DFAN:一种基于深度反馈注意力网络的图像超分辨率方法
2021-05-24施举鹏陆正嘉
施举鹏,李 静,陈 琰,陆正嘉
1(南京航空航天大学 计算机科学与技术学院,南京 211106)2(国网上海市电力公司信息通信公司,上海 200000)
E-mail:sjp.seasonsy@gmail.com
1 引 言
一直以来,图像超分辨率(Super-Resolution,SR)被广泛应用于诸如医学影像、人脸识别等对图像质量有较高需求的场景.同时在深度学习领域,作为底层的计算机视觉问题,超分辨率还可以通过产生高质量图像为其他高级视觉任务提供优质数据集来提升相应模型性能.图像超分辨率旨在实现低维图像空间向高维图像空间的映射,即低分辨率图像(Low-Resolution,LR)向高分辨率图像(High-Resolution,HR)的转换.
传统的图像超分辨率方法主要是使用插值算法[1]对需要填补的像素值进行计算,该类方法简单高效,可应用于实时快速的图像上采样,但因其过于依赖人为定义的映射关系以及先验假设,导致基于插值算法的图像重建质量往往难以保证.为了解决传统插值方法的问题,基于机器学习的超分辨率方法[2-4]逐渐发展起来,该类方法主要通过在大量带标注的图像数据集中通过一定的算法学习低分辨率到高分辨率的映射来拟合LR-HR映射关系.2014年,Dong[5]等人首次将深度学习方法应用到超分辨率领域,作为超分辨率在深度领域的开山之作,作者提出了一种使用3层卷积神经网络的方法,实现了优于传统方法的图像超分辨率重建效果,后来的深度学习模型基本上延用了该模型的基本结构,即由特征提取和图像重建两部分组成.为了改进SRCNN[5]中仍然基于插值的图像重建方式,Zeiler[6]和Shi[7]相继提出了基于反卷积和亚像素卷积的上采样方法,将图像重建部分的参数也纳入到模型训练的过程中.
随着深度学习模型的不断发展,超分辨率领域也提出了许多新的网络模型.SRResnet[8]引入了残差结构,通过在线性网络的基础上添加跳跃连接来缓解梯度信息在多层传播过程中的损失.得益于此,超分辨率网络可以设计得更深,这大大增强了模型的学习与表征能力.为了更好地利用深度卷积网络各层的梯度信息,MemNet[9]引入了稠密连接的结构.RDN[10]结合了残差与稠密连接结构的优点,提出了残差稠密块,进一步提升了图像超分辨率的质量.
尽管许多深度学习模型取得了较好的重建效果,但是较深的网络也带来了诸如过拟合以及收敛速度较慢等问题,这类问题属于深度神经网络的通病,许多质量较高的超分辨率结果大多依赖于网络的反复调参尝试,最终的模型在实际应用场景中难以复现.因此,许多网络模型设计的重点开始从增加网络的深度转移到低分辨率图像到高分辨率图像(LR-HR)映射的学习上.为了更准确地学习LR-HR映射,RED[11]提出了卷积-反卷积的对称结构,DBPN[12]引入了反射单元,这些结构已被证明能够使模型更好地学习LR-HR重构映射,从而获得更好的重建效果.同时伴随着模型的参数量不断增加,为了降低模型计算上的负担,DRCN[13]与DRRN[14]引入了递归结构.通过共享一些层的参数来控制模型的规模.为了实现特征信息的前馈及反馈传播,SRFBN[15]引入了反馈连接结构,实现了参数的充分复用.递归和反馈结构确实对模型参数的利用产生了好的影响,但由于这类结构都是通过在训练过程中以循环迭代的形式传递特征信息,冗余的特征信息以及一些噪声可能会在迭代中产生叠加效应,并影响到网络的收敛以及最终效果.
