测性能。
1 手势特征提取网络的构建
1.1 shufflenetv2网络模型
shufflenetv2网络[13]是目前简洁高效的网络结构中具有创新性和高性能的卷积神经网络之一,其网络架构是在Xiangyu Zhang等[14]提出shufflenet网络结构的基础上进行改进,由基本混洗模块和下采样模块堆叠而成,最后接一层卷积层和平均池化层。基本模块的设计考虑到网络的性能,能够达到明显提升模型精度,大幅减少网络计算量的效果。
基本混洗模块的结构特点是引入通道分割和连接操作,将输入的通道分成两个分支,一个分支上有两个卷积和一个深度卷积,后接批归一化层,激活函数为ReLU。此操作中将原先使用是1×1的分组卷积替换成了普通的1×1卷积,另一个分支保持不变。之后把两个分支得到的特征合并,使用连接操作替换加法操作,实现特征重用,同时保持输入通道和输出通道数目相同,最后使用通道混洗操作融合不同通道的特征。通道混洗操作的主要作用是让不同通道间进行信息交换,融合不同通道的特征,通过对不同通道输入的信息流进行维度改变,转置后恢复原维度输出,能够大幅提高模型的表示能力和精度。下采样模块有两个分支,一个分支使用深度卷积和点卷积替换原来的平均池化层,另一条分支使用普通卷积替换原分组卷积,两个分支连接后进行通道混洗操作。每个分支都有步长为2的下采样,特征图宽高减半,通道数翻倍。
1.2 shufflenetv2-se手势特征提取网络模型
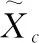
(1)
在通道级上引入注意力思想,加入权重系数,能够让模型分辨不同通道的特征重要性,更加关注重要通道特征信息,弱化非重要通道特征信息,有效减少无关信息的影响。层中将输出通道数缩减为原始输入的四分之一,整体上网络增加的复杂度不算高。SELayer采用H-Sigmoid激活函数,它是激活函数Sigmoid的简化变体,能够减少Sigmoid使用时的计算消耗。该函数的数学表达式如下
(2)
然后在shufflenetv2网络的后端引入三层上采样的转置卷积[17,18]结构来替代原网络结构最后的常规1×1的卷积层和全局平均池化层,其中转置卷积核大小为4×4。检测模型使用三层上采样的转置卷积的主要目的是为了聚合网络的深层特征,得到较高质量的特征图,网络整体上实现下4倍采样。特征提取网络在经过Stage4层模块后生成的特征图大小为16×16,再逐一进行转置卷积操作,批归一化和ReLU运算得到的特征图大小依次为32×32、64×64、128×128,特征图像分辨率依次扩张,通道数量相比下采样阶段减少,能够更好地保留原图像的特征信息。同时在训练过程中转置卷积的参数能够经过训练学习得到,在上采样阶段达到高效实现算法效果。非线性激活函数ReLU的使用有效减少噪声的影响,激活重要特征信息。网络结构参数设计见表1。

表1 网络结构参数设置
2 基于centernet的手势检测模型
2.1 手势检测网络的构建
