通用语料的眼动数据对微博关键词抽取的性能提升探究
2021-05-26章成志胡少虎张颖怡
章成志,胡少虎,张颖怡
(南京理工大学经济管理学院信息管理系,南京210094)
1 引言
关键词通常为描述文档的主题信息的词语[1]。随着信息资源的快速增长,人工标注文本关键词的方式已经无法满足实际需求。因此,关键词自动抽取研究逐渐引起了学术界的重视。此外,关键词抽取可以作为文本摘要、文本聚类、文本分类等任务的基础。
在线社交媒体是网民发表个人见解、分享个人状态的重要载体。在线社交媒体每天产生海量的用户生成内容(user generated content,UGC)。如何高效地组织用户生成内容已成为业界与学术界共同关注的问题。从海量的用户生成内容中及时有效地抽取关键词,对于在线社交网络的信息组织尤为关键。因此,许多关键词抽取研究选择微博语料作为研究对象,本文的研究同样将在推特语料上开展。
目前,机器学习方法被广泛应用于关键词抽取任务。具体来说,基于机器学习的关键词抽取研究可以分为非监督的抽取方法与有监督的抽取方法[2]。关键词抽取结果的评估,一般都以关键词标注数据作为依据。标注员在标注关键词时,首先阅读待标注文档的全文,然后根据理解标识出有代表性的若干词语。已有研究表明,当人们在阅读文档的时候,对于文本中的所有单词的关注程度并不均等[3]。这说明人们在阅读时的注意力并非均匀地分布在每一个单词上,读者更有可能将注意力集中在有助于其理解文本含义的词汇上。根据这一观察,研究者可以度量阅读者对不同单词上的注意力强弱,并将该信息用于关键词抽取,提升抽取的性能[4]。
度量读者阅读文档时在不同词语上的注意力强弱,较为直观的方式是比较读者在阅读不同词汇时眼动行为上的差异。眼动数据集记录了被试者在阅读时的眼动行为数据,可以利用这些眼动数据来度量读者在不同词汇上的注意力强弱。例如,Zhang等[4]根据该方式,依据通用语料盖科(Ghent Eye-Tracking Corpus,GECO)眼动数据集①http://expsy.ugent.be/downloads/geco,访问日期:2020年3月30日。在推特文本上进行关键词抽取实验,实验结果表明,考虑词语的注意力强弱可提升关键词抽取模型的性能。需要指出的是,通用语料眼动数据集中包含丰富的眼动行为数据,如何将这些数据用于关键词抽取等自然语言处理任务、全面深入地分析眼动数据在自然处理抽取任务上的作用,尚值得深入探索。因此,本文从眼动特征的选择、眼动特征与其他特征组合两个方面,探究通用语料的眼动数据对微博关键词提取任务性能的影响。同时,由于眼动数据集与测试数据集在词汇规模上的差距较大,使得眼动特征过于稀疏进而影响了其作用的发挥,所以本文还提出了一个眼动数据扩充方案。需要说明的是,本文通过关键词抽取模型在测试集上抽取结果的变化,来评判模型抽取性能的强弱。总的来说,本文的贡献体现在如下三个方面:
(1)本文分别将总注视时长、注视次数、平均注视时长、初次注视时长等眼动特征应用于微博关键词抽取任务,证明在仅考虑眼动特征的情况下,总注视时长对抽取模型的性能提升最为明显。
(2)将上述眼动特征与单词的词性、词长、相对位置等文本内容特征共同应用于微博关键词抽取任务后,平均注视时长与文本特征的组合达到了最优效果,证明平均注视时长这一眼动特征在关键词抽取任务的整体上来看更有价值。
(3)在基于眼动特征的微博关键词抽取中,通过单词词形之间的相似程度对眼动数据进行扩充的方法可以有效地解决眼动数据稀疏的问题。
2 相关工作概述
本文旨在对通用语料的眼动数据对微博关键词抽取任务性能的影响进行分析,同时,提出相应的方案解决眼动数据在应用时存在的问题,因此,与本文相关的研究工作主要包括关键词抽取方法与眼动数据的应用两个方面。本节将从这两个方面对相关工作进行总结。
2.1 关键词抽取方法研究概述
