基于鲁棒回归度量学习的图像分类算法
2021-06-03常冬霞王舒伟
常冬霞,王舒伟
(北京交通大学 计算机与信息技术学院,北京 100044)
图像分类是计算机视觉领域的基本问题之一,也是对图像进行检测、分割、分析等高层视觉任务的基础. 如何衡量图像的相似性则是对其分类的关键问题,而度量学习[1]的核心就是研究相似性度量,
通过寻找一个线性或非线性变换,使得同类样本间距离尽可能小,异类样本间距离尽可能大.
针对度量学习众多的学者已经展开了深入的研究,而基于Mahalanobi距离的度量方法则是度量学习的典型算法之一.这些算法根据是否使用数据集的先验信息可以分为有监督[2-3]与无监督[4-5]的学习方法.传统的有监督距离度量根据数据样本的先验信息构造成对约束信息[6]或者三元组相对约束[7],然后利用约束信息以及正则化项来构建度量学习的优化模型.经典的度量学习模型通过直接优化马氏距离函数中的半正定矩阵M得到一个新的距离函数来描述样本间的距离,从而在新的距离空间中更有效的判断样本的类别.
近年来,很多学者从线性度量学习[8-9]的角度展开研究,将M分解为M=PPT,通过学习投影矩阵P来保证M的半正定约束,即通过一个线性变换将原始数据映射到一个新的特征子空间进行度量学习.其中基于线性回归模型[10-15]的子空间学习方法是一种常用的度量学习算法.为了使得不同类样本间的距离尽可能大,许多研究者提出在松弛的标签矩阵上进行回归[10-11].文献[10]通过ɛ-draggings技术扩大不同类别回归样本间的绝对距离;为了直接从数据中学习回归目标获得更灵活的标签矩阵.文献[11]引入一个边距约束即强制正确类别与错误类别目标间的相对距离大于1.然而,这些算法注重将数据样本拟合到相应的标签上拉大类间距离而忽略了样本之间的关系,进而会破坏数据的底层结构,导致过度拟合问题.为了利用样本间的相关性,文献[12]提出了低秩线性回归(Low Rank Linear Regression, LRLR)模型,通过对变换矩阵增加低秩约束挖掘样本之间的相关性.而文献[13]则将图正则化项引入线性回归模型,使转化后的类内样本紧密地聚集在一起,进而改善过拟合问题.但以上回归模型的性能会受到数据类别数的限制,为保证学到足够的投影来构造一个更具分辨力的子空间,文献[14-15]采用两个相乘矩阵替代回归系数矩阵的方法获得更多的投影,从而进行更加有效的特征选择或分类.然而这些方法大多没有考虑数据的局部结构,并且在实际应用中,原始数据通常具有很高的维数,包含大量的噪声和冗余特征,这大大增加了直接从原始数据中揭示内在关系的难度.此外很多度量学习算法在数据存在大量噪声或具有较大的变化时,性能往往会恶化.
本文作者结合稀疏表示理论提出了一种基于鲁棒回归的度量学习方法(Robust Regression Metric Learning,RRML),该方法将稀疏表示、特征子空间学习和分类模型联合优化,通过融合标签判别信息和稀疏近邻相关性重构信息来学习度量子空间.在子空间学习中引入稀疏表示,可以自适应的学习数据间的邻域结构,进而保持样本在投影空间的内在结构;并且该方法并不直接从原始高维数据中学习稀疏表示,而是从更具判别性的低维表征空间中学习更鲁棒的图,使得挖掘出的投影矩阵具有更好的性能.此外,考虑到核范数对噪声良好的鲁棒性,选用核范数度量回归损失来提高算法对噪声的鲁棒性.实验结果表明,本文算法取得更高的分类准确率.
