面向知识发现的模糊本体融合与推理模型研究
2021-05-26张良韬
陆 泉,刘 婷,张良韬,陈 静
(1.武汉大学信息资源研究中心,武汉430072;2.华中师范大学信息管理学院,武汉430079;3.武汉大学大数据研究院,武汉430072)
1 引言
大数据时代,数据的爆炸性增长让人们对于知识的需求达到前所未有的地步[1],从多源异构的数据中发现新的知识,是人们需要解决的重要问题与挑战。知识发现是指从大量数据中获得有效的、创新的、具有价值性的以及可视化模式的高级处理过程[2]。知识主要分为两类:一类是精确知识,即确认存在的被公认的知识,可以准确的表示某种事物或事物的状态;另一类是不确定知识,即具有模糊性的不确定性知识。目前,存在着大量多源异构的不确定知识,知识融合可以将这些结构多样、不确定的模糊知识转化为统一的知识模式,通过知识推理发现新知识。
本体作为共享概念的形式化规范说明,可以对领域内的知识进行统一的有效表示,是知识融合中的一种主要知识模式。然而,当前相关的本体描述语言,如OWL(ontology web language),以及本体编辑工具,如Protégé,均无法直接实现用于描述和定义模糊本体,因此,研究者通常利用计算机处理人类自然语言的模糊性和人类思维逻辑模糊的推理,最终实现模糊本体的构建。Straccia[3]将描述逻辑和模糊逻辑相结合,提出了一种模糊描述逻辑语言Fuzzy ALC(attributive concept description language with complements)用来描述模糊本体;唐新香等[4]通过构建模糊本体定义元模型FODM(fuzzy ontolo‐gy definition metamodel)以及模糊本体建模语言FOML(fuzzy ontology modeling language),从而创建模糊本体模型。然而,上述方法均具有较高的复杂性,并且其知识的扩展性、融合性和推理性较为局限,无法对大规模多源异构的模糊知识进行知识发现。
药物相互作用是大数据背景下不确定知识发现的典型应用领域。近年来,临床多药物相容已经变得具有普遍性和常规性,药物相互作用也成为临床关注的突出问题[5]。临床研究人员利用数学框架和模型,如PBPK(physiologically based pharmacokinetic)模型[6],通过一系列临床试验来研究药物之间的相互作用。由于临床试验研究所有药物之间的相互作用需要消耗大量资源和时间,信息技术应用于药物相互作用的识别、解释和预测正越来越受到研究者的重视[7]。目前,现有数据库中包含了大量的药物知识数据,如确定已知的药物相互作用,但仍有大量药物之间的相互作用是未知的,需要通过不确定知识发现来有效识别潜在的药物相互作用,以有效规避未知相互作用的用药风险和精准开展临床药物实验。
本文将知识表示为RDF(resource description framework)三元组的形式,将模糊逻辑引入到OWL语言中,并引入概念对和隶属度,基于OWL语言提出一种具备易用性和通用性的模糊本体表现模型。同时,从知识模糊性角度出发,构建面向知识发现的模糊本体与推理模型,并在网络药物知识库中药物相关部分数据的数据集上进行药物相互作用知识发现实验,对药物相互作用进行推理、预测和解释,检验模型的有效性。
2 相关研究
2.1 模糊知识
传统的知识表示模型,对于事物是否具有某种属性是明确的,清晰确定地描述了某种知识。然而,在现实中人们常常面对的是在领域内未知的、不确定的信息,期望从这些信息中完成对事物的认识、分析、推断和预测,并为决策提供支撑。知识的模糊性表现为不确定性[8],例如,明亮、寒冷、坚硬等,这些概念不能简单的用“是”或“否”来进行描述,其本身不是界限分明的,因此,这些概念之间的隶属关系也不是确定清晰、非此即彼的,这就是知识模糊性的一种体现。Zadeh[9]于1965年首次提出模糊集理论,将特征函数的取值范围从{0,1}推广到[0,1]上,并定义一个隶属函数来表达对象对于集合的隶属度,以此来表示决策过程中的不确定或模糊信息。其主要思想是接受模糊知识的存在,并通过简单的模型将其转化为计算机可以识别和处理的信息。由于具有处理不精确和模糊参数的能力,模糊集理论得到了扩展,并在能源、医疗、材料、经济和药理学等新型领域中得到了广泛的应用[10]。Wu等[11]利用模糊集理论能够应对决策过程中评价模型的模糊性,提出了一种基于累积前景理论的模糊多准则决策(multi-criteria decision-making,MCDM),用于选择中国最合适的可再生资源。Gul等[12]考虑到决策环境的模糊性和不确定性,提出了一种通用的模糊多准则决策方法,可以实际应用于材料选择问题。Eghbali-Zarch等[13]将逐步权重评估比率分析(stepwise weight assessment ratio analysis,SWARA)方法与基于模糊多目标优化的模糊多目标优化方法相结合,构建模糊MCDM模型,辅助医生对2型糖尿病患者治疗的药物选择。