关键词抽取研究方法主要分为无监督的方法和有监督的方法两大类[2]。早期用于关键词抽取的方法主要为无监督方法,无监督的方法按照类别可以分为基于简单统计的方法、基于图结构的方法、基于词嵌入的方法和基于语言模型的方法。除了基于图结构的方法以外,其他三种方法很少单独使用,多作为关键词抽取的辅助手段出现。如doc2vec[5]、sent2vec[6]以及GloVe[7]等就属于基于词嵌入的方法,但很少有研究纯粹使用词嵌入来抽取关键词,基本均会与其他的模型方法结合使用。
有监督的方法分为传统的机器学习模型与深度学习模型两类。在传统的机器学习方法中主要存在两种思路:一种将关键词抽取任务视为分类任务;另一种将其视为序列标注任务。如Witten等[8]提出的KEA(keyphrase extraction algorithm)算法与Jiang等[9]提 出 的Ranking SVM(support vector machine)算法就是通过分类模型对候选词进行分类从而得到关键词。章成志等[10]通过序列标注模型CRF(conditional random field)实现了对中文文本中关键词的标引。而Gollapalli等[11]同样利用CRF模型对英文文本中的关键词进行了抽取,在构建单词的特征时引入了外部资源。
随着深度学习的发展,深度学习模型在多项自然语言任务中均取得了出色的成绩,自然也被应用于关键词抽取任务。Zhang等[12]为了研究如何从推特中抽取关键词,提出了拥有两个隐层的深度递归神经网络模型:在第一层中捕获关键词的相关信息,在第二层基于第一层获得的关键词信息进行序列标注。Meng等[13]在2017年提出了基于编码器-解码器框架seq2seq,该框架使用CopyRNN捕获内容的语义信息,并将数据转化为“文本-关键词”的键值对,然后使用RNN(recurrent neural network)模型学习源序列与目标序列之间的映射关系。虽然深度学习的模型种类众多,但在关键词抽取任务中,最为常见的是BiLSTM(bidirectional long shortterm memory)模型。BiLSTM属于序列标注模型,其同时考虑了文本信息正向和逆向的传递,能够很好地记录句子的结构信息,因而受到许多研究者的青睐[14]。Zhang等[15]在对微博文本进行关键词抽取时就使用了BiLSTM模型,并证明了其性能相较于CRF等传统的机器学习模型更为优异。
关键词抽取是一项重要的自然语言处理任务,科研工作者针对该任务提出了许多研究方法。从研究对象上来看,由于微博文本数据规模大、更新速度快且与人们日常生活联系紧密的特性,许多关键词抽取研究都是在微博文本上开展的。从研究方法上来看,由于深度学习模型较强的泛化性与抽取的准确性,基于深度学习的关键词抽取方法已经成为了主流。本文将使用深度学习模型抽取微博文本中的关键词,并深入分析眼动特征这一新的特征对微博关键词抽取任务性能的影响。
2.2 眼动数据在自然语言处理中的应用概述
阅读是人类认识世界的重要途径,人类通过阅读获取语言文字中的信息后才能对文本进行更深入的思考,人类的阅读行为从一定程度上能够反映人类的认知过程。早在20世纪80年代,人们就意识到了眼动数据的重要性,并建立了大量的眼动数据集,这些数据集涉及了语言学各个方面的研究[16]。随着采集设备和采集标准的规范化,进入21世纪后,出现了大批的眼动数据集。其中较为著名的有邓迪(Dundee)语料库[17]、波茨坦(Potsdam)语料库[18]、普罗沃(Provo)语料库[19]、GECO语料库[20]、祖 科(Zurich Cognitive Language Processing Corpus,ZuCo)语料库[21]等。
眼动数据集已在多项自然语言处理任务中取得较好效果。Barrett等[22]提取出邓迪语料库中的眼动数据,结合SHMM-ME模型[23]提出一种弱监督的词性标注方法。在该研究中,其还将眼动数据集中采集的眼动行为数据分为多个类别,并比较了各个类别下的眼动特征的作用。Mishra等[24]将单词的注视时长、注视次数等眼动行为数据转化为眼动特征,与单词的词向量、词性等特征组合,利用SVM、朴素贝叶斯模型和多层感知机模型对文本进行情感分析并对实验结果进行评估。
