基于时域波形映射-频域谐波损失的语音增强
2021-06-28董宏越马建芬张朝霞
董宏越,马建芬+,张朝霞
(1.太原理工大学 信息与计算机学院,山西 晋中 030600; 2.太原理工大学 物理与光电工程学院,山西 晋中 030600)
0 引 言
语音增强是从含噪语音中估计纯净语音,从而得到高质量和可懂度的增强语音[1]。多名研究者提出了基于监督学习的算法[2-7]进行语音增强。其中,基于时域波形映射的深度学习语音增强算法[8],通过全卷积神经网络可以直接将原始含噪语音作为输入,并直接输出时域增强语音,成为了语音增强领域研究的热门。但由于在时域中,背景噪声和语音之间没有明显的可辨别性,如何设计合适的损失函数来提高全卷积神经网络的去噪能力成为其中一个难点。近些年研究发现,许多语音增强算法忽略了语音的谐波结构,无法有效去除谐波之间的噪声,因此具有较差的增强性能[9,10]。而现有改进的基于时域波形映射的语音增强方法[11,12],是通过使用频谱幅度损失函数或直接采用评价指标相关的损失函数,来提高语音增强的性能。这些方法还没有考虑到直接恢复语音的谐波结构,导致这些算法在低信噪比条件下仍然不能获得让人满意的增强效果。
因此,为解决现有基于时域波形映射的语音增强算法没有考虑到语音的谐波结构,导致具有较差语音增强性能的问题。我们提出了一种基于时域波形映射-频域谐波损失的语音增强算法,通过使用本文提出的频域谐波损失函数,将语音谐波结构的恢复纳入神经网络的学习过程之中,来进一步提高语音增强的性能。具体的,将谐波噪声模型(HNM)对纯净语音进行建模得到的频域中的HNM分量作为训练目标,通过最小化频域谐波损失,训练波形映射全卷积神经网络,用训练得到的网络进行语音增强。通过实验对比,进一步探讨本文方法的语音增强性能。
1 传统基于时域波形映射的语音增强算法(FCN-MSE)
假设含噪语音y由纯净语音s和加性噪声d组成,表示为
y=s+d
(1)
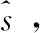
