基于图像深度预测的景深视频分类算法
2021-06-03钱立辉王斌郑云飞章佳杰李马丁于冰
钱立辉,王斌*,郑云飞,章佳杰,李马丁,于冰
(1.清华大学 软件学院,北京 100084;2.北京快手科技有限公司,北京 100085)
如今,短视频由于较好地利用了娱乐生活中的碎片时间,受到了人们的追捧。其中,利用单反等相机拍摄的景深效果视频因其高清、美观,具有较好的艺术观赏性,广受大众喜爱。用户在视频分享平台上传、分享视频时,往往需要对景深视频类型进行筛选,以方便后续进一步操作,如视频推荐算法、视频超分辨率去噪等应用。同时,在海量数据时代,靠人力在平台后端服务器逐个鉴别、筛选是不现实的,因此,研究能自动检测视频数据库中景深视频的算法具有一定的现实意义和价值。
在视频分析、分类中,传统算法通常侧重于启发式特征设计,运行速度较快,但识别精度较低。深度学习技术能高效地学习视频中的时空域特征和高级视觉特征,目前,已有较多应用深度学习的算法,并获得了较传统算法更优秀的性能。然而,将深度学习算法直接用于景深视频检测尚存在一些问题,第1,已有的应用深度学习的景深视频算法[1-2]大多为分割算法(即逐像素分类算法),输出的分割结果图谱,不能直接应用于视频分类检测任务;第2,景深视频数据集较少,而过小的训练集易使网络发生过拟合。由于数据集的数据分布(如视频内容、风格)存在差异,当在某些数据集中训练的深度网络,在其他数据集中进行测试时,网络性能通常会降低。
此外,在景深视频中,帧图像通常具有很强的视觉语义深度信息,图像中各个物体随其与相机焦平面的距离远近出现的模糊差异具有一定的逻辑性。同时,在快手app 视频数据集中,存在大量由某些编辑特效形成的与场景景深无关的伪景深视频,即部分清晰、部分模糊,影响模型识别的性能。若在深度网络训练中,应用注意力机制,显式地使模型“注意”到与图像的场景深度相关的特征,则可在一定程度上提高景深视频分类的性能。
针对上述问题,本文提出基于图像深度预测的两阶段景深视频检测算法。第1 阶段为预测视频帧图像中各个语义物体的深度,即其与相机的相对距离,然后利用该深度信息,辅助第2 阶段构建景深分类网络,以提升网络模型的检测速率。第1 阶段使用的是DeepLens 图像深度预测网络模型[3],第2 阶段使用的是经过轻量化处理的改善后的ResNet18网络模型[4]。本文还设计了一种在新视频数据库中收集景深视频数据的迭代算法,能快速地获取新的同数据分布的景深视频数据集,所需的人力成本较低;同时,这些新搜集的数据集还可用于提升本文网络模型的性能。本文算法在快手线上的景深视频数据集中识别准确率达85.7%。
1 相关工作
相关工作主要包括视频质量评价(video quality assessment,VQA)算法和视频分割(像素级分类)算法。
在景深视频帧图像中,焦平面内(即景深内)被拍摄的物体是清晰的,焦平面外被拍摄的物体由于入射光线发生聚集和扩散,影像较模糊,形成一个圆形区域,通常称为弥散圆[5]。这类帧图像(包含模糊部分和清晰部分)与失真图像(模糊)部分类似,所以可以借鉴VQA 算法的思路,通过视频质量分数,判断其是否为景深类型视频。传统的VQA 算法有:峰值信噪比(peak signal-to-noise ratio,PSNR)[6]法、结构相似性指数法(structural similarity index method,SSIM)[7]和三维数据可视化matlab 工具ViS3d[8]等。目前基于深度学习的VQA 算法较为流行,其性能亦不断被优化,如文献[9-10]。但由于景深模糊和压缩失真模糊存在一定的视觉差异,前者往往为局部模糊,后者为整体模糊,因此,用此类算法筛选的景深视频错误率较高。