上述研究的共同之处在于均需要在实验前招募志愿者来阅读相关语料并采集志愿者的眼动数据,这极大地限制了眼动数据的使用。Barrett等[25]的一项实验极大地拓宽了眼动数据的应用范围,其利用邓迪眼动数据集在其他五种不同的语料上进行词性标注实验,证明眼动特征可以应用于不同种类的语料上。Barrett等[26]在2018年的一项工作中表明,眼动数据在其他语料的情绪分类、错误语法检测、侮辱语言检测等任务上都可以起到较好的效果。在该项任务中,研究者将单词的眼动特征通过注意力机制融入深度学习模型中,使得模型在训练时更关注文本的关键部分,并取得了较好的效果。
需要指出的是,Zhang等[4]同样利用注意力机制在推特数据上进行关键词抽取研究,该研究证明将读者对词汇的总注视时长这一眼动行为数据进行一定的处理后,单独加入关键词抽取模型可以提升模型的抽取效果。但该研究未考虑使用其他眼动行为数据进行对比实验,也未从整体上考察眼动特征在推特关键词抽取任务上的作用,同时针对实验中存在的眼动数据稀疏问题也只是给出简单的均值方案。为了更加全面地分析眼动数据在微博关键词抽取任务上的作用,本文将设置三组对照实验从眼动特征的选择、眼动特征与其他特征组合,以及眼动数据的扩充三个方面进行更为深入的探究。
3 研究方法
3.1 研究思路
本文研究思路为:①http://www.natcorp.ox.ac.uk/,访问日期:2020年3月30日。数据准备:选择合适的眼动数据集与用于关键词抽取实验的微博数据集;②数据预处理:对微博文本中的非法字符进行替换,以句为单位对文本进行编码处理,对眼动数据集中的眼动数值进行归一化处理,并提出眼动数据的扩充方案;③眼动特征与文本特征概述:对本文所使用的眼动特征与文本特征进行概述,包括特征的来源、特征的处理和选择该特征的原因;④关键词抽取模型构建:针对本研究的任务构建关键词抽取模型;⑤眼动数据作用分析:说明实验设置与评价指标,并对实验结果进行分析,主要从眼动特征的选择、眼动特征与其他文本特征的组合、眼动数据扩充方案的评估三个角度进行分析。具体思路如图1所示。
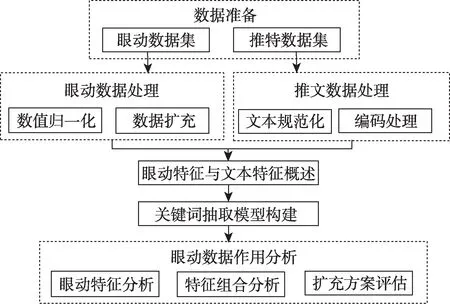
图1 研究思路图
3.2 数据集概述
本文所使用的数据集可分为两类:第一类数据集以眼动数据为主,用于生成人在阅读时对单词的注意力值,即单词的眼动特征;第二类数据集以推特数据集为主,用于训练关键词抽取模型并评估模型性能。本小节将从这两个方面对文中所使用的数据集进行概述。
3.2.1 通用领域眼动数据集
目前,开源的眼动数据集数量较为有限,并且不是所有的眼动数据都适用于本实验。部分眼动数据集会在采集数据前,给被试者提供若干与阅读文本相关的问题,使得被试者在阅读时带有目的性。尽管没有直接的研究表明这会显著地影响人的阅读行为,但为了尽可能地减少潜在的干扰因素,本文选择规避这类数据集。由于过于稀疏的眼动数据分布可能导致实验结果不显著甚至起到反作用,所选的眼动数据集规模不能过小。以ZuCo数据集[21]为例,该数据集中符合要求的部分仅包含700个句子与2206个单词,并不利于后续研究的展开。综合多种因素的考量,本文最终选择了GECO数据集[20],该数据集选择了以英语为母语的6名男性与7名女性作为数据采集对象,采集了其在一般状态下阅读小说时的眼动行为数据,共囊括了5031个句子,5749个单词,较为符合本文的要求。
本文使用眼动数据来表示人类在阅读时注意力的分布情况,但是直接使用眼动数据来度量阅读者对该单词的注意力强弱并不合理。在日常生活中,人们接触各个单词的概率并不相同,相较于熟悉的单词,人们需要花更多的时间去理解较为陌生的单词。这并不表明阅读者更加关注这类单词,只是阅读者对其更为陌生。因此,本文参照文献[4]引入英国国家语料库①http://www.natcorp.ox.ac.uk/,访问日期:2020年3月30日。(The British National Corpus,BNC),该语料库中收录了海量的英文文本数据,单词在该语料库中出现的频率可以从一定程度上度量普通阅读者接触该单词的概率与熟悉程度。GECO数据集中共有5037个单词,可以在英国国家语料库中找到对应的词频。
