基于BP神经网络的上市公司财务预警模型研究
2021-06-12杨钰晨丁元耀
杨钰晨,丁元耀
(宁波大学 商学院,浙江 宁波 315211)
一、引言
经查询,截止到2020 年6 月30 日,一共有3 897家上市公司在沪交所和深交所挂牌交易,流通市值和股票市价总值也分别达到了545 787.95 亿元和678 212.83 亿元。随着经济的快速发展,上市公司逐渐成为市场的重要组成部分,影响着市场的稳定和发展,但同时也带来了一些隐藏的风险。实质上,投资者就是通过在资本市场中对资本进行市场运作来获取收益的。因此,对公司财务状况进行预测,也变成了投资者是否进行这项投资行为的决策参考。理论意义上,一方面企业的财务预警问题已经随着市场经济的发展发生了一系列的转变,从指标化的分析转变为了建立模型来对企业进行检测分析;另一方面,再次对企业危机预警这些问题的研究,可以对已有的企业理论和风险管理理论进行完善和发展。现实意义上,选取这个研究主题,可以对上市公司的财务预警研究进行更加深入的理论研究,还可以结合我国市场实际情况对上市公司的潜在风险进行检测和预测,来判断该企业是否存在财务危机或即将发生财务危机的可能,以此来对危机进行防范。
二、文献综述
(一)财务危机的界定
许多偶然因素都有可能给某个企业带来危机,例如市场环境和决策者失策。但从整个行业来看,企业群体一般危机和财务危机的发生则存在着一定的客观性和必然性,国外的学者们一般在企业的某项指标发生变化时对财务危机进行界定。
Beaver(1966)[1]在研究中认为,当一家企业开始拖延支付股息、透支银行存款金,并且没有能力偿还债券,就可以认为其存在财务危机。Odom 和Sharda(1990)[2]则认为当一个企业的现金流能力出现无法修复的情况时,财务危机便开始形成。Ross 等(1995)[3]则认为财务危机不能从某些单个方面去界定,他们分别从四个方面对财务危机进行了相对全面的研究。
目前我国国内文献一般不将破产清算作为界定的标准,因为破产清算就意味着企业已经破产,那么对其的预测将不能产生一系列补救的手段。同时,由于某些数据问题,我国国内大部分学者在进行实证研究时,仍然将上市公司被特别处理(ST)作为发生财务危机的一个标志。但也有少部分人认为只仅仅将ST 作为财务危机的标志是不全面的。陈凯凡和陈英(2004)[4]认为从债权人的角度预测企业财务危机更有现实意义,也更加符合我国国情。吴星泽(2011)[5]认为当企业的相关利益者受到损害的情况下,并且企业支付能力不足就会导致财务危机。朱兆珍(2016)[6]从企业生命周期的角度观察财务预警,她认为根据生命周期理论,当企业处于不同的生命周期时,判断企业是否发生财务危机所要观察的指标是不同的。因此财务危机的界定应该从各方面进行研究,仅依赖于单一指标测定的财务危机缺乏准确性。
(二)财务预警模型研究现状
根据对国外文献的研究,最早的财务危机预测开始于20 世纪30 年代,Fitzpatrick 用破产和非破产公司的19 组数据作为研究样本,最终结果表明,破产和没有破产的企业,其财务比率存在着显著的区别,同时拥有相对来说最高的预测能力的两个指标是净利润/股东权益和股东权益/负债[7]。
1966 年,芝加哥大学教授Beaver 用某一单个财务比率来建立模型,研究表明,当样本发生的时间与实际中所产生的危机时间段之间的关系与模型的准确度是呈正相关关系的[1]。1977 年,Altman、Haldeman 和Naravanan 首创性地选取样本,将Z 模型进行修整,并且新增了两个变量[8]。同年,Martin第一次在Z 模型的研究基础之上,将Logistic 回归模型和财务危机问题进行结合,以58 家来自美联储众多银行发生危机的银行为样本,进行了预测[9]。相较于Z 模型,Logistic 回归模型的错判率明显较低,但随着当前技术的飞速发展,它已经不能满足财务预警机制所要求的精准性。1990 年,Odom 和Sharda 第一次创造性地将神经网络模型运用到财务危机预警中去,并将65 家企业按照一定的比例划分为训练组和检测组,最后发现,研究结论是该型比其他模型更加准确[10]。