为了抑制基于反馈结构的超分辨率网络中由于深度迭代产生的副作用,本文提出了一种基于深度反馈注意力的超分辨率网络(DFAN),该网络可以有效抑制冗余信息在反馈迭代中的叠加,提高参数共享及特征传播的质量,同时提升模型的收敛速度.DFAN中基本的反馈模块由上采样和下采样层交替组成,模型中利用通道注意力机制学习图像特征的权重,将注意力学习到的权重,通过反馈结构共享到每一轮迭代当中,进而形成基于迭代的残差注意力,实现对冗余特征的过滤机制.不同于其他基于迭代的超分辨率网络,本文方法的深度反馈注意力实现了一种面向迭代过程的特征过滤机制,从而在迭代过程中使模型有效区分有效信息和冗余信息,增强对有效信息的学习并抑制冗余信息的进一步传播.
本文的主要贡献包括:
1)提出了一种基于反馈机制的迭代反馈注意力超分辨率网络,实现了参数复用以及冗余特征过滤机制,与同类超分辨率模型相比,该模型具有更少的参数量以及更快的执行速度,同时也能获得较高质量的超分辨率重建水平.
2)提出了一种新的迭代反馈注意力结构,引入了注意力机制,在特征的反馈传播中学习注意力权重以实现通道层次的过滤,提高了模型学习的效率,同时该结构可以应用到任何基于反馈结构的模型中.
3)本文提出的模型在公开标准数据集上取得了优于大部分同类方法的重建效果,在单张处理时间秒级以内的情况下达到了最高38db以上的峰值信噪比.同时在实验中分析了迭代反馈注意力结构对于网络训练速度及收敛过程的影响.
本文后续章节安排如下:第2节主要介绍了基于深度学习的超分辨率模型的相关工作;第3节介绍本文提出的基于深度反馈注意力的超分辨率网络DFAN;第4节通过DFAN模型的参数对比实验以及与同类方法的超分辨率重建对比实验来验证本文方法的有效性;第5节对本文方法进行总结,并探讨进一步的研究方向.
2 相关工作
自SRCNN[5]超分辨模型开始,卷积神经网络(Convolutional Neural Network,CNN)被广泛地应用于图像超分辨率领域,本文的DFAN模型主要是基于卷积神经网络中的注意力机制与反馈机制实现的,因此本部分将介绍与这部分内容相关的国内外相关工作.
2.1 基于卷积神经网络的超分辨率
最早将卷积神经网络应用于SR问题的是SRCNN[5],作者提出了3层的卷积神经网络,取得了优于传统方法的效果.随后,更深更复杂的网络开始出现,VDSR[17]提出了一种基于20层卷积神经网络的超分辨率模型.实践表明,越深的网络表达能力越强,也越易于出现过拟合和梯度爆炸等问题.为了解决这些问题,SRResNet[8]和MemNet[9]分别引入了残差结构以及稠密结构,相较于线性网络,这些结构通过跳跃连接可以更好地传播梯度信息.RDN[10]同时结合了上述两种结构的优势,并引入了Residual in Residual结构,进一步提升了重建质量.随着网络结构的进一步加深,超分辨率重建的效果逐渐趋于饱和,而网络参数的规模以及计算消耗越来越大,基于基本卷积块叠加的卷积神经网络在超分辨率的效率上很难进一步提升.
2.2 基于反馈网络的超分辨率
为了解决参数规模日益庞大以及卷积层的大量堆叠导致的网络难以训练的问题,受到RNN[16]的启发,DRCN[13]首次在超分辨率领域引入了递归结构.该方法在训练过程中,将某些卷积层的参数进行递归复用,将每一个卷积层的参数合并到后面的参数中一起训练,从而可在较少参数量的情况下取得较好的重建效果.DRRN[14]结合了残差结构将递归网络模型的深度进一步加深.虽然递归结构可以在不增加过多参数的情况下增加网络深度,但是并没有改变特征信息的前馈传播方式,导致参数仍是单向共享的.为此,SRFBN[15]引入了反馈机制,基于反馈连接的形式复用参数,将每轮迭代的特征并入下一轮迭代的特征输入中,实现了特征信息的反馈传播,并取得了更好的重建效果.递归结构与反馈结构形式的不同如图1所示.