3.2.2 关键词抽取测试数据集
影响人眼动行为的因素十分复杂,为了获取有效的眼动数据,数据采集者会选择句子长度较短、内容更易理解的文本作为采集文本。本文使用的GECO数据集同样符合这些特点,所以在选择用于进行关键词抽取实验的测试数据集时,本文选择了句子长度较短的推特文本作为测试数据集。同时,为了确保实验结果不受特定数据集的影响,本文选择了两个不同来源的推特数据集作为对照组。两个数据集分别名为Daily-Life数据集和Election-Trec数据集[27]。这两个数据集都采集自推特,前者是根据日常生活词汇通过Twitter API抓取的2018年1月至4月的用户推文;后者是TREC 2011比赛中的一个子数据集。这两个数据集与GECO数据集、BNC数据集词汇(不含标点符号)的相关统计如表1所示。
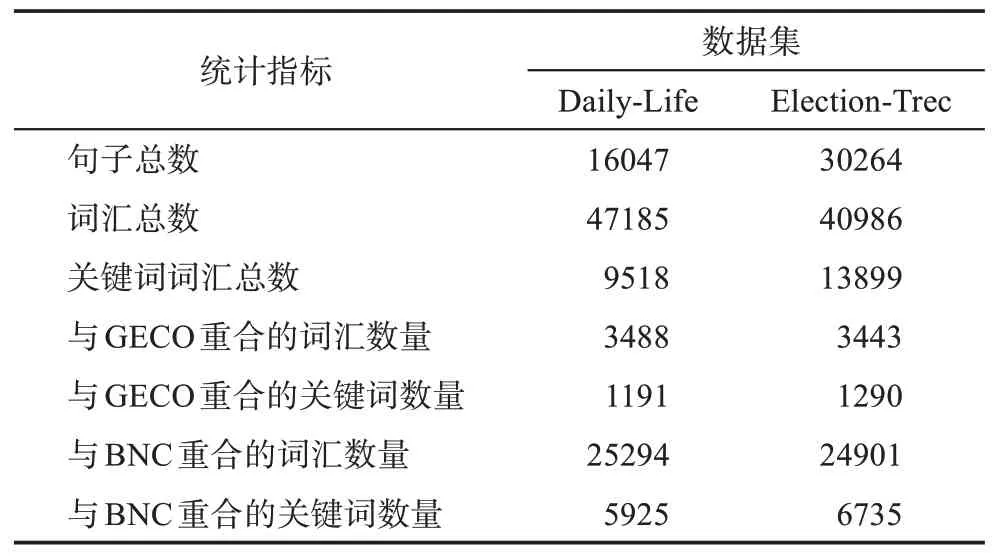
表1 测试数据集词汇统计表
3.3 数据预处理
本文的数据预处理工作主要分为两个部分:第一部分是对推特数据集的非法字符进行替换,并对文本数据进行编码处理;第二个部分是将眼动行为数据处理为眼动特征,并提出眼动数据的扩充方案。
3.3.1 推特数据集预处理
由于本文的测试数据来自推特,其文本的规范性难以得到保证,在推文中掺杂了较多无法识别的字符以及网址。为了得到规范化的文本,本文通过字符的编码判断字符串是否是英文单词,对无法识别的字符串用“UNKNOWN”标签代替,同时使用正则表达式识别推文中的网址并将其以“URL”标签代替。
由于本文使用序列标注模型来解决关键词抽取任务,需要将文本处理成向量的形式,故本文在对文本进行规范化后,对文本以句子为单位进行了独热编码(One-Hot)处理。独热编码的流程大致可以分为三步:第一步,是为文本中所有的单词编号,使每个单词拥有唯一的编号;第二步,是将句子序列中所有的单词以编号表示;第三步,是根据数据集中最长序列的长度为其他序列进行补齐。
3.3.2 眼动数据扩充方案
本文对眼动数据的处理参照了文献[4],单词的眼动特征由归一化后的眼动数值与BNC中归一化后的词频相乘得到,区别在于该研究中使用眼动特征的均值来代替缺失值,而本文采用了眼动数据扩充方案来应对缺失值。
从表1不难看出,GECO与BNC数据集在两个推特数据集上的词汇覆盖情况并不理想,只有不足10%的词汇能够找到对应的眼动数值。如果单纯地以眼动特征的均值来代替缺失值容易衍生出两个关键的问题:一是以均值表示的词汇数量相较于拥有眼动特征的词汇来说更多,这就使得拥有眼动特征的词汇显得更为“特殊”,仅从实验结果来看很难解释究竟是眼动特征发挥了作用,还是因为拥有眼动特征的词汇更为“特殊”,从而使得关键词抽取模型的效果得到了提升;二是过于稀疏的眼动特征会限制其在关键词抽取任务上的作用,影响模型的抽取结果。
为此,本文提出了一个眼动数据扩充方案,该方案的目的是赋予尽可能多的词汇一个近似的眼动特征,以缓解眼动数据稀疏的问题。在该方案中,本文假设单词的眼动数值是与其词形是存在一定程度的关联的,那么该方案的目的是通过单词之间词形上的相似来赋予其一个近似的眼动数值。本文首先取出测试集中无法在GECO数据集或是英国国家语料库中找到对应数值的单词,遍历上述两个数据集中的所有单词,如果该单词为某一单词的子字符串,则认为两者之间存在关联,该单词的眼动数值为所有与其相关联词汇的眼动数据均值。通过这种方式,3432个单词获得了一个近似的眼动数值,302个单词获得了近似的词频,一共有39302个单词至少拥有眼动数值或词频之间的一个值,这个数量远远超过了单纯采用均值的方案。本文将在第4节通过对比实验来说明该方案的有效性。
3.4 眼动特征与文本特征概述
本文需要使用两类特征:第一类特征是来自GECO数据集的眼动特征,目的是探究哪一类眼动行为数据可以更好地度量阅读者的注意力;第二类特征是来自BNC数据集与推特数据集的文本特征,目的是探究眼动特征与文本特征结合后,能否从整体上提升微博关键词抽取任务。本节将分别阐述这两类特征。
3.4.1 通用领域眼动特征
