基于交互式机器翻译环境的语境架构
2021-05-27王鹏


〔摘要〕自设计之初,机器翻译面临的一个主要挑战就是对语境中意义的把握。目前采用的交互式机器翻译引擎,试图尽可能地使机器吸收人类的智慧与认知能力,并取得了一定的成果。文章由交互式机器翻译的技术环境入手,根据译者处理语境时付出的认知努力,提出包括本地语境、全局语境、语境效果在内的基于交互式机器翻译环境的语境架构。该等级框架从译者认知的角度出发,能够有效地收集、管理、分析译者反馈的数据,评估翻译系统对译者的依赖程度,从而更有效地在引擎自动切分、人机互动翻译等方面融合语境因素,以不断提高交互式机器翻译引擎的水平。
〔关键词〕交互式机器翻译环境; 神经机器翻译; 语境架构
〔中图分类号〕H085〔文献标识码〕A〔文章编号〕1008-2689(2021)02-0138-09
任何學科的颠覆性变革往往源自外部的力量,翻译亦是如此。机器翻译(machine translation)作为人类早期的人工智能(artificial intelligence)项目,最早得益于20世纪40年代美国数学家 Warren Weaver 等人的大力推进。1947年,Warren Weaver写信给麻省理工学院的语言学与计算机领域的专家Norbert Wiener,讨论自动化翻译(automated translation)的可能性,他写道:
有人会很自然地联想到翻译问题是否可以被视为密码学的问题。当我看到一篇用俄语写的文章时,我的反应就是:“这实际是用英语写的,但是它却用了奇怪的符号来编码,而我现在就要为它解码。”
One naturally wonders if the problem of translation could conceivably be treated as a problem in cryptography When I look at an article in Russian, I say: “This is really written in English, but it has been coded in some strange symbols I will now proceed to decode”[1]
从这段话可以看出,Weaver 将翻译视为编码与解码的过程,似乎有一本神奇的密码本,可以将不同的编码互相转变。在一定程度上,采用机器翻译的人工智能系统的目的就是从语言转换中最大限度地提取这部密码本的内容,将其中理性的、可分析的、重复的部分总结出来。解密的过程其实是一个从人类深层认知到表层体现的转变。经过基于翻译逻辑的算法(algorithm)和机器训练(machine training)之后,人类将部分认知能力、记忆等传授给机器,由机器取代或辅助我们的部分工作,这个过程形成了由人与机器构建的一个动态发展的生态系统。我们必须认识到,整个交互式机器翻译系统的进化,不单只依靠机器的进步,译者或语言学者作为系统内最重要的一部分,也必须根据系统进化的需要对自己的技能与工作内容进行相应的调整,以带动整个系统的良性循环与高效运行。本文将提出语境架构的概念,分析机器与人类在交互式机器翻译系统中各自发挥的作用。
一、 语境与意义:翻译人工智能的难点
事实上,Weaver 所提出的“解码”过程要远比最初设想的难得多,因为能够显示在纸上的俄语内容只是冰山一角,它激活了隐藏在文字后面的深不可测的意义与承载意义的语境。我们知道,翻译首先是个理解的过程,而任何理解都必须建立在意义之上。同时,翻译也是一个生成意义的过程,但是它的意义并不是自然产生,而是受到原文的牵引。换言之,翻译是一个引导性的意义创造的过程(guided creation of meaning)[2]15。 从这个角度来讲,人工智能可以很方便地应用于翻译领域,因为原文本身就是一个必须遵循的转换依据。
但是,无论是翻译的理解,还是意义的生成,都必须以一定的语境为依托。没有语境,单纯的文本也就谈不上意义。语境是伴随文本的语言环境和非语言环境[3]5。由于语言系统间的差异,翻译中的完全对等(equivalence)往往很难实现,它通常只是在具体语境中的某个或某些层面上的等值[4]34-36。而在此过程中,语义的模糊性以及语境的即时性、多变性、灵活性,一直以来都是机器翻译的难点。
实际上,这个问题从机器翻译创建伊始便被提出来了。1947年,当Norbert Wiener收到Warren Weaver关于机器翻译的来信后,他回复道:
“坦率地讲,我认为不同语言的词汇的界限太过模糊、太过情感化,其意义也太宽泛,从而使任何类似机械翻译的计划都没有什么太大的希望。”
