基于DBP的Top-k高效用项集挖掘算法
2021-06-28路昕宇王慧娇宋佳璐
蒋 华,路昕宇,王慧娇,宋佳璐
(1.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004; 2.西安邮电大学 计算机学院,陕西 西安 710061)
0 引 言
近年来高效用项集挖掘[1-4]成为数据挖掘领域的重要研究方向。Top-k高效用项集挖掘巧妙地将设定最小效用阈值的问题转变为设定所需高效用项集数量的问题,因此受到广泛关注。
由于多次扫描数据库并且产生大量候选集的缺点,以TKU算法[5]和REPT算法[6]为代表,二阶段算法逐渐被一阶段算法替代。一阶段算法则通过改进数据结构方式去解决二阶段算法的问题。TKO算法[5]采用效用链表结构,在算法第一次扫描数据库时将关键信息存入效用链表,之后只需扫描效用链表信息,通过连接操作和递归效用链表构建过程挖掘高效用项集。TOPKHUP[7]算法提出HUP-Tree结构,将事务效用保存到树结构中,使用HUP-Tree计算项集效用。TKHUP[8]算法采用投影方式将事务效用链表投影到投影表,并通过4种策略操作子投影表构建过程挖掘Top-k高效用项集。KHMC[9]算法在TKO算法基础上提出多种修剪策略降低候选集产生。Vert_Top-k DS[10]算法加入滑动窗口模式可以处理流数据。RHUM算法[11]提出重用链表R-list结构降低内存消耗。
上述Top-k高效用项集算法挖掘时需要不断合并项集构造效用链表,却忽略管理内存空间的效用链表,导致算法内存消耗量大,运行时间长。因此本文提出数据缓冲池(data buffer pool,DBP)结构的高效用项集挖掘算法TKBPH。算法将效用链表存储在数据缓冲池并由索引链表记录其位置,挖掘过程中通过直接访问索引链表读取效用链表位置,在数据缓冲池动态插入和删除效用链表,降低内存空间消耗,提升算法效率。
1 相关定义及问题陈述
设由m个项组成的项集I={i1,i2,i3,…,im},则项集长度为m或称为m-项集。设事务数据库D={T1,T2,T3,…,Tn},对于每个事务Tk(1≤k≤n)都由I的子集组成。项集I中的每个项ik(1≤k≤m)都与有内部效用qi(数量)和外部效用pi(利润)与之关联,如表1所示,事务T1中的项a和项b的内部效用分别为2和1。项的外部效用见表2。

表1 事务数据库

表2 外部效用
定义1 令事务Tk中项i的效用为u(i,Tk),u(i,Tk)=p(i)×q(i,Tk)。
定义2 令事务Tk中项集X的效用为u(X,Tk),u(X,Tk)=∑i∈Xu(i,Tk)。
定义3 令数据库D中项集X的效用为u(X),u(X)=∑X⊆Tk⊆Du(X,Tk)。
定义4 令事务Tk的事务效用为Tk中项集效用值之和,记作TU(Tk)=∑i∈Tku(i,Tk)。
定义5 用户给定最小效用阈值minUtil,如果项集X的效用u(X)≥minUtil,则称项集X为高效用项集,反之则称项集X为低效用项集。
频繁项集挖掘算法中基于支持度的反单调性。修剪搜索空间的方式不能直接用于效用度量来挖掘高效用项集。高效用项集挖掘算法通常采用事务加权效用(transition weighted utility,TWU)度量高估项集效用来解决这个问题。事务加权效用度量假定所有项的外部效用均为正值,定义如下。
定义6 设项集X的事务加权效用为所有包含项集X的事务效用之和,记作TWU(X)=∑Tk∈g(x)TU(Tk)。
性质1 项集X的事务加权效用不低于它的效用,TWU(X)≥u(X)