1 鲁棒回归度量学习
1.1 StLR和RJSR模型
假设给定训练样本矩阵X=[x1,x2,…,xN]T∈RN×d,其中N为训练样本个数,d为样本维度.标准的线性回归分类模型(Standard Linear Regression, StLR)是通过学习一个投影矩阵将原始训练样本转换到二元标签空间进行分类,其优化目标函数为
(1)
式中Y=[y1,y2,…,yN]T∈RN×c为二元标签矩阵,c为类别数,Y的定义为:训练样本xi(i=1,2,…,N),yi∈Rc为对应的标签向量;若xi属于第k类(k=1,2,…,c),则yi的第k个元素为1,其余的元素等于0.W∈Rd×c为变换矩阵,‖·‖F为矩阵的F范数.但是StLR模型及后续很多改进模型都受类别数的限制,并且对异常值比较敏感.为了解决上述两个问题,文献[14]提出了一种联合稀疏回归的鲁棒特征选择方法(Robust Jointly Sparse Regression, RJSR),其目标函数为
(2)
s.t.ATA=I
RJSR模型通过增加投影矩阵B来突破StLR模型受小类别数的限制,并且通过对正则项使用L2,1范数约束来学习用于特征提取和选择的联合稀疏投影,进而增强了RJSR模型对异常值和噪声的鲁棒性.然而,这些方法大多没有考虑数据的局部结构,则当数据投影到低维空间中不能较好的保持原始局部几何结构和特征间的相似性.并且当数据集存在异常值或受光照变化影响时,很多回归方法使用平方残差度量回归损失,导致性能对噪声或数据的变化比较敏感[16].因此,本文提出了一种新的鲁棒回归度量学习算法(RRML),将稀疏表示引入线性回归模型,通过联合优化低维特征子空间、稀疏表示与分类模型参数,将原始数据样本映射到新的特征子空间中以便实现更好的分类效果.
1.2 RRML算法的目标函数
为了提高新的度量空间的分类性能及噪声条件下算法的鲁棒性,本文将稀疏表示引入子空间学习,通过稀疏约束使得数据样本尽可能通过其特征空间中的临近样本稀疏重建,以保留数据的局部几何结构,并且由于原始特征往往具有较高的维度,包含大量的噪声和冗余,直接从原始特征空间很难获得数据的内在结构,因此本算法将数据投影到更具判别性的低维表征空间,在低维空间中联合学习稀疏表示矩阵.考虑到对于光照变化等引起的噪声,核范数比L1范数或L2范数更适合用于表征重构误差,采用核范数度量回归损失.综上,RRML目标函数为
α‖Z‖1+β‖P‖2,1+λ‖E‖2,1
(3)
ATA=I
式中:‖·‖*表示矩阵的核范数;P∈Rd×m是子空间投影矩阵;A∈Rc×m是正交回归系数矩阵;Z∈RN×N是稀疏表示矩阵,矩阵Z可以有效地编码数据的局部结构信息;同时采用L2,1范数约束子空间映射矩阵P和噪声矩阵E,进而获得具有对异常值的鲁棒性和联合稀疏性的特征转换矩阵;并且通过拟合二元标签矩阵Y引入有区分性的监督信息.此外,为了解决数学不适定问题,提高求解过程的数值稳定性增加了对A的正交约束.
1.3 模型优化求解
为了求解式(3),首先将其转化为
β‖P‖2,1+λ‖E‖2,1
D=Y-(PTXZ)TAT
(4)
ATA=I
在数据规模太大时,每次迭代中若都采用奇异值分解(Singular Value Decomposition,SVD)来处理式(3)中的核范数则会使得计算量很大.为了改善这个问题,参考文献[17]将核范数转化为固定秩分解问题:D=UN×rVr×c其中r为类别数,有监督学习情况下,可以将其设置为D的秩.因此,式(4)可以转化为
α‖J‖1+β‖W‖2,1+λ‖E‖2,1
D=Y-(PTXZ)TAT
(5)
ATA=I
其增广拉格朗日函数为
β‖W‖2,1+λ‖E‖2,1+
(6)
式中:μ>0为惩罚参数;Y1,Y2,Y3,Y4,Y5是拉格朗日乘子;
首先,固定其他变量求D,则式(6)可以等价为
L(D)=
(7)
将上式对D求偏导并令其为0,可得
(8)

固定其他变量求解J,则式(6)可等价为
(9)
极小化上式可通过收缩算子求解
(10)
式中:shinkα/μ=sign(t)max(|t|-α/μ,0).