图1 DRCN [13](a)的递归结构以及SRFBN [15](b)的反馈结构的迭代展开形式Fig.1 Expanded form of the recurrent structure of DRCN [13](a)and the feedback structure of SRFBN [15](b)
2.3 基于注意力的超分辨率模型
注意力在人眼视觉机制上起着至关重要的作用[18],在深度学习领域,视觉注意力也被广泛引用于诸如图像分割,图像识别等高级计算机视觉任务中.注意力机制主要用过在特征提取的过程中,引入响应特征强度的权重矩阵来实现对重要特征的增强.基于空间域、通道域以及混合域等的注意力模型被用来解决不同的计算机视觉问题.在图像超分辨率领域,RCAN[19]首次引入了通道注意力,对网络学习的特征信息进行筛选,在添加极少量参数的条件下,提升了超分辨率重建效果.
为了解决反馈网络中冗余特征信息的传播,实现特征选择,本文方法在基于反馈连接的图像超分辨率网络中引入了通道注意力模型,同时借鉴了SE-Net[20]中的方法,以全局平均池化代替了注意力模型中的全连接层以进一步减少参数量,还参考了RAN[21]中的残差注意力结构,并结合反馈模型,提出了迭代反馈注意力结构,以实现循环过程中对于特征信息的迭代过滤.具体的模型结构与机制将在下面的章节中介绍.
3 基于深度反馈注意力网络的图像超分辨率方法
本文结合了反馈结构与注意力机制,提出了基于深度反馈注意力的图像超分辨率模型.如图2所示.在DFAN模型中,核心部分包括参数的循环迭代以及残差注意力.循环迭代机制通过反馈连接形成的反向传递实现,其确保了特征信息在迭代过程中的充分利用.注意力模块通过学习对应的权重来对每轮迭代的特征通道进行过滤,并在迭代中不断对SR特征进行微调.由于注意力模块本身对于特征信息的传递存在抑制作用,为了减少这种对特征的削弱,本文借鉴了RAN[21]中引入残差的方法来实现注意力模板,通过与上一轮迭代的权重模板相关联,每一轮迭代的注意力模板都学习一个基于迭代的更深一层的残差信息,利用这种迭代,不断细化图像的特征.这两种机制的结合确保了参数共享,也使得模型更加精准地学习LR-HR映射.
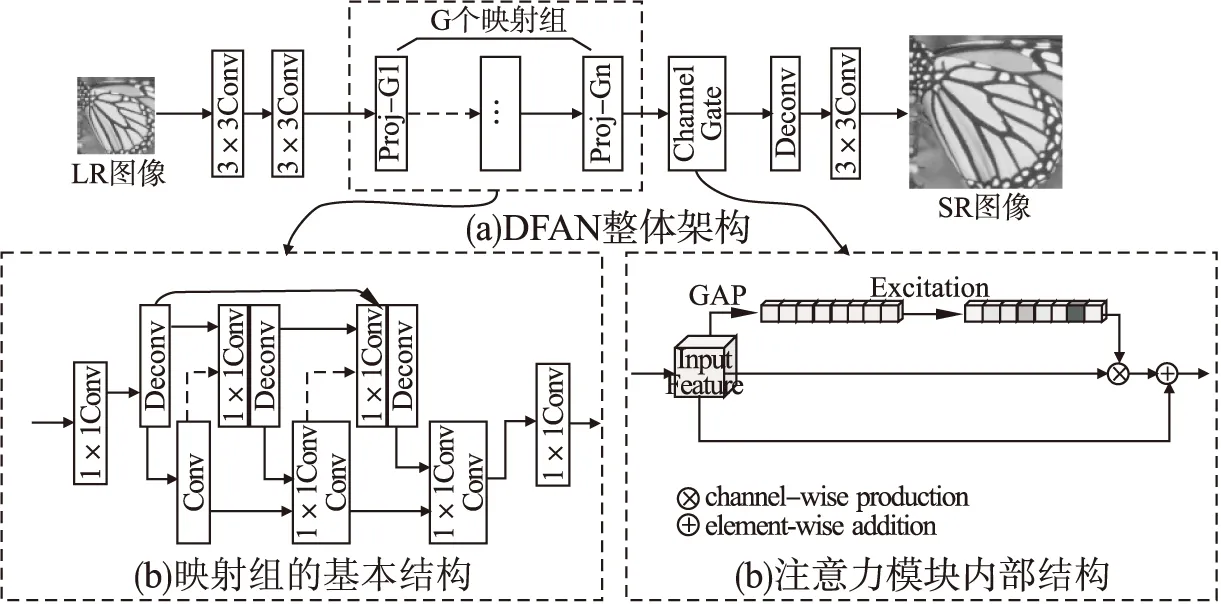
图2 基于深度反馈注意力的超分辨率网络模型框架图Fig.2 Overall framework of deep feedback attention network for image super-resolution
3.1 网络基本结构
图2所示为DFAN的静态结构,在实际训练过程中,模型的动态迭代结构如图3所示,单幅图像的训练可被展开为T轮迭代,迭代的序号由1-T表示.图中下面部分的实线表示特征的反馈复用,上面部分的虚线表示每轮学习的注意力被叠加至下一次循环以形成迭代残差学习.每轮迭代中模型会合并当前输入与之前迭代输出的所有特征,共同作为当前的输入特征,以实现参数复用及特征共享.模型的基本组成模块主要包含由卷积层和反卷积层构成的反馈块和一个通道注意力门.

