基于图像自身信息感知的无参考低光照图像增强
2021-05-24吴建斌牛玉贞张宇杰
吴建斌,牛玉贞,张宇杰
(福州大学 数学与计算机科学学院,福州 350000)
E-mail:yuzhenniu@gmail.com
1 引 言
随着拍摄设备越来越普及且便携,人们可以拍摄到视觉效果好的图像.但是在光线不足的场景下,如夜景或昏暗的室内,要得到视觉效果良好的摄影图像仍然是十分困难的.如图1所示,由于场景光线不足或背光拍摄,捕获到的图像会呈现曝光不足,这类图像被称作低光照图像.低光照图像中的某些的区域几乎看不到图像细节,如图1中的第1列图像所示.此外,低光照图像中的对比度普遍低.低光照图像不仅呈现较低视觉效果,而且会影响许多基本的计算机视觉和图像处理方法的性能,如图像分类、图像显著性检测、对象检测和识别等.
为了解决低光照图像的上述问题,研究者们提出了对低光照图像增强方法进行研究,提出了很多方法,包括传统的方法和基于机器学习的方法.目前,基于深度学习的图像增强方法通常能获得比其它方法更好的结果.但是基于深度学习的图像增强方法,如图像去雨[1]、图像去雾[2],普遍需要使用成对的图像对进行训练.
然而,在低光照图像增强问题上,获得可用于深度学习模型训练的成对数据集是很困难的[3].首先,捕获同一个时刻场景下的低光照图像和正常光照图像是非常困难甚至是不可行的.其次,使用正常光照图像来合成的低光照图像和真实场景下的低光照图像往往存在差异,这将导致使用合成数据集训练出来的模型在应用于真实低光照图像时产生伪影.最后,由于场景亮度的变化是复杂多样的,对于特定的低光照图像,难以定义与其对应的唯一的正常光照图像.而在强监督的训练方法中,每个训练样本都有其唯一的参考标签.
受到无监督的图像到图像转换方法[3-5]的启发,本文采用生成对抗网络(GenerativeAdversarial Network,GAN)来解决低光照图像到正常光照图像的增强问题,这样可以避免使用依赖于成对的图像来进行训练.对于无参考低光照图像增强任务,不仅需要恢复出低光照图像中难以观察到的结构信息,还需要生成正常光照场景下自然的颜色信息.为此,本文使用改进了的基于空间和通道的自注意力融合模块和结合低光照图像全局信息的自适应实例归一化模块来恢复图像的结构和细节信息,并且提出自颜色损失用于还原低光照图像的颜色,进一步提升了低光照图像增强的性能.