2.2 本体知识融合与推理
知识融合的本质是对知识进行融合重组,从众多分布式异构的网络资源获取多源异构、语义多样和动态演化的知识,并将其转换为统一的知识模式并组织成知识库,实现“1+1>2”的效果,发现新知识。本体作为一种知识载体,可以根据分类对齐、属性对齐和实体对齐等完成多源知识的融合。徐赐军等[14]对领域本体中的知识元素进行了关系分析,形成了包含知识集构建、测度指标确定、融合算法设计和融合后处理的知识融合框架,提高了知识的语义相关性和准确度。目前,研究常用基于贝叶斯理论、D-S理论和本体理论的知识融合方法。贝叶斯理论分类错误小,物理概念简明,但是其要求预知先验概率和知识源之间观测相互独立在实际上很难满足,降低了其实用性[15]。D-S理论具有较大的灵活性,可以较好地区分知识不确定和不信任,但是其数学基础欠严谨,并且其运算量随知识源增多而呈指数增长[16]。本体理论直接通过知识源的对齐匹配来实现知识融合,通过设计属性可以较为轻松的表现出知识的不确定性,可以与其他融合方法相结合,提高融合效果。
知识推理,是指在已有知识的基础上,获取某种规则或策略,然后模拟人类推理方式,通过归纳演绎、推理规则等手段,进一步挖掘出隐含知识的过程[17]。本体可以对知识进行表示描述,使其能够更好的被计算机理解,从而实现知识推理。目前,本体知识推理方式多样,主要分为基于规则的推理、基于神经网络的推理以及混合推理等。基于规则的推理运用简单规则或同级特征进行推理,可解释性强、准确率高,但规则不易获得。Jiang等[18]关注于用启发式规则推理不确定和冲突的知识,提出基于马尔可夫逻辑网的去噪、抽取知识。基于神经网络的推理对知识事实元组进行建模,从而实现对其的向量表示,用于进一步的推理,推理能力较强,但是复杂度更高、可解释性较弱。Socher等[19]利用神经张量网络(neural tensor network,NTN)刻画实体间复杂的语义关系,有助于实现知识推理。混合推理可以充分利用不同方法的优势,但缺乏更深层次的混合模式。陆凌云等[20]采用训练后的神经网络模型分配属性权重,同时,提出了一种基于规则的柔性逐层推理方法,有效应用于仿真实验设计方法的智能选择。
2.3 知识发现
知识发现,是一个交叉综合研究领域,是经过数据预处理有效处理错误的、不确定的和不一致的数据,然后选择合适的数据挖掘算法进行挖掘,得到知识并进行评估。知识发现的主要目的是探索领域的新知识,其核心是数据挖掘[21],具体方法包含:机器学习[22]、规则推理[23]、模糊集[24]、粗糙集[25]等。知识发现主要从数据层面、知识层面和系统层面进行研究。①数据层面主要包含知识发现算法研究和知识发现应用研究。Abdelhamid等[26]提出了一种新型MAC(message authentication codes)分类算法,通过减少分类尺寸,有效的提高了分类准确率;Czibula等[27]针对软件维护和演化过程中的缺陷预测问题,提出了基于关联规则挖掘的分类预测算法,可以有效预测识别有缺陷的软件模块。②知识层面主要包含知识融合与知识推理的研究。Fisch等[28]认为,知识融合有数据层、模型层和参数层三种层次,并提出了基于模型层的知识融合框架。本体知识推理可以通过规则或描述逻辑实现,规则是知识的一种表示形式,是一种接近人们对问题描述的方式,基于规则的推理流程通过取决于初始状态和搜索过程,在大多数情况下,这种匹配过程是试错性的[29]。③系统层面主要包含知识发现过程、系统设计和系统使用等方面的研究。在构建知识发现系统之前,首先应该明确整个知识发现过程中“what”——做什么,以及“how”——怎么做的问题[30]。之后,基于此实现知识发现系统的设计与开发,在国外比较典型的商用知识发现系统有SAS公司的Enterprose Miner[31]、IBM公司的Intelligent Miner[32]、SGI公司的Set Miner[33]以及SPSS公司的Clemen‐tine[34]等。在知识发现系统使用过程中,通常会面临数据方面或者使用方面的问题。Perez-Rey等[35]提出了一种基于本体的KDD(knowledge-discovery in databases)自适应联合方法,可以实现数据库集成和检索,增加基于数据库的知识发现效率。