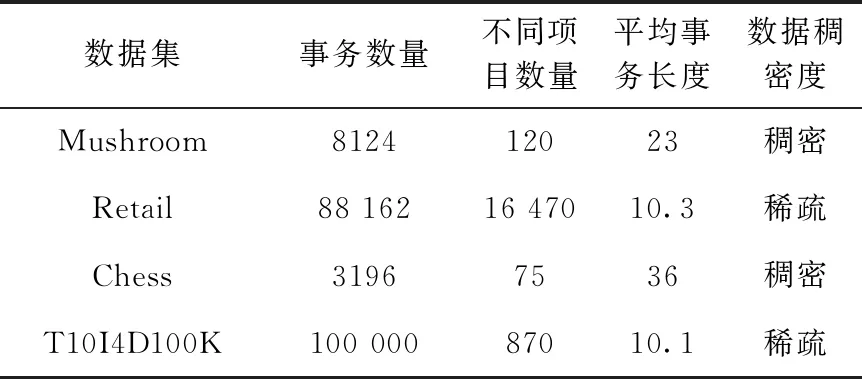
性质2 如果项集X的事务加权效用TWU(X) 定义7 令项集I为数据库D中所有项的集合并以事务加权效用值升序排列。数据库D中项集X的效用链表记作PX.UL,效用链表由(tid,iutil,rutil)形式的元组构成。tid为事务Tk的唯一标识符,iutil为事务Tk中项集X的效用,rutil为事务Tk中除项集X外其余项集效用之和,记作∑i∈Ttid∧i≻x∀x∈Xu(i,Ttid)。 性质3 项集X的效用为u(X)可以通过效用链表中iutil值的总和来计算。如果iutil之和SumIutil小于min-Util,那么项集X为低效用项集。否则,项集X是高效用项集。 定义8 数据库D的评估效用共现结构(estimated utility co-occurrence structure,EUCS)记作EUCSD,EUCSD={(a,b,TWU(ab))∈I*×I*×R+},I*是数据库D中不小于最小效用阈值minUtil的项集。 为了有效管理项集挖掘过程中的内存管理,提高内存复用率,降低系统内存空间消耗,本文提出数据缓冲池(data buffer pool,DBP)结构用于管理Top-k高效用项集挖掘过程的内存空间,具体定义如下: 定义9 令I为数据库D中所有项的集合,TidD为数据库中所有事务标识符的集合,数据库D的数据缓冲池结构记作DBP。DBP采用(tid∈TidD,iutil∈R,rutil∈R)的元组形式存储效用链表,这些元组称为数据段。 为了快速访问和维护存储在数据缓冲池的相关信息,采用索引链表存储数据段在数据缓冲池的位置信息和效用信息,索引链表定义如下: 定义10 令X为数据库D中的项集,IndexList(X)为项集X相关信息的索引链表,IndexListD={IndexList(X),X⊆I}。IndexList(X)存储的元组形式为(X,StartPos,EndPos,SumIutil,SumRutil)。其中StartPos和EndPos元素分别表示数据缓冲池中数据段起始位置和结束位置。SumIutil元素存储效用链表PX.UL中iutil之和。SumRutil元素存储效用链表PX.UL中rutil之和。 在应用数据缓冲池结构中,TKBPH算法创建4个链表,分别是Tids、Iutils、Rutils和IndexList。前3个链表存储数据段,IndexList索引链表记录数据段的位置信息和效用信息。如图1所示,项g的效用为u(g,T5)=8,剩余效用为ru(g,T5)=29,项g只出现在事务T5,所以项g只有一个数据段为(5,8,29)。由于g是第一个插入IndexList索引链表的项,起始位置StartPos和结束位置EndPos分别为0和1,总效用之和SumIutil为8,剩余效用之和SumRutil为29。 图1 数据缓冲池中的项g 在挖掘过程开始时,TKBPH算法将这4个链表初始化为空并将单一项的效用链表分别存放在4个链表。随着挖掘过程的进行,项集的效用链表全部插入到数据缓冲池。>如图2所示,表1中所有项的效用链表均存储在数据缓冲池。 图2 插入项集后的数据缓冲池 当数据缓冲池初始化的内存空间已满,数据缓冲池会自动扩充内存空间存放效用链表。当数据缓冲池中的效用链表不在被挖掘过程所需要时,数据缓冲池会释放相应的效用链表,将回收的内存空间重新分配给需要插入的效用链表,同时更新IndexList索引链表中效用链表的位置信息。 在进入搜索子程序时发现项集X和X的分支项集可能是一个潜在的高效用项集,TKBPH算法通过将项集X的效用链表临时插入到数据缓冲池尾部,并记录存储其存放位置StartPos和EndPos。