GECO数据集中采集了被试者的多种眼动行为,如被试者注视某个单词的时长、阅读单词的顺序、注视某个单词的次数等。本文选择了其中的初次注视时长、总注视时长和注视次数这三组数据。其中,初次注视时长表示被试者在某个单词上发生注视行为的时间跨度,表示被试者对单词进行初步加工的时间;总注视时长是被测者在某个单词上发生注视行为的时间跨度总和;注视次数表示被测试者在整个阅读过程中,在该单词上发生注视行为的次数。
总注视时长表示被试者在阅读时在该单词上发生注视行为的时长总和,能较好地体现阅读者在整个阅读的过程中消耗在该单词上的注意力,在许多研究[4,26]中均选择了用其来度量阅读者对该单词的注意力。但由于总注视时长容易受到读者个人兴趣等因素的影响,故本文加入了阅读者的初次注视时长数据作为对照组。同时,本文也加入了被试者在单词上发生注视行为的次数,以及由总注视时长与注视次数求得的平均注视时长这两组数据作为对照组。
3.4.2 微博数据文本特征
在文本特征选择方面,本文选择了单词的词性、词长与相对位置特征,这三个特征常被用于关键词的抽取研究中,且能显著地提高模型性能。例如,YAKE中使用了单词的词长、相对位置等特征用于关键词抽取研究[28],而Chen等[29]则在筛选候选关键词时,考虑了单词的词性特征,说明了上述三个特征均是有助于关键词抽取任务的。
单词的词长与相对位置特征的获取并不困难,前者只需统计单词中所包含的字符个数,而后者可以通过单词在句子中的位置除以该句的长度得到。这两个特征都可以直接用一维向量表示,而词性特征则需要进行不同的处理步骤。词性特征来源于BNC数据集,其中共标识了62种不同的词性标记,考虑到英国国家语料库中的词汇并不能完全覆盖测试集中的所有单词,包括“缺失”标签在内共有63种词性标签,故本文使用63维的向量来表示每个单词的词性。
3.5 关键词抽取模型构建
本文使用的关键词抽取模型由两个模块组成,即序列标注模块与注意力机制模块。序列标注模块主要负责对输入序列进行标注,标识出句子中的关键词;注意力机制模块的主要任务是为了引导模型在训练时更关注句子的关键部分。句子的关键部分或者说句子中各个词汇的重要程度则是通过人们在阅读该单词时的眼动行为,即单词的眼动特征来度量的。该模型结构如图2所示。
在序列标注模块中,本文采用了BiLSTM模型。该模型是一种循环神经网络模型,其在训练时会同时考虑文本信息正向与逆向的传递,是关键词抽取任务中较为常见且性能较好的模型。因为BiLSTM是一种序列标模型,所以本文需要将推文转化成模型可以识别的输入与输出序列。目标推文首先经由独热编码后生成形如<Xi,1,Xi,2,…,Xi,|x|>的序列,其中|x|表示推文的长度。本文的目标是在模型中输入该序列,从模型的输出中得到形如<Yi,1,Yi,2,…,Yi,w>的结果,其中,Yi,w表示Xi,w是否表示关键词或关键词组的一部分。
在序列标注模块中,BiLSTM模型的输入由三个部分拼接而成,分别为词向量、字符级词向量以及文本特征。其中,Xi,w表示第i句中的第w个单词所表示的词向量。<…,Xi,w,c-1,Xi,w,c,Xi,w,c+1…>表示单词字符级的序列,是每个单词经由独热编码转换后形成的由字母组成序列,将其通过BiLSTM模型训练得到单词字符级的词向量,Jebbara等[30]已通过实验证明了,将该向量与单词的词向量拼接后,可以有效地提高模型的性能。文本特征为单词的词性、词长与相对位置特征,其中词长与相对位置特征分别转化为一维向量后直接拼接在词向量之后,词性特征则是通过独热编码后生成多维的向量后进行拼接,最终得到模型的输入Vi,wc。
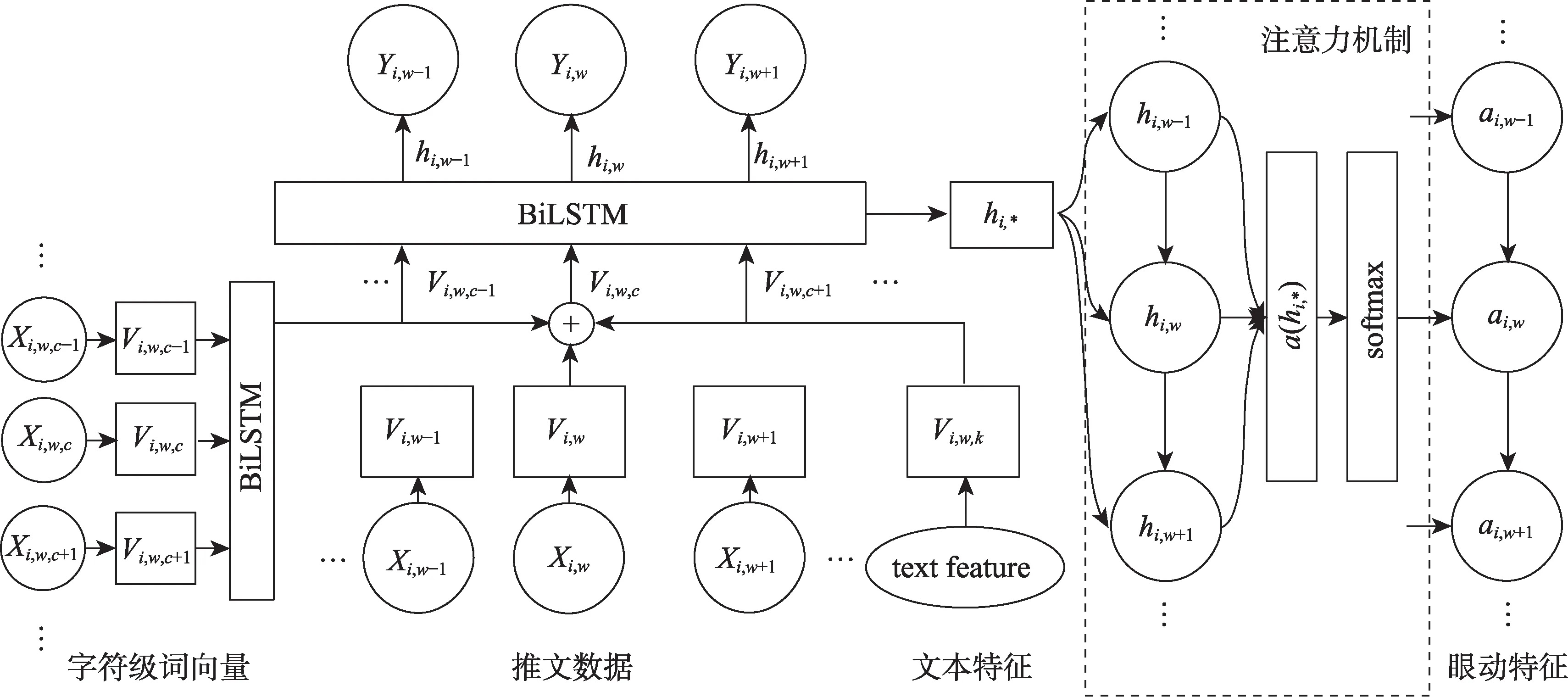
图2 关键词抽取模型结构图
BiLSTM模型可以表示为
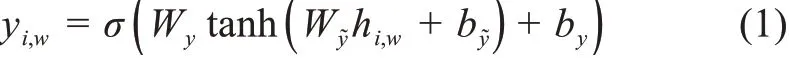
其中,hi,w表示Vi,wc通过BiLSTM层训练后得到的向量;Wy与by则是模型σ(.)通过训练需要学习得到的参数;而Wy~与by~则是tanh(.)训练所得到的。yi,w为最后模型的输出,是一个五维的张量,代表了五种标签,这五种标签分别为