也有一些可直接预测景深视频像素的分割算法,如文献[11-12]手工设计了景深像素敏感的特征描述子,其中,文献[11]侧重于模糊边缘部分的特征提取,基于稀疏表示和图分解,建立稀疏边缘表示和失真估计之间的关系。文献[13]利用端到端的全卷积网络学习图像中的高级视觉语义特征,预测图像景深外模糊区域。考虑深层网络特征更抽象,该方案选用了较深的网络模型。然而很难将该方法直接应用于景深视频分类,首先,其仅预测了模糊分割结果,与视频是否有景深效果不相关(有可能为伪景深视频),需要做进一步后处理,如利用分割结果图谱或中间特征图谱预测视频类型。其次,分割算法需要人工进行精细标注,其收集成本远高于分类任务所需的标注数据。文献[1]通过训练与U-Net[14]类似的深度网络,检测图像中的景深外模糊和运动模糊。文献[2]针对模糊的好坏提出了分类预测的统一框架(如景深效果中的模糊是好的,压缩模糊是坏的)。此类算法属于分割算法,预测了景深外侧模糊像素,经改善,可将其应用于景深视频分类筛选。但此类算法均未考虑景深视频帧图像中各语义物体的深度差异。
2 基于深度预测的视频分类算法
本文在文献[1-2]算法的基础上,将帧图像分割结果转变为视频类型预测,但在后处理过程中会导致精度降低。考虑景深视频帧图像中各语义物体与相机的相对距离存在一定的逻辑关系,本文利用注意力机制,提出了一种基于图像深度预测的新的两阶段景深视频分类算法,该算法的网络模型如图1 所示。此外,提出了可大幅降低人力成本的迭代式景深视频数据集收集算法。
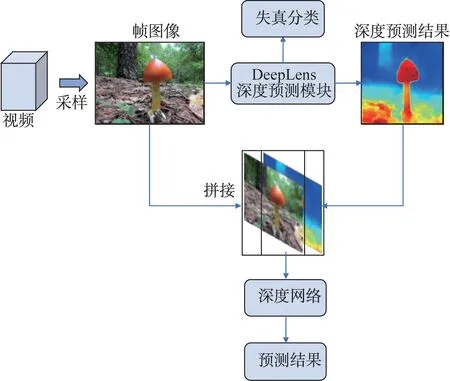
图1 整体网络模型Fig.1 Overview network model
2.1 两阶段景深视频分类网络
2.1.1 帧图像深度与景深类型的逻辑关系
在景深视频帧图像中,各语义物体与相机的相对距离不同,在景深范围内的物体成像较为清晰,而在景深范围外的物体成像较为模糊。这意味着,在景深类型的视频帧图像中,包含较为明显的深度特征信息,如图2 所示。图2 中,红框为景深范围内物体的成像,蓝框为景深范围外物体的成像。可见,两个框中的物体具有明显的距离差,红框中的物体与相机的距离更近。

图2 景深类型图像样例Fig.2 Depth-of-field image samples
根据相机成像原理[5],不同物距的物体成像后清晰度不同。因此,在景深视频帧图像中,清晰部分对应的物距是类似的。这为深度网络预测帧图像景深类型提供了新思路,即在深度网络预测帧图像类型时,如果事先得到该图像的景深信息,并将其作为显式特征指导后续预测算法,那么可进一步降低误检率。通过显式的图像景深信息,新网络能判定的逻辑关系更丰富,见表1。
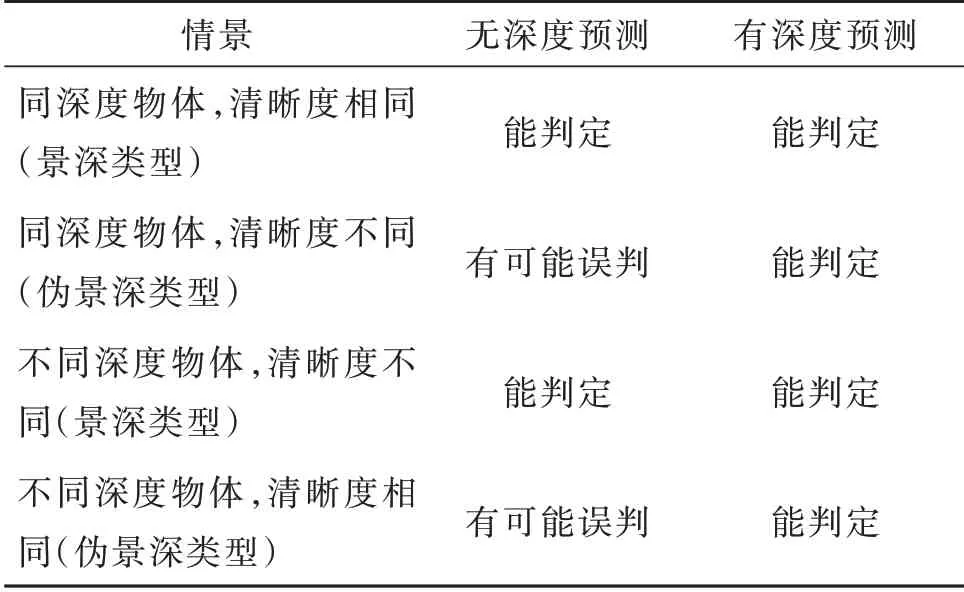
表1 判定逻辑比较Table 1 Decision logic comparison
例如,在图2(a)中,叶尖(红框部分)与叶根(蓝框部分)具有不同的物距深度,如果均为高清像素,则可判定其为非景深视频帧;而以往的深度网络如果仅学习到了中间部分为高清,边缘部分为模糊,就会判定其为景深视频帧,则出现了误判。