当需要查找项集X的效用链表时,TKBPH算法可以直接访问索引链表中StartPos和EndPos信息读取相关数据。假设TKBPH算法正在处理项集{d},通过索引链表IndexList查询项集{d}的信息,根据StartPos和EndPos的位置信息直接访问数据缓冲池{d}的效用链表。当搜索子程序完成对项集X的效用链表搜索时,算法将数据缓冲池分配给项集X效用链表的临时内存重新分配给其它需要被搜索的项集效用链表,提高内存复用率。具体数据缓冲池构建过程见算法1。 算法1:数据缓冲池构建过程 输入:数据缓冲池DBP,索引链表IndexList,项集P,Px,Py 输出:更新数据缓冲池DBP和索引链表IndexList中的Pxy 设PPnt,PxPnt,PyPnt分别为索引链表IndexList(P).StartPos,IndexList(Px).StartPos,IndexList(Py).StartPos起始位置的3个指针同时指向数据缓冲池DBP。 (1)如果指针PxPnt指向元组中Tids小于指针PyPnt指向元组中Tids,那么将指针PxPnt向右移动一位; (2)如果指针PxPnt指向元组中Tids大于指针PyPnt指向元组中Tids,那么将指针PyPnt向右移动一位; (3)如果指针PxPnt指向元组中Tids等于指针PyPnt指向元组中Tids并且索引链表IndexList(P)不为空,那么指针PPnt连续向右移动,直到指针PPnt移动到IndexList(P)的结束位置或者指针PPnt指向元组中Tids和指针PxPnt指向元组中Tids相同; (4)数据缓冲池DBP的尾部添加一个新元组,令Tids为指针PxPnt指向的Tids,Iutils为指针PxPnt指向的Iutils加指针PyPnt指向的Iutils减去指针PPnt指向的Iutils,Rutils为指针PyPnt指向的Rutils; (5)当指针PxPnt没有指向索引链表IndexList(Px)的结束位置EndPos,并且指针PyPnt没有指向索引链表IndexList(Py)的结束位置EndPos时,返回步骤(1); (6)更新索引链表Pxy和数据缓冲池IndexList。 TKBPH算法是一阶段高效用项集挖掘算法,即算法在执行过程中仅需扫描一次数据库计算项集的加权事务效用值。数据库中项集的效用链表全部存入数据缓冲池,并将相关信息存入索引链表IndexList。挖掘过程时将需要挖掘项集X的效用链表依次插入数据缓冲池尾部,完成挖掘后不再需要项集X的效用链表时,TKBPH算法将数据缓冲池中分配给项集X的效用链表临时内存空间回收并重新分配给其它需要挖掘的效用链表。 TKBPH算法主要分为3步,第一步扫描数据库计算单一项的加权事务效用值并按升序排列;第二步建立数据缓冲池DBP和索引链表IndexList;第三步调用搜索子程序Search挖掘高效用项集,通过用户设定的k值,不断更新最小效用阈值minUtil,挖掘出前k个高效用项集,整体算法见算法2。 算法2:TKBPH算法 输入:事务数据库D,k值 输出:高效用项集 (1)初次扫描事务数据库D并计算单一项的加权事务效用值,将最小效用阈值minUtil初始化为0; (2)将单一项的效用链表存入初始化链表I*并按加权事务效用值升序排列; (3)再次扫描数据库D,数据缓冲池DBP和索引链表IndexList,建立EUCS结构,创建高效用项集队列; (4)调用搜索子程序Search,将初始化链表I*、EUCS结构、数据缓冲池DBP和索引链表IndexList传入子程序Search; (5)输出前k个高效用项集。 