图3 深度反馈注意力结构的展开形式Fig.3 Expanded form of deep feedback attention structure
令Conv(f,n)和Deconv(f,n)分别表示具有n个大小为f*f的卷积核的卷积层和反卷积层,令ILR为低分辨率图像,经过特征提取后输入到注意力模块中的输入可表示为:
(1)
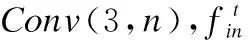
(2)
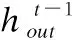
最终每一次迭代的注意力反馈模块的输出由重建模块进行重建,本文采用一个反卷积层Deconv(k,n)对输出的特征进行上采样,然后再用一个卷积层Conv(3,c)生成最终的SR残差图像.SR残差图像和原图像的上采样共同生成最终的SR结果.最终SR结果可以表示为:
(3)
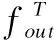
3.2 深度反馈注意力模块
3.1中介绍了从LR产生SR图像的整个线性过程,本部分将介绍在卷积-反卷积映射组以及注意力门中的具体迭代过程.
基于深度反馈注意力的映射模块主要由卷积块、反卷积块以及注意力门组成,卷积块和反卷积块的叠加可以实现特征重构并不断迭代,在反复的上下采样中计算累计的重构误差.这种迭代方式与DBPN[12]中的上反射与下反射单元的堆叠有略微不同,通过直接连接的卷积-反卷积层形成交错稠密连接的结构,这种连接方式可以实现特征的反复重构从而在约束浅层特征的同时保证梯度信息的有效传播.
(4)
接下来输入特征将由多个卷积块和反卷积块组成的级联组进行迭代重构,同时每一个组的输出都会与之前所有组的输出进行合并,在自反馈模块中,第t轮迭代第n个组的输入可以表示为:
(5)
其中fproj↑↓表示由卷积和反卷积层构成的一个反射组,该式表明了在迭代过程中,每一轮迭代的输入特征都是由当前输入特征与之前迭代过程产生的所有特征合并而来.输出特征接下来会通过注意力单元进行特征过滤,本文采用的通道注意力单元包含3个过程:挤压、激励以及放缩.
1)挤压函数
传统的注意力机制将特征全部展开并通过全连接层学习一个激励权重,本文借鉴了SE-Net[20]中的方式,通过计算每一个通道特征的全局平均值来代表整个特征图的特征值从而大大缩减后续权重矩阵所需的参数数量,基于全局平均池化的挤压环节可以表示为:
(6)
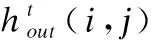
2)激励函数
激励函数通过学习特征值张量对应位置的权重来对各个通道的特征进行增强或抑制,该部分由两个带激活函数的全连层组成,激励环节可以表示为:
mt=σ(w2δ(w1×gt))
(7)
其中w1和w2分别为两个一维权重,δ表示ReLU函数,σ表示Sigmoid函数,最终激励函数给出一个维数与输入特征通道数相同的一个权重矩阵.激励函数是注意力机制里最核心的部分,通过学习的权重,可以对特征信息中对梯度响应较强的特征予以加强,同时对梯度响应较弱的无效特征予以抑制,从而增加模型学习到特征的准确性.