与国外财务预警模型相比,国内财务危机预测的研究尚处于起步状态,这基本上是在验证现有的方法适不适合中国的市场环境,因此与国外有一定的差距。但在国外研究的基础上,许多研究中,学者们已经开始基于中国国情对该问题进行研究,加入了许多中国特有的元素。
吴世农和黄世忠(1986)[11]在他们的研究中用财务指标分析并建立了预测模型。这之后,邢精平在深、沪两市场选取了1998 年和1999 年中38 家ST公司和132 家正常健康的公司作为样本,运用多元逻辑回归方法进行财务危机预测[12]。鲍新中和何思婧(2012)[13]提出新思路,认为以往的财务困境预警研究都忽略财务困境程度的度量这个问题,因此提出一种基于集成聚类、粗糙集、神经网络方法的财务预警思路。黄晓波和高晓莹(2014)[14]将非财务指标也引入到神经网络模型中,更加全面地对训练的指标进行分析。刘萍和张燕宇(2015)[15]通过Z-Score模型对制造业上市公司进行预测,结果都显示预警模型精度较高。
目前越来越多的学者开始致力于提高财务预警模型精度,关于财务困境的研究也发展到了对集成算法的应用阶段,例如庞清乐和刘新允(2011)[16]创造性地将蚁群算法和神经网络放在一起用来对财务危机进行研究。张培荣(2019)[17]将Xgboost 与财务危机预测结合。在预警变量筛选方法上,杨波(2017)[18]提出财务危机预警变量筛选新方法偏最小二乘方法,并通过实证来论证偏最小二乘方法在筛选财务危机预警变量中的优势。蒋晶晶等(2020)[19]选取盈利指标,基于粒子群优化算法来对企业财务危机进行预测。
此外大部分对于财务危机预测的研究仍采用静态均衡数据进行建模,王鲁(2017)[20]构建了一种既能动态选择样本又能处理非均衡数据的动态预测模型,有效提高了预测精度。
这之后,毕明琪(2019)[21]、李鸿禧和宋宇(2020)[22]通过COX 模型与财务预警模型的动态结合,研究宏观因子下财务预警模型的精度。周梦洁还通过同行业非平衡数据进行了模型建立,同样得出预警效果较好的结果[23]。
(三)研究述评
企业财务危机预警开始于20 世纪30 年代,目前,在该领域的研究越来越成熟。在回顾总结这些研究时,我们发现这个历程可以根据研究方法分为四个阶段:对趋势的分析、对危机的判别、人工智能的加入分析和前沿技术的引入。这些阶段是财务预警研究的一步一步发展的过程,那么投资者如何判断预警模型的预测能力以及如何选择不同的预警模型就成了我们主要研究的问题。因此本文选取2019 年首次被公开处理的上市公司为样本,结合神经网络算法,对2016 年样本公司的财务数据进行判别和预测。另外本文还将通过不同模型的对比分析基于人工神经网络建立的财务预警模型是否存在其优势。
三、模型设计
在研究了市场环境和会计的相关准则之后,由于我国对财务危机的界定还没有进一步的发展,所以本文认为财务危机的界定还仍然延续以往学者的建议,认定是被公开特别处理或被退市风险警示的上市公司。首先研究对象是2019 年首次被公开ST 或*ST 的上市公司,在除去了因审计未通过以及因重大诉讼被处理的公司之后,对样本数据进行处理,总计40 家。另外在数据处理过程中剔除重复的B 股数据以及缺少个别数据的公司,最终样本数为36家;其次,又以训练样本:检测样本以7∶3 的比例,检验样本数则为11;然后随机抽取40 家非ST 样本,选取与ST 公司相对应的数量。剔除缺少数据及重复的公司,具体样本数量如表6 样本统计表所示。
在时间的选择上,根据观察,这些公司都是由于2017 年度和2018 年度连续两年的净利润均为负值才被特别处理的,但由于其名称全部改为了*ST,因此应当选取2016 会计年度的相关指标进行预测。如表1 样本统计表所示。

