基于深度学习的面部动作检测
2021-05-25杜虓龙余华平
杜虓龙,余华平
(长江大学计算机科学学院,湖北荆州 434023)
0 引言
随着汽车的普及,行车安全问题逐渐进入了大家的视野。2019 年,全国共发生道路交通事故238 351 起,造成67 759 人死亡、275 125 人受伤,直接财产损失9.1 亿元,其中21% 是疲劳驾驶导致的车祸,可见疲劳驾驶是导致车祸的重要因素[1]。近年来,通过机器学习对驾驶人进行自动判断并且作出反应的智能系统变成了研究的主流,主要研究内容便是对驾驶人的违规驾车行为进行判断,如未佩戴安全带、开车时抽烟、接电话、注意力不集中和疲劳驾驶等问题。
目前,国内对于该领域的研究主要存在于高校,国外对于违规驾驶的研究主要集中在大学与科研院所。例如美国研制的瞌睡预警系统,该系统根据PECLOS 算法[2]对驾驶员进行疲劳判断,而PECLOS 算法如今也是最常用的疲劳检测算法。此外,还有利用红外获取人类眼球特征[3],再对驾驶员的眼球状态进行检测以判断是否为疲劳驾驶方法等。这些方法的基础是人面部动作识别[4]。图像识别[5]算法有许多,当前面部动作识别领域最常用的技术之一是卷积神经网络(Convolutional Neural Networks,CNN)[6],但是传统卷积神经网络存在识别速度慢、识别流畅度低等缺点;还有YOLO3[7]算法,使用YOLO3 算法识别物体不仅速度快,准确率也很高,不过对于面部识别而言并不太适合;利用脑电传感器检测面部动作表情的研究[8],虽然可以实现高精度的面部动作分类,但是实现过程相对复杂,资源消耗较高,无法快速普及。
鉴于此,本文在单一CNN 网络基础上,增加了一个多任务卷积神经网络(Multi-Task Convolutional Neural Net⁃work,MTCNN)。MTCNN 主要进行对象的面部识别,CNN网络主要进行对象的面部动作识别,二者结合弥补了识别速度与流畅度低等缺点,并且使用简单、资源消耗少。
1 设计原理
1.1 卷积神经网络(CNN)
卷积神经网络的观点雏形由Wiesel &Hubell 于1962年提出,他们通过对生物学的研究首先提出了感受野的观点[9]。1980 年,日本学者Fukushima 在感受野的基础上提出了神经认知机观点,该观点可以认为是卷积神经网络的第一版。最终在1998 年,卷积神经网络的第一个网络,即LeNet5 网络[10-13]被提出,并且成功应用于文字手写识别,这使得卷积神经网络在此类领域逐渐得以发展。
卷积神经网络主要分为4 个部分,分别为输入层、卷积层、全连接层和输出层[14]。网络结构如图1 所示。
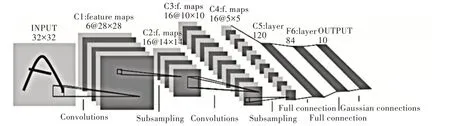
Fig.1 Network structure图1 网络结构
由图1 可以看出,一个待识别的图片输入到网络中,通过第一次卷积生成了第一个特征地图(Feature Maps),再通过池化(Pooling)和激活函数激活后进入第二层卷积,以此类推。在卷积过程结束后会进入到全连接过程,全连接层后便是输出层,将悬链好的特征进行输出[15]。接下来对卷积层和全连接层进行详细介绍。