3)尺度函数
尺度函数利用上面过程学习到的通道注意里权重矩阵对原输入特征各个通道进行放缩,从而增强有效特征,抑制无用特征,放缩环节可以表示为:
(8)
如公式(8)所示,mt-1表示上一轮迭代学习的权重模板,×表示矩阵中各元素一一对应相乘,因此公式左边的部分表示上一轮迭代学习到的HR特征表示,mt表示该轮迭代学习的权重模板,其实际上学习的是与上一轮学习到的特征表示相对应的残差信息.该环节将本次迭代的注意力权重信息与上一轮迭代的权重相关联,从而构造迭代形式的残差注意力,具体而言,基于反馈与注意力机制提出了如下的结构.
第1轮迭代中注意力单元学习LR-HR的残差注意力权重,在后面的每一轮迭代中,注意力权重产生的特征图都会与上一轮迭代输出的特征进行叠加,结合上一轮的权重信息共同组成本轮迭代的输出.因此每一轮迭代模型学习到的注意力随着训练过程也在不断迭代加深.
4 实验与分析
4.1 数据集介绍
本文实验性能分析中主要使用DIV2K作为训练集,该数据集是NTRIE和PIRM竞赛采用的基准数据集,其中包含了900张2K分辨率的高质量png图片.在数据预处理上使用了和EDRN[22]相同的办法.采用PSNR和SSIM作为SR结果的评估指标.基准的测试集主要包括Set5[23],Set14[24],B100[25],Urban100[26]和Manga109[27].
为了和其他SR模型进行比较,本文和大多数方法一样选择双3次插值的方法来从HR图像中下采样得到LR图像,得到的LR图像与原HR图像共同构成了模型训练的标注数据集.为了适配卷积层的计算,输入图像在训练中均被切分成多个图像块(patch),块大小根据放大倍率设置为不同的数值,具体如表1所示.

表1 输入patch大小的设置Table 1 Settings of input patch size
本文训练模型时采用16的批处理大小(batch size),网络参数的初始化方法与[28]相同,选择Adam[29]作为训练优化的算法,初始的学习率设置为0.0001,并且每隔200个epochs衰减一半.本文提出的DFAN基于Pytorch框架实现,并且在NVIDIA1080Ti GPU上进行训练.
4.2 评价标准和参数设置
对于图像超分辨率的重建结果质量评价,常用的指标主要是峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM).
1)峰值信噪比
该指标主要从信号的角度衡量图片之间的相似程度,其定义如下:
(9)
其中MSE为图像之间的均方误差,n为像素值的位深,在本文的数据集中,n的取值为8,即像素值的最大值为28-1=255.PSNR的取值越大,证明两幅图像越相似,一般当PSNR取值大于38时,人眼便不容易分辨图像之间的差异.
2)结构相似性
结构相似性从图像组成的角度将结构信息定义为独立于亮度、对比度的,反映场景中物体结构的属性,并将失真建模为亮度、对比度和结构3个不同因素的组合,从而估计两个图像之间的相似程度.其定义如下:
(10)

SSIM的取值范围为0-1,当两幅图像完全一样时,SSIM的值为1.
本文的模型采用了基于距离的损失来进行优化.损失函数可表示为:
(11)
其中T表示迭代的轮数,Wt表示每轮迭代的输出权重矩阵.由于PSNR与MSE为负相关关系,许多模型依照MSE损失来进行优化,但以均方损失为基础的优化会导致结果在像素值上出现均值化的效应.同时,由于DFAN学习了很多深层残差信息,因此本文选择使用L1损失在规避均值化效应的同时,对参数施加一定的稀疏约束从而防止一定的过拟合.