传统的基于时域的语音增强方法,如图1所示,可以描述为:是通过训练全卷神经网络(FCN)的参数集合θ构造一个高度复杂的非线性函数fθ,使得损失函数Er
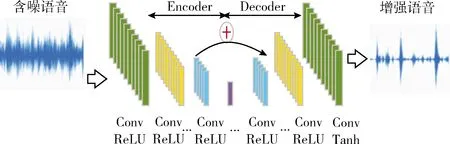
图1 基于时域波形映射的语音增强算法
(2)
(3)
但传统的方法只是通过最小化式(2)所示的时域纯净语音和估计纯净语音信号之间的均方误差(MSE)损失来训练网络。传统FCN-MSE算法语音增强对比语谱图如图2所示,由于在时域中,背景噪声和语音之间没有明显的可辨别性,使用时域损失会存在如图2(c)圆圈部分语音失真的问题。并且由于这种损失函数中训练目标的设置只是简单使用纯净语音的波形,没有考虑到语音的谐波结构(在语谱图上,谐波结构显示为横纹),如图2中方块位置,增强语音相比纯净语音,没有明显的谐波结构,横纹不明显,很难去除谐波之间的噪声,进一步影响了其语音增强的性能。
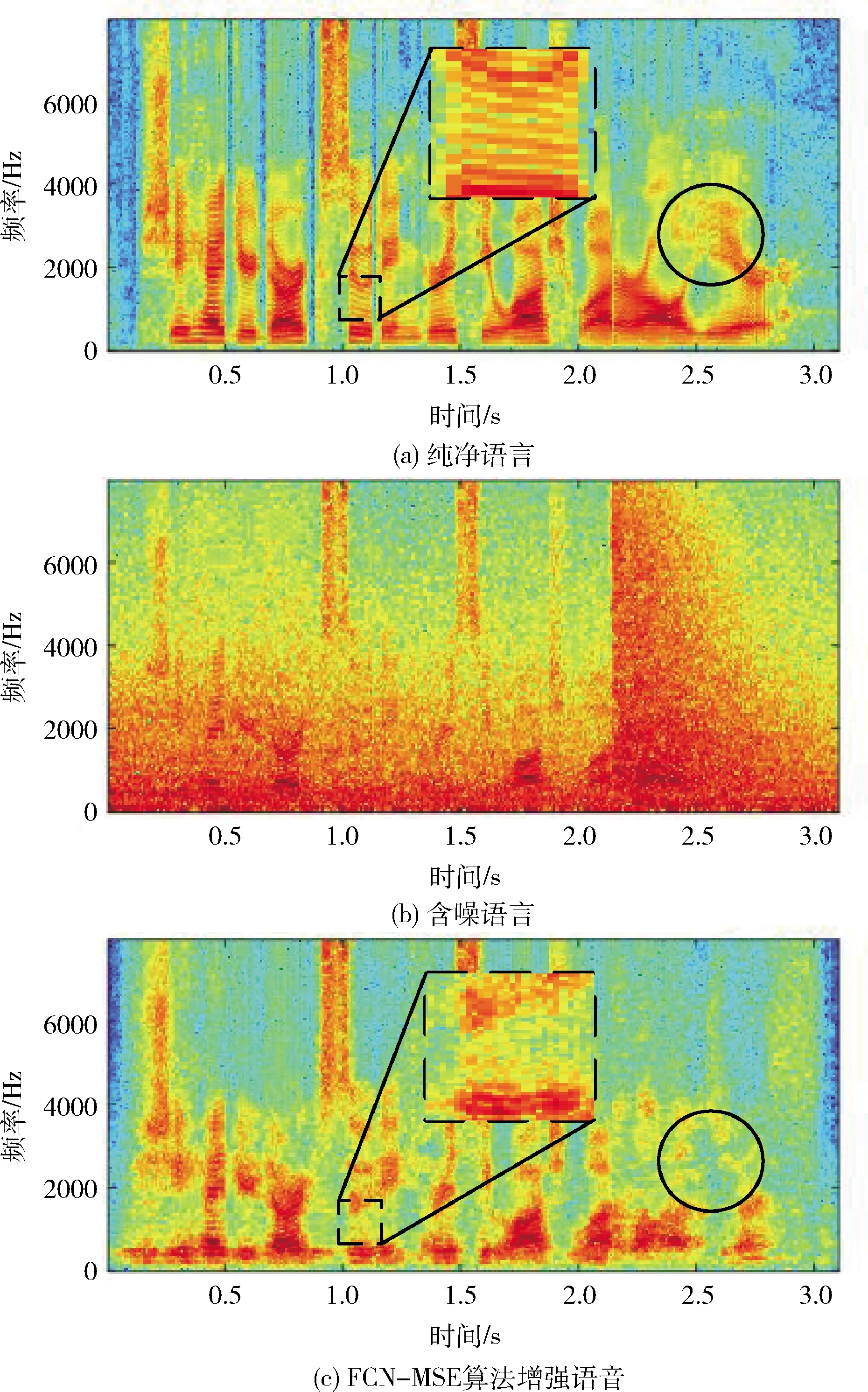
图2 FCN-MSE算法语音增强对比语谱图
2 基于时域波形映射-频域谐波损失的语音增强算法
为解决上述传统方法使用损失函数不能很好地恢复语音的谐波结构,导致具有较差语音增强性能的问题。本文利用谐波噪声模型(HNM)对语音进行建模,提出了频域谐波损失函数,将谐波结构的恢复纳入到训练阶段的网络学习过程中,以提高增强语音的质量和可懂度。
本文提出的基于时域波形映射-频域谐波损失的语音增强算法的实验框架如图3所示,它包括两个阶段:训练阶段和增强阶段。在训练阶段,将含噪语音进行分帧,然后将含噪语音帧作为全卷积神经网络(FCN)的输入,使用HNM对纯净语音建模得到的纯净语音频域谐波分量和语音残余分量作为损失函数中的训练目标来训练FCN。然后通过最小化频域谐波损失来得到训练好的FCN。在增强阶段,通过使用训练好的FCN将输入的时域含噪语音帧映射为时域增强语音帧。最后将所有的增强语音帧拼接合成,得到完整的增强语音语句。
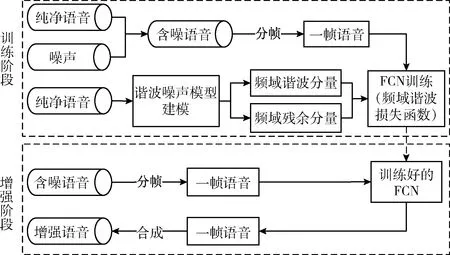
图3 基于时域波形映射-频域谐波损失的语音增强算法