2.1.2 帧图像深度预测网络
帧图像的深度预测模块选用的是DeepLens 网络模型中的深度预测模块。输入某图像后,该模块将输出对应的深度预测热力图,部分结果如图3 所示,其中,左侧为输入的图像,右侧为对应的深度预测结果热力图,偏红的区域表示深度较小,偏蓝的区域表示深度较大。

图3 深度预测网络结果示意Fig.3 Depth prediction results
分割任务中的深度网络模块包含编码器和解码器两部分,编码器采用预训练的ResNet 50 架构[4],解码器则由一系列上采样模块构成,同时包含来自编码器的跳跃连接。与跳跃连接对应的2 个层分辨率相同,分别用于减少在网络正向计算时下采样操作中的特征损失和防止网络梯度传播中出现梯度消失现象。该模块采用多任务训练方式,同时训练网络预测深度估计和前景分割数据集,以提升网络的泛化能力。
考虑景深检测任务和失真问题的相似性,本文借鉴多任务联合训练的方法,在将该模块用于景深深度提取的同时,预测图像是否失真(独立于景深类型的一个人工标签),即增加一个分类损失,从而进一步增加多任务训练的多样性,提升性能。其损失函数为

其中,Loss 表示该模块的总损失;Lossdeep表示深度预测的损失[3],λ表示协调损失权重的参数,y1表示样本是否为失真类型的标签,Y1表示网络该分支的输出。因此,此处深度预测模块有2 个输出:深度预测结果热力图和图像失真情况分类。
2.1.3 视频景深类型预测网络
通过帧图像深度预测模块得到帧图像深度信息,并将其用于执行景深分类任务,以提高预测网络性能。这里并不需要为景深设计特定的特征描述子,只需将其作为指导性特征,输入景深分类网络。
本文将原帧图像和预测的深度预测结果热力图按通道合并作为输入。由于深度预测模块输出的维度与图像输入的维度不同,如果对输入帧图像做缩放处理,易导致变形,使图像语义发生变化,混淆网络提取特征,为此,首先,将输入图像以其短边为基准,裁剪成长、宽相等,再缩放至224×224×3 的特定尺寸。随后将深度预测结果的尺寸也缩放为224×224×3,按照通道维度合并拼接,得到新的输入图像,维度为224×224×6。考虑在景深类型分类任务中需要一定的高级语义特征,但较深的网络运行速率低,本文选择ResNet 18 架构[4],对其做一定修改后作为本文的深度网络,结构见表2。表2中,Bottleneck 代表残差模块,重复次数表示相同残差模块的连接个数。该深度网络相对于ResNet 18结构的主要不同在于输入、输出的维度和中间各残差模块的重复次数。在实际应用中,网络消耗越深,计算资源越多,而预测性能的提升却有限,因此,做了折中处理。
该模块的损失函数为预测的景深分类结果和真实标注之间的交叉熵,记为
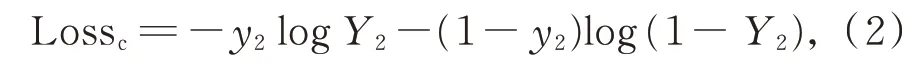
其中,Lossc表示景深分类预测损失,y2为样本是否为景深类型的标签,Y2表示网络的输出。
2.2 迭代式景深视频数据集收集算法
通常,公开的景深数据集很少,大多为图像类数据集,且规模较小,与实际应用中的待测试数据分布差异较大。如数据集CUHK[1]几乎全为风景类,而在快手线上,人物影像类视频居多。然而,由于景深视频在线上出现的概率较低,如果直接用人工筛选打标则费时费力,因此需要一种可以在新的数据集上低成本地收集打标所需数据的方法。为此,提出迭代式景深视频数据集收集算法,流程如图4 所示。
