一种德州扑克博弈的决策模型
2021-05-25彭丽蓉
李 轶,彭丽蓉,杜 松,伍 帆,王 森
(1.重庆理工大学两江人工智能学院,重庆 401135;2.重庆工业职业技术学院大数据与人工智能学院,重庆 401120)
0 引言
机器博弈在人工智能领域一直具有重要的研究价值[1],根据博弈信息的可知程度,可将其分为完备信息博弈和非完备信息博弈。完备信息博弈是指博弈各方在决策时都完全了解曾经发生的所有博弈信息,例如围棋、象棋和六子棋等;非完备信息博弈是指博弈各方仅能获取部分信息,无法获得对方所有信息,例如军旗或德州扑克,非完备信息博弈的难点就在于此。在完备信息博弈中,极大极小值算法[2]获得了巨大成功,而在非完备信息博弈中,由于无法得知部分信息,极大极小值中所需的对状态的评估过程便无法直接进行,也难以推测对手后续动作,因而使原有博弈算法不能直接应用于非完备信息博弈中。机器学习中的强化学习算法[3]为非完备信息博弈提供了新思路。因此,本文提出一种德州扑克决策模型ACP,并在训练过程中融入先验知识,以提高模型训练效率。将强化学习应用于非完备信息博弈中,是对计算机博弈方法的一次新的探索与尝试。
1 相关工作
德州扑克的主要研究方法大多是基于博弈论(gametheoretic)或基于知识(knowledge-based)构建的。其中基于博弈论的方法简单来说就是搜索纳什均衡点,德州扑克有很多不同的牌型组合,有限制双人德州扑克的信息集数量便达到了3.19×1014。两人、三人及多人德州扑克存在博弈树规模巨大的问题。针对该问题有两种解决办法:①蒙特卡洛树搜索。不用对博弈树进行全部搜索,通过牺牲较小的精确度可获得巨大的性能提升;②牌型抽象化。将博弈过程划分为两部分:第一部分包括翻牌前、翻牌和转牌3个阶段,第二部分为河牌阶段,如果通过胜率进行抽象化,就可采用整数规划和状态空间算法。如文献[4]使用平滑区间UCT 搜索(Smooth UCT Search)算法,可达到近似纳什均衡点。然而,基于博弈论的方法存在的主要问题为:在如此巨大的状态空间中求解纳什均衡需要消耗大量计算资源,同时使用纳什均衡策略只能保证自己不输,因此其期望收益往往很低,在具体博弈场景中实现难度较大。基于知识的方法主要通过记录职业选手比赛数据,从相关数据中提取出打牌策略[5],通常可采取穷举法估算手牌牌力,但穷举法存在计算量太大的缺陷。蒙特卡洛搜索能解决计算量大的问题,如文献[6]提出在德州扑克博弈系统中使用强化学习技术,采用蒙特卡洛模拟方法计算胜率作为近似的值函数回报;文献[7]提出采用基于专家知识的方法建立博弈系统,对职业比赛数据进行特征提取分析,具体特征包括对手下注列表、潜力等。但是,基于知识的方法缺乏比赛数据是德州扑克研究面临的普遍问题。在数据缺乏的情况下,关键在于如何获得可靠的先验知识以及如何使用先验知识解决策略梯度的收敛问题。为此,本文引入一种德州扑克决策模型ACP,以期解决以上问题。
2 德州扑克决策模型ACP
本文根据强化学习框架[8]建立一种德州扑克决策模型ACP。AC 算法包括Actor 网络和Critic 网络两部分,其中Actor 采用基于策略梯度的Reinforce 算法[9]。参数更新公式为:
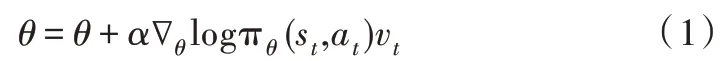
式中,πθ(st,at)表示t 时刻的一种策略,α是学习率,vt、st、at分别表示在t 时刻的奖励、状态与动作,参数为θ。在ACP 模型中,Critic 加入先验知识,即首先通过有监督学习预训练网络参数,然后在自博弈中实时存储对战数据,再结合已有数据形成系统的知识库,最后通过损失函数更新整个神经网络[10]。
整个德州扑克决策模型包含4 个模块:卷积神经网络模块、预测胜率模块、强化学习模块、损失函数模块。决策模型结构与网络结构如图1、图2 所示。