“I frankly am afraid the boundaries of words in different languages are too vague and the emotional and international connotations are too extensive to make any quasimechanical translation scheme very hopeful”[5]7
随后,尽管1954 年著名的乔治城大学和 IBM(GeorgetownIBM)机器翻译原型实验取得了巨大成功,但是正如Yehoshua BarHillel在其Report on the state of Machine Translation in the United States and Great Britain[6]一书中指出的那样,由于语义的模糊性,完全自动化的高质量翻译(fully automatic highquality MT,FAHQT)几乎不可能存在,他举了一个著名的例子:
Little John was looking for his toy box Finally, he found itThe box was in the pen John was very happy
60多年后,绝大多数机器翻译引擎对 The box was in the pen 的翻译依然是“盒子在笔里”。BarHillel[6] 指出,机器翻译无法根据语境来决定 pen 的意义,但是任何一个英文足够好的读者都可以“自动地”判断出 pen 在此语境下的意义是“让婴儿游戏的圈栏 (playpen)”,而并非“盒子 (box)”。而这也仅是翻译的最初始的一个步骤,它甚至都还没有涉及到语言的转换过程。
二、 交互式机器翻译环境
(一) 交互式机器翻译
相较于表层的语言符号,语义以及承载语义的语境是抽象的、动态的、无形的。从某种程度上讲,机器翻译发展史也是一部机器不断探索、把握、学习人类这种抽象认知能力的历史。从最初的遵循人类制定的语法规则,到 20 世纪 90 年代兴起的对语言数据的学习,再到 21 世纪初叶的试图构建人工神经网络来解码、编码进行语言转换[7]12-15[8],机器翻译人工智能在不断摸索从语言表层符号规律到深层语义及其依托语境的学习方法。
首先,依据语法规则的机器翻译(rulebased machine translation)引擎很难将语境与意义有机结合到机械化语言转换的过程中。正如 ALPAC(Automatic Language Processing Advisory Committee)报告[9]19所指出的那样:“经过 8 年努力,乔治城大学的机器翻译项目虽然希望在 1962 年得出有意义的结果,但是他们不得不借助于译后编辑(postediting),而译后编辑的过程却要比传统的人工翻译花的时间更多,成本也更高。”
值得注意的是,在此期间机器翻译获得成功的案例大多都是对语境有具体限定的、专业内容范围较窄的垂直机器翻译引擎,例如:专注于气象报告与预警内容翻译的引擎 Météo[10] 以及总部在乔治城大学附近的泛美卫生组织(Pan American Health Organization,PAHO)自行设计的机器翻译引擎 PAHOMTS[11]。Météo 与 PAHOMTS 均是针对专门内容与语境的翻译引擎,这在一定程度上减少了机器翻译对意义把握的不确定性,从而提高了机器翻译的准确性和可用性。
20世纪90年代兴起的统计机器翻译(statistical machine translation)是基于大量平行语料库及单语言对比语料库而进行统计分析、构建语言模型(language model)的方法。语料库即“大型的、依据原则而收集的自然文本的集合”[12]4。相较于人工语言或人造语言(artificial language),自然文本或自然语言(natural language) 更加注重语言的实际使用,强调语言使用的文本以外的特点,例如语域、方言、时间等。因此,统计机器翻译在一定程度上实现了从“使用中的语言”数据中间接学习人类处理语境与语义的方法,这是机器翻译的一大突破。但是,正如Way与Hearne[13]指出的那样,这种方法忽视了语言学者与译者所起的核心作用。一方面,许多译者很难理解统计机器翻译的基本模式;另一方面,这种模式完全取决于大量的翻译数据,而很少去思考数据产生的过程并反映实际翻译文本中已知的现象。也就是说,即便机器可以根据概率和语料库作出正确或接近正确的翻译判断,它也不知道如何从语言学、翻译学的角度分析、解释这种现象。虽然产生的翻译结果可能相同或相似,但是机器对于语境与语义的理解与人类的认知是完全不同的。
