实验报告抄袭检测系统的研究
2021-06-21于海浩黄成哲
于海浩,汪 伟,黄成哲,孙 栩
(黑龙江工程学院 计算机科学与技术学院,哈尔滨 150050)
抄袭检测是反抄袭的有效手段,是帮助教师评价学生学习成果的有力工具,对学校教育教学质量的提高有重大的促进作用[1]。许多学校和机构都制定了各种学术规范和标准来检测抄袭[2-4]。国内应用最广泛的是CNKI,国外抄袭检测系统主要有Turnitin、PlagScan、Dupli Checker、Plagiarism Checker、Copyleaks等系统。
针对抄袭检测技术的应用,学生不断实施反抄袭技术。他们利用改变语序、相似词替换、主被动语句修改、概念泛化等多种手段来逃避抄袭系统的检测。这种行为对抄袭检测软件构成严峻挑战,需要抄袭检测软件不断地改进抄袭检测的算法和模型。抄袭语料是抄袭检测技术的研究基础,反映真实抄袭文本的语料库对抄袭现象和规律的分析、抄袭检测算法的设计起着至关重要的作用[5]。但抄袭者一般不会同意将他所采用的多种反抄袭手段和反抄袭改写的内容应用于研究中,使得真实抄袭检测语料库的获取比较困难。
针对学生多变的抄袭手段和抄袭语料匮乏的问题,开发了实验报告抄袭检测系统,在实现实验、实习报告、课程论文、作业等抄袭检测的基础上,创新性地增加了以下三项功能:
1)针对不同抄袭类型的自适应抄袭检测。系统使用自适应抄袭类型检测算法[6],动态判别不同抄袭类型,涵盖了对照搬照抄、简单修改的低模糊抄袭、释义修改的高模糊抄袭的检测。
2)抄袭语料自动获取。系统使用基于自然标注的抄袭语料获取算法[7-9],从学生多次提交的同一主题的文档中自动获取高质量的释义抄袭语料。
3)抄袭算法自动更新。系统通过自动获得的抄袭语料不断训练抄袭检测模型,实现抄袭检测算法的自动更新。