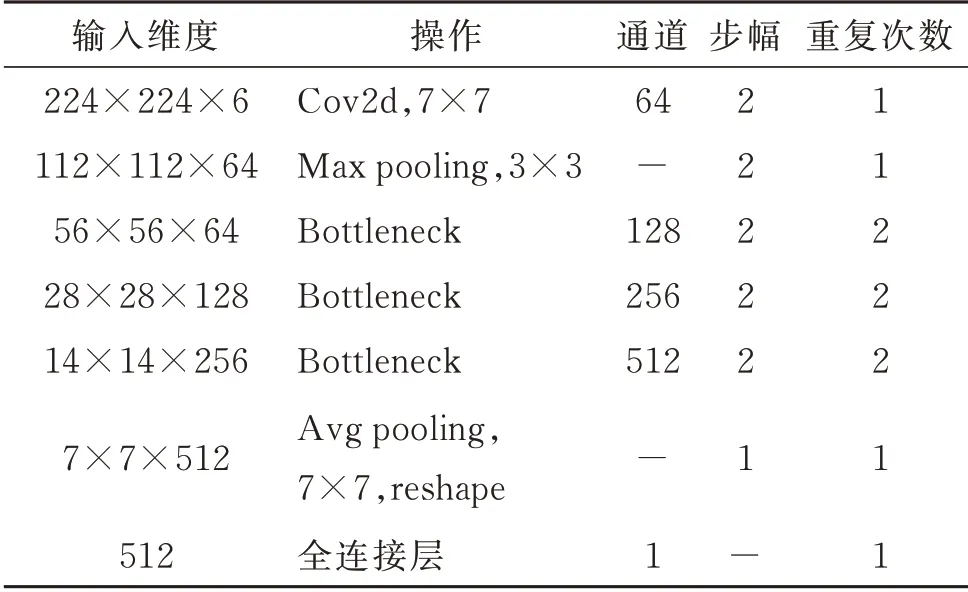
表2 深度网络结构Table 2 Depth network structure

图4 迭代式景深视频数据集收集流程Fig.4 Iterative depth-of-field video collection
记随机初始化的模型参数为M0。首先,将模型在其他数据分布的公开数据集S0中训练,使用Early Stopping[15]的思想训练若干代数,得到模型参数M1。随后在快手线上随机筛选K个数据视频集S1作为测试集,这时将模型M1对S1中预测判定为“景深”的视频数据,即其子集Z1做人工筛选。相较于直接在S1中做人工筛选,Z1中出现景深视频的概率p更大(p等于模型对于S1预测的正确率),从而降低了人力成本。随后将新搜索得到的有标数据(包括景深视频和非景深视频)加入S0中,重新训练网络模型,得到M2,继续以同样方法,在新的一批线上视频S2中做预测、搜索和打标,依次迭代,直至网络性能无明显提升或不再提升。通过该算法迭代实际完成了2 个任务:(1)通过增加训练数据和改善训练数据分布,进一步提升了深度网络的性能;(2)以较低成本得到了大量景深视频数据,用于进一步研究。
3 实验及数据分析
实验比较的数据集包括在快手线上收集的景深视频数据集和文献[1]中的景深图像数据集CUHK,其中,快手线上收集的景深视频共350 个,包含171 个景深类型视频和179 个普通视频。在景深视频类型中,对光圈大小和焦深不作要求,唯一标准是景深;而普通视频类,包括模糊视频和清晰非景深视频两类。
3.1 参数选择和训练细节
模型训练的批大小(batch size)设置为32,网络模型使用Adam[16]优化器训练,初始的学习率设置为0.001,后续每50 个epoch 学习率降为之前的0.1倍。大量实验表明,宜将式(1)中的λ设置为0.9。在快手线上的视频数据集中,用140 个景深视频和140 个非景深视频作为训练集,余下数据用于测试。训练中,首先对视频做采样帧处理,对于输入的视频,每间隔10 帧采样一帧,以降低计算量。测试时,将所有采样帧输入网络,并将所有结果的均值作为网络对视频的分类预测。而CUHK 图像数据集则无须该处理。网络为回归输出,即为(0,1)内的分数,值越大表示为景深视频的概率越高,以T=0.4作为阈值。在迭代式数据集收集训练中,迭代次数设为4,每次迭代收集的数据集大小为K=1 000。
首先,需加载DeepLens 模块预训练的参数,以提高初始参数分布的有效性,同时,快手线上景深视频数据不包含分割网络所需要的标注,无法计算该模块的损失函数,模型仅在首次训练时以学习率0.000 1 微调DeepLens 模块,在后续的迭式训练中冻结DeepLens 模块中的参数,只训练分类网络模块。
3.2 快手线上数据的测试对比实验
由于文献[1]和文献[2]均为分割算法预测像素分类,无法直接预测视频类型。为公平比较,本文先对预测结果做进一步处理,然后再进行预测视频分类。对于文献[1],由于其预测图像中每个像素模糊的种类(未失真、运动模糊、景深外模糊)不同,因此将其预测结果中景深范围外模糊占比高于20%或没有运动模糊只有景深范围外模糊的帧图像判定为景深视频帧;对于文献[2],将预测结果为“好模糊”的帧图像判定为景深帧。此外,考虑快手线上数据无分割标签,无法用于训练文献[1]和文献[2],因此仅在CUHK 数据集中做了比较。所有实验均重复20 次,取均值作为最终结果,见表3。