卷积层的工作就是将图片中的特征提取出来。输入的图片会被转化为计算机可识别的矩阵,然后卷积核(ker⁃nel)会对该矩阵进行滑动计算生成一个新的矩阵,新的矩阵便是一个特征,每一个卷积核在滑动计算完毕后都会生成一个特征地图,生成的每个特征地图又会进入下一层的卷积层与下一层的卷积核进行卷积操作。卷积工作过程如图2 所示。
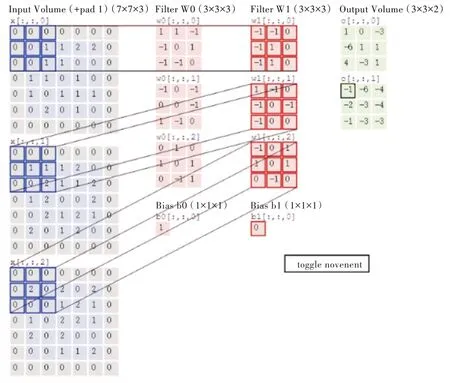
Fig.2 Convolution working process图2 卷积工作过程
在生成了特征地图后还需要进行池化和激活操作,由于特征地图的数据较大,在处理复杂或者庞大的数据时会耗费计算机性能,而且也会延长识别时间,对于疲劳识别这种需要快速识别类型的工作而言是致命的。因此,需要加入池化操作对特征地图在保留关键特征的条件下缩小数据量。池化操作分为MaxPooling 和SamePooling,目前常用的是SamePooling。
激活函数(Activation Function)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络。神经网络之所以能解决非线性问题,本质上就是激活函数加入了非线性因素,弥补了线性模型的表达力,将“激活的神经元特征”通过函数保留并映射到下一层。目前,常用的激活函数为Rule 和Sigmiod 函数。
在完成池化与激活后,这一层的特征提取操作即完成。提取前后的图片对比如图3 所示。
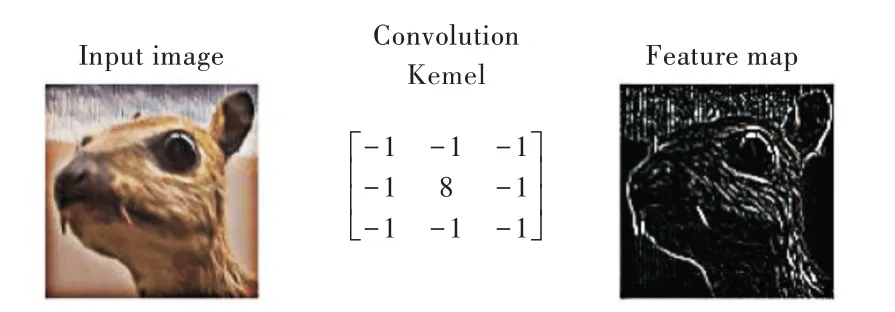
Fig.3 Comparison before and after extraction图3 提取前后对比
在将完成的特征地图传给下一个卷积层前,为了防止过拟合,还会进行Droupout 操作,该操作由Droupout 函数完成。该函数的主要作用是按照一定概率抑制神经网络中的神经元,被抑制的神经元输出为0 并且不会恢复,不再参与接下来的一系列训练操作。
在卷积操作完成后会将特征传给全连接层,全连接层会将自己已有的神经元与上一层传来的神经元相连接,判断出每个特征所代表的元素。
在全连接层后电脑会自动判断输出结果是否为真实结果,真实结果与输出结果的差距成为损失值,若损失值过大就说明识别效果越差,这时就需要神经网络进行反向传播,使用梯度下降等算法对之前的权值进行反复更新,使损失值降为最小,神经网络训练才算完成。
1.2 多任务卷积神经网络(MTCNN)
MTCNN[16-17]是由中国科学院深圳研究院在2016 年提出的专门用于人脸检测的多任务神经网络模型。该模型主要由3 个级联网络组成,分别为可以快速生成候选框的P-Net 网络、进行候选框过滤的R-Net 网络和生成最终边界框并且标出人脸特征点的O-Net 网络。该模型主要运用了图像金字塔、非极大抑制(NMS)和边框回归技术(Bounding-Box Regression)。
图片在进入3 个级联网络前会通过图像金字塔技术对图片进行尺寸重新划分,将原图缩放为不同的尺度,从而构成图像金字塔;然后将这些不同尺寸的图片送入3 个级联网络进行训练,这是为了让网络可以检测到不同大小的人脸而进行的多尺度检测。
