模糊残差算法对离群点数据的优化研究
2021-05-24郑文凤
刘 云,郑文凤,张 轶
(昆明理工大学 信息工程与自动化学院,昆明 650500)
E-mail:2867328528@qq.com
1 引 言
在数据分析中常存在偏离目标数据的离群点,降低了数据的可用性,严重影响回归模型的拟合精度,使气象预测,医疗挖掘,企业决策等应用的数据分析结果存在较大偏差[1-3].随着海量和高维数据的增多,离群点数据的不确定性提高,因此,推动了一般回归分析到模糊回归分析的扩展,通过模糊集理论解决了数据的不确定性,并且适当模糊化能够提高模型的灵活性[4].
Zhang等人基于模糊C回归模型方法,提出鲁棒T-S模糊(RTS-L1,Robust Takagi Sugeno-L1)算法,使用L1范数损失函数代替传统最小二乘(LS,Least Squares)估计法中的L2范数损失,克服了LS对离群点的敏感问题,有效降低离群点数据对模型精度的影响[5].Zeng等人引入了一种新的三角模糊数之间的距离,提出最小绝对模糊线性回归(FLAR,Fuzzy Least Absolute Linear Regression)算法,用三角形模糊数的相似度测量方法评估观察值和估计值之间的拟合度,适用于处理模糊不确定的离群点数据,模型鲁棒性与普通模糊LS算法相比更优[6].
为了减少可能的离群点数据对回归模型造成的干扰,提高数据拟合精度,提出基于鲁棒策略的模糊残差(FR,Fuzzy Residual)算法.首先,根据模糊回归建模方法,在模糊域中构建模糊回归模型;其次,计算模糊数残差并确定了随残差迭代变化的权重;再通过新的加权LS目标函数估计模型参数,得到鲁棒模糊回归模型,新的模型根据不同的权重快速识别离群点数据并减少其对目标数据拟合的影响.仿真结果表明,FR算法比其他现有算法更有效的消除了不确定性离群点的破坏作用,使回归模型更准确的拟合数据,适用于进行高效的多维数据分析.
2 模糊集和模糊模型
2.1 模糊集
(1)
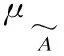
(2)

(3)


图1 三角模糊隶属函数的几何表示Fig.1 Geometric representation of triangular fuzzy membership function
(4)
(5)
2.2 模糊回归模型
离群点数据会降低算法的估计性能,通过模糊回归方法给不确定性问题提供了解决方案,比传统回归方法更适合处理大量和多维数据的离群点问题[11].首先根据这种建模方法构建模糊回归模型,通过优化模型估计参数提高异常离群点识别精度,使模型准确拟合目标数据,排除离群点数据的干扰.

图2 模糊回归模型拟合数据的主要流程Fig.2 Main process of fuzzy regression model fitting data
(6)
得到:
(7)

(8)
在模糊回归模型中,参数估计的优劣直接影响了模型拟合数据的精度.通常基于加权函数直接构造鲁棒模糊回归模型,便于实现更加精确的数据回归效果[13].
3 模糊残差(FR)算法
3.1 FR算法


(9)

(10)
式(10)中wi(i=1,…,n)表示第i个观测值的权重,该加权LS目标函数不仅降低了异常离群点对插值过程的影响,且计算复杂度较低,算法收敛时间更快.
输入一组观测数据集后,FR算法使用迭代重加权LS估计输出最优参数和相应的权重向量,主要执行过程见算法1.
算法1.模糊残差算法(FR)
输入:

2)n×(k+1)阶的预测矩阵X.