由此可知,现有的关于模糊知识发现的研究主要在于知识融合及推理的方法研究,大多数基于特定领域知识,针对性较强,并且其知识的扩展性、融合性和推理性都较为局限,无法对大规模多源异构的模糊知识进行知识发现。然而,在Web 3.0时代,网络信息资源的复杂多源特性使知识发现需要兼顾不同领域知识的精准性与模糊性差异,当前相关本体描述语言及本体编辑工具均无法直接实现用于描述和定义模糊本体。因此,本文从知识模糊性角度出发,构建包含精确知识和模糊知识的模糊本体,探讨面向知识发现的模糊本体融合与推理模型并进行验证。
3 面向知识发现的模糊本体融合与推理模型构建
本文以多源异构的网络知识库为主要研究对象,提出一种新的模糊本体表示模型。该模型既可以表示精确知识,也可以表示模糊知识,提高知识的复用性和可扩展性,且具备对各领域知识表示的通用性,通过将多源异构的知识转化为统一的知识模式,构建模糊本体。利用知识融合将模糊本体进行融合形成全局本体知识库,构建精确规则和模糊规则,最终通过本体知识推理发现知识。知识发现模型如图1所示。
3.1 模糊本体
模糊本体,即描述了模糊知识的本体,模糊本体的构建需要对事物的不确定性程度进行描述,在本体的形式化构建中增加对模糊概念、模糊关系的语义描述,通过对本体的模糊化扩展同时遵循本体建模基本原则来建立模糊本体[36]。知识的模糊性可以用模糊理论中的隶属度来进行表示,因此,本文对通用领域本体进行扩展,将具有模糊性的概念、属性和关系都通过隶属度来表现,将模糊本体定义为四元组O=<C,A,R,X>,其中,C是概念集,包含了精确概念和模糊概念;A是属性集;R是概念与概念间以及概念与属性间的关系集,包括正常关系和模糊关系;X是公理集,是模糊本体中概念、属性以及关系的约束等。
模糊关系主要体现在隶属度中,通常使用的模糊本体将隶属度与实体直接结合来表示知识的模糊程度。例如,<小明,症状,(咳嗽,0.6)>这样的一个三元组形式来表示患者与咳嗽之间的相关程度,但是在实际应用中,这样的表示方法针对性太强,相当于是把“咳嗽”和“0.6”看作一个整体,在OWL语言中相当于创建一个症状与隶属度相结合的类,表现为一个字符串,导致知识的复用性会降低,并且对于本体知识融合也有较大的局限性。因此,本文通过构建一个概念对的类,可以将组成概念对的类与概念对类相联系起来,同时,构建一个专门描述隶属度的类别,这样模糊关系就可以通过概念对和隶属度来进行描述,其三元组形式为g=<(s1,s2),P,As1(s2)>,表示概念s1和概念s2间的模糊关系,隶属度As1(s2)∈[0,1]刻画了两个概念之间关于模糊关系的相关程度,如上述三元组的例子表示为<(小明,咳嗽),症状,0.6>,同时<小明,组成(小明,咳嗽)>以及<咳嗽,组成,(小明,咳嗽)>,这样在实际应用中既可以了解“小明”或者“咳嗽”的其他属性,也可以清晰表示出其之间的相关性程度,增加了知识的复用性和可扩展性,将精确知识和模糊知识表示在同一本体中。
3.2 模糊本体构建与融合
本研究的模糊本体构建,主要是基于OWL语言构建概念对以及引入隶属度等来实现模糊本体的构建。模糊本体的融合主要流程是实现本体对齐,希望能够链接多个现有的本体知识库,整合领域内不同主体之间的概念和数据,实现概念层属性层的对齐和实体的匹配,并从顶层创建一个大规模的统一的本体知识库,从而帮助计算机理解底层数据。本研究中模糊本体构建与融合框架如图2所示。
数据预处理阶段,原始数据的质量会直接影响到最终对齐的结果,不同的数据集对统一实体的描述方式往往是不相同的,对这些数据进行归一化处理是实现本体对齐的重要步骤。在特征工程中,对数据进行预处理主要进行数据清洗,即处理缺失值、处理重复值、数据标准化、正则化等。根据应用环境和目标选择的不同,有时还会对数据进行属性编码、特征选择、主成分分析等处理。在进行数据预处理之后,通常不同的知识源并没有统一的标准来指定相同属性的表现形式,因此,还需要对数据进行标准化设计,实现语法正规化和数据正规化。