相较于前面两种机器翻译模式,2013 年开始兴起的神经机器翻译(nearual machine translation)研究更多地考虑了语言与语境之间的联系。统计机器翻译可以通过 ngram 等方法来分析简单的语境,但是远不如神经机器翻译对语境的利用。例如:神经机器翻译的词向量的分布式表征(distributed representation)可以根据词之间的距离来判断它们之间的(语法、语义上的)相似性。
2015 年,Green等[14] 指出,随着机器翻译的快速发展, 现在的人工智能与人机交互(humancomputer interaction)之间的结合越来越紧密,形成了交互式机器翻译系统(interactive machine translation)。人工智能旨在建立替代人类智力的机器智能;而人机交互恰恰相反,它更多地强调具有可用性与实证性的方法与人类因素。译后编辑是一种较为简单的人机交互形式。例如,PAHOMTS 成功的另一个主要原因就是它可以很好地将译后编辑的结果反馈到机器翻译引擎当中。实际上,译者针对机器翻译结果进行的修改是神经机器翻译的反向传播算法(back propogation)中训练人工神经网络(artificial neural network)的最重要的数据。
目前交互式机器翻译的典型模式是译者从翻译开始便与机器互动。机器首先对原文进行切分,并提供翻译建议,译者再根据语境与意义选择或修改机器的建议。接着,机器又会根据人类的选择实时调整下面的建议。这个过程对于译者与机器均有益处。
具体来讲,交互式机器翻译一般采用的是在句子层面的由前缀控制的机器翻译(prefixconstrained machine translation)方法。也就是说,翻译首先由译者输入最前面的部分,即前缀(prefix),然后机器对剩余的部分,即后缀(suffix),进行预测,自动生成翻译结果,生成的结果可以自动填入剩余的部分,或者将其视为一个新的单位,循环应用前缀—后缀的翻译生成模式,直至翻译完成[15-16]。当然,在这个过程中,由于设计思路及使用的逻辑、算法(例如集束搜索、目标集束搜索)的不同,最終呈现的人机交互的形式可能也有其特定的表现。但是,无论表现如何,交互式机器翻译的一个共同特点便是人类在翻译的过程中起到了决定性的作用。
(二) 交互式机器翻译环境
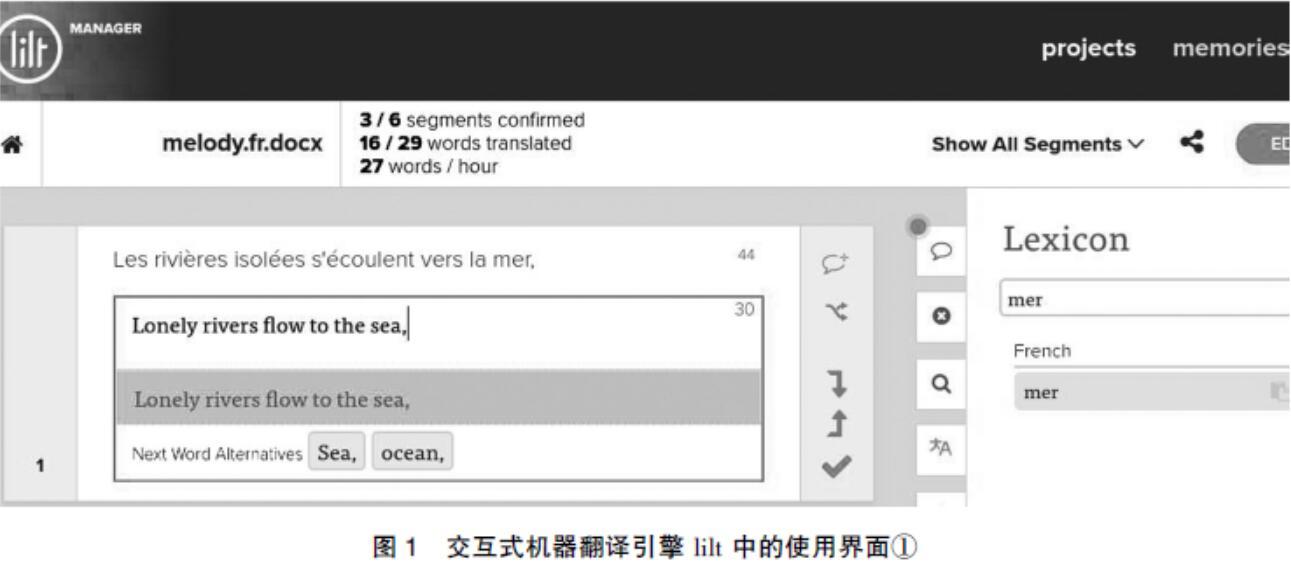
交互式机器翻译环境是根据计算机辅助翻译中的翻译环境工具(translation environment tools, 缩写为TEnTs)的概念而派生出来的。翻译环境工具是指将不同计算机辅助翻译工具集成于一个平台或软件,以帮助用户更高效地利用翻译技术工具[17]。同理,交互式机器翻译环境也是集交互式机器翻译引擎、术语(terminology)、翻译记忆(translation memory)等功能于一体的、供用户更有效使用这些软件功能的操作平台,例如美国的 lilt 神经机器翻译平台(见图1)。
如图1所示,交互式机器翻译环境与传统的翻译界面(例如使用Word文档进行翻译)有很大的区别。在交互式机器翻译软件环境中,原文被切割为不同的切分单位(segment),每一个切分单位都经过类似于图1所展示的交互式机器翻译引擎的会话过程,最后由译者确定最终翻译结果,这是交互式机器翻译环境的核心(图1左边的对话框是引擎切割的翻译句段,图中显示了一个切分单位)。而且,除了交互式机器翻译引擎外,这个平台也集成了术语(图1右侧的lexicon)、翻译记忆(图1右上角的memories)、项目管理(图1右上角的projects)等计算机辅助翻译工具的常见功能,而这些都是传统翻译环境不能提供的。
相较于传统的翻译环境,交互式机器翻译环境有其独特的特点。首先,交互式机器翻译环境结合人机互动的特点和原理,也就是说,它既包括人类认知,也包括软件平台所具有的特定功能。当然,机器翻译引擎,尤其是神经机器翻译引擎,是建立在对人类神经网络的模仿之上的,两者之间必然有许多相似的地方。但是机器主要是通过对数据分析、建立模型等数学方式来解决问题的,而人类的认知则包含意义及理解等诸多领域。其次,如图1所示,交互式机器翻译环境的使用者界面与传统的翻译界面不同,这也意味着译者接触语境的方法和形式在一定程度上受到了软件环境的限制,甚至有很多译者认为新的翻译技术使用者界面在一定程度上影响了译者对语境的把握。可以肯定的是,翻译环境的差别必将影响译者的翻译过程及其对翻译策略的选择,从而影响译者对语境和意义的认知。因此,本文提出的基于交互式机器翻译环境的语境架构,不仅适用于与机器翻译系统互动的人,还适用于机器翻译引擎本身。也就是说,它不仅可以帮助我们更好地理解译者在翻译环境中的行为,还可以让我们更好地总结、提取、分析、管理机器翻译相关的数据,预测交互式机器翻译环境对人类干预的依赖程度,以便让软件开发者和使用者更好地制定人机互动的策略(例如预测、核算译者所产生的翻译成本等)。