图1 本文方法结果图.第1列为输入的低光照图像,第2列为增强结果图像Fig.1 Results of our proposed method.The first column shows some input low light images,and the second column shows the enhancement results
实验结果显示,本文提出的方法能够较好的还原低光照图像到正常光照图像,并且在图像的视觉效果和无参考自然图像指标(Natural Image Quality Evaluator,NIQE)上的表现均比已有的低光图像增强方法有提升.图1给出了本文提出的无参考低光照图像增强方法的结果.
2 相关工作
2.1 传统方法
低光照图像增强问题作为图像处理的问题之一,已经有许多方法被提出来.有一些经典方法,比如,通过限制图像的直方图分布让其趋于均匀分布来提高原始图像对比度的直方图均衡化法(Histogram Equalization),以及后续发展的自适应直方图均衡方法(Adaptive Hisogram Equalization).再有基于Retinex 的方法[6],通过合理的先验假设将输入图像分解为反射图和光照图,然后分别调整反射图和光照图来增强图像.文献[7]提出了一种简单而有效的低光图像增强(Low-light image enhancement via Illumination Map Estimation,LIME),其使用RGB通道中的最大值来估计每个像素的照度,然后施加结构先验来调整光照图来实现图像增强.在使用对数操作对图像进行Retinex分解时,对数域下低光区域的梯度会被放大而导致图像增强结果不真实.对此文献[8](aweighted variational model for Simultaneous Reflectance and Illumination Estimation,SRIE)提出了补偿方法来弥补低光区域梯度放大问题,使得增强结果更加真实.文献[9](Naturalness Preserved Enhancement algorithm for non-uniform illumination images,NPE)使用亮度滤波对图像进行Retinex分解,再使用对数双边变换调整光照图以增强图像细节同时保留图像的真实性.
2.2 基于机器学习的方法
最近越来越多的研究者提出使用基于机器学习的方法来解决低光照图像的增强问题.例如,Bychkovsky等人[10]创建了第1个同时最大的数据集MIT-Adobe FiveK,其中包含了原始低光照图像和专家增强后图像的图像对.Yan等人[11]提出了一种机器学习的排序方法,用于自动增强照片中的色彩.文献[12]构造了语义图以实现语义感知的图像增强.
随着深度学习在计算机视觉领域许多任务上取得了较大的性能提升,基于深度学习的低光照图像增强方法也被提出.Retinex-Net[13]将Retinex理论和深度网络相结合,通过深度卷积网络来模拟图像的Retinex分解,再分别对反射图和光照图进行去噪和增强,然后合成增强后的正常光照图像.HDR-Net[14]将深层网络与双边网格处理结合,在低分辨率下使用网络学习双边网格参数,再对原始分辨率图像进行仿射变化实现了实时的低光照图像增强.Chen等人[15]通过直接处理相机摄影时得到的原始传感器数据实现了高质量低光照图像增强.但是以上方法都需要使用成对的低光照图像和正常光照图像进行训练.
生成对抗网络(Generative Adversarial Network,GAN)[16]是深度学习中的一种特殊模型,与普通的深度学习框架不同,生成对抗网络中包含生成器网络和判别器网络,生成器用于产生于目标数据分布相同的真实数据,而判别器则用于区分真实数据和生成数据,一般情况下二者交替训练且最终收敛到纳什平衡.生成对抗网络已被广泛的用于各类计算机视觉任务[17-19],然而多数现有的方法使用成对的训练数据,例如超分辨率方法[20],单图像去模糊方法[21],去雨方法[22]和去雾方法[23].对于缺少成对训练数据集的计算机视觉任务,文献[4,5]采用双向GAN训练方式,其使用两对生成器和判别器分别完成两个相反方向的域转换,并且使用生成对抗损失和提出的循环一致损失来同时训练这两对生成器和判别器.
双向GAN的训练方式虽然能在无成对数据集上进行学习,但是其成倍增加了训练的时间成本和硬件成本,同时引入了额外的不稳定性.EnlightenGAN[3]提出使用单个生成对抗网络实现无参考图的低光照图像增强方法,其通过提出的自特征保留损失实现增强结果域输入低光照图像内容上的一致性.与EnlightenGAN不同,本文提出的方法使用生成对抗损失来增强低光照图像中难以观察到的结构内容,并且进一步提出自颜色损失来还原低光照场景中的颜色信息,使得生成结果更加真实自然.
3 本文方法
本文所提出的基于生成对抗网络的无参考低光照图像增强模型框架如图2所示,其包含一个基于U-Net[24]的生成器网络和一个全局判别器网络、一个局部判别器网络.生成器接受低光照图像作为输入,不依赖正常光照图像,输出对应的增强结果,判别器则训练区分样本是真实正常光照图像或是生成器的增强结果图像.