表1 样本统计表
(一)模型指标的选择
在参考了现有的研究之后,我们发现在危机预警指标的选择上有两大类,分别是财务指标和非财务指标,但由于非财务指标的量化过于复杂,且代表性未知,因此仍然选择财务指标进行分析。在参考已有文献和独立研究的基础上,本文认为应从企业各个方面的能力来选择指标,最后决定选择表2财务指标中所整理的13 个财务指标(见表2)。

表2 财务指标
(二)对财务危机的预判别
财务危机预判别说的就是通过某些指标对其进行预判别,判定该企业现在处于什么预警状态,即健康、轻度危机和重度危机。在研读了众多国内外文献之后,本文将从两方面对财务危机的判别进行划分,一个是风险,另一个是收益。财务危机需要进行预判别的原因是,在神经网络中,对训练样本进行训练时需要让他们先学习,这样之后的检测样本才能进行预测,再将预测的结果与实际结果进行比对。
本文在对进行预判别时的标准有两个,分别是净利润和资产负债率,最后的判别标准有三个,即健康(a)、轻度危机(b)和重度危机(c)。具体划分依据为:当某公司净利润为负或资产负债率大于0.7时,判定该公司存在轻度财务危机;当公司的净利润为负且资产负债率大于0.7 时,判定该公司存在重度财务危机;当公司的净利润为正且资产负债率小于0.7 时,则判定该公司为健康。
(三)样本数据的处理
为了财务危机预警的准确性,我们选择增加指标数量。但在选取的13 个财务指标中,发现在公司的资产负债表中,各个指标之间的相关性很强,因此选择对指标进行主成分提取,以简化指标。
从表3KMO 与Bartlett 检验中可以看出Bartlett球形检验的Sig.取值是0.000,也就是说其间存在相关性,可以进行因子分析,且KMO 检验的结果是0.527,表明可以推动下一步的进行(见表3)。

表3 KMO 与Bartlett 检验
表4 主成分列表中列出了所有的13 个主成分,并且是按照特征值由大到小的次序进行排列,选取的主成分的累计贡献率超过70%,表示可以进行提取研究,所以本文选取了前4 个因子。
表5 特征向量矩阵是变量前4 个主成分的特征向量矩阵,各个变量均已在SPSS 中进行过标准化处理。根据表5,可以得出4 个主成分的表达式,例如F1 的表达公式为(1):
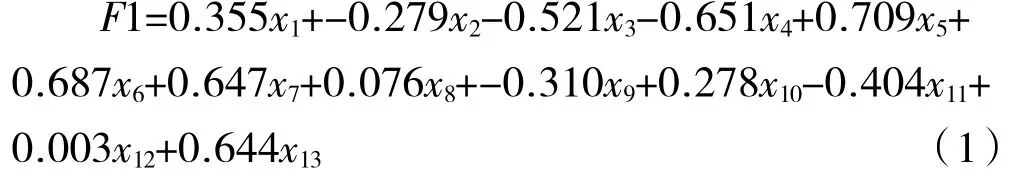
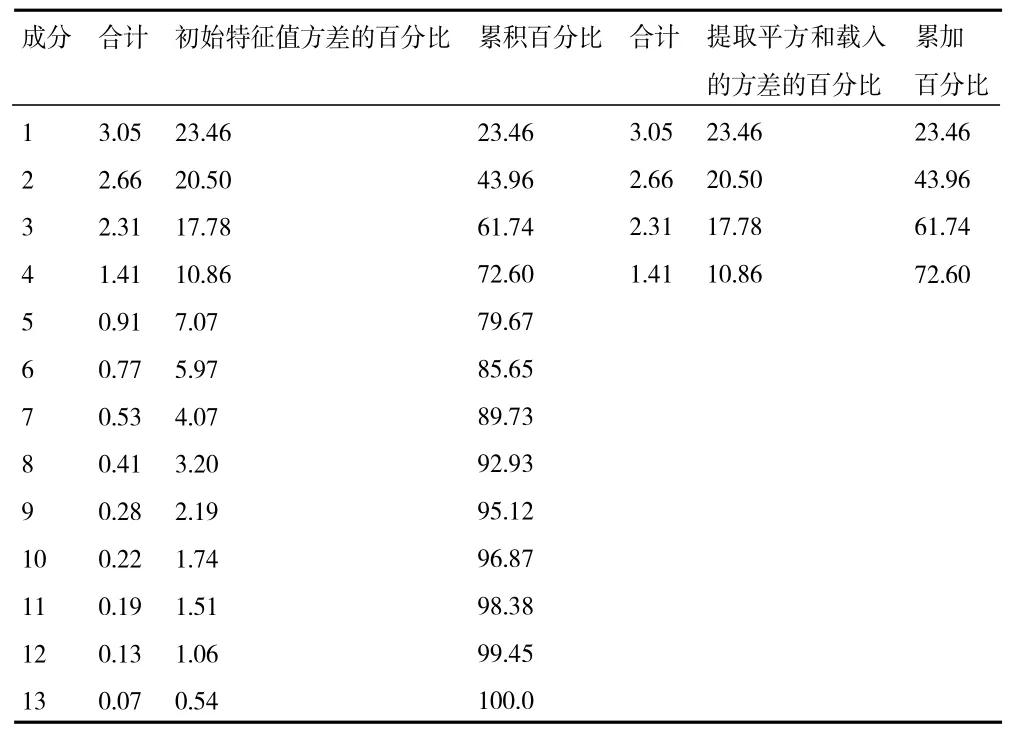
表4 主成分列表