在完成图像金字塔后,生成的图像会进入MTCNN 的第一个网络层,即P-Net 网络层。P-Net 全称为Proposal Network,该网络也是一个全连接网络,对于上一步输入的图像,通过全卷积网络(FCN)初步提取图像特征并且给出初步的标定边框,这时会出现许多标定边框,因为P-Net会通过一个人脸分类器将可能为人脸的部分都打上边框。在该网络的最后会通过Bounding-Box Regression 与NMS对刚才生成的边框进行初步筛查,丢弃不符合标准的标定边框。P-Net 网络结构如图4 所示。
从P-Net 网络输出的标定边框的人脸区域会进入下一个网络,即R-Net 网络进行处理。

Fig.4 P-Net network structure图4 P-Net 网络结构
R-Net 全称Refine Network,该层网络从结构上讲就是一个基本的卷积神经网络,比P-Net 多了一层全连接层,这使得对脸部特征点和边框的筛选将更为严格。
对网络中输入的值进行更加细化的选择,并且舍去大部分错误,该层也会利用人脸关键点定位器对人脸关键点[18]进行定位以及边框回归,最后利用Bounding-Box Re⁃gression 与NMS 对结果作进一步优化,将可信度较高的人脸区域输出给下一层网络,即O-Net 网络。R-Net 网络的网络结构如图5 所示。
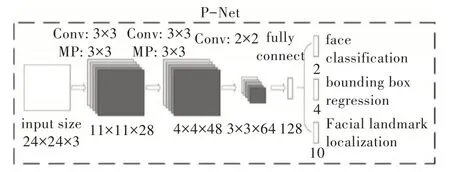
Fig.5 R-Net network structure图5 R-Net 网络结构
O-Net 网络的全称为Output Network,该层网络基本结构与R-Net 网络结构相似,多了一层卷积层,网络结构更加复杂,拥有更好的性能,模型优化也更好。在该层对输入图像进行人脸判别、人脸边框回归以及特征点定位,最后在图片中输出人脸区域的5 个特征点。O-Net 网络结构如图6 所示。

Fig.6 O-Net network structure图6 O-Net 网络结构
2 实施过程
2.1 实验流程
将原始图片输入MTCNN 网络,让MTCNN 网络可以准确地识别出人脸和关键点。然后通过检测到的5 个关键点,再根据“三庭五眼”理论将人脸的眼睛、嘴巴和耳朵分为了3 个区域,定义了左、右眼中心点连线与水平方向的夹角为θ,眼部区域宽度为W,高度为H=w/2。从鼻尖点位C 向左右嘴角连线作垂线,记垂距为D。嘴部区域上、下沿分别取该垂线及其延长线上D/2 和3D/2 处。这样在检测时可将这3 个部分分开检测,不同的区域、不同的动作会产生不同的结果。
具体动作判断需要在CNN 网络中实现,本文通过SimpleVGGnet 网络对需要判断的动作进行分类训练。SimpleVGGnet 只有3 个卷积层、3 个池化层和2 个全连接层,卷积核的大小为5,学习率设置为0.01,EPOCHS 设置为500,保证模型完全训练。将网络上得到的数据分为open_mouth、close_mouth、open_eye、close_eye 和smoke 5 个数据集,具体如表1 所示。