Fig.1 The structure of ACP model图1 ACP 模型结构
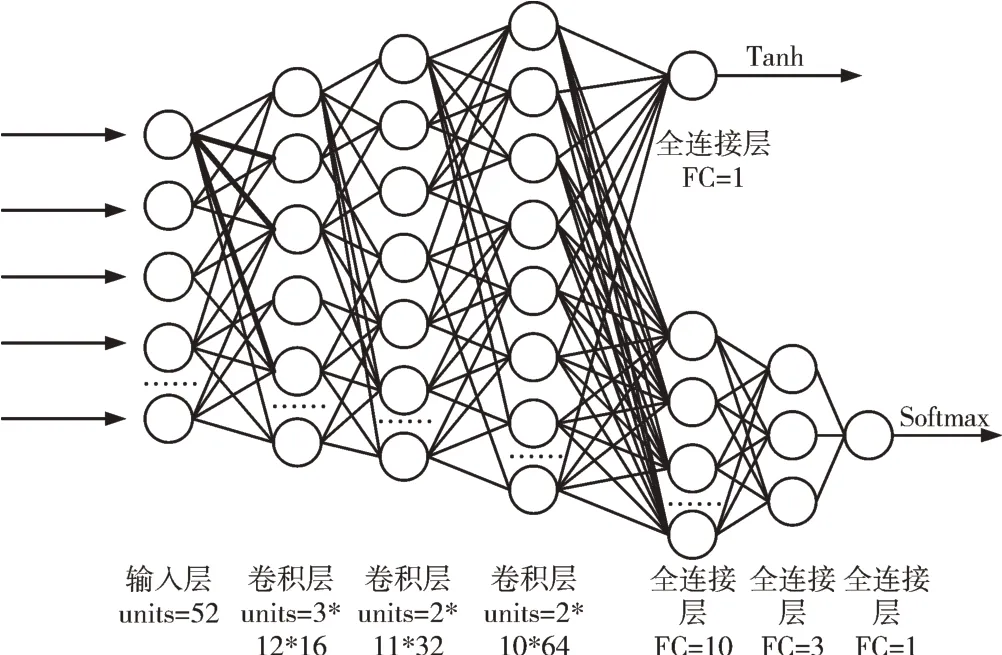
Fig.2 The structure of network图2 网络结构
2.1 卷积神经网络模块
德州扑克需要52 张牌(王牌除外),本文将52 张牌用一个4*13 的0、1 矩阵表示。该模块的输入为4*13*1 的矩阵,4 表示高度(height),13 表示宽度(width),1 表示通道数(filters),中间设置3 个卷积层,卷积核为3*3,步长为1,通道数分别为16、32、64,提取特征得到一个4*13*64 的矩阵。
2.2 预测胜率模块
提取特征得到矩阵4*13*64,通过压缩层(Flatten)转换为1*3 382 的一维数组,再通过激活函数tanh 输出胜率,胜率值在(-1,1)之间。
2.3 强化学习模块
将特征提取得到的数据通过3 个全连接神经网络,神经元个数分别为10、3、1。要注意在第3 层网络,数据经过一次转置才能得到想要的输出形式。通过第1 层网络得到4*10 的矩阵,第2 层网络得到4*3 的矩阵,第3 层网络得到3*4 的矩阵,第4 层网络得到3*1 的矩阵,再通过soft⁃max 分类器输出一个动作,用3*1 的矩阵表示。将该动作输入环境,胜输出1,负输出0,最后将胜负结果输入损失函数。
2.4 损失函数模块
该模型采用的损失函数为KL 散度(Kullback-Leibler divergence)与交叉熵(Cross Entropy)之和,如式(2)所示。
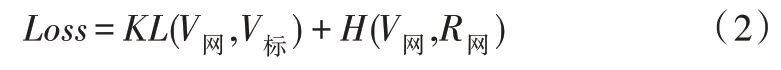
式中,V网表示网络预测胜率,R网表示动作胜率,V标表示实际胜率,损失函数中包含数据库,数据库记录获胜的牌型和牌型胜率,产生实际胜率。V网对应q(xi),V标、R网对应p(xi),KL(V网,V标)能够提高预测胜率与实际胜率的相似度,H(V网,R网)能够提高动作胜率与预测胜率的相似度。
交叉熵能够通过判断不同信息源之间的两两相交程度确定相互支持度,并依据相互支持度确定信息源权重。相互支持度越高,所占权重越大[11]。在离散情况下,具体公式为:
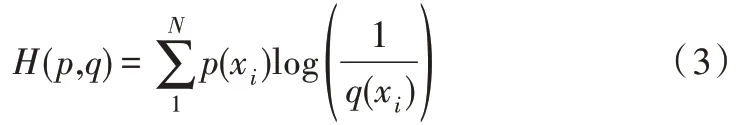
其中,p(xi)、q(xi)表示概率矢量,交叉熵表示概率p(xi)与q(xi)之间的距离,即两概率分布之间的接近程度。
KL 散度用来度量两个概率分布的相似程度,可以衡量两个随机分布之间的距离。当两个随机分布相同时,其相对熵为零。当两个随机分布的差别增大时,其相对熵也会增大[12],如式(4)所示。