表3 快手线上景深视频数据实验结果Table 3 Experimental results of Kuaishou depth of field video
表3 中,本文算法表示与其他方案一致的训练数据集(即训练中没有加入快手数据集),本文算法+表示迭代式地利用快手视频数据训练网络。由表3可知,本文算法在准确率和召回率上均较文献[1]方法和文献[2]方法好。其中,文献[1]方法表现较差的主要原因是其只做了分割任务的训练学习,不适用于直接视频分类任务。同时,在训练集中加入快手线上数据后,可看到本文算法的性能得到了进一步提升,这也证实了迭代式景深数据集收集算法的作用。
3.3 深度预测特征的有效性
为验证深度预测模块的有效性,进行消融对照实验,即删去DeepLens 深度预测模块,在网络模型中只输入224×224×3 的原始帧裁剪图像,结果如表4 所示。进一步,在文献[1]方法中,尝试将深度预测的结果,如本文方案中的按通道合并,加入输入中,即只改变网络的输入和第1 层的输入维度,并在同样的景深像素分割任务中进行训练测试,观察其分割性能指标的变化,结果如表4 所示。
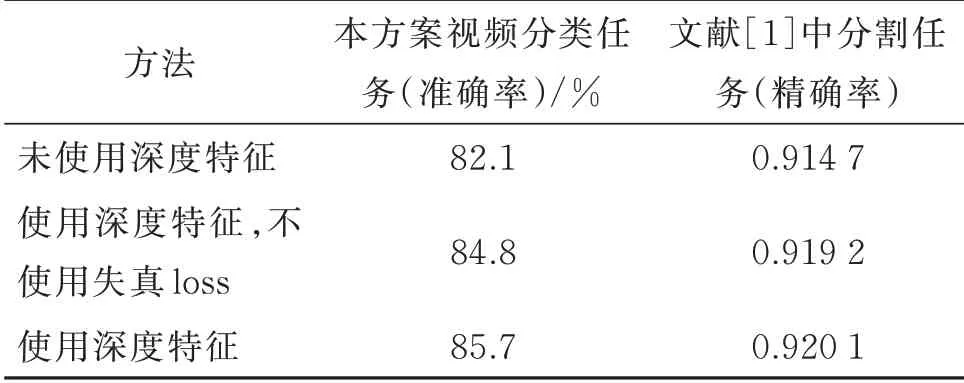
表4 深度预测特征有效性实验结果Table 4 Experimental results of the validity of depth features
由表4 可知,在与景深强相关的任务中,加入景深深度信息可有效增加模型特征的感知能力,从而提高模型的性能。
3.4 深度预测特征的有效性
为验证迭代式景深收集算法的性能,收集了不同迭代次数的算法性能,如表5 所示。随着迭代次数的增加,算法的性能得到逐步提升,迭代之初提升较快,之后提升变慢。多次迭代后,算法训练的数据集瓶颈得到消除。

表5 迭代式景深视频收集算法性能变化Table 5 Performance versus number of iterations in the iterative depth-of-field video collection algorithm
同时,按照本文算法在较短时间(2 h,只统计人工筛选的时间)内在快手线上收集到了105 个景深视频。
3.5 可视化结果比较
表6 可视化地展示了迭代式景深视频收集算法带来的性能提升(分数越高,为景深视频的概率越大)。表6 中,第1 和第3 行为景深视频截图,2 个方案都预测准确。第2 行为伪景深视频帧,脸部同时存在清晰、模糊,未使用深度特征的算法发生了误判。第4 行也为伪景深视频帧,场景有较强层次感,但远、近处清晰度相似。

表6 本文算法预测分数可视化比较Table 6 Visualization of prediction score
可见,本文算法可较好地识别景深深度逻辑存在问题的伪景深视频帧。
4 结论
研究了景深视频分类算法的线上应用问题和深度学习分类应用的几个问题。针对景深视频分类任务,由景深成像原理,在景深视频帧图像中,根据景深预测结果,可解决预测逻辑问题,从而降低误检率。针对线上数据集较少的问题,设计了迭代式景深视频数据集收集算法,以较低的劳动成本实现快速收集所需数据,具有一定的应用价值。