图2 模型框架图Fig.2 Model framework
3.1 生成器网络结构
本文采用基于U-Net结构的生成器.如图3所示,生成器可以分为编码器和解码器两部分,分别包含3次下采样提取图像特征和3次上采样还原输出图像,并将各尺度的编码器特征跳连到解码器部分对应层输入中,从而充分利用多尺度特征来合成高质量图像.其中编码器的下采样由步长为2、卷积核大小为3×3的卷积操作完成,解码器的上采样则由最近邻插值的方式进行.在编码器部分,使用卷积、批归一化和Leaky ReLU 激活进行图像特征提取.在解码器中,本文使用卷积、层归一化和Leaky ReLU激活函数和上采样操作来还原增强图像.此外,如图3所示,本文还通过卷积子网络f(.)将输入的低光照图像编码成潜在编码,用于对生成器中最小尺度特征进行自适应实例归一化,并且引入多尺度权重图在解码器部分引入自注意力融合模块.本文将在后面对二者进行详细的介绍.
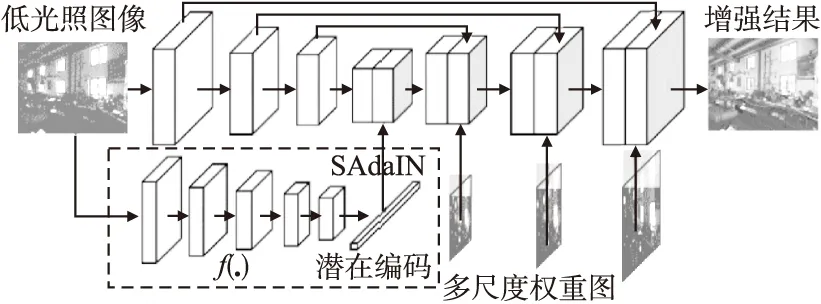
图3 生成器网络结构Fig.3 Generator network styucture
a)自适应实例归一化(Self-Adaptive Instance Normalization,SAdaIN)
由于不同低光照图像之间的亮度存在差异且同一张低光照图像内不同区域之间也存在复杂的亮度变化,因此对不同低光照图像,其需要增强的程度也不同.受到Huang等人[25]的启发,本文使用改进的自适应的实例归一化(SAdaIN),其定义如公式(1)所示:
(1)
其中μ(x)和σ(x)分别表示输入特征x在宽、高维度的均值和标准差,μf(.)和σf(.)是由全连接层学习出的特征变化系数,f(.)则是一个卷积子网络,其由五个串联的步长为2卷积核大小为4×4的卷积层、LeakyReLU激活函和一个全连接层数组成,用于将输入的低光照图像I转换为一维的潜在编码.SAdaIN模块使用根据输入的低光照图像学习到的特征变换系数对归一化后的特征进行变换,以适应不同亮度程度的低光照图像.如图3所示,本文在生成器模型的中间部分插入SAdaIN 模块来调整图像特征.
b)自注意力融合模块(Self-Attention Merge,SAM)
在解码器部分,受到文献[3,26]的启发,本文使用改进了的基于空间和通道的自注意力融合模块(SAM).如图4所示,通过将输入图像I中每个RGB像素视为三维向量并计算其欧几里德范数(Euclidean norm)得到一张权重图M,对权重图M使用卷积操作,为该模块的输入特征fc的每个通道学习一个空间权重图得到Mc,再将fc和Mc进行点乘得到fc′,将fc′进行全局平均池化得到一维向量,使用全连接层进行压缩和扩张得到通道注意力向量Vc,再将通道注意向量Vc点乘回fc′作为输出.如图3所示,本文通过对原始输入图像的权重图M进行不同尺度的缩小,在解码器的各个尺度上引入自注意力融合模块.

图4 自注意力融合模块Fig.4 Self attention merge module
3.2 判别器网络结构
判别器用于判别输入图像是真实的正常光照图像或是生成器输出的增强图像.本文使用了全局判别器和局部判别器来充分利用输入图像全局信息和局部块信息,其详细结构如图5所示.

图5 判别器网络结构Fig.5 Structure of discriminators
全局判别器含有5层步长为2,卷积核大小为4×4的串联卷积层,串联的卷积层逐步降低输入图像的分辨率,从128×128降到4×4的空间大小,再经过展平(Flatten)后使用串联的全连接层和Leaky ReLU层合并全局图像信息,最后使用一个全连接层预测判别结果.
相似地,局部判别器使用5层串联的步长为2,卷积核大小为4×4的卷积层,将输入图像转变成特征矩阵,并在最后使用全连接层将该特征矩阵变换为输出的预测矩阵.通过计算卷积操作的接受域大小可知,局部判别器的预测矩阵中每个位置的值对应于的原始输入中94×94大小的像素块,故预测矩阵中的每个值表示对输入图中对应位置块的判别结果.两个判别器中均使用LeakyReLU作为激活函数.
3.3 损失函数
本文优化Hinge版本的生成对抗损失[27]来训练生成器和两个判别器,如公式(2)所示:
LD=Ex~P[max(0,1-D(x))]+Ez~Q[max(0,1+D(G(z)))],
LG=-Ez~Q[D(G(z))]
(2)
其中z表示低光照图像,x表示正常光照图像,G为生成器网络,D为判别器网络.由于本文采用了双判别器结构,所以对于全局判别器和局部判别器分别有相同形式的损失函数LDglobal、LGglobal和LDlocal、LGlocal.
由于本文提出的无参考方法无法获得参考图像的颜色信息,为了对增强后的图像的颜色进行约束,本文提出自颜色损失函数.首先本文发现,如图6所示,将低光照图像的像素值线性缩放到[-1,1]区域后,通过对整张低光照图像计算均值和标准差,再使用该均值和标准差归一化RGB 3个通道的像素值能够明显的还原出图像中的颜色信息.根据此发现,本文提出自颜色损失Lsc,通过约束生成图像和归一化低光照图像中对应位置上RGB像素的向量夹角使生成图像能够复原出输入的低光照图像的色彩,同时限制生成图像的颜色变化和归一化图像的颜色变化相似.如公式(3)所示.