搜索子程序Search是一个递归过程,根据之前算法得到的项集P和P的分支项集,挖掘高效用项集。在算法挖掘过程中通过性质2和性质3,判断项集P和项集P的分支项集是否为高效用项集。如果项集P为高效用项集则将项集P加入到高效用项集链表。如果项集P的分支项集为高效用项集,那么通过调用数据缓冲池构建过程挖掘高效用项集,直到遍历完所有项集。具体实现见算法3。 算法3:搜索子程序Search 输入:初始化链表I*,EUCS结构,数据缓冲池DBP,索引链表IndexList,项集P和P的分支项集 输出:高效用项集 (1)对于每一个项集P的分支项集Px,如果索引链表IndexList(Px)的SumIutil不小于最小效用阈值minUtil,那么将项集Px加入到高效用项集队列。在项集Px加入之前判断队列长度是否大于k值,若小于k值,直接将项集Px插入队列;若队列长度大于k值,则比较项集Px的效用值和高效用队列中的最小值。如果项集Px的效用值小于高效用队列中的最小值,则不插入队列。如果项集Px的效用值大于高效用队列中的最小值,则删除最小值的项集,插入项集Px并将minUtil更新为高效用项集最新的最小值; (2)如果项集Px的索引链表IndexList(Px)中的SumIutil与SumRutil之和不小于最小效用阈值minUtil,那么Px的分支项集则可能是高效用项集; (3)对于每个项集P的分支项集Py,Py与Px合并使得y>x并且TWU({x,y})≥minUtil,形成新的Pxy分支继续执行; (4)将项集P,Px,Py,数据缓冲池DBP,索引链表IndexList作为参数调用数据缓冲池构建过程; (5)完成数据缓冲池构建后,若Pxy链表不为空,则Pxy及其分支项集将被搜索进程Search继续挖掘,不断地递归此程序直到没有分支项集。 从内存空间方面分析,TKBPH算法采用数据缓冲池进行高效内存管理,在挖掘开始时将单一项效用链表一次性插入到数据缓冲池。在搜索子程序Search挖掘分支项集时仅需在数据缓冲池尾部临时插入需要挖掘的项集效用链表,搜索子程序Search完成对该项集效用链表的挖掘时回收该项集所占用内存空间重新分配给其它需要挖掘的项集效用链表,极大地提高内存复用率,减少内存空间浪费。 从时间复杂度方面分析,TKBPH算法在输入数据集后,算法的第一步是计算单一项的TWU值,需要扫描一次数据库,设数据库D有m个事务,其中最大事务包含n个项,时间复杂度为O(mn)。在之前算法中,通过某些子集的效用链表相交构造项集的效用链表。对于链表Px.UL中每个元组都需要在链表Py.UL二分查找是否存在相同元组。设s和t分别为Px.UL和Py.UL,则效用链表构建过程的时间复杂度表示为O(slogn)。TKBPH算法提出数据缓冲池结构,将数据缓冲池的数据段位置信息记录在索引链表。通过读取索引链表,TKBPH算法直接访问数据缓冲池中数据段的效用链表,构建过程的时间复杂度为O(s+t)。所以TKBPH算法的总体时间复杂度为max{O(mn)+O(s+t)}。 本文从运行时间和内存消耗两个方面作为标准评估算法的性能。实验选取目前主流的TKO、TKU和Vert_topk DS算法与本文提出的TKBPH算法进行对比。算法均采用Java编写,实验设备处理器为英特尔酷睿i5-4300,8 G内存,搭配64位Window 7操作系统。对比算法的Java源码和数据集来自于SPMF[12]和UP-Miner[13],数据集的数据特征见表3。 表3 实验数据集 实验采用两个稠密数据集和两个稀疏数据集对TKBPH算法进行充分对比。