Table 1 Number of data set categories表1 数据集分类数量
可以看出,数据集的数量较大,模型对特征的提取越精确。还有25% 作为测试集,在对数据集进行训练后得出模型,实施流程如图7 所示。

Fig.7 Experiment process图7 实施流程
2.2 实验环境
系统:Window10;处理器:Intel(R)Core(TM)i7-8750H CPU @ 2.20GHz 2.21GHz;内存:32GB;GPU 型号:NVIDIA GeForce RTX 2080;Python 环境:Python3.7;Tensor⁃flow 和 keras 环境:Tensorflow-gpu==1.14.0,Keras==2.2.0;CUDA 版本:CUDA==9.0。
3 实验结果分析
本文使用MTCNN 网络对人脸进行识别并对人脸关键点进行提取,后经过CNN 神经网络对动作进行分类训练处理,得到一个识别率较高的面部动作识别模型。CNN 训练结果如图8 所示。
Fig.8 Training result图8 训练结果
测试过程中的数据变化如图9 所示,模型最终准确率达0.99,并且对于数据集的训练程度很高。
训练过程中的数据变化也符合普遍神经网络的训练变化,Loss 值呈下降状态然后趋于平稳,ACC 值呈上升状态后慢慢平稳,从数据看出模型训练很成功。
接下来对模型进行测试,本次是调用摄像头进行实时识别,模拟开车时的真实情况,测试结果如图10 所示。
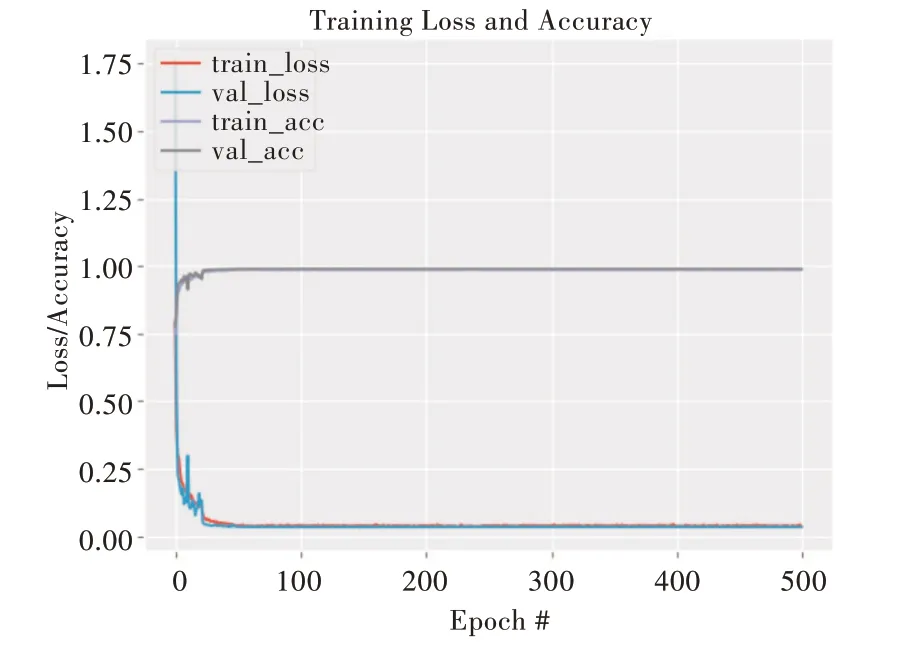
Fig.9 Training process changes图9 训练过程变化
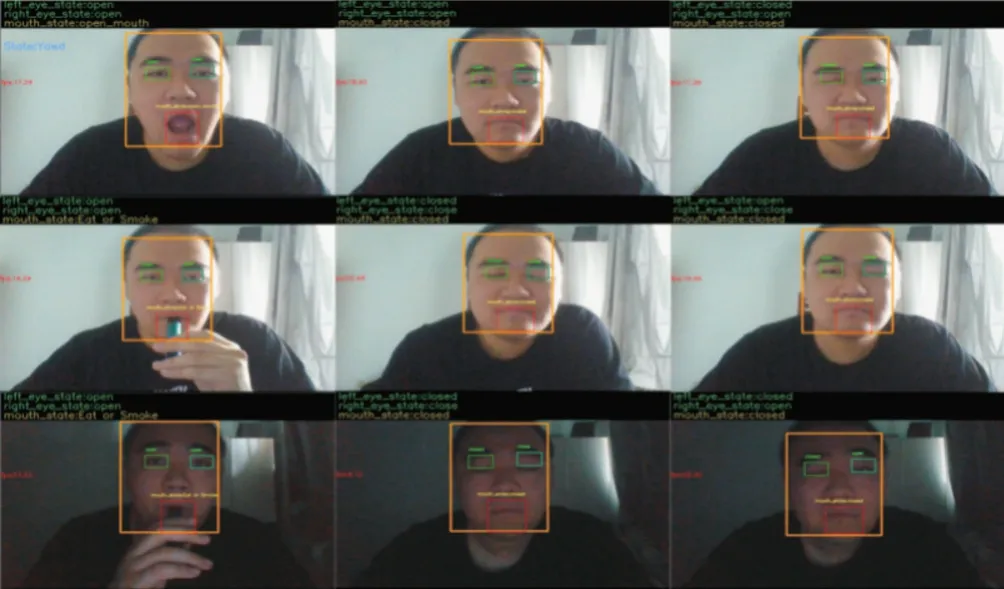
Fig.10 Test results图10 测试结果
从测试结果看,基于该模型可对3 个区域分别进行识别,并且帧数在19 帧左右,相对较为流畅。图10 的第1列是对对象嘴巴部分的分类识别,根据嘴部不同的动作分别识别出张嘴大叫、吃东西或抽烟,第2 列为测试对象的眼睛睁闭识别,第3 列为测试对象两只眼睛的不同动作识别结果,能够看出模型准确识别出单个眼睛的睁闭情况。除面部动作识别外,还对识别环境作了一些调整,前两行模拟白天识别情况,最后一行模拟夜晚识别情况。从测试结果可以看出,模型能够准确识别对象的面部动作,但夜晚情况下的面部动作识别还存在一些不足。
4 结语
面部识别和动作检测已有许多网络模型,本文在对其它模型进行研究后结合程序本身需要,先使用MTCNN 网络检测面部并且提取关键点,再结合VGG 神经网络的分类训练方法对面部动作识别模型进行优化,并且得出以下结论:①MTCNN 虽然对面部识别效果较好但是无法识别重合图像,若识别区域中有别的人脸出现会干扰测试;②可以对VGG 网络进行复杂处理,由于本次使用的是Sim⁃pleVGG 网络,性能不及完整的VGG-16 网络。
本文方法对面部动作识别表现较好,但依然存在一些不足,如检测的动作类别较少,具体只有3 类,且在检测时画面有明显卡顿,这在后续研究中需继续优化。