图1 基于模糊本体融合与推理的知识发现模型

图2 模糊本体构建与融合流程框架
3.2.1 模糊本体构建
Bobillo等[37]通过识别模糊本体语言必须面对的语法差异,提出了一种利用OWL2注释属性来表示模糊本体的方法。本文基于OWL语言构建模糊本体,然而OWL语言无法直接对模糊知识进行描述,因此,本文通过构建概念对以及引入隶属度,将模糊知识转换为可以用概念对以及隶属度表示的精确知识,从而实现知识的模糊性表达。模糊本体表现模型如图3所示。
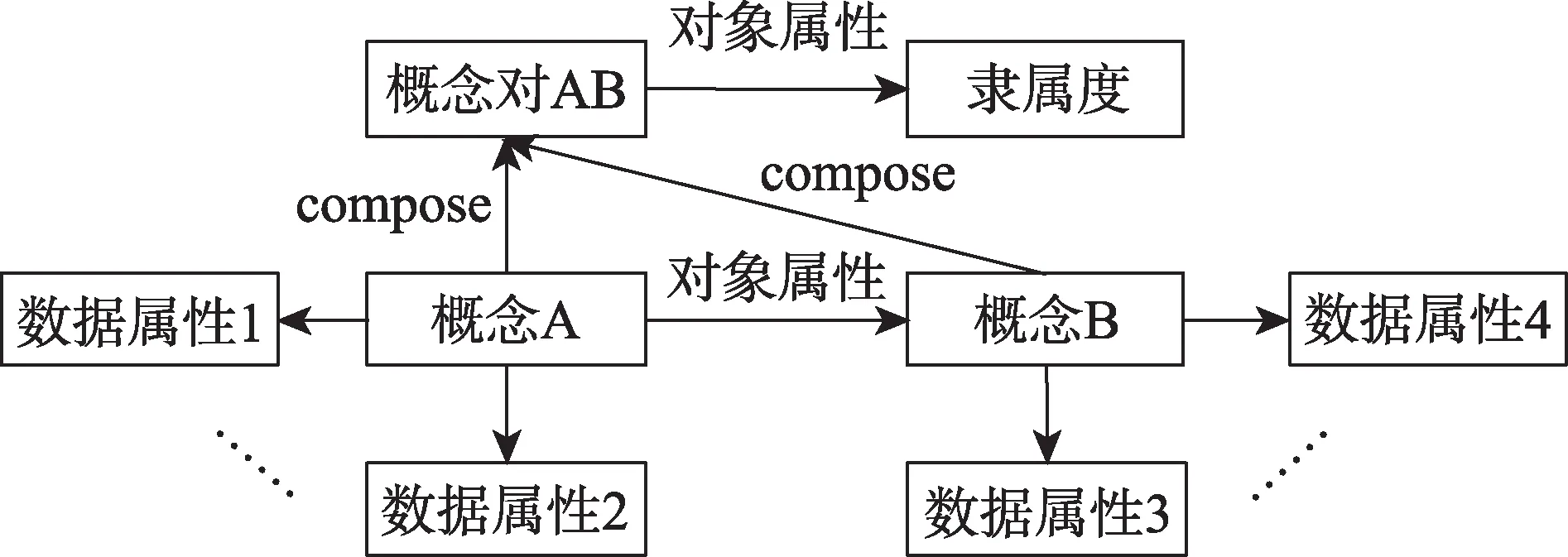
图3 模糊本体表现模型
3.2.2 模糊本体融合
在获取多个本体知识库之后,对其进行本体融合形成全局本体知识库。在本文中,实现本体融合主要采用概念对齐、属性对齐和实体匹配操作,制定融合规则对融合结果进行处理,从而形成全局本体,融合框架如图4所示。

图4 模糊本体融合框架
概念对齐和属性对齐采用自动识别或人工识别方法,了解不同本体知识库中对同一概念、属性的不同描述,挖掘等价概念和等价属性,生成相应的匹配规则,从而实现概念层和属性层的对齐。在完成概念层和属性层的对齐之后,对实体进行匹配。因此,本文面向属性定义较准确的知识库内容,采用基于属性相似度的实体匹配算法,其算法定义流程见下文。
经过OWL语言规范化后,设实体A属性名集合为Propertya={pa1,pa2,…,pam},对应的属性值集合为Valuea={va1,va2,…,vam};实体B属性名集合为Propertyb={pb1,pb2,…,pbn},对应的属性值集合为Valueb={vb1,vb2,…,vbn},其中m、n分别是A、B实体的属性个数。实体A和B的共有属性计算公式为

对于共有属性pi∈Interproperty(A,B),其中Pax=pi并且Pby=pi,实体A的属性Pax对应的属性值为vax,实体B的属性Pby对应的属性值为vby。属性pi的相似度计算公式为

其中,lcs(vax,vby)为实体属性值的最长公共子序列。
实体A和实体B的相似度计算公式为
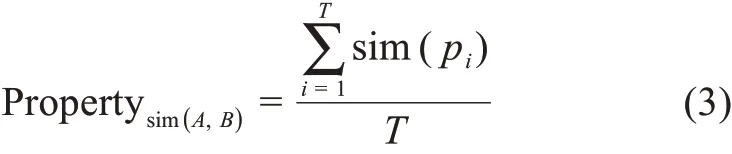
其中,T=|Propertya∩Propertyb|。
在加和所有匹配属性的相似度评分后,获得实体A和实体B的相似度Propertysim(A,B),然后通过设置两个相似度阈值,判断计算结果位于哪个相似度区间,可以形式化表示为

其中,A、B是待匹配的实体对;t1、t2是相似度阈值的下界和上界,这两个值是根据实验结果来调整,没有固定值,并由此对实体对匹配程度进行判断,取值大于等于t2是完全相同,大于等于t1且小于t2时是可能相似,而小于t1则是不相似。
此外,本文模糊本体中引入了概念对和隶属度的形式,通常概念对只有名称和隶属度这两个属性,一个概念对相当于一个字符串,包含了两个实体,本文不考虑复杂因素,仅考虑概念对类中概念名称这一属性,对概念对进行分割排序组合之后,计算概念对的相似度:
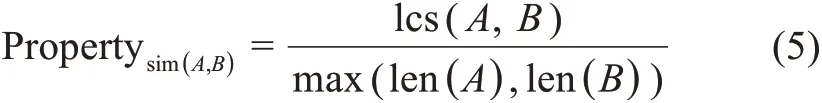
然后再根据相似度阈值对概念对的匹配程度进行判断。
在完成实体匹配后,有时会存在属性值不一致的情况,即不同本体中对同一个实体的属性值描述不一,那么就会给用户反馈不一致的结果,因此,通常需要对所有结果采取融合规则,将其化为一个结果。本文涉及模糊信息,采用隶属度来表示,因此进行融合结果处理时,可以对概念对和隶属度进行扎德算子中的“并”运算,也就是取最大值原则:

3.3 模糊本体知识推理
本文将模糊本体运用到知识推理中,可以实现基于规则的面向模糊知识的知识推理,通过对SWRL(semantic web rule language)规则进行扩展,使其能够表示相应的模糊规则,然后基于推理机完成规则匹配和冲突消解,实现模糊本体知识推理,其知识推理框架如图5所示。
3.3.1 SWRL规则扩展
SWRL是由语义的方式呈现规则的一种语言,其规则部分概念是由RuleML所演变而来,在结合OWL本体论中产生,是为了弥补OWL DL无法表示规则而产生的语言。通过SWRL可以对OWL本体中类间关系、属性间关系、实例间关系以及公理等进行规则扩展,增强本体的逻辑表达能力,使得本体和推理规则能够更好地结合在一起,从而有效的实现基于规则的知识推理[38]。SWRL不仅可以用来表示精确知识的规则,也可以通过扩展表示不确定知识的规则,Pan等[39]对SWRL进行模糊扩展,提出了f-SWRL语言,可以用于表示模糊知识,例如,

但是,f-SWRL语言描述的规则是模糊规则,现在的推理机无法直接对其所描述的模糊规则进行推理,通常需要将f-SWRL规则转换为Prolog规则,OWL本体转换为Prolog语言表示的知识库,才能实现模糊规则的推理。本文引入概念对和隶属度的做法,将隶属度作为概念或概念对中的属性值,由此联立概念、概念对、隶属度,相当于把模糊知识转换为了可以表示模糊性的精确知识,从而避免进行转换,直接通过OWL模糊本体和SWRL语言在推理机中实现知识推理。例如,通过SWRL的内置函数,可以将hasEysDrifting这种作为类的数据属性,将隶属度作为数据属性的值,直接用SWRL语言表示为
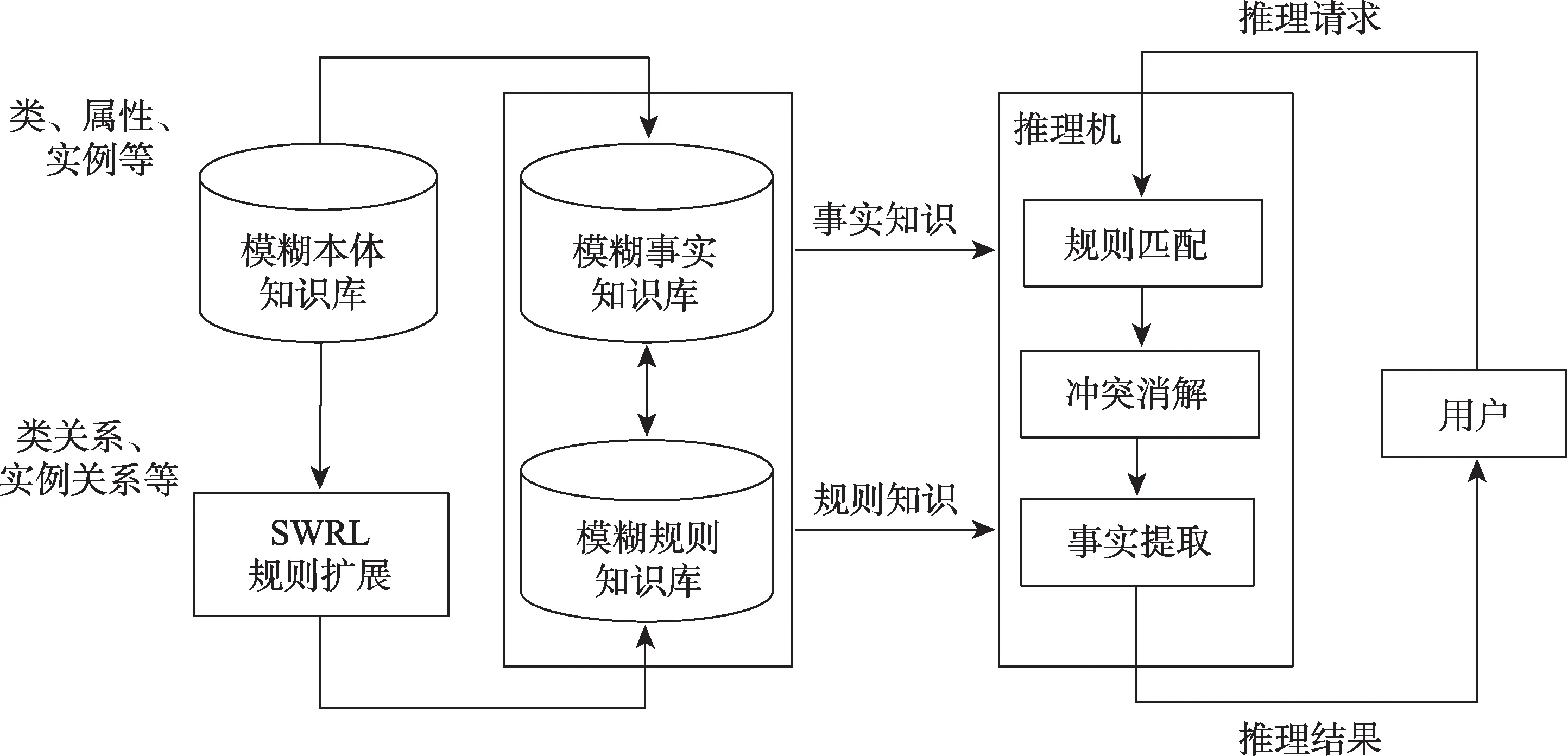
图5 模糊本体知识推理框架