在实现创新性功能的基础上,使用实验报告抄袭检测系统,对提高高校教学质量、减轻教师工作负担具有重要价值。主要作用有如下几个方面:
1)方便了解学生专业知识的掌握情况。教师利用系统的智能化分析,能够很好地了解学生对专业知识的掌握情况,并能够做出合理的作业评价,有利于学生水平的整体提高。
2)减轻教师的工作负担和压力。系统的重复性检测可以让教师免去审查学生是否具有抄袭行为的工作,极大地减轻了教师的工作负担和压力,同时通过报告质量检测中的自动打分,可以辅助教师完成作业、报告的批改工作,减少教师的工作量。
3)有利于改变学校学风。反抄袭技术在教学活动中的使用,能够促进学生的自主学习和创新意识,保证学校毕业生的质量,营造学生良好的学习氛围。
1 系统框架和核心算法
实验报告抄袭检测系统以在抄袭检测国际评测PAN@CLEF上多次获得第一名的抄袭检测算法为技术基础,围绕高校与课程相关的各种文档的原创性检查这一主要功能,实现实验、实习报告、作业等全过程质量管理,辅助教师评估学生报告质量,实时发现报告中的学术不端问题,有效预防抄袭行为,引导学生遵守学术规范,树立学术诚信。
在本系统中,教师的主要任务是建立课程和该课程下的所有实验,导入学生数据,设定相关参数。教师人工检查学生报告是否抄袭交由系统自动完成,极大地减轻了教师的工作负担,降低了抄袭率。具体对比情况见表1。学生主要任务是将自己的报告形成电子文档后上传到系统中,对于报告没有通过的学生,需要修改后重新上传报告。系统通过从学生多次提交的同一主题文档中自动获取高质量的释义抄袭语料,并且利用这些语料不断训练更准确的抄袭检测算法和模型[6]。具体对比情况见表2。

表1 抄袭比重与效率对比调查

表2 抄袭检测时间与准确率对比
1.1 系统总体框架