在本章中主要对语音的谐波噪声模型建模、频域谐波损失函数的构建和FCN训练这3个部分进行介绍。
2.1 语音的谐波噪声模型建模
在语音分析和合成领域,谐波噪声模型(HNM)模型[13]是一种常用的语音波形分析和合成模型,使用HNM对谐波结构进行建模可以显著提高合成语音的可懂度和质量。因此在本文中,我们打算使用HNM模型对纯净语音进行建模,将HNM模型建模后得到的频域谐波分量和语音残余分量作为损失函数中的训练目标。
HNM可以将语音建模为谐波部分和噪声部分。为了区分HNM中的噪声部分和传统意义上的噪声,将HNM中的噪声部分称为语音残余。因此,语音信号s(n)可以写成
s(n)=h(n)+r(n)
(4)
式中:h(n)和r(n)分别代表谐波分量和语音残余。
谐波分量代表语音中大部分的浊音语音信息,并且可以建模为基频f0及具有其谐波频率的一系列正弦波的加权叠加,即
(5)
φh,i(n)由下式得到
(6)
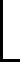
语音残余通过在时域语音中减去谐波分量来获得。对于纯净的语音s(n),语音残余通常为非周期性语音,代表语音中大部分的清音,例如唇齿摩擦声、抽吸噪声和声门湍流,而对于含噪语音y(n),语音残余包含非周期性语音和背景噪声。
但是,因为在时域中语音的谐波分量和语音残分量的波形与背景噪声波形相比,并没有明显的可辨性,直接将时域谐波分量和语音残余分量用作训练目标,很难使网络学习恢复语音的谐波结构。为此,我们需要将谐波噪声模型建模得到的时域HNM分量通过短时傅里叶变换转换到频域。式(4)的相应STFT表示为
S(l,k)=H(l,k)+R(l,k)
(7)
式中:l和k分别为帧索引和频率索引。大写字母S(l,k)、H(l,k)和R(l,k)表示s(n)、h(n)和r(n)对应傅里叶变换后的时频分量,可以由幅度和相位表示成如下具体形式
S(l,k)=As(l,k)ejΦs(l,k)
(8)
H(l,k)=Ah(l,k)ejΦh(l,k)
(9)
R(l,k)=Ar(l,k)ejΦr(l,k)
(10)