表5 特征向量矩阵
四、实证分析
(一)BP 神经网络的设计
在SPSS 的主成分分析之后,13 个财务指标可以被4 个主要成分所取代,所以一共有4 个主成分进入模型中。BP 神经网络的设计需要确定的是各层的节点数以及隐藏层的个数。因此节点的数量设置为4,隐藏层和输出层节点的数量均为3。同时输出有三个目标值,取0 为两年后正常经营的公司的标记数,取1 为两年后发生重度财务危机的标记数,取-1 为轻度财务危机的标记数。当输出值越接近1,则企业是健康的企业可能性越大,越接近0 则越有可能发生重度财务危机,越接近-1 则越有可能发生轻度财务危机。
(二)BP 神经网络的训练及预测
1.训练的结果
在模型中,我们对发生财务危机的上市公司和未发生财务危机的上市公司运用R 语言软件一起进行训练,按7∶3的比例划分,将总样本分为训练样本和测试样本。先对51 家上市公司进行训练,然后再对23 家测试样本进行仿真。
通过R 语言的各种输入输出,得出神经网络模型的结果矩阵(见表6):

表6 神经网络模型的结果矩阵
通过R 语言得到的另一部分输出结果,神经网络模型的输出结果(见表7),从输出结果看,训练执行了1 870 步,终止条件为误差函数的绝对偏导数小于8.767813e-03(reached.Threshold),误差值为2.603 124,还有待调整(见表7)。

表7 神经网络模型的输出结果
2.BP 神经网络模型的可视化
图1 为神经网络模型的拓扑结构图,图中的粗线表示每一层与其相关权重直接的关系,而细线表示拟合过程中,每一步被添加到细线上的误差项,这些误差可以表示一个线性模型的误差区间。在本文中可以看到,该模型需要1 870 个步骤才能达到期望误差之下,且最后的总体方差为2.60(见图1)。
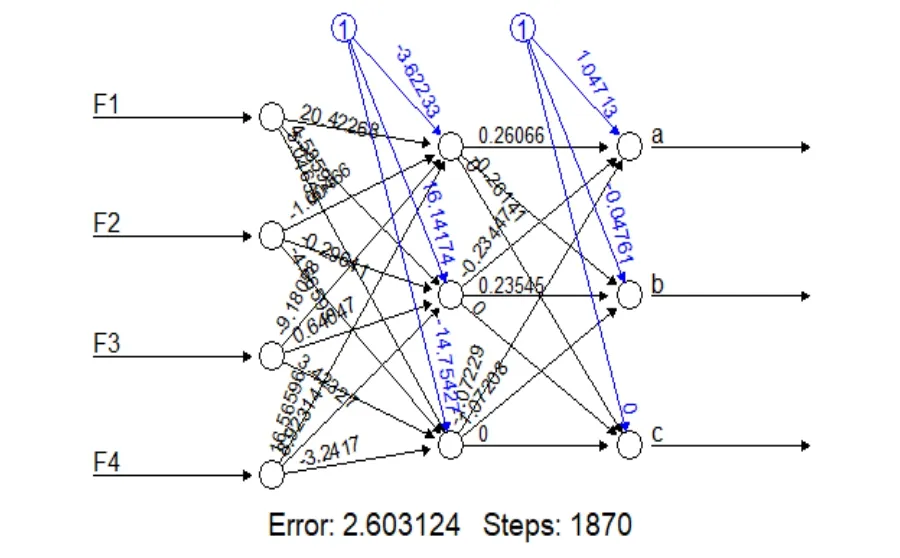
图1 神经网络模型的拓扑结构图
另外图2 泛化权值图分别展示了每个协变量F1、F2、F3 和F4 对分类的响应,图2 显示,所有泛化的权值都接近于0,即这个协变量对分类结果的影响并不大,并且本文总体方差大于1,则说明协变量对分类结果存在非线性影响。