(二) 交互式神经机器翻译环境
目前的交互式机器翻译系统大多以神经机器翻译为基础框架。神经机器翻译是指直接采用神经网络以端到端方式进行翻译建模的机器翻译方法。区别于利用深度学习技术完善传统统计机器翻译中某个模块的方法,神经机器翻译采用一种简单直观的方法完成翻译工作:首先使用一个称为编码器的神经网络将源语言句子编码为一个稠密向量,然后使用一个称为解码器的神经网络从该向量中解码出目标语言句子。这种神经网络模型一般称之为“编码器—解码器”结构[18]。
在交互式神经机器翻译引擎与使用者互动的过程中,机器具有其独特的优势,例如机器记忆、逻辑分析等,但支撑机器的人工神经网络始终是建立在对人类的模仿之上,这种模仿从表层的语言成分的关系不断延伸到更深层、更复杂的语言现象,如语义、语境等。归根结底,人类之所以能够在人机交互的系统中占据主导地位的原因,也许不再会是我们所拥有的知识、记忆、逻辑思维,而是我们与生俱来的更自然的人类体验。
神经机器翻译引擎存在语境与意义方面的缺陷,机器需要在与人类互动过程中不断学习,以对算法和数据进行进一步的修正。例如:Luong等[19] 指出神经机器引擎还没有系统使用语言的句法与语义特征,另外它在宏观的文本结构上也存在较多的问题,例如语篇结构、指代等。Koehn 和 Knowles[20] 提出了六大神经翻译引擎的问题,其中也包括了某些词汇在不同专业领域中意义选择的错误(domain mismatch)、对长句子翻译的错误率较高等。这些问题实际上都或多或少地都涉及到语境中的意义这个命题,这也是机器最需要在与人机互动的过程中不断学习的地方。
三、 基于交互式机器翻译环境的语境架构
(一) 语境
任何交流都是一个动态的过程,一旦发生,我们便再不可能有完全一样的经历。交流过程中的所有元素不断地互相影响,当语境因素(contextual factors)不同或有所改变时,一个人的思想也往往在频繁的转换与进化[21]24。以翻译来驱动的跨文化交流亦是如此,而帮助我们把握这个动态交流过程的一个重要工具便是语境。
波兰裔人类学家马林诺夫斯基(Malinowski)[22]99-103对于语境的研究作出了重要的贡献,他区分了确定文本意义的全局语境与更广泛语境,即情景语境(context of situation)与文化语境(context of culture)。例如,在对特罗布里恩(trobriand)岛上居民的话语进行翻译的过程中,译者不仅要向英语读者解释岛上居民话语的直接语言环境,还要解释相关的特罗布里恩岛特有的传统与信仰,否则英语读者便不能理解原文所蕴含的全部意义。
Halliday 和 Hasan从系统功能语言学的角度[3]12-28,总结出描述语境的三条主线:话语范围(field of discourse)、 话语基调(tenor of discourse)、话语方式(mode of discourse)。他们指出,这三个概念诠释了文本的社會语境,确定了事件中所交流意义的环境,它们分别对应于系统功能语言学的三大语言元功能。这种语境模式充分体现了语言功能与语境之间的关系。
另外,在术语的语境研究中,Faber和LeónAraúz[23] 将语境分为本地语境(local context)与全局语境(global context),每一种语境又分别包括语法、语义、语用三个下属层级。 Faber和LeónAraúz[23]5 对本地语境的定义是词汇的前 5 个和后 5 个词,这当然是根据术语研究的特点提出的。Faber和LeónAraúz[23] 认为,全局语境的范围更为宽泛,它可以是包括术语的整篇文档、某个交际语境(例如:正式与非正式的)、某个主题领域(例如:地理、气象学等),甚至是整个语言与文化。
(二) 交互式机器翻译环境的语境架构