3 实验结果与分析
3.1 实验设计
数据来源:ACPC(http://www.computerpokercompetition.org/downloads/competitions/)、中国大学生计算机博弈大赛(http://computergames.caai.cn/download.html)以及ACP 模型自我对战产生的数据。
3.1.1 数据预处理
提取胜率和牌型数据进行预处理:
(1)按行读取,提取每一小局比赛数据,如手牌和公共牌:QsJd|9sKd|Qd6hTc/Ks/Qc 。
(2)根据“/”划分出每个阶段,将手牌、公共牌分别存入一个数组。
(3)循环每个阶段:①读取时默认从小盲位开始,并对变量赋值,小盲赋值为1,否则为0;②对阶段变量赋值,如flop 阶段={1 0 0},turn 阶段={010},river 阶段={001};③读取对应阶段公共牌,存在A、K、Q 则相应变量赋值为1,否则为0;④判断是否有2 张相同牌值出现,出现一对牌时相应变量赋值为1,否则为0;⑤判断是否存在3 张牌值相同的牌,参考步骤④;⑥A、K、Q 在公共牌中出现的次数统计,参考步骤④;⑦统计花色相同的牌数量,参考步骤④。
(4)存储处理得到的数据到表中。
3.1.2 实验流程
(1)打牌程序生成2 个手牌,随机输出公告牌(从flop阶段开始记录),然后输出胜负结果,将手牌信息及胜率记录到表中。
(2)使用表中数据预训练网络参数。
(3)将完全相同的两个模型相互对弈,一个更新参数,一个不更新参数。训练一定局数后,将更新模型的参数复制给不更新的模型,再进行对弈。通过模型间不断的参数交替,反复对弈,得到最终版本。
(4)将模型最终版本与其他3 个版本进行对弈,得出结果。
3.2 损失函数收敛对比
图3 为普通PG 模型损失函数走势图,该模型采用与ACP 模型类似的网络结构,但不融入先验知识。PG 模型和ACP 模型训练100 000 局,PG 模型损失函数值在2.25~2.26 之间振荡幅度较大,随着训练局数的增加,损失函数也没有明显的收敛趋势,模型在没有先验知识的指导下,收敛性较差。图4 中ACP 模型的损失函数值在10 000 局后呈现较明显的收敛趋势,振荡幅度减小。因此,融入先验知识的ACP 模型具有更好的收敛性。

Fig.3 Trend of PG model loss function图3 PG 模型损失函数走势

Fig.4 Trend of ACP model loss function图4 ACP 模型损失函数走势
3.3 ACP 模型与其训练版本对比
图5 为ACP 模型自博弈训练最终版本与其它3 个版本智能体分别对弈5 000 局的平均收益对比图(平均收益=当前赢得的总筹码÷当前完成局数),版本1 为一个只会跟注、不会弃牌的扑克智能体,版本2 是单纯根据胜率决策的智能体,版本3 是采用ACP 模型自博弈训练了100 000局后的智能体。随着训练局数的增加,ACP 模型在先验知识的指导下,通过损失函数不断更新神经网络,决策胜率也逐步提高。实验结果表明,ACP 模型最终版本与其他3个版本相比具有一定优势,但不能保证持续获得更大的收益。

Fig.5 The game benefits result of ACP model vs 3 agents图5 ACP 模型与其他3 个版本对局收益情况
4 结语
本文从基于知识和基于博弈论两个方面简单介绍了德州扑克的主要决策方法,并根据强化学习框架设计了一种德州扑克决策模型。该模型采用AC 算法,融入了先验知识,一定程度上提高了强化学习算法的收敛速度。该模型与其他3 个版本对局时有较好表现,缺点是ACP 模型的决策不能针对特定对手获得极限收益。此外,该模型存在高方差、收敛速度慢等缺陷。因此,如何将A3C 算法运用于该模型中,对网络参数进行分布式训练,同时提高训练效率,是后续研究重点。