其中,Ah(l,k)为谐波幅度,Ar(l,k)为语音残余幅度,Φh(l,k)和Φr(l,k)为对应的相角。
可以看出频域上的谐波分量H(l,k)和语音残余分量R(l,k)具有明显的时频特性,将其作为损失函数的训练目标,训练网络来最小化频域谐波损失,可以使网络更好地学习语音的谐波结构,消除谐波之间的噪声,以提高增强语音的质量和可懂度。
2.2 频域谐波损失函数的构建
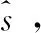
(11)
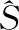
(12)
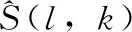
(13)
式中:S(l,k)是纯净语音通过短时傅里叶变换后得到的时频分量。N是离散傅里叶变换(DFT)的长度,i∈{1,2,…,I}是谐波的索引。使用具有幅度压缩的基音估计滤波器(PEFAC)[14]来计算基频f0。然后,通过从S(l,k)中减去H(l,k)来获得频域语音残余分量R(l,k)。
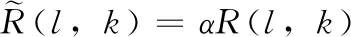
2.3 FCN训练
全卷积神经网络(FCN)的搭建参考了文献[15],其由编码器和解码器组成,结构如图4下部所示。编码器包括9层卷积,其中第一层的步幅为1,而其余8层的步幅为2。解码器由反卷积层组成,由于来自编码器的跳跃连接将每个编码层连接到其同源解码层,因此解码器中通道数等于编码器中相应对称层中的通道的两倍。在网络中除了输出层,每个卷积层之后使用ReLU激活函数,输出层之后使用Tanh激活函数,因此所有的输出波形都被归一化到[-1,1]的范围。训练语音被分帧为帧长2048的语音帧作为网络的输入,帧移为256。网络的输出同样是帧长为2048的语音帧。具体网络的尺寸为:2048×1(输入),2048×64,1024×64,512×64,256×128,128×128,64×128,32×256,16×256,8×256,16×512,32×512,64×256,128×256,256×256,512×128,1024×128,2048×128,2048×1(输出)。使用Adam优化器训练网络,初始学习率设置为0.001,在每个时期之后,学习率将呈指数下降。