y∈{Single;Begin;Middle;End;Not}
其中,Single标签表示该关键词为单个单词;Begin、Middle、End标签则分别表示关键词词组的起始、中间与结束部分;Not标签表示该单词不属于关键词。
除了序列标注模块之外,本文还引入了注意力机制模块,该模块的主要作用是模拟阅读者阅读时在不同单词上的注意力分布,从而引导模型在进行训练时更关注句子的关键部分。该模块的输入为单词的眼动特征,即本文通过眼动特征来度量阅读者对该单词的注意力强弱。该模块可以表示为
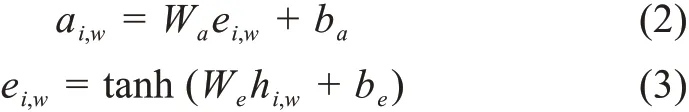
序列标注模块中BiLSTM模型的输出hi,w首先通过激活函数为tanh(·)的全连接层得到ei,w,再将其通过归一化指数函数(Softmax(·))进行归一化后与单词的注意力值ai,w进行拟合。其中,Wa、We、ba、be为模型通过训练得到的参数。因为模型在训练时需要兼顾两个模块的拟合情况,所以本模型的损失函数由两个部分组成,分别为序列标注模块的损失函数
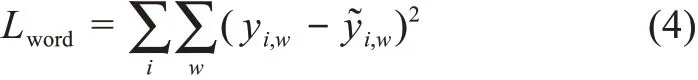
与注意力机制模块的损失函数

其中,yi,w与ai,w表示样本的真实值;而y~i,w与a~i,w表示样本的预测值。该模型整体的损失函数为上述两个损失函数的加权和,λword与λatt分别表示其对应的权重,计算公式为
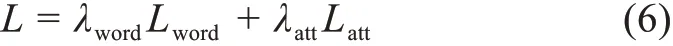
4 眼动数据作用分析
4.1 实验设置与评估方法
本文使用Keras库①https://keras.io/,访问日期:2020年3月30日。对本文使用的关键词抽取模型进行了实现。两个测试数据集均等分为10份,并且以8∶1∶1的比例分别作为训练集、验证集与测试集。模型序列标注模块的参数参照文献[4]设置,BiLSTM层的输出维度为300,字符级词向量的输出维度设置为20,所以每个单词在考虑文本特征的情况下应当由285维的向量表示,其中包括200维预训练得到的词向量、20维的字符级词向量、63维的词性向量、各1维的词长与相对位置向量。需要说明的是,考虑到两个测试数据集的数据规模并不大,直接使用这两个数据集训练得到的词向量并不合适,因此,本文中的词向量参照文献[15],在更大规模的推特数据集上进行训练,并将维度设置为200,该推特数据集中共包含9900万条推文和460万个不同的单词。
此外,本文提出的关键词抽取模型的序列标注模块在训练时所使用的优化器为RMSProp[31],损失函数为交叉熵函数(categorical_cross-entropy),见公式(5),注意力机制模块的损失函数为均方误差(mean squared error),见公式(6),模型的训练轮次设置为5。经过初步的实验,两个损失函数λword与λatt的比例最终确定为6∶4。为了避免实验的偶然性导致的误差,本文中的所有实验均重复5次,取5次实验的均值作为最终的结果。
为了探究眼动特征的作用,本文设置了两个基准模型,这两个基准模型均是BiLSTM模型,区别在于前者仅以词向量与字符级向量作为输入,用于探究在仅加入眼动特征的情况下眼动特征的作用,在图表中以BiLSTM表示;后者以词向量、字符级向量与文本特征为输入,用于探究与文本特征结合后眼动特征的作用,在图表中以BiLSTM+POS+LEN+RP(BPLR)表示。
本节将通过实验结果对眼动数据在推特关键词抽取任务中的作用进行分析,首先需要说明本文所使用的评价指标。本文以关键词抽取结果的F1值作为模型抽取效果的评价指标,该指标由准确率与召回率计算得到,准确率P与召回率R的计算公式为


其中,TP表示预测准确的正例个数;FP表示预测为正例但实际为负例的个数;FN表示预测为负例但实际为正例的个数。F1值的计算公式为

4.2 不同眼动特征的作用分析