当其他变量固定时求Z,由式(6)得
L(Z)=
(11)
将上式对Z求偏导并令其为0,可得
Z=(2XTPPTX+I)-1(XTPATQ+
(12)
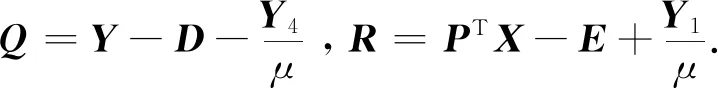
当其他变量固定时求E,由式(6)得
L(E)=
(13)
其中E的第i列为
(14)
当其他变量固定时求W,其求解方法同J:
(15)
当其他变量固定时求P,由式(6)得
L(P)=
(16)
将上式对P求偏导数并令其为0,可得
P=[XZZTXT+
(X-XZ)(X-XZ)T+I]-1×
(17)
当其他变量固定时求U,由式(6)得
(18)
求上式对U求偏导并令其为0
(19)
当其他变量固定时求V,由式(6)得
(20)
上式对V求偏导并令其为0,可得
(21)
最后,当其他变量固定时求A,由式(6)得
APTXZQ-QTZTXTPAT-QTQ)
(22)
s.t.ATA=I
因为Tr(APTXZZTXTPAT)=Tr(PTXZZT×XTPATA),所以式(22)可以写为
2QTZTXTPAT-QTQ)
(23)
s.t.ATA=I
则式(22)的求解可以转化为等效优化问题
s.t.ATA=I
(24)
根据文献[15]中的定理1得:QTZTXTP的SVD分解为UDVT,则A=UVT.
为了方便,将所提RRML算法总结如下.
输入: 训练数据X∈Rd×N与其对应的标签矩阵Y∈RN×c,参数α、β和λ.
输出: 判别性子空间映射矩阵:P∈Rd×m
初始化:D=E=Y1=Y2=Y3=Y4=Y5=0,μmax=1010,ρ=1.3,σ=10-4
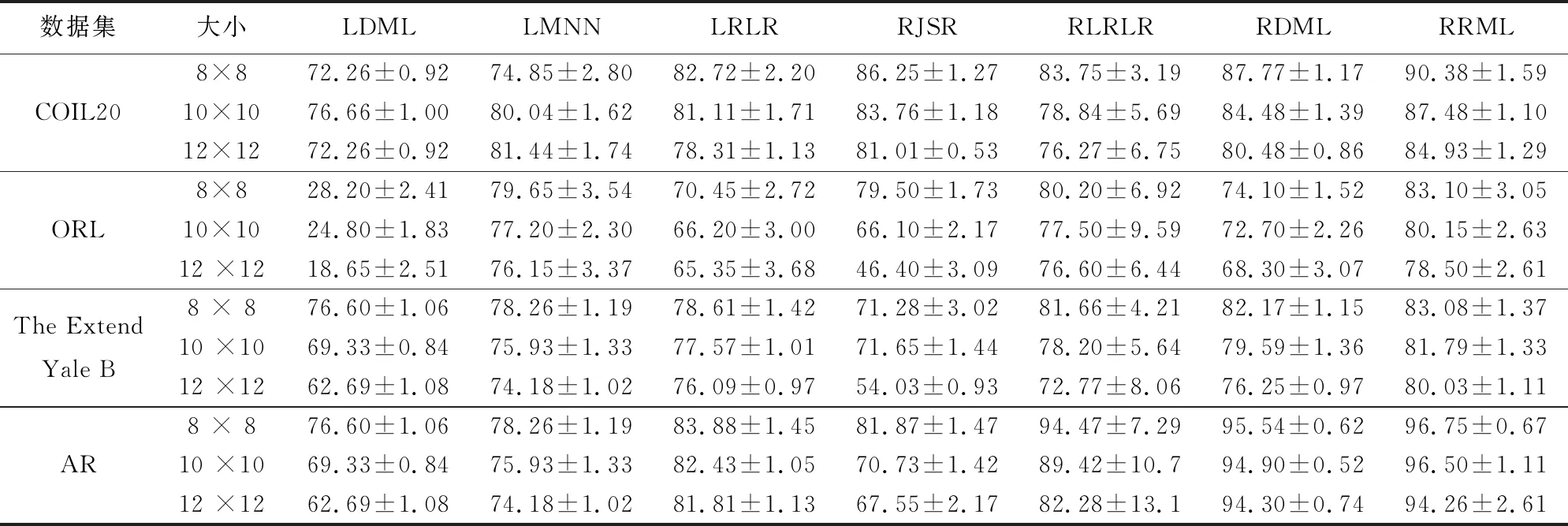
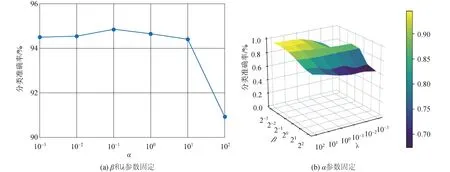
While not converged or t 通过式(7)更新D 通过式(8)更新J 通过式(9)更新Z 通过式(10)更新E 通过式(11)更新W 通过式(12)更新P 通过式(13)更新U 通过式(14)更新V 通过式(17)更新A 更新拉格朗日乘子Y1,Y2,Y3,Y4,Y5: Y1=Y1+μ(PTX-PTXZ-E) Y2=Y2+μ(D-UV) Y3=Y3+μ(Z-J) Y4=Y4+μ[D-Y+(PTXZ)TAT] Y5=Y5+μ(P-W) 更新参数μ:μ=min(ρμ,μmax) 收敛条件判断: ‖PTX-PTXZ-E‖∞<σ,‖D-UV‖∞<σ,‖Z-J‖∞<σ ‖D-Y+(PTXZ)TAT‖∞<σ,‖P-W‖∞<σ t=t+1 end while 为了验证所提算法的有效性,采用4个图像数据集对所提RRML算法与LDML[6]、LMNN[7]、LRLR[12]、RLRLR[13]、RJSR[14]和RDML[17]算法的性能进行比较.实验结果表明所提RRML算法具有更高的分类准确率和更好的鲁棒性.表1给出了实验中采用的4个图像数据集的具体参数,其中使用的图像均被调整为32×32. 