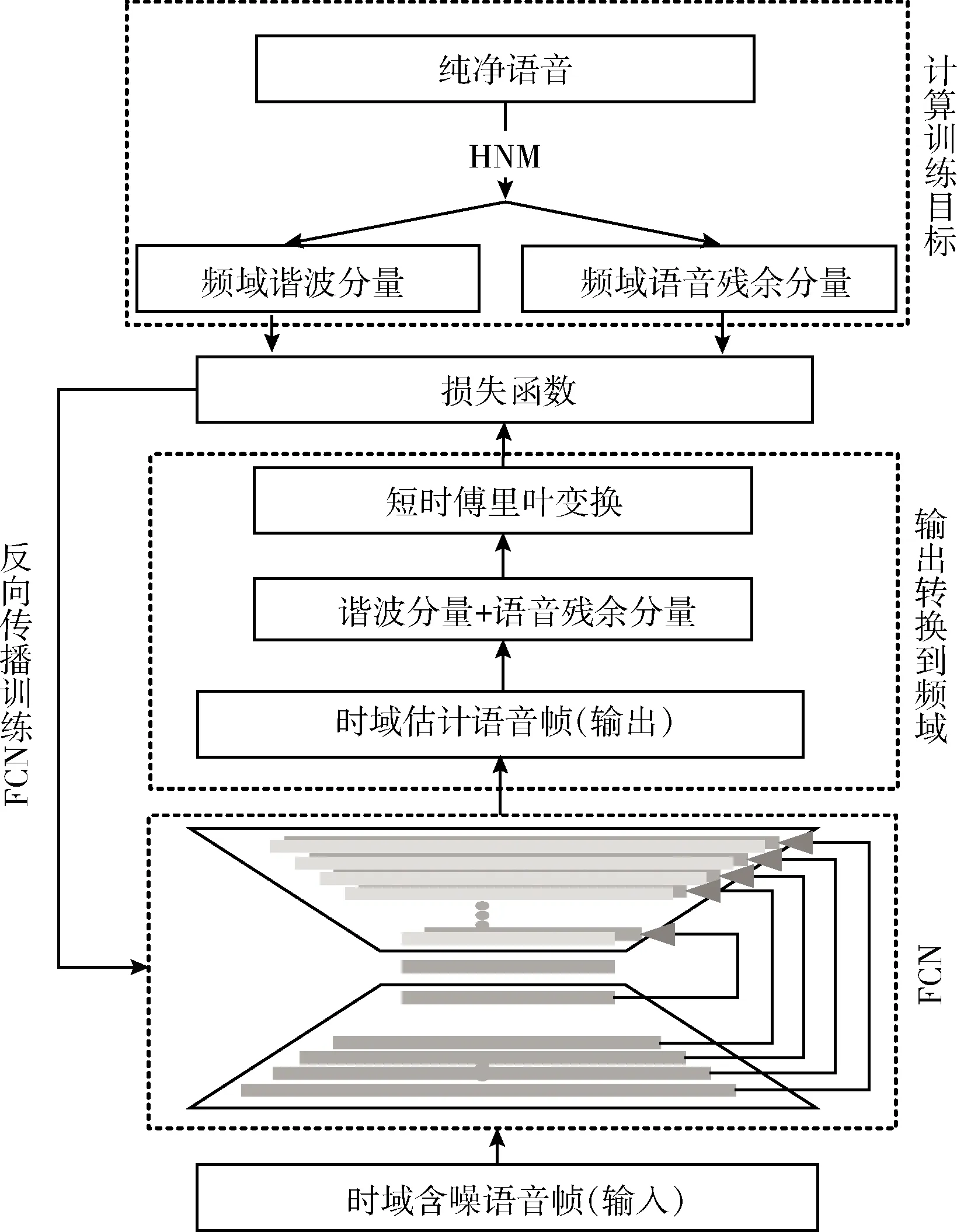
图4 时域波形映射-频域谐波损失的FCN训练流程
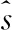
3 实 验
在本章中将会介绍所使用的实验配置以及评价方法。我们会将本文提出的算法和几种当今流行的语音增强算法在同条件下进行比较,通过两种客观评价方法对增强语音进行评价,并对其结果进行分析。
3.1 实验配置
实验使用从TIMIT语料库男性和女性说话者的6300句语音中随机挑选(每位说话人的10句语音中随机挑选一句)的630条语音作为训练集和测试集的纯净语音,其中70%(441条)作为训练集的纯净语音,另外30%(189条)作为测试集的纯净语音。从NOISEX-92数据库中挑选出8种噪声。其中4种类型(white、babble、factory1、f16)为可见噪声,其它(pink、factory2、tank、volvo)为不可见噪声。通过以下方式得到含噪语音:从可见噪声中随机切分出噪声段与训练集中的纯净语音叠加,得到信噪比分别为-10 dB、-5 dB、0 dB、5 dB的含噪语音,最终训练集包含7056(411×4×4)条含噪语音,约6 h。为模拟更真实的情况,测试集中使用一些和训练集不匹配的噪声类型,将2种可见噪声和4种不可见噪声随机切分出的噪声段与测试集中的纯净语音叠加,得到信噪比分别为-10 dB、-5 dB、0 dB、5 dB的含噪语音,最终测试集包含4536(189×2×4+189×4×4)条含噪语音,约4 h。实验中所有语音和噪声的采样率均为16 KHz。
3.2 评价方法