本文提出的手势检测网络模型结构主要由两部分构成,前端部分是加入SELayer的shufflenetv2基础网络和上采样卷积结构,用于对输入的图像进行特征提取,同时能够有效融合不同通道和低层细节的特征信息,高效获取复杂手势特征;后端部分是检测网络,进行关键点热图、目标大小以及中心点偏移的预测。SCNet整体的网络模型结构如图1所示。对整体网络结构进行了改进,从后期实验结果验证了改进后的网络结构拥有更高的准确率。
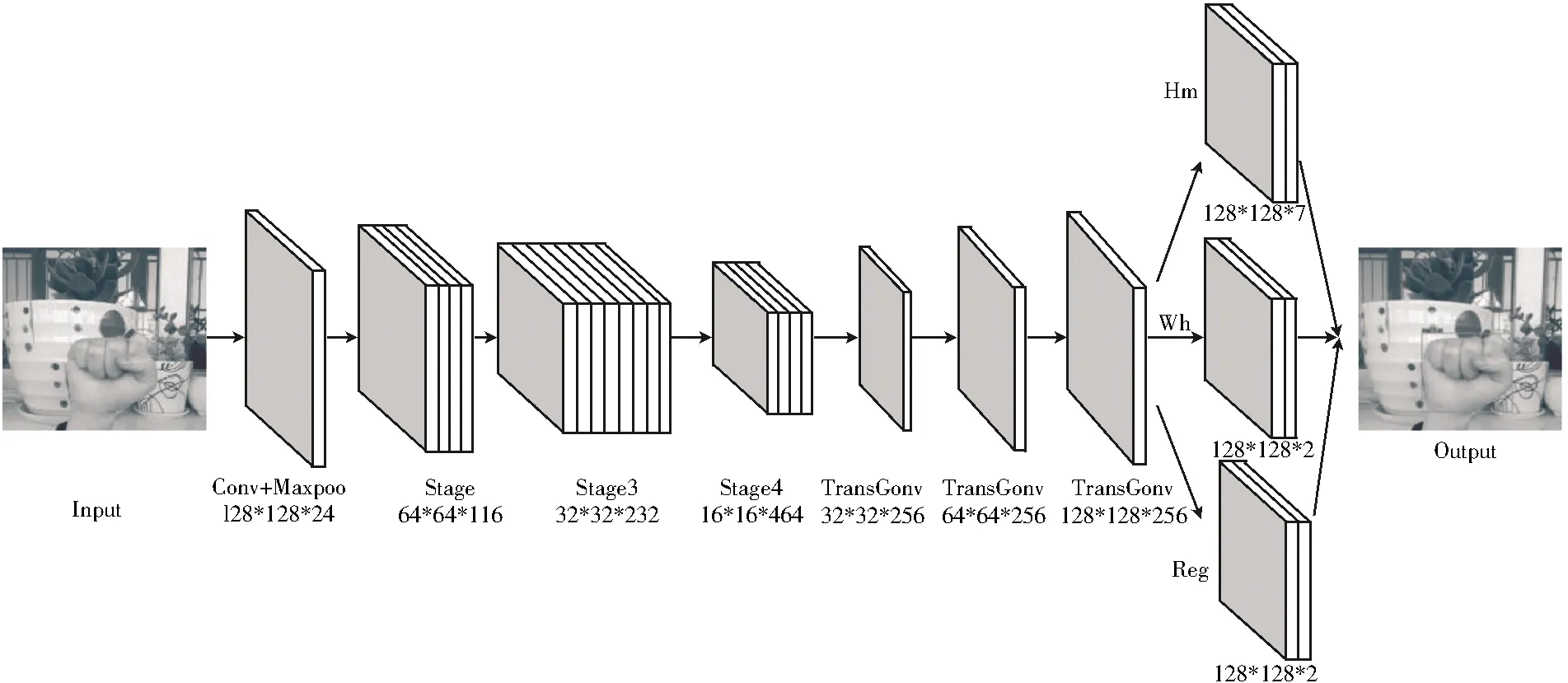
图1 SCNet网络模型结构
与其它检测算法相比,基于centernet的目标检测网络的创新是提出中心点热图检测思想,网络只提取每个目标的中心点作为关键点来预测目标大小信息,得到更简单高效的检测模型。由SCNet模型检测手势的具体过程分为3个阶段:首先传入手势图像,经过前端检测网络模型预测生成手势关键点热图,然后对热图上样本特征进行三分支的卷积操作直接预测出关键点、偏移量和目标尺寸值,最后解码得出手势目标位置边框。整体网络实现端到端检测,省去了基于锚框检测算法在后处理阶段的额外计算和训练开销,同时引入中心点来检测目标相对cornernet算法,不需要对关键点进行分组,能够更好去除小目标的误检框,在检测速度和识别精准性上有明显优势。
2.2 网络损失函数和属性值
SCNet网络的目标损失函数由关键点热图损失Lk、目标尺度大小损失Lsize、中心点偏移量损失Loff这3部分组成,如式(3)所示
Ldet=Lk+λsizeLsize+λoffLoff
(3)
式中:λsize的值为0.1,λoff的值为1。
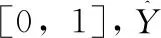
(4)
(5)
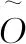
(6)
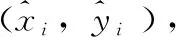

(7)
3 实验的结果和分析
3.1 实验数据集的处理
本文的检测对象是在复杂背景下的手势,设计的实验分别是在公开数据集Egohands[19]以及在自建RGB数据集上进行单类别和多类别的训练和评估,验证算法的性能。
公开Egohands数据集包括两人互动的4800张图片,使用Google glass拍摄,拍摄的活动场景复杂多样互动形式丰富,包括室内和室外等场景。其中每张图片大小为1280×720 px,且图片上的手势区域都带有位置标签。数据集中图片只包含一种类别,标签为hand,训练集、验证集和测试集的图片的划分比例为8∶1∶1,训练集图片共计3840张,验证集480张,剩余480张图片为测试集。部分手势如图2(a)所示。

图2 部分手势数据样本图像
多类别实验采用增强的手势数据集进行训练,通过RGB摄像头采集手势数据集包含7个类别,3850张图片,每张图片采用LabelImg进行标注。数据增强分为离线数据集增强和在线训练数据增强两种方式,考虑到数据量较少,以及对小目标检测的准确度,采用离线数据增强策略对数据集进行两倍扩充,共计11 550张图片,按照8∶1∶1的比例划分训练集、验证集和测试集,其中测试图片数为1155张,验证图片数为1155张,剩余9240张作为训练数据。数据增强策略是将原始手势数据集进行随机平移,平移范围是原图像宽高的5%,为了更好检测小目标,随机进行缩放调整,缩放比例为原始图像大小的0.8倍或0.5倍,部分手势图像如图2(b)所示。