表1 数据集描述Tab.1 Descriptions of databases 在进行分类性能对比实验中,从每类中选取相同样本数构造训练集,每个实验独立重复10次,将平均分类准确率和标准差进行比较.在COIL20目标数据集上,随机选取每类N(N=10,15,20)个样本作为训练集,其余样本作为测试集进行实验.在ORL人脸数据集中,随机从每类选取N(N=4,5,6)个样本作为训练集.从the Extend Yale B数据集中随机选取每类的N(N=10,20,30)幅图像进行训练.另外,在原始AR人脸数据集中选取了120人1 680幅图像的子集对不同的分类方法进行评价,同样随机抽取每类的N(N=5,6,7)幅图像进行训练,其余的图像用于测试. 表2给出不同数据集的分类结果.由表2可见所提RRML算法具有更好的分类性能.首先,与经典度量学习方法LDML、LMNN和RDML相比,所提RRML算法能够得到较高的分类准确率.这是因为使用相应的二元标签矩阵作为监督信息,能够获得具有较强判别性的特征,从而提高了算法的分类性能.其次,与同样基于线性回归模型的LRLR、RJSR和RLRLR算法相比,RRML算法也获得了更高的分类准确率,表明本文学习得到转换矩阵将数据变换到新的度量空间,该度量空间具有更高的判别性. 表2 不同训练样本数下算法的平均分类准确率和方差Tab.2 Classification accuracy (mean ±std %) of different methods under different training samples of each subject 2.2.1 算法收敛性 采用COIL20和ORL数据集对算法的收敛性进行分析。实验中从每类中分别选择10个和5个训练样本组成训练集,算法收敛曲线如图1所示.由图1可见,随着迭代步数的增加目标函数收敛于一个稳定值,进而该模型获得一个局部最优解. 图1 COIL20和ORL数据集上的收敛曲线Fig.1 Convergence curves of COIL20 and ORL dataset 2.2.2 运行时间分析 实验中,均采用同样的1-NN分类器对测试数据集验证分类效果,所以本节仅分别给出了每个算法的训练时间,来实现公平的对比.从表3可以看出,在绝大多数情况下,RRML的运行时间要小于除LRLR外的其他对比算法,这表明,本文通过引入固定秩矩阵分解来加速奇异值分解的策略,可以较大程度减小计算量从而降低运行时间. 尽管 LRLR 的运行时间最短,但是 LRLR算法的分类准确率较低,且远低于本文所提算法. 表3 不同算法在不同数据集上的运行时间Tab.3 Running time of different algorithms on different datasets s 为了评估RRML算法对噪声的鲁棒性,在图像受损情况下对算法的分类性能进行了对比.实验中给图像加上大小分别为8×8, 10×10和12×12的损坏块.图2分别给出了一些图像示例.