3.3.2 模糊知识推理

本文模糊本体支持精确规则和模糊规则,其基于规则的推理最终可以实现精确知识和模糊知识的发现。精确规则是根据模糊本体中表示精确概念的定义以及其之间的语义关系构建的规则。例如,如果两种药物都作用于同一个靶标,一种对靶标起到抑制作用,一种对靶标起到促进作用,那么两者就具有相互作用,其精确规则可以表示为

模糊规则是根据模糊本体中表示模糊概念的定义以及其之间不确定的语义关系构建的规则,通过隶属度来表示不确定语义关系,将不确定性转换为精确性,同时,引入概念对的形式可以用来表示两个不同实体之间的模糊关系。例如,定义两种药物组成药物对,根据计算后这组药物对发生相互作用的概率大于0.8,则认为这两种药物具有相互作用,其模糊规则可以表示为
SWRL语言只是规则描述语言,其本身并不具备知识推理的能力,因此在进行知识推理的过程中,通常需要将定义好的SWRL规则与推理机相连接,从而实现知识推理。规则匹配过程主要分为两种:正向推理和逆向推理,区别在于前者从已知事实出发,后者从结论入手。根据本文的研究内容,采用正向推理方法执行规则匹配。在匹配过程中,理想的状态是事实只匹配成功一条规则,那么推理机就执行这条规则,但是实际中常常会遇到事实匹配成功多条规则,这种情况就称为规则冲突,这时候就需要进行冲突消解,应用某种策略来决定首先应用哪些规则。
4 模型验证——以药物相互作用为例
药物相互作用主要包含三种作用行为:“Induc‐er”诱导行为、“Inhibitor”抑制行为和“Substrate”底物行为。药物相互作用是药物不良事件的主要原因之一。但是,由于在线数据库中的药物数据可能不完整,例如,某些药物数据可能无法实时更新,导致药物相互作用知识的覆盖是不完善的。考虑到肿瘤及精神卫生疾病高发和并发的重要现实问题,本文选择这两类疾病的相关药物进行实证。根据全球癌症统计报告,全球2018年有1810万恶性肿瘤新发病例以及960万死亡病例,其中接近一半发生在亚洲[40]。2019年我国发布的癌症统计数据显示,2015年我国恶性肿瘤发病人数约为392.9万人,相当于每分钟有7.5万人确诊为恶性肿瘤[41]。而肿瘤疾病患者经常并发精神卫生疾病,如抑郁、焦虑、狂躁等。Mehnert等[42]经临床试验发现,即使按照严格意义上的精神障碍诊断标准,仍有31.8%的癌症患者会出现精神障碍疾病,远高于一般人群的精神障碍发病率。因此,本文利用目前使用广、数据全的药物信息数据库:Drugs[43]以及DrugBank[44]中与肿瘤及精神卫生疾病相关的药物数据,通过本文构建的面向知识发现的模糊本体融合与推理模型进行药物相互作用实验,对药物相互作用进行推理、预测和解释,检验模型的有效性。
4.1 实验数据与预处理
采用爬虫工具爬取Drugs以及DrugBank两个数据库中肿瘤及精神卫生疾病的药物相关部分数据,搜索词为“tumor or mental disease”,包括药物、靶标、转运蛋白、酶、作用行为和相互作用药物对数据,将其转换为结构化药物数据。其中,靶标、转运蛋白、酶、作用行为数据作为发现药物相互作用知识的基础数据,而相互作用药物对数据作为检验数据,与最终模型发现的药物相互作用进行对比检验。采用两个数据库,原因在于可以让数据多源且互为补充,达到验证本文所提出的知识融合方法的可行性以及补充潜在的药物相互作用对的目的。同时,由于Drug数据库中只明确了药物之间的相互作用,而没有明确指出药物所对应的靶标、转运蛋白、酶等基础数据,为设置模糊本体进行融合实验,故将Drugbank数据随机抽取分为两部分数据,最终爬取药物数据如表1所示。