语音增强性能的评价方法包括质量评价和可懂度评价。质量性能可以表示听者听语音时的舒适度,而可懂度性能则表示语音中听者可以听懂的程度。为了比较不同方法的语音增强性能,本文采用现阶段广泛使用的两种客观评价算法评价增强语音的质量和语音的可懂度,包括:采用语音质量感知评估(PESQ)来评价增强语音的质量;采用短时客观可懂度(STOI)来评价增强语音的可懂度。其中PESQ即语音质量感知评估是ITU-T(国际电信联盟电信标准化部)推荐的语音质量评价指标,其得分范围为-0.5到4.5,得分越高表示增强语音的质量越好;STOI即短时客观可懂度,经证明与人类语音的可懂度主观评分高度相关,其得分范围为0到1,STOI得分越高,表示增强语音的可懂度越好。
3.3 评价结果
为检验本文提出的基于时域波形映射-频域谐波损失语音增强算法的语音增强性能,将本文提出的方法(FCN-HR、FCN-H)与采用对数功率谱(LPS)作为输入输出特征的基线DNN方法(DNN-baseline)以及两种基于时域波形映射的语音增强方法进行语音增强实验对比。两种基于时域波形映射的方法分别为:基于时域波形映射-时域最小均方误差损失的方法(FCN-MSE)和基于时域波形映射-频域幅度损失的方法(FCN-SM)。其中FCN-MSE即为传统的时域波形映射方法,直接使用原始波形和增强波形的均方误差(MSE)来计算损失。FCN-SM是一种改进的方法,使用STFT频谱幅度损失来训练时域的增强网络。为消除网络结构对增强效果的影响,两种基于波形映射的增强算法使用与本文提出算法相同的网络结构,并使用Adam进行批量归一化训练。
通过使用本文提出的方法和上述对比方法对测试集中的含噪语音进行增强,并计算增强后语音的PESQ和STOI得分。表1和表2分别给出了在4种不同信噪比条件下的语音增强算法PESQ得分和STOI得分,并加入未处理的含噪语音的客观评价得分作为对比。不同信噪比条件下的最佳结果均用粗体进行了标记。
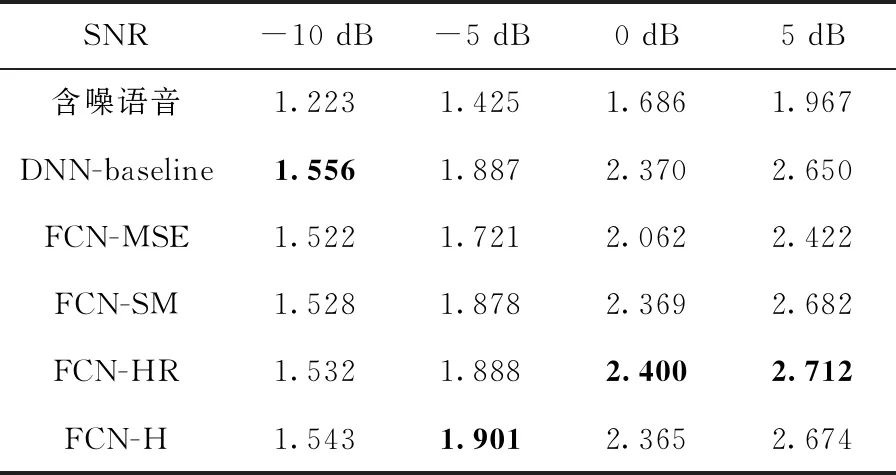
表1 不同信噪比下的平均PESQ结果
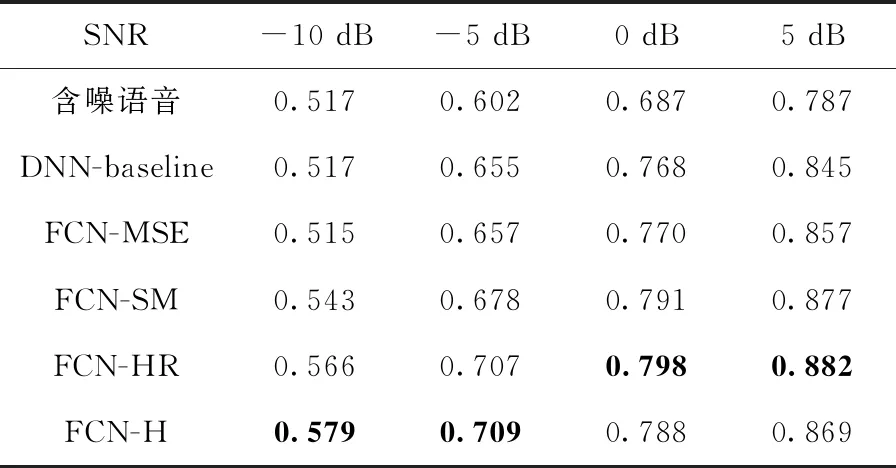
表2 不同信噪比下的平均STOI结果
结合表1和表2可以看出,在大多数情况下,本文提出的FCN-HR和FCN-H方法,相比其余3种对比方法具有更好的客观质量和可懂度得分,验证提出的方法可以有效提高语音增强的性能。