以上有关语境的研究,从人类学、系统功能语言学、术语研究等不同的视角赋予了语境相应的理论框架,使语境不再是模糊的、朦胧的抽象存在,从而增加了语境分析的可操作性。但是,这些理论框架均不是专门针对交互式机器翻译系统的。正如我们在第二部分所讨论的那样,语境与意义一直都是机器翻译的难点,而交互式机器翻译引擎在一定程度上弥补了机器在这方面的不足。在实际的人机互动过程中,我们有必要了解机器对译者的依赖程度,从而更好的把握译者与机器之间的关系。因此,本文以交互式机器翻译环境为基础,并借用了 Sperber 和 Wilson的关联理论[24],以译者的认知效果(cognitive effect)与认知努力(cognitive efforts)为切入点,将交互式机器翻译系统中的语境因素分为不同层级。
具体来讲,该语境框架包括本地语境、全局语境、语境效果三个基本层级。我们将本地语境定义为所考察的当前切分单位。正如我们在传统的翻译记忆软件中所看到的那样,翻译软件将原文切分为不同的部分,译者对切分的结果逐一翻译,当译者需要理解某个意义单位时,他应该首先理解该意义单位所在的当前句段。如果译者在当前切分单位中还是无法确定其意义的话,那么在交互式机器翻译软件中,译者會在与当前切分单位最近的句段中寻找答案。因此,我们提出当前切分单位的前n 个和后 n 个切分单位为全局语境,具体量化的数值 n 会根据原文文本的特点而有所不同。例如,同样一句话“Romance is finding your fantasy in people who dont have it”,如果是在普通文本中可能会是一个切分单位;但是为了突出效果,有很多海报、明信片、笔记本封面等在引用这句话时常常采用以下的排版格式:
对于这样的文本,大多数引擎会根据换行将其分为6个切分单位,分别为(1)romance,(2)is finding your,(3)fantasy,(4)in people,(5)who dont,(6)have it。因此,相较于仅有文本的原文,图2所显示的原文中的任何一个切分单位的全局语境的n值会更大。
语境架构的顶层是语境效果,这是关联理论的一个主要概念[24,20]。Sperber和Wilson[24]对语境的定义是:“语境是一个心理构建,是听者关于世界假想的一个子集。当然,正是这种假设,而并非世界的实际状态,影响了对表达的诠释。从这个意义上讲,语境不仅仅局限于直接的物理环境或紧邻于该话语之前的表达:对未来的预测、科学的假设或宗教信仰、经验记忆、一般文化设想、对讲者心理状态的设定等,都可能在诠释过程中都起到作用。”在交互式机器翻译环境中,我们认为所有无法用本地语境和全局语境来诠释的语境因素均为语境效果,这包括超出切分单位前后n个单位的句子、甚至超出原文的其它语境因素。交互式机器翻译环境的语境架构的具体情况,详见表1。
(三) 基于译者认知努力的交互式机器翻译的语境架构
表1的划分是根据交互式机器翻译软件的特点来划分的,在此基础上,我们再根据译者认知努力来进一步区分语境架构的层级。首先,处于最低层的是本地语境的句法、语义层级(11,12)。在这个层级上,机器对译者的依赖最小,译者的努力也最小,机器训练的效果也最好。第二个层级便是全局语境的句法、语义层级(21,22)。在此层级,译者不仅要考虑当前切分单位,还要考虑紧邻当前切分单位的其它切分单位。因此译者的努力比第一层多,机器训练所需的数据较第一层更宽泛,但是在此层级还不需要离开交互式机器翻译软件环境。第三层是本地语境的语用层级(13)。在此层级,译者已经无法从交互式机器翻译系统中找到问题的答案,而需要暂时离开机器翻译平台或借助平台内部集成的外部资源(如图片、参考文档等),来完成对意义的理解。例如,以下是一个展示排球运动员Adam Smith的一场排球比赛表现的例子:
如果将该文本导入到交互式机器翻译引擎中,引擎会将其切分为“Adam Smith”“spike”“block”“serve”“68”“19”“20”等切分单位。如果我们要理解“block”的意思,那么“spike”和“serve”便是“block”的全局语境。如果熟悉排球的译者可能可以仅从全局语境便可确定“block”的意义是“拦网”,这是全局语境的语义层面(22)。但是,若译者对排球并不了解,他可能还需要离开交互式机器翻译环境,去查看原图。当他看到图片上排球的照片时,这个语境信息会帮助译者确定“block”的意思,这就是利用了本地语境的语用层面(13),这是语境架构的第三层。当然,为了确保理解的准确性,译者还可以根据图片来进一步确定“serve”和“spike”在该语境中的意义,这就将理解延伸到了全局语境的语用层面(23)。
语境层级的最高一级是语境效果。我们来看下面一段对话:
(1) My mom really asked why I have 30 missing assignments