表1 实验数据类型
本文是根据药物相似度以及药物代谢动力学机制(药物代谢动力学机制观点认为,相似的药物可能作用于相似的蛋白质,此外靶标也是发现药物相互作用知识的考虑因素之一,故具有相似靶标的药物更有可能具有相同的药代学机制,如果两种药物作用于同一转运蛋白或者酶,那么两者就有可能发生相互作用)来发现药物相互作用知识,因此,需要对基础数据进行进一步处理,即基于靶标计算药物之间的相似度。本文使用余弦相似性来计算药物之间的相似度,首先构建药物-靶标的作用矩阵,其中横坐标代表药物,纵坐标代表靶标,这样药物X的作用靶标可以表示为向量VX=(v1,1,v1,2,v1,3,…,v1,m),药物Y的作用靶标可以表示为向量VY=(v2,1,v2,2,v2,3,…,v2,m)。如果靶标Ti是药物X的靶标,那么使得v1,i=1;否则v1,i=0。那么药物X与药物Y的相似度可以表示为

4.2 药物相互作用模糊本体构建
为了实现药物相互作用知识发现的目的,基于药代学药物相互作用机制以及药物相似度机制,本文构建了4个概念类、1个概念对类和6个对象属性。其中,概念类分别为:“drug”药物类、“en‐zyme”酶类、“transporter”转运蛋白类、“lsd”隶属度类;概念对类分别为:“drug_drug”药物-药物对类;对象属性分别为:“inducer”诱导关系、“in‐hibitor”抑制关系、“substrate”底物关系、“similar‐ity”相似关系、“interact”相互作用关系、“com‐pose”组成关系。概念以及概念间关系如图6所示。

图6 药代学药物相互作用模糊本体结构
在构建好本体框架之后,将结构化数据转化为RDF三元组的形式,获取对应于同一数据源的多个RDF三元组文件,将其扩展为OWL本体描述语言,对其进行OWL序列化扩展,实现模糊本体的构建。根据OWL描述语言的类、属性以及个体语法类型,完成从RDF三元组到OWL描述语言的转换,最终结果输出为一个OWL本体文件,即最终获得的模糊本体知识库。
4.3 药物相互作用模糊本体融合与推理
在构建好模糊本体之后,采用基于属性相似度的实体匹配算法。由于医药领域知识的严谨性,直接对药物名称进行相似度计算,设定相似度阈值为1,表明完全一样才是同一实体。同时,在融合后处理阶段对模糊属性(即药物相似度)采用扎德“并”运算,完成对来自两个知识源知识的集成与融合。基于药代学机制发现药物相互作用知识,Boyce等[45]使用一阶逻辑(first order logic,FOL)来描述药代学药物-药物相互作用;Herrero-Zazo等[46]基于SWRL创建规则来表示药物相互作用机制,并推断出新的可能的药物相互作用;Moitra等[47]创建了一套规则来表示一种药物如何根据药代动力学改变另一种药物的代谢。
因此,本文基于药代学机制构建药物相互作用精确推理规则。药代学机制规则属于精确规则,即如果两种药物作用于同一酶或者转运蛋白,如药物X对酶Z起到抑制作用,而药物Y对酶Z起到底物作用,那么药物X可能会抑制药物Y产生作用,即药物X和药物Y发生了相互作用。本文基于药代学的药物相互作用机制,采用Preissner等[48]研究中的五条基本规则。药物相似度规则属于模糊规则,即判断当两种药物相似度大于某种阈值时,认为这两种药物可能作用于同一个酶或者转运蛋白,如药物X对酶Z起到抑制作用,如果药物Y在现有知识中没有确认其与酶Z有作用,且药物Y与药物X相似度达到阈值,那么认为药物Y也可能对酶Z起到抑制作用。在构建好推理规则之后,通过推理机完成知识推理,从而实现药物相互作用知识发现,最后将发现的药物相互作用知识与检验数据中存在的药物相互作用进行对比评价,完成实验。
4.4 药物相互作用知识发现结果分析
本文综合考虑了药物相似度机制和药物代谢动力学机制,因此将药物相似度作为阈值,发现在某个阈值条件下推理得出的药物相互作用知识,即在模糊规则中设定swrlb:greaterThan(?l,阈值),当药物相似度大于此阈值时,认为后续推理结果成立,即药物对酶或转运蛋白的某种行为成立,再根据精确规则(即药代学机制规则)推理发现药物相互作用,实验结果各指标曲线如图7所示。
从图7可以看出,随着相似度阈值的降低,召回率逐渐增高,准确率逐渐降低。在相似度阈值为0.55时,取得较高召回率的同时准确率也趋于平滑,此时召回率为79.98%,准确率为37.84%。当相似度阈值为0.20及以后时,获得最高召回率89.94%且趋于平缓。即根据目前实验现有药物相互作用数据中,模型通过结合模糊规则和精确规则可以发现最高89.94%的药物相互作用,由此可以看出,本文构建的模型可以有效发现药物相互作用知识。
由于本研究是从药物代谢动力学机制出发发现药物相互作用,而在实际中药物相互作用以及其潜在机制涉及了复杂的药理学过程,因此,本文主要使用召回率作为模型的评价指标。同时,数据库没有保持最新的更新以及可能有更多的药物相互作用还未发现,导致无法证明推理得知的不在检验样本中的相互作用药物对是否真的不存在药物相互作用。除此之外,药物相互作用知识发现这类任务下,更重要的是在快速缩小可能性范围时不漏过药物相关的潜在知识,在这类任务下提高召回率有效揭示了新知识,因此,本文主要使用召回率作为模型的评价指标。相比较于以往基于本体推理的药代学药物相互作用发现研究,本文的召回率有大幅度的提升,如Herrero-Zazo等[46]构造一个药物相互作用本体,解决了因药物动力学机制和药效学不同类型机制导致的药物相互作用的表示,但是其药物相似度预测的召回率只有27%。本文结合药代学精确规则和药物相似度作用模糊规则进行药物相互作用实验,为发现药物相互作用提供了一个新的思路,且召回率最高可达到89.94%。具有高准确率的数据挖掘方法来预测药物相互作用,如支持向量机[49]、文本挖掘[50]等则因为缺乏对药物相似度的解释而未实现应用。本研究提出的面向知识发现的模糊本体融合与推理模型不仅能够很好地解释药物相互作用的机理,而且还提高了召回率,是对药物相互作用知识发现的有效提升。根据实验结果,研究者可以有针对性、目的性地进行临床试验,发现两种药物是否具有药物相互作用,有助于节省资源避免盲目发现。
从该实验可以看出,本文提出的模糊本体表现模型可以直接通过OWL语言来表示精确知识和模糊知识,通过SWRL语言同时表示精确规则和模糊规则,并在推理机中完成精确推理和模糊推理,无需进行本体语言扩展和模糊规则转换。本文通过概念对和隶属度相结合的形式可以有效将模糊知识转换为精确知识,将模糊规则转换为精确规则,完成本体的融合与推理,从而发现知识,并且具备一定的可解释性。因此,本文模型适用于本体表示精确知识和模糊知识,并进行本体知识融合与推理,可以极大的简化对模糊知识的表示和处理,方便构建模糊规则,并实现推理机上的推理,对知识发现具备很好的辅助作用。