系统总体框架如图1所示。其中,文本的深度匹配模块实现针对不同抄袭类型的自适应抄袭检测,抄袭语料构建器实现抄袭语料自动获取,并且向文本的深度匹配模块提供模型训练和更新的数据。
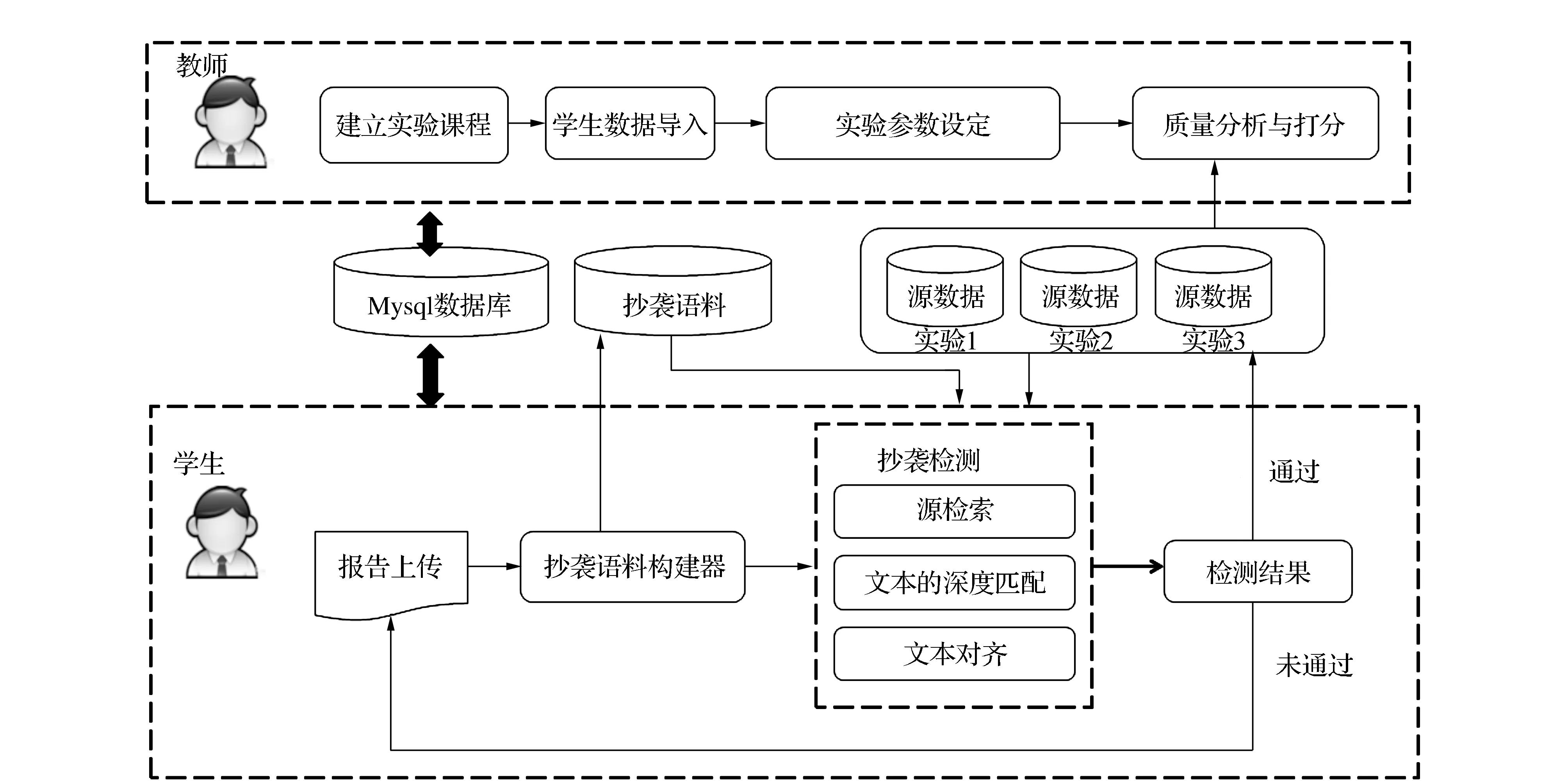
图1 系统总体框架
1.2 抄袭语料自动获取
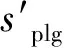
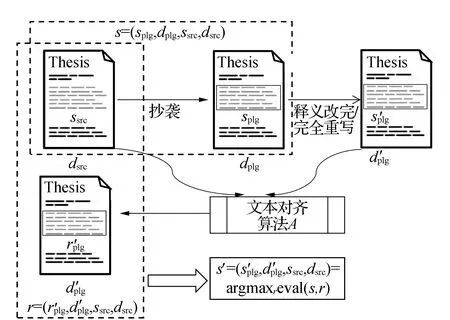
图2 抄袭语料构建过程
1.3 自适应抄袭检测
1.3.1 多类型文本特征提取
现有的研究大多以文本在某类特征上(如词汇、语义等)的相似度作为是否存在抄袭的依据。这样的方法在低模糊的抄袭和非模糊的抄袭上取得了较好的效果,但在高模糊抄袭的识别上却丢失了大量的抄袭种子,最终无法获得令人满意的效果。笔者采用的多类型文本特征主要有词汇特征、语义特征和句法特征。词汇特征采用的是基于单词的n-gram和基于字符的n-gram。这些特征包括N-gram距离、Dice系数、Jaccard系数等;语义特征采用WordNet3.0作为语义库,利用语义距离,根据文献[10]计算两个概念的语义相似度,从而获得待比较文本片段在语义上的相似度;句法特征方面采用文献[11]POS n-gram距离;结构特征采用文献[12]的Word Pair Order,该特征用于计算两个文本片段中以相同顺序出现的两个单词。
1.3.2 基于逻辑回归模型的抄袭检测自适应算法
使用逻辑回归模型结合词汇、句法、语义和结构特征来自适应各类型的抄袭,并通过利用各种特征来捕获更多抄袭种子。

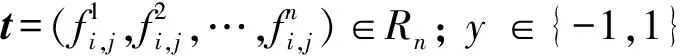
(1)