为了探究不同的眼动行为数据是否同样可以度量读者对单词的注意力强弱,本文分别将眼动数据集中的总注视时长(total reading time,TRT)、注视次数(number of fixation,FIX)、平均注视时长(average fixation duration,AFT)和初次注视时长(first fixation duration,FFD)处理得到的眼动特征融入关键词抽取模型中。在仅加入眼动特征的情况下,各个对照组的实验结果如表2所示。
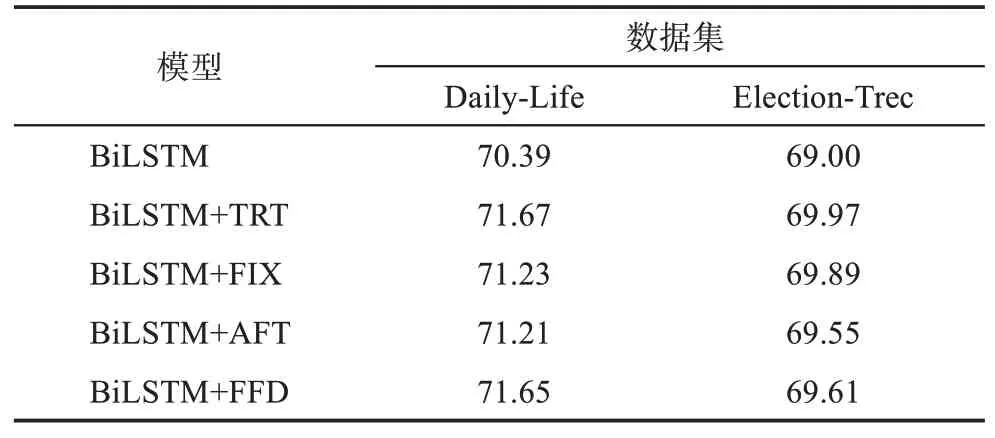
表2 单独加入眼动特征的模型F1值(%)
通过对比表2中各组别的结果,可以得出两个结论:首先,以总注视时长、注视次数、平均注视时长和初次注视时长作为眼动特征加入抽取模型的组别结果均高于基准模型BiLSTM,说明了这四类眼动特征都可以从一定程度上度量读者阅读时在不同词汇上的注意力强弱。其次,从对模型抽取结果的提升幅度来看,使用总注视时长这一眼动特征的组别在两个数据集上均取得了最好的结果,说明了在仅加入眼动特征的情况下,总注视时长相较于其他三类眼动特征来说更有价值。
在理想的情况下,不加入眼动特征的模型对每个单词的注意力应当是相同的,模型在关键词上的注意力应当为关键词个数与句子所包含单词数的比值。相应地,在加入眼动特征的情况下,模型在关键词上的注意力应当为关键词所对应的眼动数值与整句所对应的眼动数值和的比值。如表3所示,本文选取了若干例句加以说明,其中粗体为该句的关键词部分。
在表4中,本文计算了关键词在例句中所占的注意力比值,其计算公式为

表3 推特关键词抽取例句

其中,分子表示句子中关键词所对应的眼动数值的和,分母表示句子中所有单词所对应的眼动数值的和。为了对比在不考虑眼动特征的状态下,关键词在句子所受到的注意力,本文设置了基准组,即将所有单词的眼动数值视为相等的值。
从表4中可以发现,依据眼动特征为单词赋予不同的注意力值,可以使得句子的关键词部分获得更大的权重,从而引导模型在训练时更加关注句子的关键部分,从一定程度上也增强了模型的解释性。
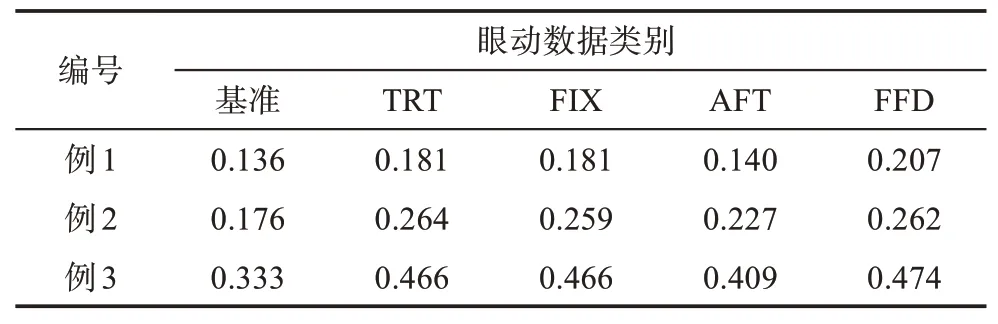
表4 关键词所占注意力比值
4.3 与文本特征结合后的眼动特征作用分析
关键词抽取任务中存在多种有用的特征,而特征之间又会相互影响,想要评价眼动特征在微博关键词抽取整个任务上的作用,仅单独考虑眼动特征是不合理的。因此,本文在关键词抽取模型中加入了单词的词性(part of speech,POS)、词长(length of word,LEN)、相对位置(relative position,RP)等文本特征,用于考察与文本特征结合后的眼动特征作用。本文首先仅在BiLSTM模型中分别加入了各个文本特征,用于探究这三种文本特征为抽取模型带来的提升。仅加入文本特征的关键词抽取实验结果如表5所示。
从表5可以看出上述三种文本特征均能较为显著地提升模型的抽取结果,同时加入三种特征可以最大限度地提升模型的性能,但三种特征的作用机理之间存在一定程度上的重复,从整体上来看其对模型的提升并非简单地累加。在此基础上,本文在关键词抽取模型中同时加入了眼动特征与上述文本特征得到表6。
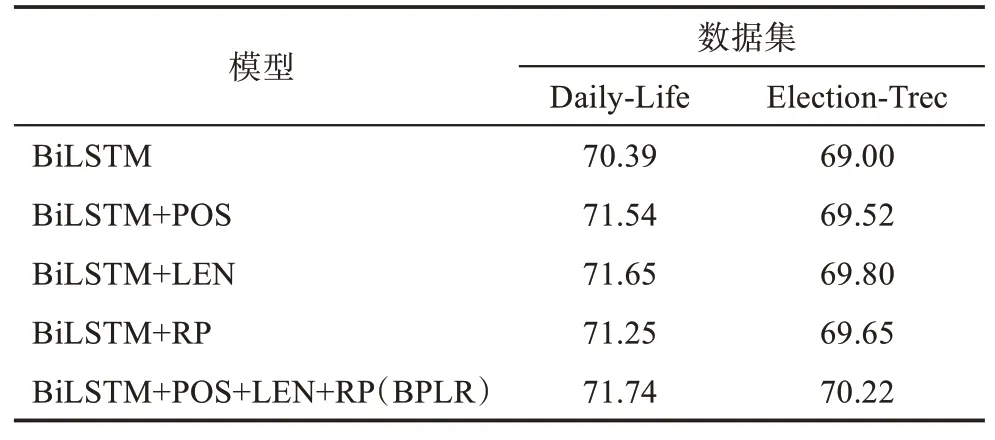
表5 加入文本特征的模型F1值(%)

表6 眼动特征与文本特征结合的模型F1值(%)
为了更加直观地说明文本特征的加入如何影响眼动特征作用的发挥,本文结合了表2、表5与表6的实验结果生成了图3与图4。
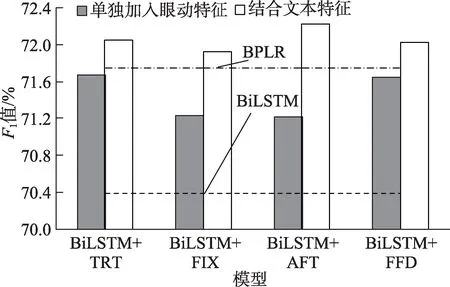
图3 结合文本特征前后眼动特征作用差异图(Daily-Life)

图4 结合文本特征前后眼动特征作用差异图(Election-Trec)
从图3与图4可以看出,将眼动特征与文本特征同时加入模型后,模型的结果均高于只加入文本特征的基准模型,这就说明了眼动特征的确可以从整体上提升微博关键词抽取模型的性能。同时,对比加入文本特征前后眼动特征的作用可以发现,使用总注视时长这一眼动特征的组别的实验结果不再具有优势。相反地,使用平均注视时长这一眼动特征的组别的实验结果,在两个数据集上都有了显著地提升,具体如图5所示。