主要步骤:
1.Begin
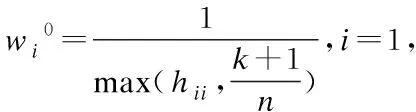
4.计算模型拟合的残差,记为e.
5.迭代计算t=t+1
6.计算新的权重


10.End
算法1中,计算第i次观测值初始化权重的hii是投影矩阵H=X(XTX)-1XT对角线上的第i个元素.得到初始权重后,先在第0次迭代中得到模型初始参数,再根据估计值计算残差,并由步骤6计算新的权重;直到第t次迭代满足算法停止准则时输出最优参数和对应权重,否则,转回步骤4计算新的残差,重新估计最优参数.
3.2 算法估计性能分析

(11)
通过FR算法优化的鲁棒模糊回归模型,可以估计出带有明显区分度的权重的数据点.见算法1,初始权重与偏离最大的离群点(hii)相关,逐步迭代计算的权重则由残差决定.模糊数的残差计算公式为:
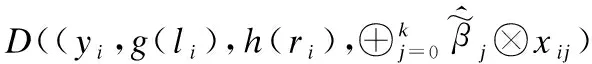
(12)
根据该残差公式可以得到n个数据点在第t次迭代时的权重:
(13)
由此可见,影响力较大的点或者说残差较大的点获得了更低的权重,使这类模糊离群点以最小隶属度被识别,并降低了其对目标数据拟合的干扰作用.因此,FR算法在保证收敛速度的同时具有较好的鲁棒性,可以精确估计存在离群点的数据集.

(14)
结合式(11)可以得到三角模糊数的鲁棒模糊回归模型,在求解模型时,让g(·)=h(·)=Ln(·).
4 仿真分析
4.1 数据集及仿真环境
与类似算法仿真一致,表1中的一组模糊数据集来自于Zeng等人[6]使用过的通用数据源,并且受到表2中不同数量的离群点数据的影响,该数据源对模糊离群点研究具有一定的针对性.

表1 一组三角模糊观测数据集Table 1 A set of triangular fuzzy observation data sets
为了利于研究,表2中离群数据是根据离群点的定义有意生成的.分别针对的第11,12和16个观测值,并分为3组不同的情况进行对比.

表2 3组不同情况下的离群点数据Table 2 Three groups of outlier data under different conditions
分别对存在不同数量的离群点的数据集进行回归分析,对比FR算法与其他算法的性能.为了形成明显的对比,选择的离群点都是偏离在目标数据上方的值,如果继续考虑其他位置的离群点,分析的结果相似.
4.2 拟合优度分析
为了评估模型对观测值的拟合程度,在拟合优度标准中采用3个被广泛用来评估模糊回归模型的标准,分别是相似性度量均值(MSE)[7],绝对误差均值(MAE1)和扩展的绝对误差均值(MAE2)[16].
(15)
(16)
(17)
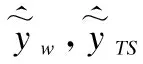
表3 离群点数据影响下和模型的拟合优度标准Table 3 Goodness of fit criteria of the and under the influence of outlier data
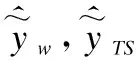
表4 删除离群点后和模模型的拟合优度标准Table goodness of fit criteria after removing outliers