3.2 实验平台和参数设置
本文的实验平台是在图形卡为NVIDIA GeForce GTX 1660s上进行训练,系统环境为windows10,采用Pytorch深度学习框架,cuda10.0和cudnn7.6。实验输入数据集图片的像素大小设为512×512 px,将数据集转成coco数据集标注格式进行训练,训练过程中,初始学习率设置为1.25e-4,batch size设为12。在迭代次数为90时,学习率下降为1.25e-5;迭代次数为120时,学习率再降为1.25e-6。其中单类别训练中的训练迭代次数设为200,多类别训练中的训练迭代次数为140。
3.3 单类别数据集实验结果和对比分析
单类别检测实验主要从网络模型性能、大小和速度上进行对比,选择基于锚框的单阶段代表性算法SSD和传统shufflenetv2网络。一组实验设置的对照组为:①采用mobilenet作基础网络的SSD算法;②采用本文提出的网络模型SCNet。实验分别从mAP,AP(0.5)和AP(0.75)这3个维度进行比较。
从表2的实验可以看出,使用基于centernet的检测网络在Egohands数据集上能够达到很好的准确率,相较于基于mobilenet的SSD算法不管是均值平均精度,AP(0.5),AP(0.75)上都更优,两者在mAP上相差达到4.6%左右。

表2 对比实验结果
为了验证使用SELayer的有效性,在传统特征提取网络shufflenetv2上做对比实验,尺度选择1.0,网络分别是激活函数选择ReLU的shufflenetv2后端加入三层上采样转置卷积模块,以及在stage3和stage4中使用SELayer且后端加入三层上采样卷积模块的SCNet网络这两种模型。分别从平均检测精度、模型大小、参数量以及单帧耗时4个方面来衡量模型的性能,实验结果见表3。
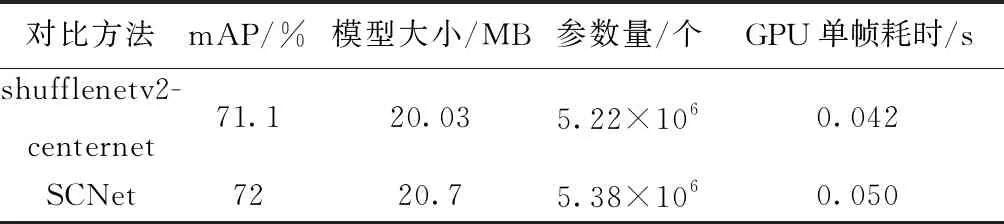
表3 对比实验结果
在同样大小的输入图片上,本文改进后的模型SCNet相较于原始shufflenetv2算法来说,在模型大小和速度上的差距不大,但是SCNet能够达到更高的准确率,其对单目标检测的准确率比shufflenetv2高0.9%。仅仅通过增加少量参数达到更好的性能提升。表中单帧耗时的计算结果为摄像头识别的速度,为总的计算时间(tot),包含每帧图像的预处理时间。实验结果表明在GPU加速上能达到快速识别的效果。用构建网络(net)和解码时间(dec)计算加速后峰值帧率可达到45 frames/s,相较于CPU i5平台有大幅速度提升。
3.4 多类别数据集实验结果和对比分析