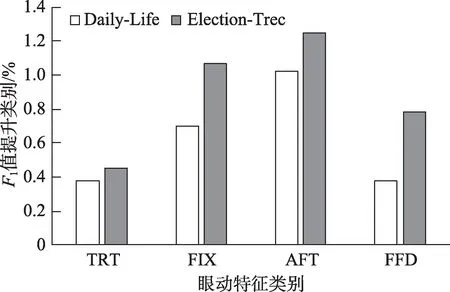
图5 加入文本特征后模型F1值提升数值图
由图5可以看出,相对于其他特征,平均注视时长这一眼动特征在微博关键词抽取任务上的价值更大。单纯考虑眼动特征时,使用平均注视时长的组别表现并不优异,说明该眼动特征中所包含的有效信息并不如其他眼动特征来得多,但是一旦与文本特征结合后,这个缺陷就会被文本特征所弥补。同时,由于其中包含了更多一般的文本特征无法涵盖的信息,平均注视时长这一眼动特征相较于其他眼动特征来说更有价值。
4.4 眼动数据扩充方案的评估
在第3.3.2节中,本文说明了在关键词抽取任务中使用眼动数据时会遇到的眼动数据稀疏的问题,并提出了一个基于词形对眼动数据进行扩充的方案。第4.2节与第4.3节中的实验均是使用了扩充之后的眼动数据。为了更加直观地展示本文所提出的眼动数据扩充方案的效果与必要性,本文使用了未经扩充的眼动数据集作为对照组,其中的数据缺失值以均值代替,实验结果如表7所示。其中,BiLSTM组与BiLSTM+POS+LEN+RP组的模型并不涉及眼动特征,故在扩充前后的结果相同,仅作为基准模型用于比较眼动特征的作用。
为了更加直观地展示对眼动数据进行扩充的必要性,本文分别绘制了图6与图7。
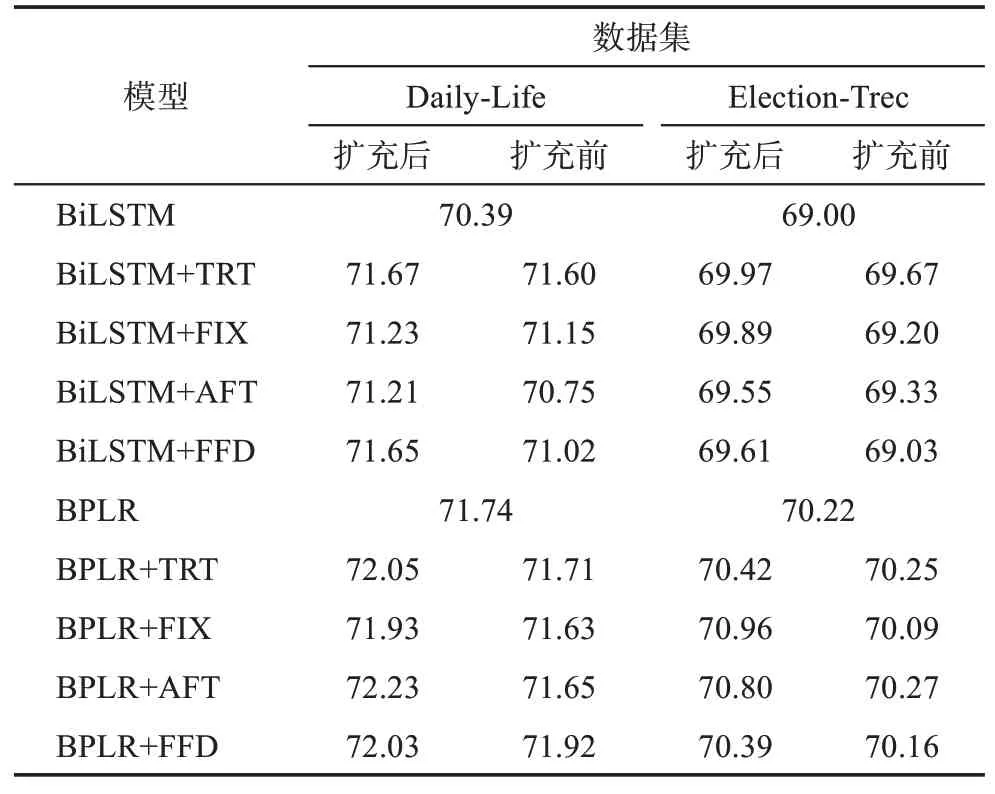
表7 眼动数据扩充前后的模型F1值(%)
从图6与图7可以明显看出,对眼动数据进行扩充可以较为显著地提升模型的抽取效果。对比两个基准模型来看,所有采用扩充后眼动特征的组别结果均高于基准模型,而单纯采用均值策略来处理缺失值的部分组别结果甚至低于基准模型,即过于稀疏的眼动数据甚至起到了相反的作用,这也进一步说明了对眼动数据进行扩充的重要性。同时,由于本文采用的眼动数据扩充方案本质上是基于单词词形上的相似程度对眼动数据进行扩充的,因此,有理由相信字形是影响单词眼动特征的重要因素,这为未来更细致全面的眼动数据扩充方案提供了方向。
综上所述,眼动特征在微博关键词抽取任务中有着较高的价值。总注视时长、注视次数、平均注视时长、初次注视时长等眼动特征均能提高微博关键词抽取模型的性能,只考虑眼动特征时,总注视时长对模型带来的提升效果最为明显,而在结合单词的词性、词长和相对位置等文本特征时,平均注视时长的表现更为优异。同时,眼动数据的稀疏问题是影响眼动特征在微博关键词抽取任务中作用的重要因素,过于稀疏的眼动数据甚至会降低抽取模型的性能,可通过单词词形上的相似程度对眼动数据进行一定程度上的扩充,从而缓解这一现状。
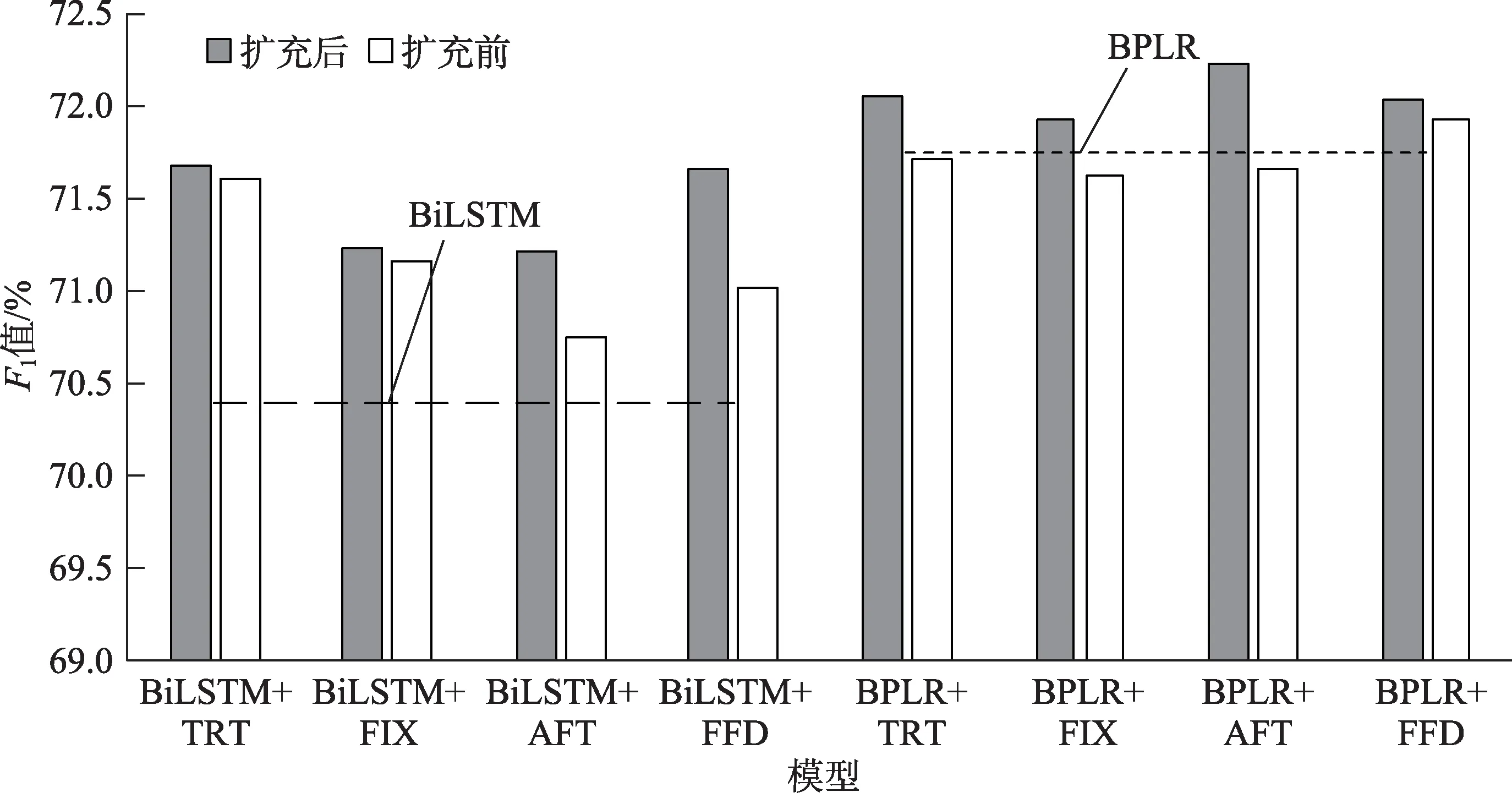
图6 眼动数据扩充前后实验结果图(Daily-Life)
5 结论与展望
现有工作证明了,可以使用眼动数据中被采集者在不同词汇上的总注视时长,来度量其对该词汇的注意力强弱,在关键词抽取模型训练时,引导模型更关注句子的关键部分,从而提升关键词抽取的效果。本文在现有工作的基础上,从眼动特征的选择、眼动特征与文本特征的组合和眼动数据的扩充三个方面,对眼动数据在微博文本关键词抽取任务上的作用进行了更为深入的分析。通过实验发现在仅考虑眼动特征的情况下,总注视时长为微博关键词抽取任务所带来的性能提升最为明显,但将眼动特征与单词的词性、词长与相对位置等文本特征结合使用后,发现平均注视时长的作用得到了显著的提升。同时,本文在研究中注意到,眼动特征的稀疏问题会显著地影响眼动特征作用的发挥,本文通过基于字形的眼动数据扩充方案有效地缓解了这一问题。
在未来,本课题组将针对眼动数据现有的问题进行更为深入的研究。首先,需要解决的是眼动数据的稀疏问题,在现有方案的基础上,将从更多的角度考虑影响眼动数据的因素,并依此来完善眼动数据的扩充方案。其次,本文只采用了单一的眼动行为数据来度量读者对单词的注意力强弱,但在实验中发现,某些眼动特征的效果会随着文本特征的加入发生非常显著地变化,这从另一个角度说明了,单一的眼动行为数据并不能很好地度量读者的注意力强弱,可以尝试将多种特征进行组合,以寻求更好的度量读者注意力的方式。