在忽略离群点后,FR算法更快得到了数据拟合模型,在表4中计算了两种模型在的拟合优度标准,通过比较表3和表4的结果可得出结论,当离群点数据被忽略时,基于残差加权的模糊回归模型与其他方法的拟合误差没有太大差距,但计算时间复杂度更低,证明了FR算法的适用性.
根据结果得出,FR算法比现有模糊算法具有更优的模型拟合度,算法估计精度明显提高,可以得到可靠的数据估计结果.同时,FR算法在用于清理后的数据集时更快收敛.
4.3 鲁棒性分析
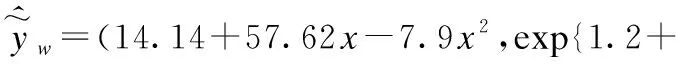
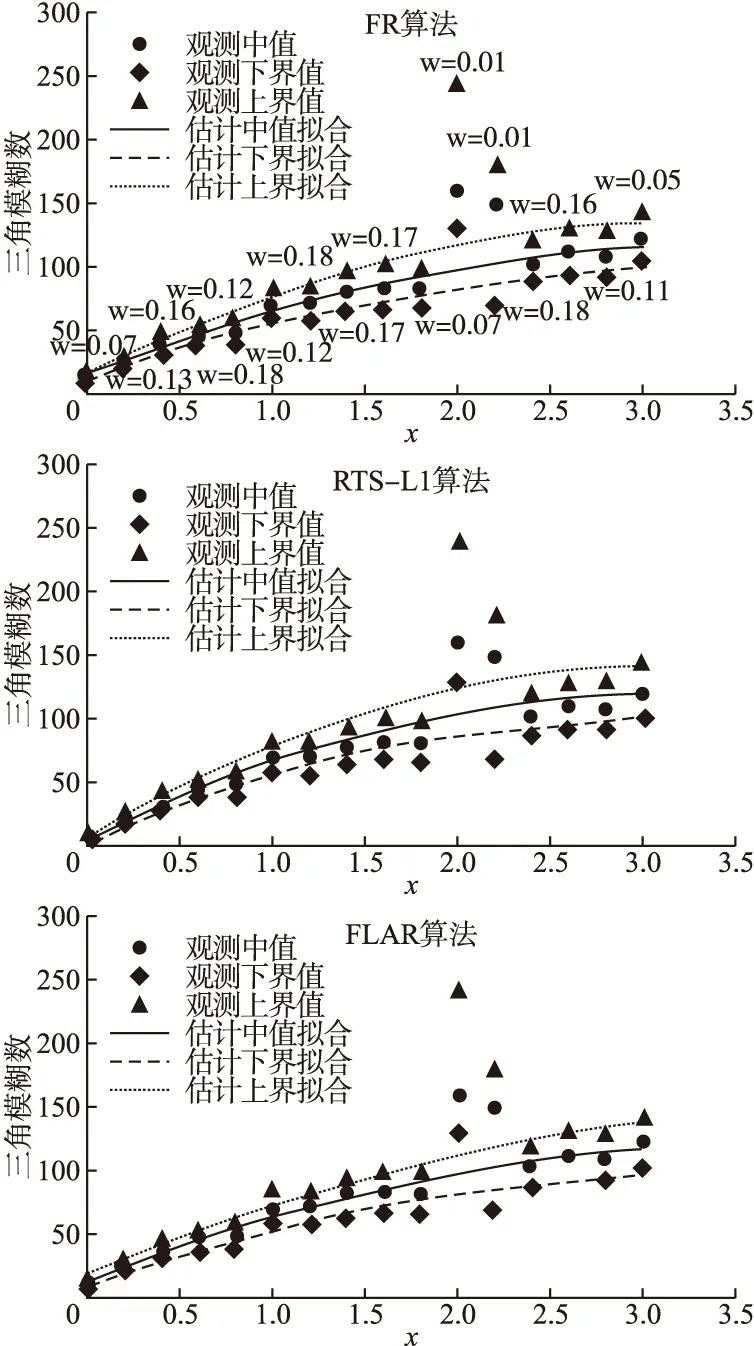
图3 情况2中3种算法的模型拟合结果Fig.3 Model fitting results of the three algorithms in case 2