(2) Xue hua piao piao, bei feng xiao xiao图片来源于https:wwwshinecnfeaturelifestyle2007101900。
在交互式机器翻译环境中,系统会将此对话分为两个切分单位,即(1)和(2)。如果要翻译“Xue hua piao piao, bei feng xiao xiao”这个句段,那么显然字面翻译“雪花飘飘,北风潇潇”无法让中国读者理解,译者需要介入,重新根据这个句段产生的心理效果来翻译。要准确地把握说话者的意图,译者需要了解这句话在西方流行的原因和背景。这句歌词来自中国的一首老歌《一剪梅》,2020年在TikTok软件上迅速且广为流行的一句话,它反映了世界新冠疫情爆发时人们所经历的心理与环境的变化,是在世界疫情的大环境下经过西方网友的二次创作的产物,尤其使西方待在家里无可事事的年轻人产生了强烈的共鸣。根据实际的使用环境、使用者的心理,在英文文本中,它可以表达对一件事的绝望或不屑,也可以是说话者不知道该怎么回答时的一种敷衍的措辞。译者要找出准确的翻译,还需要了解更广泛的语境,例如以文字出现的这个故事的上下文,或者是非语言情景,这便是语境效果层级。在此层级,交互式机器翻译引擎对人类最为依赖,译者所耗费的认知努力也越大。
表2是基于译者认知努力的交互式机器翻译的语境架构的总结。如表2所示,层级数越高,译者就越有可能离开交互式机器翻译环境,从紧邻当前切分单位,到超出全局语境的翻译,再到翻译环境以外的语境资源,包括实际资源(如交互式机器翻译环境以外的文档、图片等)以及心理资源(例如“Xue hua piao piao, bei feng xiao xiao”在中文读者与英文读者之间构建的心理效果的差异)。层数由小变大的过程,也反映了译者所需的认知努力不断加强。
四、 基于交互式机器翻译环境的
语境架构的应用基于交互式机器翻译环境的语境架构可以帮助软件开发者和使用者(包括软件开发人员、翻译项目管理人员、机器引擎训练技术人员、译者等)更好的分析语言数据(尤其是译者反馈的数据),提高交互式机器翻译引擎的机器训练、机器学习的效果,并可以更有效地评估在该技术环境下人机互动的程度,以制定相应的机器翻译技术实施的框架和策略。具体来讲,它可以从以下两個方面评估系统对译者的依赖性。
(一) 语境架构在引擎自动切分中的作用
交互式机器翻译引擎与非交互式机器翻译引擎(例如谷歌、百度机器翻译引擎)的界面有很大的区别。在一定程度上,交互式机器翻译引擎的用户界面与传统的翻译记忆软件(例如SDL Trados Studio, MemoQ, Déjà Vu)更为相似,因为它们均包括对原文进行句段切分的步骤。不同的翻译软件句段切分的算法各不相同,算法中对语境因素考虑得越充分,得出的自动句段切分结果就越理想。严格来讲,这个阶段与交互式机器翻译引擎互动的人员首先是翻译项目管理者和软件设计开发者,然后他们再根据需要决定是否让译者或语言服务商对切分结果进一步标注、分析。
需要指出的是,机器翻译引擎切分句段与人类切分句段有所不同。例如,译者对原文的切分往往是建立在意义之上的,他们可以很轻松地区分形式与意义的差别。例如,“Romance is finding your fantasy in people who dont have it”这个句子,无论排版的格式如何,大多数译者都可以毫不费力的将其切分为一个句子,但是机器引擎目前还做不到这一点。一些人类不以为然的问题,例如字体样式、字体大小、字体颜色、换行等,对于机器来说尤为棘手。所以,当处理图2的文本时,字体大小、是否黑体、换行等格式信息会干扰机器对原文的切分,而将其切分为:(1)romance,(2)fantasy,(3)is finding your,(4)in people,(5)who dont,(6)have it。这是因为如图2所示,romance和fantasy的字体大小一致而且均是黑体,is finding your与in people的字体大小一致,who dont与have it的字体大小一致,而图2上的分行是引擎将其分为6个切分单位的主要原因。这就是我们在表1所总结的语境框架中的本地语境和全局语境中的语用层面。