在COIL20和the Extended Yale B数据集上,每类随机抽取10幅图像作为训练集,其余图像用于测试.同样,在ORL和AR数据集每类中随机选取5幅图像作为训练集.实验结果如表4所示,除了AR数据集12×12损坏块外,RRML方法均获得最高的分类准确率,这表明所提出的模型在噪声干扰下具有更好的鲁棒性. 表4 不同大小损坏块下算法的平均分类准确率和方差Tab.4 Classification accuracy and variance of different methods with occluded images 图2 不同数据集不同大小的遮挡图像Fig.2 Occluded images with different sizes block occlusions of different databases 为了分析3个主要参数α,β和λ对模型的影响,参照文献[18]中的策略使用这些参数的不同组合进行实验寻找不同数据集对应的最佳参数.图3给出了以ORL作为测试集,模型中3个参数与分类准确率的关系,其中每类选取5个训练样本.首先固定β和λ,由图3(a)可以看出,α在[10-3,10-1]范围内分类准确率较稳定,所以在[10-3,10-1]内确定α,并定义β的候选范围{2-3,2-2,2-1,20,21,22},λ的候选范围{10-3,10-2,10-1,100,101,102}.然后通过不同的组合实验得到β和λ的最佳组合.最后用得到的最佳值固定这两个参数,并用相似的方法再从α的候选范围中寻找最优值.通过上述步骤可以从α,β和λ的候选参数构成的三维空间中找到这3个参数的最佳组合.从图3(b)可以看出,与α相比,分类性能对β和λ的变化更为敏感.最终将这组参数代入原模型在对应数据集上进行10次实验,并给出平均分类精度与方差以供比较. 图3 ORL数据集中识别率与不同参数组合的关系Fig.3 Relationships of the classification accuracy and different combination of parameters on ORL database 1)提出了一种鲁棒回归度量学习(RRML)方法并将其应用于图像分类,该算法融合了投影矩阵的紧凑性、回归目标的判别性以及对数据误差的鲁棒性的三重特性,将稀疏表示、特征子空间学习和分类模型集成到一个统一的框架中进行优化. 2)RRML算法首先联合稀疏表示搜索最优的度量子空间,通过对表示矩阵施加稀疏约束自适应地提取样本间的局部信息,并且重构系数矩阵的稀疏约束可以去除冗余及噪声的影响,同时对噪声矩阵E施加行稀疏约束,使得挖掘出的数据转换更好地揭示数据局部结构和去除噪声. 3)选用核范数度量回归损失来提高噪声条件下的度量稳定性.最终得到一个具有紧凑性、鲁棒性和判别性的特征子空间。实验结果表明,本算法在多分类任务上具有优良的性能.2 实验结果与分析

2.1 图像分类结果分析

2.2 算法收敛性及运行时间分析


2.3 鲁棒性对比分析

2.4 参数选择与分析
3 结论