除最后一层采用tanh激活函数以外,所有卷积层和反卷积层内都使用了PReLu[28]作为激活函数,本文按照[12]中的方法对应不同的倍率设置了不同的卷积核大小,步长以及填充量.具体的设置见表2.最后一轮迭代的输出将作为最终的超分辨率重建结果.

表2 卷积层参数设置Table 2 Settings of convolution layers
4.3 注意力模型消融实验
为了分析引入注意力模型带来的实际影响,本文对注意力模型在不同的结构下的超分辨率效果进行了比较.实验使用的模型包括4次迭代和3个卷积组,训练了200个epochs.结果如表3所示.

表3 不同的注意力结构的效果对比Table 3 Comparison with different organization of attention structure
DFAN-A表示不带有注意力的模型,DFAN-B表示引入了通道注意力但没有实现迭代残差结构的模型,DFAN代表引入了迭代残差注意力结构的模型.实验表明,单纯的引入注意力尽管略微提升了一点效果,但是网络的收敛速度受到了一定程度的影响.这种影响可能是由于多次迭代过程中注意力对特征的抑制作用的叠加效应,另一方面,在同时引入了结合反馈连接与注意力的结构后,网络的性能得到了进一步提升,这说明了注意力与反馈机制的结合可以削弱深层注意力带来的副作用,并强化反馈机制的作用.
我们还比较了引入深度反馈注意力机制的DFAN与其他主流模型之间的参数量和运行时间对比,如表4所示.所有的数据基于Urban100数据集上的4倍重建任务,结果表明相较于其他模型,DFAN能够在保持较小的参数量的情况下,达到较高的重建水平.
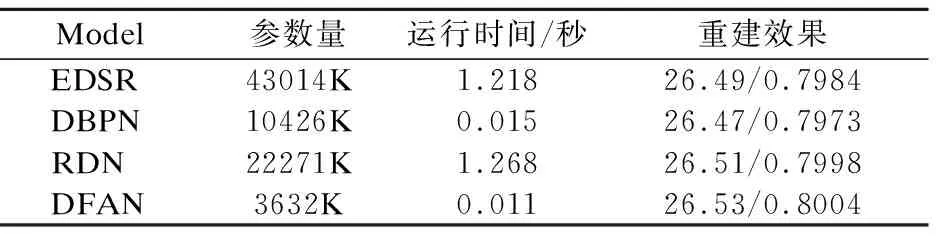
表4 模型规模与运行效率对比Table 4 Comparison of model size and execution time from different model
4.4 迭代次数对比实验
在DFAN中,模型在多轮反馈迭代后,通过迭代残差注意力不断学习更层次的注意力信息及图像特征,同时对网络参数不断地进行微调,并向最优解逼近.在迭代次数增加的同时,DFAN模型中的深度反馈注意力结构不仅仅加深了反馈传播的深度,同时也增加了注意力权重的准确程度.为了研究模型的参数学习与迭代次数的关系,通过比较迭代次数T的变化对重建效果的影响来分析反馈结构下的注意力级别对于模型重建精度的影响.

图4 关于T的模型损失与重建指标分析Fig.4 Loss and PSNR/SSIM results analysis of different T
如图4所示,当T从2增加至4时,训练损失扩大了,但是验证集上的损失反而下降了一些,这意味着增加一定的迭代深度可以有效抑制深层网络的过拟合情况,并提升一定的网络收敛速度.注意到T=3与T=4相比,训练集上的损失不断增大,但是重建效果相当接近.这是由于迭代层次进一步加深时,每轮迭代学习的是不断递进的残差信息,因此越往后的迭代学习到的参数会越稀疏.如表5所示的重建结果也印证了这一点.这表明过深的迭代次数可能会导致迭代残差注意力的学习陷入局部最优解.根据实验结果,最终认为T的取值应当在4上下浮动,最多不超过6,否则反馈连接带来的效果提升将会饱和.