出现图2所示的引擎切分的结果会对翻译造成很大的困难,因为如果仅是集中在本地语境的话,即按从(1)到(6)切分单位字面翻译,然后再将在交互式机器翻译环境中翻译的结果放回原图的话,那么机器整合出来的结果必然是错误的。如果考虑到原文的格式,即考虑全局语境,将整句话作为一个句子考虑,然后译者可能会考虑将这六个切分单位翻译成:(1)romance—浪漫,(2)fantasy—幻想,(3)is finding your—就是发现,(4)in people—在那些,(5)who dont—没有拥有,(6)have it—浪漫的人身上。这样,当这些切分单位被翻译引擎合成后输出的结果虽然不是最佳的翻译效果,但也可以勉强接受。这似乎是一个不错的解决方案。不过这样做会造成翻译记忆的错误,因为从(4)到(6)句的中英文明显不对应,而这样的翻译记忆错误会直接影响机器翻译引擎的训练,造成无法修复的错误循环。
解决的办法之一便是翻译项目经理要求译者或语言服务商对于机器翻译引擎的自动切分结果进行手动修复。但是机器翻译所处理的项目往往工程浩大,一个项目可以包括几十万甚至几百万的字数,项目经理需要衡量工作的成本以制定合理的计划。在这种情况下,语境架构是一个有力的工具。例如,我们可以通过本地语境的字数、全局语境定义中的n 值、语境效果所包括的因素及其数量等,来预测自动切分的语境难度。
(二) 语境架构有助于评估机器对译者的依赖程度
语境架构在交互式机器翻译环境中应用的第二个方面是译者参与翻译的阶段。交互式机器翻译自动切分句段后,译者将按照切分后句段与机器互动,对其进行翻译。在此过程中译者对机器给出的建议进行选择,一旦译者否定了机器的意见之后,机器便会对下面的建议进行相应的调整,如此滚动进行,并最终得出翻译的结果。相较于翻译过程中没有人类参与的机器翻译,交互式机器翻译系统在一定程度上弥补了机器对语境处理能力不足的情况。如表2 所示,译者越是在语境框架的下游(11,12, 21,22)进行处理,他所耗费的时间和精力可能就会越少,而越是向上(13,23,3),他就需要离开交互式机器翻译引擎而寻找其它的资料。所以,我们可以通过语境架构框架来预测机器引擎对译者的依赖性,从而预测译者的劳动强度,制定相应的翻译项目实施计划。
从机器训练的角度来看,传统的机器翻译引擎一般会在获得译者的反馈数据后定期对机器进行训练,而交互式机器翻译引擎可以在翻译的过程即时得到译者的反馈数据,机器训练的效果会更加明显。随着机器翻译引擎的不断优化,机器依靠译者的程度和侧重点会有所变化,从而导致对引擎所需的译者的数量与质量的变化。在这种动态的发展过程中,语境架构可以帮助我们更好的把握机器训练的特点和结果。
五、 结 语
2017年3月9日,Viktor MayerSchonberger[25]于英国国家广播公司(BBC)的《未来》(Future)频道发表了“The last things that will make us uniquely human”一文,他指出,我们必须着眼于人类对劳动分工的贡献,对机器的理性进行补充,而非试图与它竞争。这样做会让我们与机器产生差异,而正是这种差异化才会创造价值。
基于交互式机器翻译环境的语境架构框架可以幫助人类更好地了解自己在人机互动过程中所起的作用,译者也应该根据机器的进化趋势,不断调整自己知识与能力的侧重点,在人机交互中发挥主导与核心作用。最后需要指出的是,机器翻译的语境难点也受到翻译语对与翻译方向性的影响。本文中大多数例子是英进中翻译,如果交互式机器翻译引擎处理的原文是中文的话,情况可能会更复杂一些。中文的结构松散,语言内涵的判断对语境的依赖更高于其他语言,这也是我们可以在今后的研究中进一步探讨的课题。
致谢
明德大学蒙特雷国际研究学院的鲍川运教授在百忙之中审阅了本文,并提出宝贵意见,特此致谢。
〔参考文献〕
[1]WEAVER W. Translation [C] LOCKE W N & BOOTH A D. Machine Translation of Languages. Cambridge, New York: The Technology Press of MIT & John Wiley & Sons, Inc., 1955: 1523.
[2]HALLIDAY M A K. Language theory and translation practice [J]. Revista Internazional Di Tecnia Della Traduzione, 1992(0): 1525.
[3]HALLIDAY M A K & HASAN R. Language, Context, and Text [M]. Victoria: Deakin University Press, 1986.
[4]王鹏.《翻译理论探讨》——对当代西方翻译理论的批判性认识[J]. 中国翻译, 2010, 31(3): 3337.