具体的,在-10 dB条件下DNN-baseline获得了最高的PESQ分数,但其STOI得分很低,结合主观听觉测试,发现该方法在去除噪声的同时消除了太多的语音成分导致增强语音难以理解,因此可懂度得分很低。同时,传统的时域波形映射方法FCN-MSE模型相比DNN-baseline的基线方法,在多数信噪比条件下STOI值有一定提升,这表明在进行语音增强时,时域波形映射对STOI得分有利。FCN-SM方法在传统时域波形映射方法的基础上改进损失函数,使用频域的损失来训练时域波形映射网络,相比传统时域波形映射方法进一步提升了PESQ和STOI得分,但其在-5 dB和-10 dB的低信噪比条件下,语音可懂度得分仍然较低,存在增强语音主观听感上很难听懂的问题。
而本文提出的FCN-HR和FCN-H方法在-5 dB和-10 dB信噪比条件下,相比两种基于时域波形映射的方法,均取得了更好的客观评价得分,在5 dB和10 dB条件下也取得了接近或者更好的得分,验证了本文使用的频域谐波损失可以进一步提高时域波形映射语音增强算法的性能。值得注意的是,在低信噪比(-10 dB)噪声条件下,所有对比方法在STOI得分上均出现了不同程度的失效,而FCN-H取得了最高的STOI得分和令人满意的PESQ得分,可以看出在低信噪比条件下,语音被背景噪声严重破坏时,提出的FCN-H方法将语音残余的比例系数设置为0,使网络集中注意力恢复语音的谐波分量,从而可以更好地去除谐波间的干扰噪声,恢复对语音可懂度贡献更大的浊音段语音。
3.4 语谱图分析
为了更直观比较提出的方法与其它方法的语音增强性能,使用上述的5种语音增强算法对测试集中一段含有factory2噪声,信噪比为-5 dB的含噪语音进行语音增强。然后对增强语音的语谱图进行比较。
图5包含纯净语音语谱图(a)、含噪语音语谱图(b)、DNN-baseline方法增强语音语谱图(c)、FCN-MSE方法增强语音语谱图(d)、FCN-SM方法增强语音语谱图(e)、FCN-HR方法增强语音语谱图(f)、FCN-H方法增强语音语谱图(g)。