表5 迭代次数的分析Table 5 Investigation of T
4.5 超分辨率效果对比
本文在5个基准数据集上用多个其他超分辨率方法与本文方法进行了对比实验.实验中图像特征的通道数都设置为64,DFAN中的迭代次数设置为4,参与比较的方法包括Bicubic,SRCNN[5],VDSR[17],LapSRN[30],DRRN[14],MemNet[9],EDSR[22],SRFBN[15]和DFAN.结果分别包括了放大倍率取{2,3,4}的情况,结果见表6.由于LapSRN不支持3倍的图像超分辨率,因此结果中省略了相应内容.更直观的视觉重建效果展示图5可知本文提出的模型能达到更好的重建效果,在细节上有更高的重建质量.

表6 ×2/×3/×4倍率下的超分辨率重建结果(PSNR/SSIM)Table 6 Average PSNR/SSIM for scale factor ×2/×3/×4 with bicubic interpolation degradation
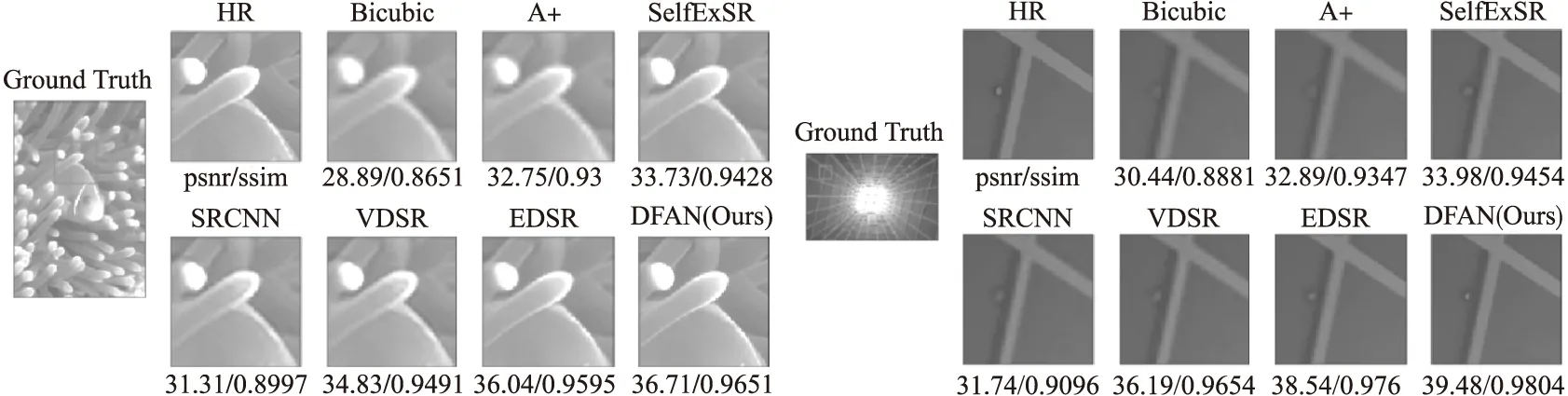

图5 不同模型在4倍放大下的重建视觉效果对比Fig.5 Visual results of super resolution by different model
5 结 论
本文提出了一种新的基于深度反馈注意力的图像超分辨率网络(Deep Feedback Attention Network,DFAN),该模型通过在反馈机制中形成迭代的残差注意以抑制冗余信息的传播,提高了特征学习的效率,并能够生成高质量的超分辨率图像.该方法通过反馈连接带来的参数复用缩减了模型的参数量,利用通道注意力建立了对特征学习的筛选机制,并在迭代中不断提升特征映射的准确度.实验部分验证了深度反馈注意力结构的引入确实改善了超分辨率网络的特征映射学习能力,减轻了过拟合以及收敛慢等问题,本文提出的方法优于当前同类型的图像超分辨率方法.下面的研究重点将在反馈注意力的基础上,结合人眼视觉的机制,进一步分析注意力机制在卷积神经网络中的作用,并研究新的注意力结构以实现更好的模型性能.