图7 药物相互作用知识发现实验结果指标曲线
5 结语
目前,Web 2.0时代正向关联数据所形成的Web 3.0时代过渡,知识发现过程和模型也随之发生变化。网络上存在着大量的多源异构知识,由于客观环境的复杂性,知识往往兼具精确性与不确定性。而本体作为一种形式化的、对于共享概念体系的明确而又详细的说明,可以有效的对知识进行表述,可以在知识发现过程中为用户提供支持。因此,本文在知识发现相关研究的基础上,提出面向知识发现的模糊本体融合与推理模型,模糊本体为知识表示形式,融合与推理为知识发现方法。通过对多源异构知识进行数据抽取,数据清洗等预处理手段,构建模糊本体,采用基于本体的知识融合方法将来自多个知识源构建而成的模糊本体进行融合,形成一个全新的模糊本体知识库,然后通过推理规则的手段实现知识发现,最终通过实验验证模型的有效性。
本文的主要贡献在于:①从理论层面上来看,基于OWL语言提出了一种新的模糊本体表现模型,在本体描述语言中引入概念对以及隶属度,通过联立概念、概念对、隶属度可以清楚的表示概念或概念间的不确定程度,既可以表示精确知识也可以表示模糊知识,提高知识的复用性以及可扩展性,且具备对各领域知识表示的通用性,使其在本体融合与推理过程中都具有简易处理的能力。同时,本文提出了面向知识发现的模糊本体融合与推理模型,提出了构建RDF三元组的算法,并基于SWRL语言构建了精确规则和模糊规则,具备发现精确知识和不确定知识的能力,有助于构建更为全面的知识发现体系。②从实际层面上来看,本文实验部分结合了药物相似度机制和药代学作用机制发现药物相互作用,将药物相似度机制作为模糊规则,药代学作用机制作为精确规则,结合两类规则通过本文提出的模糊本体融合与推理模型完成药物相互作用知识发现,在药代学的基础上为发现药物相互作用知识提供了一种新的思路。
本文将互联网多源异构的数据转换为同一知识模式即模糊本体,然后将其融合转换为更为全面的模糊本体知识库,并进一步进行知识推理从而实现知识发现,这对面向Web 3.0时代的知识发现有一定的启发作用。但本文构建的面向知识发现的模糊本体融合与推理模型仍有不足,主要在于不确定知识发现领域中除了模糊知识以外,还存在一种知识形态——粗糙知识,本文仅考虑了模糊知识,需要对粗糙知识进行进一步的研究,结合粗糙性和模糊性,考虑其在本体中的表现形式以及融合推理过程中的处理,完善本文模型内容。同时,本文在基于本体的知识融合时,采用的基于属性相似度的实体对齐算法仅能针对同一语言的知识进行融合,对于跨语言的知识不能适用,因此,需要对算法进行进一步的改进,尝试着从跨语言方面进行知识融合。