数据集Mushroom、Retail和Chess是来自现实场景的真实数据集,数据集T10I4D100K是由IBM数据合成器生成的语义数据集。所有数据集使用对数正态分布生成项的外部效用介于-1000和1000之间,项数量在1和5之间随机生成。由于k值设置较低,所以算法运行时间超过200 s或者内存溢出则视为低效,立刻终止算法运行。 将TKO、TKU、Vert_top-k DS算法与TKBPH算法在不同数据集进行测试,运行结果如图3所示。在语义数据集T10I4D100K上,当k值等于4000时,TKBPH算法仅需5.28 s,而TKU算法的运行时间已经高达121.47 s,其余TKO和Vert_top-k DS算法也分别为24.46 s和29.71 s。在稀疏数据集Retail上,TKBPH算法不仅运行时间最短,而且随着k值的增长,时间效率变化非常平稳。当k值从200上升至800,TKBPH算法的运行时间仅从25.76 s上升至28.66 s,然而Vert_top-k DS算法已经从121.75 s上升至431.39 s。在稠密数据集Chess和Mushroom上,TKBPH算法同样性能优异,对比在Chess数据集上进行实验的其它算法,在同等k值情况下,仅需其它算法大约二分之一的运行时间。主要原因是单一项效用链表在链表初始化时已经插入到数据缓冲池,当搜索子程序Search挖掘分支项集时,只需把合并项集的效用链表插入到缓冲池,根据索引链表IndexList中单一项效用链表的位置信息直接读取效用链表信息进行计算,从而避免之前算法项集合并时大量比较操作,提高算法运行效率。 图3 4种算法在不同数据集下的运行时间对比 通过将4种算法在不同数据集上运行,监测内存空间使用量如图4所示。TKBPH算法提出的数据缓冲池结构,将单一项的效用链表存储在数据缓冲池,将数据缓冲池内效用链表的位置信息存储在索引链表。挖掘新的分支项集时只需在缓冲尾部加入新的项集,当完成挖掘操作不再需要此项集时,数据缓冲池会回收此项集所占用的内存空间等待分配给其它需要的项集。数据缓冲池充当内存管理者角色,将内存中不需要的空间回收再利用,使得算法运行时内存空间的消耗大幅降低。相比其它算法,TKBPH算法在实验中所需的内存仅需二分之一甚至更少。由于缓冲池结构的内存复用,在调整k值的过程中,内存消耗的波动非常平稳。在数据集T10I4D100K的实验中TKBPH算法内存从50.32 MB上升至54.14 MB,然而其它算法中内存消耗最小的TKO算法内存消耗从286.1 MB至538.38 MB,内存波动最小的TKU算法在551.68 MB到567.76 MB,但内存消耗比TKBPH算法相比高一个数量级。 图4 4种算法在不同数据集下的内存消耗对比 本文提出一种Top-k高效用项集挖掘算法TKBPH,该算法主要采用数据缓冲池结构和索引链表方式与构造效用链表过程相结合,通过内存复用的方式减少挖掘高效用项集所需运行时间和内存空间。通过选取4个不同类型的数据集对算法运行时间和内存使用量进行实验论证,实验结果表明TKBPH算法提出数据缓冲池结构相比于传统的效用链表构建过程,时间和内存使用量最多降低一个数量级。 随着在线交易系统、无线传感器网络、社交媒体等领域的广泛应用,流数据处理逐渐成为研究热点。在未来工作中,对于流数据和缓冲区结构的特性,将数据缓冲池结构应用于流数据的高效用项集挖掘算法。2 基于DBP的Top-K高效用项集挖掘算法
2.1 DBP结构


2.2 TKBPH算法
2.3 算法性能分析
3 仿真实验及结果分析
3.1 实验设置
3.2 运行时间分析

3.3 内存消耗分析

4 结束语