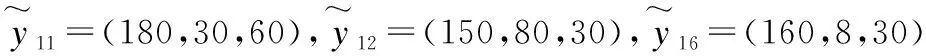
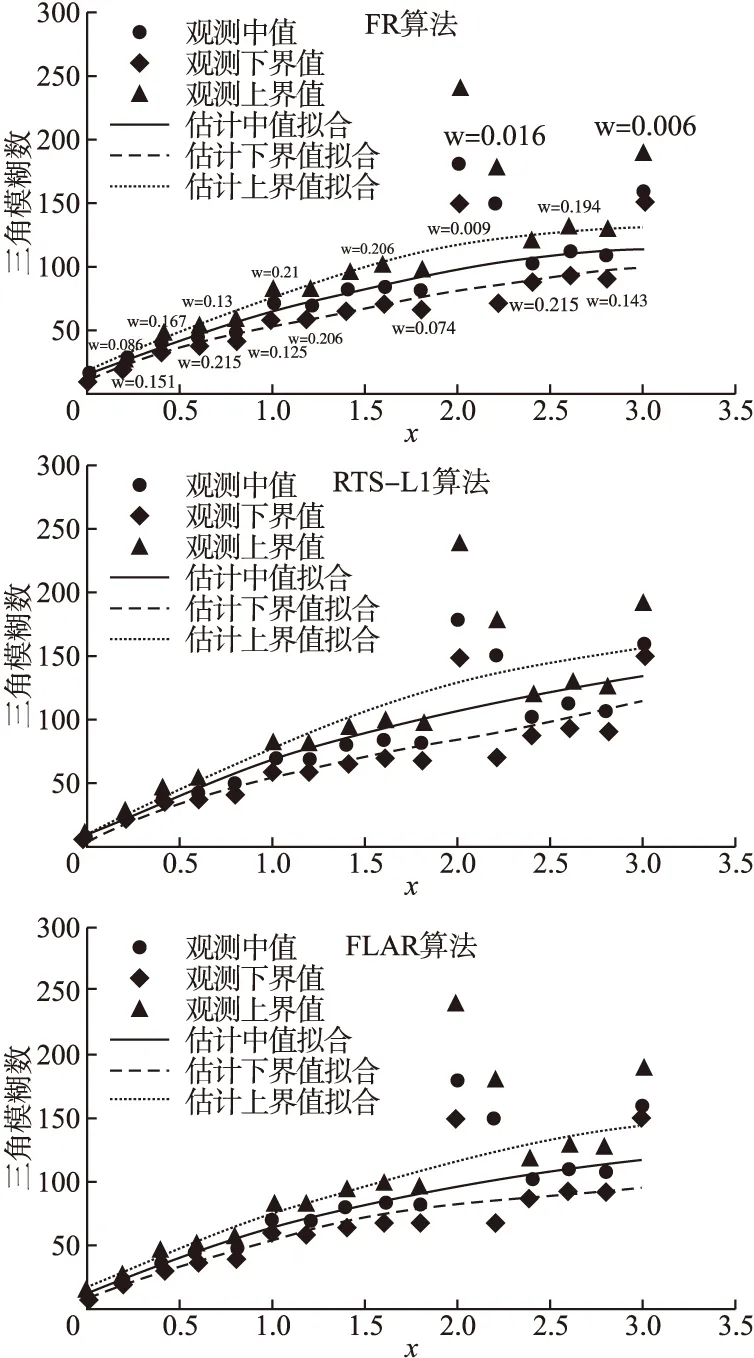
图4 情况3中3种算法的模型拟合结果Fig.4 Model fitting results of the three algorithms in case 3
在第3种情况下,鲁棒模糊回归模型的拟合效果更加明显,成功地降低了3个模糊的离群点的影响,说明FR算法有更好的鲁棒性,估计性能优.
RTS-L1算法容易受到左右分布的或中心的模糊离群值的影响,特别是两种情况同时出现(见图3),FLAR算法则在处理多离群点数据时的鲁棒性效果较低.相比之下,FR算法具有很好的鲁棒性,不管是受到哪个模糊离群点数据的污染,优化的模型都可以得到可靠的数据拟合效果.
5 结 论
当大量和高维数据集被离群点数据污染时,传统LS算法的性能都不理想,因此,具有鲁棒性的FR算法可以更好地解决离群点数据的不确定性.在模糊域中构建模糊回归模型后,根据FR算法进行残差迭代计算权重并结合LS法估计模型最优参数,得到基于加权优化的鲁棒模糊回归模型,为离群点数据确定了更低权重.仿真结果表明,所提算法能够很好地处理被离群点污染的数据集,精确识别离群点数据并拟合目标数据,具有更高的鲁棒性.实际数据中离群点产生的原因是多方面的,人为误差造成的可直接删除,具有研究意义的离群点应进行深入挖掘,下步将深入研究如何确定是否将离群点数据留在模型中或将其移除.