[5]NILSSON N J. The Quest for Artificial Intelligence: a History of Ideas and Achievements [M]. Cambridge: Cambridge University Press, 2009.
[6]BARHILLEL Y. Report on the Sate of Machine Translation in the United States and Great Britain [M]. Jerusalem: Hebrew University, 1959.
[7]ARNOLD D J, BALKAN L, Humphreys R L, et al. Machine Translation: An Introductory Guide [M]. Oxford: Blackwell, 1994.
[8]TINSLEY J. A report from the front line of NMT [J]. Multilingual, 2018, 29(1): 4045.
[9]PIERCE J R. Languages and Machines: Computers in Translation and Llinguistics [M]. Washington, D.C.: National Academy of Sciences, 1966.
[10]THOUIN B. The Metero System [M]. Amsterdam: NorthHolland Publishing Company, 1982.
[11]AYMERICH J. Using Machine Translation for Fast, Inexpensive, and Accurate Health Information Assimilation and Dissemination [M]. SalvadorBahia, Brazil: 9th World Congress on Health Information and Libraries, 2005.
[12]BIBER D, CONRAD S & REPPEN R. Corpus Linguistics: Investigating Language Structure and Use [M]. Cambridge: Cambridge University Press, 1998.
[13]WAY A & HEARNE M. On the role of translations in stateoftheart statistical machine translation [J]. Language and Linguistics Compass, 2011, 5(5): 227248.
[14] GREEN S, HEER J & MANNING C. Natural language translation at the intersection of AI and HCI [J]. Communications of the ACM, 2015, 58(9): 4653.
[15] ORTIZMARTINEZ D, LEIVA L A, ALABAU V, et al. An interactive machine translation system with online learning [EBOL]. (201106)[20201112]. https:www.aclweb.organthologyP114012.
[16]WUEBKER J, GREEN S, DENERO J, et al. Models and Inference for Prefixconstrained Machine Translation [M]. Berlin: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
[17]ZETZSCHE J. A Maze of TEnTs [EBOL]. (200807)[20201210]. https:internationalwriters.comtoolkitJuly08Column.pdf.
[18]王星,熊德意,张民. 神经机器翻译[JOL]. (20161104)[20201210]. http:www.cipsc.org.cnqngw?p=953.
[19]LUONG T, CHO K & MANNIN C. Neural machine translationtutorial ACL [EBOL]. (2016)[20201012]. https:sites.google.comsiteacl16nmt.
[20]KOEHN P & KNOWLES R. Six challenges for neural machine translation [EBOL]. (20170804) [20201014]. https:www.aclweb.organthologyW173200.pdf.
[21] SAMOVAR L A, PORTER R E, Mcdaniel E R, et al. Communication between cultures [M]. Belmont, CA: Wadsworth, 1998.
[22] KATAN D. Translating Cultures [M]. UK: St. Jerome Publishing, 1999.
[23] FABER P & LeónAraúz P. Specialized knowledge representation and the parameterization of context [EBOL]. (20160223)[20201012]. https:www.frontiersin.orgarticle10.3389fpsyg.2016.00196.
[24] SPERBER D & WILSON D. Relevance: Communication and Cognition (2nd ed.) [M]. Oxford: Blackwell, 1986.
[25] VIKTOR M. The last things that will make us uniquely human [NOL]. (20170309)[20201006]. https:www.bbc.comfuturearticle20170309thelastthingsthatwillmakeusuniquelyhuman.
On the Hierarchical Structure of Context in Interactive Machine
Translation Environment Tools
WANG Peng
(School of Translation and Interpretation, University of Ottawa, Ottawa ON K1N 6N5, Canada;
Nanfang College, Sun Yatsen University, Guangzhou 510970, China)Abstract: Since its inception, one of the biggest challenges for machine translation is meaning in context. Nowadays, the fields of artificial intelligence (AI) and humancomputer interaction (HCI) are influencing each other like never before. Recent breakthroughs in the translation are made possible by a healthy AIHCI collaboration. This article proposed a hierarchical structure of context for interactive machine translation environment tools, including local context, global context and contextual effects, based on translators cognitive efforts when interacting with machines. This framework helps software developers, project managers and linguists who work with the interactive machine translation system better incorporate the contextual factors when collecting, managing and analyzing data from human feedback, which leads to relevant strategic plans for automatic segmentation as well as effective estimation for the degree of human involvement.
Key words: interactive machine translation environment tools; neural machine translation; hierarchical structure of context
〔收稿時间〕 2020-11-13
〔作者简介〕 王鹏(1975—),女,河北邯郸人,广东省副教授。加拿大政府翻译局同声传译译员,渥太华大学翻译与口译学院兼职教授,中山大学南方学院客座教授。