图6 使用归一化还原低光照图像中的颜色实例.左半部分为归一化后的图像,右半部分为原始的低光照图像Fig.6 An example of using normalization to restore colors in a low-light image.The left half is the normalized image,and the right half is the original low-light image
(3)
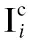
由于低光照图像往往存在噪声,而噪声图像的总变分往往比正常的自然图像要高,故本文使用总变分损失来抑制生成的增强图像的噪声,其定义为:
(4)
综上所述,本文使用的总损失函数为:
(5)
其中λ1、λ2、λ3和λ4为各项损失平衡系数.
4 实 验
4.1 实现细节
本文使用文献[3]给出的不成对的数据集,其中包含914张低光照图像和1016张正常光照图像.训练时,首先从完整图像中随机裁剪出n×n(128≤n≤320)大小的图像块,然后统一将图像块缩放到128×128大小,同时使用了随机翻转、旋转操作作为数据增强,将这些图像块作为训练的输入图像.本文使用了四个标准的数据集进行测试来衡量方法的效果,包括DICM(DIgitalCaMeras)[28],LIME(Low-light IMageEnhancement data)[7],MEF(Multi-Exposure image Fusion)[29]和NPE(Naturalness Preserved Enhancement data)[9]数据集,它们分别包含有64、11、17和8幅不同程度的低光照图像,场景覆盖了室内、户外、建筑和自然景观等,且图像大小不一.
本文方法使用Tensorflow深度学习框架实现,使用2张NVIDIA P100 GPU进行训练.在训练模型时,分别将超参数λ1、λ2、λ3和λ4设置为1、1、10和0.0001,对于超参数λsc为0.5.训练时采用Adam优化器[30]并且设置优化器的学习率为0.0001,beta1为0.5和beta2为0.999,训练的批大小为48,epoch为300.
4.2 与其他方法对比
为了验证本文方法的有效性,将本文方法和五种低光照图像增强方法进行比较,包含RetinexNet[13]、LIME[7]、SRIE[8]、NPE[9]和EnlightenGAN[3].方法对比包含结果图的视觉对比和客观评价指标.由于测试数据集内不含有可用于参考的正常光照图像,本文采用无参考图像质量评价指标,自然图像质量评估(Natural Image Quality Evaluator,NIQE)[31]作为对比的客观评价指标.NIQE能在没有参考图的情况下给出定量的评估结果.
各方法的增强效果如图7所示.由图7可见,尽管6个低光照图像增强方法都能增强低光照输入图像,但效果存在差异.如输入图像(a),在光照特别低的情况下,LIME方法、SRIE方法和EnlightenGAN方法只能恢复出少许的灯光,而本文方法的增强结果中能明显看出场景的结构信息.对于输入图像(A),可以看出RetinexNet方法、NPE方法和EnlightenGAN方法的增强结果中存在颜色退化问题,即黑色的背景色在其增强后出现了不同程度上的色偏,而本文方法的增强结果则更加自然.同样对于输入图像(H),LIME方法的增强效果十分有限,SRIE方法和EnlightenGAN方法则只能增强窗户周围的区域,只有RetinexNet方法、NPE方法和本文的方法能够增强光照更低的区域,而RetinexNet方法和NPE方法的增强结果颜色却不自然.由此对比可见,本文的方法不仅能够增强光照极低情况的输入图像,而且能够复原出合理和自然的颜色.

图7 测试集中不同图像的增强结果对比Fig.7 Comparison of the enhancement results of different test images
表1给出了4个测试数据集上原始输入和各个方法增强结果的NIQE指标,该指标数值越低表示方法性能越好.如表1所示,本文的方法在DICM和LIME测试数据集上的表现优于所对比的其它低光照图像增强方法,在MEF测试集上的表现略低于EnlightenGAN,在NPE测试集上的表现略低于NPE和SRIE.综合4个数据集,本文方法的性能优于已有方法.