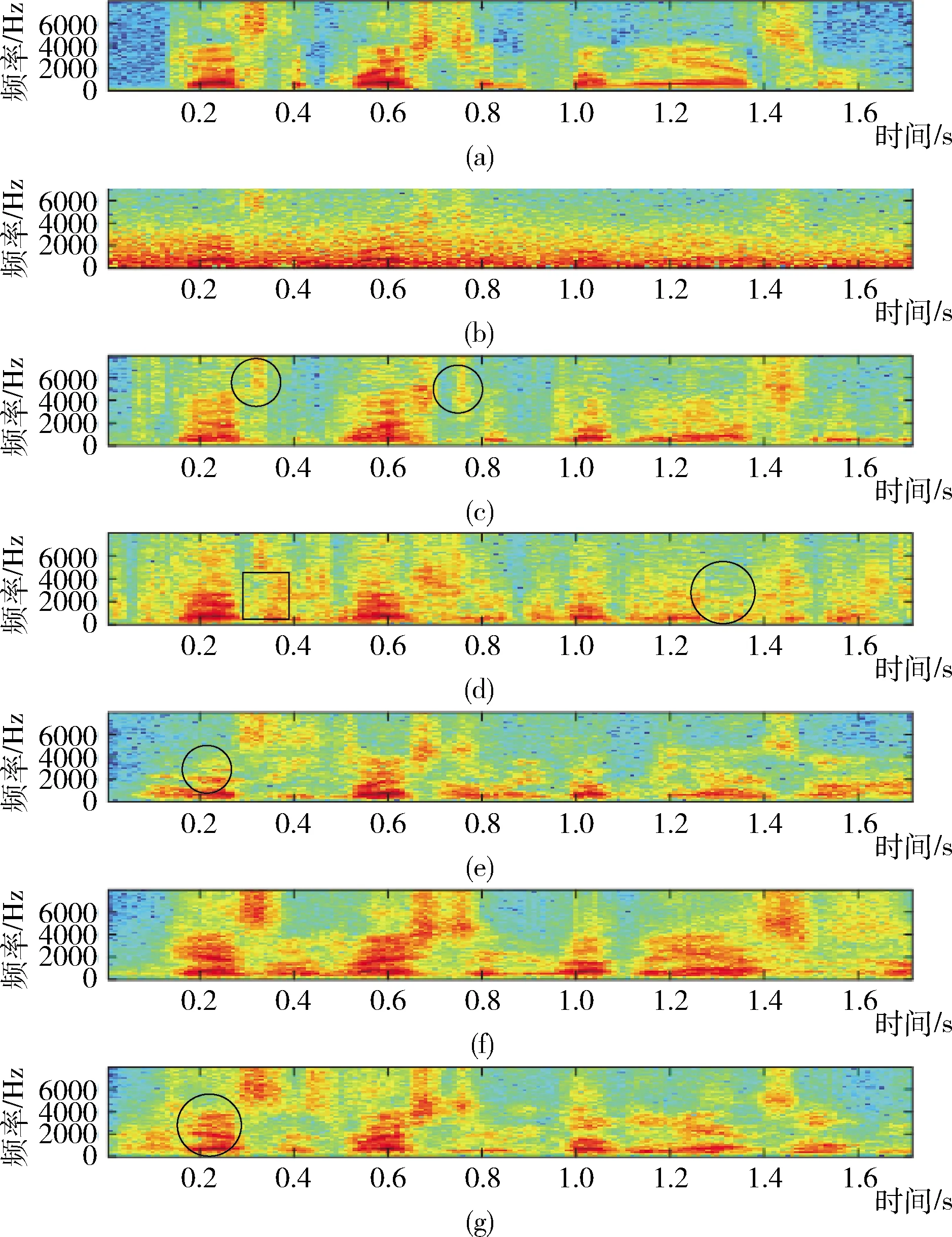
图5 语音信号的语谱图比较
具体的,相比图5(a)的纯净语音,图5(c)DNN-baseline的基线方法虽然残留噪声较少,但是存在语音失真的问题,如图5(c)中圆圈部分。这也是造成其客观可懂度得分较差的原因。图5(d)可以看出传统的基于时域波形映射的方法,存在如图5(d)中方块部分存在残留噪声的问题和如图5(d)中圆圈部分局部语音信息失真难以恢复,且不存在明显谐波结构的问题。这也很好地解释了传统基于时域波形映射方法仅简单使用时域最小均方误差损失不能获得令人满意的质量和可懂度得分的原因。图5(e)FCN-SM算法,使用频域的损失训练时域映射网络的方法,相比FCN-MSE有了更好的去噪能力,残留噪声较少,但仍存在一定的语音失真尤其是谐波结构不能完全恢复的问题,如图5(e)中圆圈部分,其中代表谐波的横纹结构不明显。将图5(f)和图5(g),与对比方法增强语音的语谱图相比,可以看出,本文提出的两种方法可以消除更多噪声,并且可以很好地恢复语音信息,验证了本文提出的频域谐波损失可以很好地提升语音增强效果。特别是图5(g)中圆圈部分可以看出,谐波可以清晰显示,有明显的横纹结构,说明着重恢复语音谐波分量的FCN-H方法可以更好地消除谐波之间的噪声,因此在低信噪比条件下可以进一步提高增强语音的可懂度。
4 结束语
本文提出了一种基于时域波形映射-频域谐波损失的语音增强算法。与FCN-MSE和FCN-SM的现有基于时域波形映射的语音增强算法相比,本文提出的算法旨在恢复语音的谐波结构,实验结果表明,我们提出的语音增强算法可以获得更优异的语音质量和可懂度得分。并且本文提出的着重恢复语音谐波分量的FCN-H方法可以进一步提高低信噪比条件下增强语音的可懂度。
下一步可以将本文使用的频域谐波损失函数中谐波和语音残余的比例系数进行调整,探究不同比例系数对语音增强性能的影响。此外,今后可以尝试使用其它语音分析模型对语音进行分析建模并将其应用在损失函数中。