系统通过训练这个基于二项逻辑回归的分类器C,学习各类抄袭特征的预测结果在最终分类决策中的权重,据此判断文本片段si∈dplg与rj∈dsrc存在抄袭的概率。如果si与rj存在抄袭的概率大于si与rj不存在抄袭的概率,则分类器输出为1,否则输出为-1。利用分类器C(si,rj),对给定的dplg=(s1,s2,…,sn)和dsrc=(r1,r2,…,rn),获得dplg和dsrc中所有疑似抄袭片段对(si,rj)的列表,这些抄袭片段对将作为抄袭种子。
2 应用效果及分析
系统目前支持用户并发数1 000以上,单篇论文详细分析时间5.9 s以内,日检测量可达10 000篇,可疑片段召回率70%,抄袭检测精确率96%,系统界面展示如图3所示。
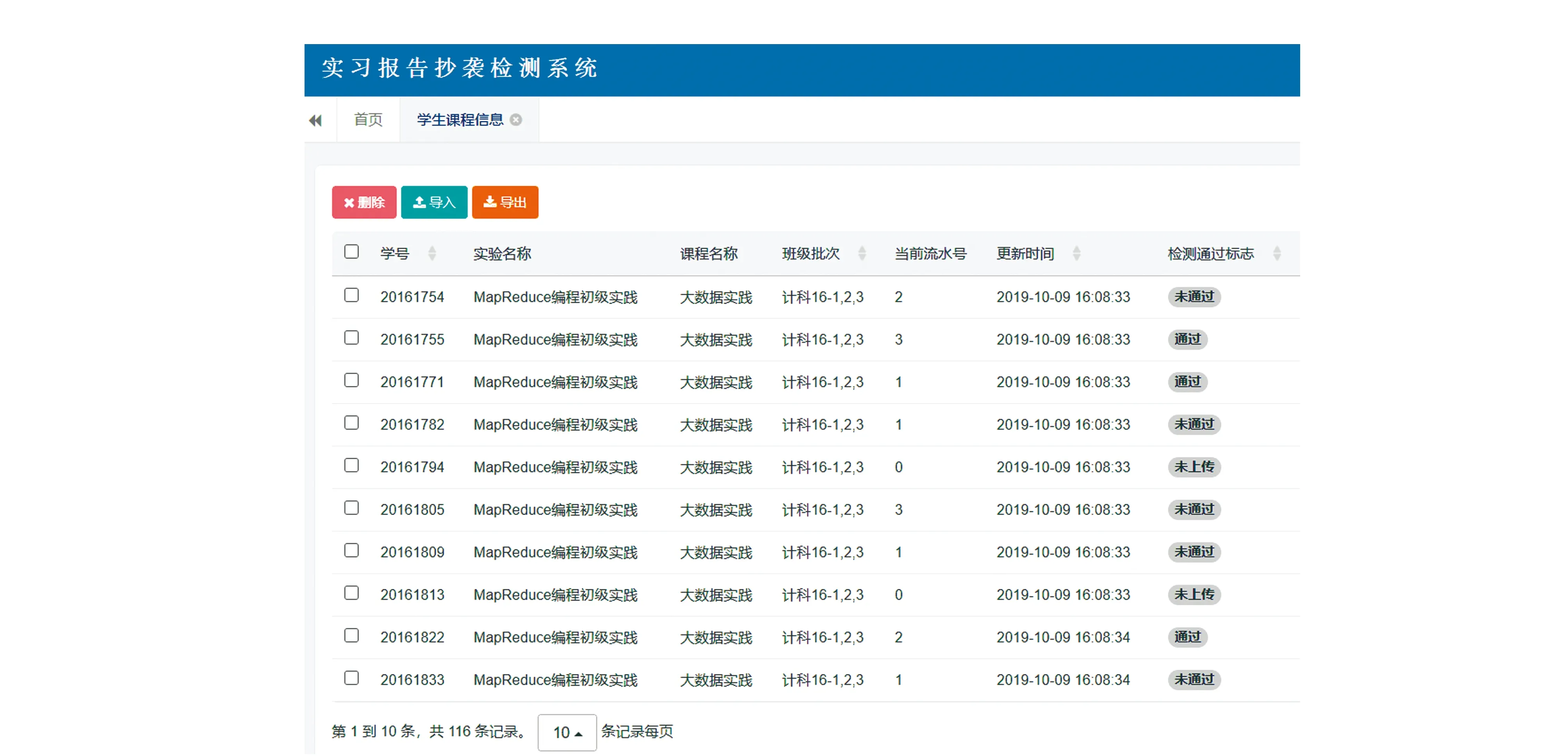
图3 系统界面展示
文中选取三门课程,对每门课程同一实验内容的所有学生的实验报告分别通过人工方式和系统自动检测方式进行数据对比,如表1所示。其中,合格抄袭率是教师设定的学生报告确认为合格的抄袭率最高值,抄袭率=抄袭字数/全文字数,抄袭占比=抄袭学生数/全部学生数。从表1—2可以看出,使用系统的教师平均检查时间降低至原来的1/6,学生的抄袭占比下降近38%。
将上述三门课程实验内容每名学生的实验报告分别在两个抄袭检测算法中运行,一个抄袭检测算法是使用自动获取抄袭语料来不断训练、更新抄袭检测模型的机器学习算法,另一个使用传统的启发式算法。从表1—2对比可知,每篇抄袭检测平均时间提高近5 s,准确率提高近3%。
3 结束语
文中设计实现了一个基于统计机器学习的实验报告抄袭检测系统。该系统采用基于自然标注的抄袭语料自动获取方法,从学生多次提交的同一主题的文档中自动获取高质量的释义抄袭语料,利用这些语料不断训练更准确的抄袭检测算法,模型的应用提升了抄袭检测的性能。实际应用表明,该系统能够满足高校教学科研活动的需要,对实践教学质量的提升有良好的促进作用。