多类别检测实验主要以不同类别的网络作为前端手势特征提取的网络结合centernet算法得出的检测网络模型在性能上进行对比,选择squeezenet网络、shufflenet网络以及mobilenetv2网络在自建RGB手势数据集上设计对比实验。实验设置的对照组分为4组:①使用squeezenet作特征提取网络;②使用shufflenet作特征提取网络;③使用mobilenetv2(0.75x)作特征提取网络;④本文提出的网络模型SCNet。其中mobilenetv2后端用三层深度卷积形式的转置卷积替代,训练过程中训练集和验证集的损失值变化如图3所示。实验在迭代90次之后损失值收敛,不管是在训练集还是验证集上没有大幅振荡,从训练效果上看,SCNet的损失值相比于squeezenet网络、shufflenet网络和mobilenetv2网络都处于较低值水平,收敛速度较快。
图3 实验损失值曲线
由表4可知,在同样大小的输入图片下,本文设计的模型SCNet对于不同手势的检测上测试精确率能够达到91%,优于squeezenet网络、shufflenet网络和mobilenetv2网络,相对于squeezenet网络来看,SCNet准确率提升在6.9%左右,漏检率上减少5.6%左右,误检率上减少7%左右;与shufflenet网络对比,准确率提升在2.5%左右,漏检率上减少2.3%左右,误检率上减少2.5%左右;对比mobilenetv2的前端网络,本文采用优化shufflenetv2网络的检测准确率能够提高2.3%左右,在漏检率上减小1.7%左右,在误检率上减小2.4%左右。对比实验结果显示了本文方法模拟的有效性和高效性,为手势检测的研究提供了方法和途径。
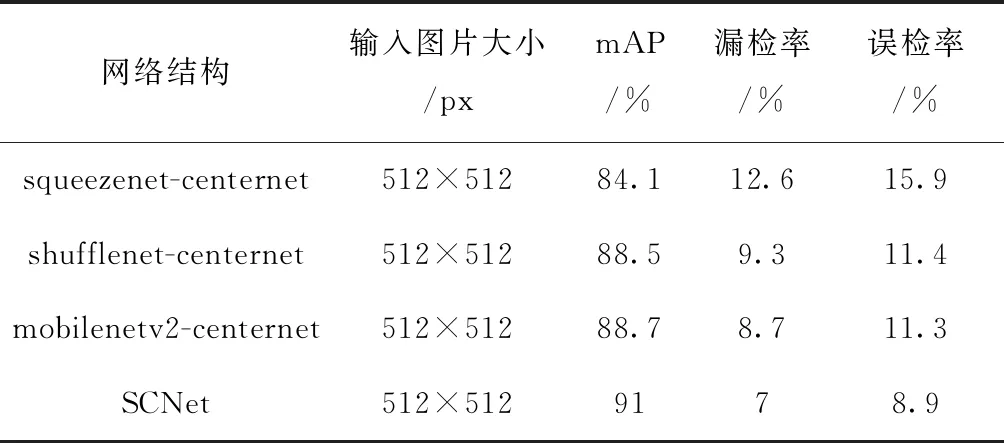
表4 对比实验结果
单类别检测实验中用mobilenet-SSD和SCNet网络模型进行对比,采用mobilenet-SSD网络输入图片后的检测结果如图4(a)所示,使用SCNet检测模型输入图片后的检测结果如图4(b)所示。在复杂背景下,mobilenet-SSD网络针对于小部分遮挡目标没有检测出,有出现漏检情况,SCNet模型对于遮挡和不完整的目标物体检测效果很好,基本手势检测两者差距不大;多类别检测实验图片测试中使用shufflenet-centernet和SCNet模型对比,分别采用图片输入后的检测结果如图4(c)和图4(d)所示。在复杂背景下,shufflenet-centernet模型检测结果会出现漏检误检的情况,识别效果不佳;SCNet模型对于图中目标物体的检测效果很好,类别准确。其中左侧为中心点热图结果,在热图上标示了手势关键点的位置以及检测结果。

图4 复杂背景下手势检测
4 结束语
本文主要讨论针对复杂背景下手势图像目标检测的算法,在手势检测识别网络的结构和准确性两方面分别讨论。本文采用基于centernet算法的手势检测网络结构,采用目标中心点预测物体边界,将使用SELayer优化的shufflenetv2作为特征提取网络,后经上采样的转置卷积恢复原特征图大小,使模型变得更加准确和高效。网络整体使用ReLU激活函数。实验结果表明,本文提出的手势检测模型在速度和精度上有明显优势,能够较好地提升手势图像目标的检测效率和识别精准度,实现了快速准确的手势检测,但对于小目标和重叠目标的检测需要做进一步的改进。后续研究尝试结合其它主干网络进行实验,如mixnet、ghostnet等,提高手势检测的效率和精度。