图2 泛化权值图
3.模型的类标号预测(基于neuralnet 包)
由表8 可知,总共23 个测试样本中,将靠近a和b 以及b 和c 的样本归为轻度财务危机。一共有13 家企业是健康的,剩下的10 家中是有轻度财务的。结合上文中财务的预判别,经合计,样本数据危机程度中健康、轻度财务危机的个数占总样本的比例分别为73%和27%,检测样本中这三者占检测样本数的比例分别为65.3%、34.7%。从总数的比例来看各个状态的公司占比相差不大,但健康和轻度危机的公司都存在一些误判。

表8 神经网络的预测结果
经过对实际样本的观测,实际样本中健康状态的公司有15 家,轻度危机的公司有8 家,重度危机的公司有0 家,因此本文危机公司为轻度危机的公司。而根据表8,健康状态的公司预测正确的有13家,有两家健康公司被误判给了轻度危机公司。轻度危机的公司预测正确的有6 家,有两家公司被错误预测成了健康公司。因此预测样本有4 家与实际情况不符,健康公司预测准确率为86.67%,危机公司的准确率为75%。从整体来看,误判率只有近17%,即总体准确率达到了83%。因此该模型的预测还是较为准确的。
五、对比其他预警模型的分析
为了评价模型预测能力,本文另外选取随机森林算法模型对上市公司财务状况进行比较分析。随机森林算法是Breiman(2001)提出的一种组合分类算法。此算法基于训练数据的不同子集构建多棵决策树,每棵树的预测结果都视为一张投票,获得投票数最多的类别就是预测的类别,并组合成一个新的模型,预测结果是所有决策树输出的组合。
首先是对测试集进行判别,构建随机森林时,需要设定随机森林的两个参数:一是分类决策树数量,二是决策树节点的特征变量,模型过程的默认节点个数为2,决策树的数量为100。表9 训练集的分类效率是对训练集进行分类训练的结果,模型将训练集中的“轻度危机”误判为“健康”的错误率较高,对“健康”的判断则较为准确,达到82%。由于危机公司分类的准确率较低,这也将导致训练集中危机公司的误判率增加。

表9 训练集的分类效率
通过上一步的分类模型对测试集进行预测,根据表10 测试集的预测效果可以看出,预测结果显示健康公司的预测率准确率很高,只有一家误判成危机公司,而危机公司预测的准确率很低,有4 家危机公司误判为健康公司,误判率达到80%。整体上来看,总体预测准确率达到77.78%。

表10 随机森林测试集的预测结果
通过表11 的对比分析可知,针对本文所用样本数据,基于神经网络预警模型的总体准确率较高,但对风险公司的预测准确率却只有75%,选择随机森林算法模型时,对健康公司样本的准确率较高,达到了92.3%,但是此时对风险公司的预测准确率却只有20%,这是牺牲了对正类的准确率而换来的负类准确率的提升,这也再次验证了在随机森林训练样本中危机公司分类准确率不高会导致预测能力较低的说法;相较于随机森林算法模型,神经网络模型的总准确率、风险公司预测准确率、健康公司预测准确率都达到了一个相对的平衡水平,且都在72.23%的预测精度以上。

表11 两种模型的预警效果比较分析
六、结论及建议
本文在以往学者相关研究的基础上,利用神经网络模型对上市公司的财务状况进行了分析和检验。得出结论为:首先,从财务指标的主成分分析上来看,可以通过主成分提取的方式,计算得到综合得分来对公司财务进行判别分析,从四个主成分因子中可以发现流动资产、总资产周转率等得分较高;其次,本文基于t-3 期的数据进行分析,从模型预测准确度来看,基于BP 神经网络的财务危机预警模型在短期内的预警能力是较强的,总体准确率较高,达到82.6%,而随机森林算法的总体准确率只有72.23%;且划分出的两个判别指标(即净利润和资产负债率)可以在一定程度上帮助我们提前预知企业是否存在危机可能。
根据以上结论以及财务预警模型的最终目的,以下是关于对上市公司在合理规避以及消除财务风险上提出的一些建议:第一,根据各财务指标的得分情况,上市公司应该更关注公司营运能力以及偿债能力,具备足够的现金流。第二,上市公司发生风险,并不是风险因素才发生,而是已经出现的风险因素再次爆发。因此上市公司只有完善内部控制制度,有清晰明确的内部控制标准、规范,加强对财务部门的监督,才能正确反映企业财务风险,提高预警能力。同时,当前市场要健全信息披露惩罚机制,从法律上防范和打击违规信息披露,中国证监会应当加强执法力度,形成应有的震慑力。