表1 在测试数据集上NIQE的实验结果Table 1 NIEQ results on testing datasets
4.3 消融对比
为了验证本文方法中网络结构和损失函数的有效性,在相同数据集和训练参数的设置下,进行了消融实验来对比验证自适应实例归一化(SAdaIN)、自注意力融合模块(SAM)和自颜色损失对低光图像增强的效果.对于自适应实例归一化,本文通过使用实例归一化代替来进行对比试验.通过计算消融实验设置下模型的NIQE指标,来定量分析各模块和自颜色损失的有效性.
如表2所示,在不使用自颜色损失的情况下,模型在4个测试数据集中的NIQE均明显变差,这是由于只使用生成对抗损失和总变分损失的时候,生成的图像出现严重的颜色退化导致其于自然图像差异较大.而缺少自适应实例化模块和自注意力融合模块的时候,模型在DICM和LIME两个测试数据集上均出现一定程度的退化.这进一步验证了自适应实例化模块和自注意力融合模块的有效性.
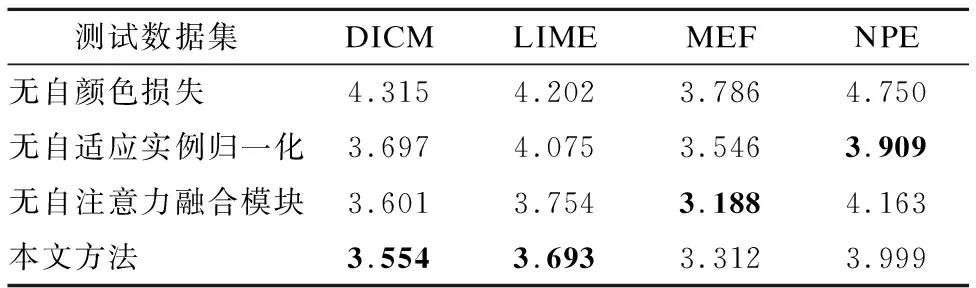
表2 各消融实验的NIQE结果Table 2 NIQE results of each ablation experiment
本文进一步通过比较各个消融设置下模型的增强结果图,来验证提出方法的有效性.如图8所示,在不使用自颜色损失函数的情况下,增强结果(b)、(g)虽然能够恢复出低光照场景下的结构信息,但是其颜色出现明显的退化,导致其于自然图像不符;在使用实例归一化替代自适应实例归一化的情况下,由于其缺少整幅图像的光照信息,模型的增强结果出现一定程度的颜色退化,表现在(h)中黑色背景部分出现轻微的色偏情况;而在不使用自注意力融合模块的情况下,模型对结构细节的恢复效果下降,表现在(d)中柱子部分细节丢失.综合上述消融实验的结果,验证了本文提出和改进的自颜色损失、自适应实例归一化、自注意力融合模块对于低光图像增强问题的有效性.

图8 消融实验效果图Fig.8 Effect of ablation experiment
4.4 讨 论
图9展示了一个失败的例子,该例子为一个熟知的室内场景.本文提出的方法以及其他对比方法都无法对该场景产生视觉上令人满意的结果.具体表现为对低光照图像的色彩还原不够理想,出现色偏且饱和度较低.此外,对比方法的结果中还在墙壁上呈现出不同程度的噪声放大.这是因为低光照图像增强方法难以把握适当的增强幅度,过度的增强容易出现噪声放大问题,不恰当的增强幅度也导致了颜色恢复不足.因此提高方法对场景的识别能力和颜色复原能力是未来工作的目标.

图9 失败的低光照图像增强例子Fig.9 Failure case of low-light image enhancement
5 结束语
本文提出了基于生成对抗网络的低光照图像增强方法,利用生成对抗网络损失、自颜色损失和总变分损失能够在无正常光照的参考图像下训练模型进行低光照图像增强.在基于U-Net结构的生成器基础,使用改进了的自适应实例归一化来根据输入的低光照图像的全局信息调整特征图像,并且在解码器部分引入了改进的基于空间和通道的自注意力融合模块,提升模型在低光照增强中对细节的保留,并且恢复低光照场景下的颜色信息.实验结果表明,本文方法在低光照增强的视觉效果和无参考自然图像指标NIQE上相对已有方法均有提升.
