深度学习节点分配的遗传算法设计
2021-05-24蔡恒雨郑启龙
蔡恒雨,郑启龙,2
1(中国科学技术大学 计算机科学与技术学院,合肥 230026)2(中国科学技术大学 国家高性能计算中心,合肥 230026)
E-mail:chy520@mail.ustc.edu.cn
1 引 言
近年来,深度学习[1]技术获得了快速发展,在自然语言处理、语音识别、图像处理和计算视觉领域取得了很多成果,并且广泛应用于各个领域.在2012年的ILSCVR竞赛中,在ImageNet[2]数据集上AlexNet[3]网络的错误率降低到15.3%.在2014年,VGG[4]系列网络将错误率降低到7.3%,GoogleNet[5]网络将错误率降低到6.67%.在2015年,ResNet[6]残差网络将错误率降低到3.57%.除了在视觉领域的快速发展,深度学习也逐渐应用于雷达信号处理中,提升雷达信号处理的效率.
随着深度学习的发展,深度学习模型变得越来越大.单个计算设备难以满足深度学习模型的训练和推断需求,通常需要将模型部署在分布式计算平台上,并搭配相应的计算通信库.GPU(Graphics Processing Unit)作为高性能计算设备的代表,具有较强的计算性能和较高的显存,经常被用于深度学习模型的部署和训练.为了更好的实现多GPU的并行计算,英伟达公司设计了NCCL和CUDA,NCCL可以在InfiniBand[7]上实现快速通信,CUDA[8]可以提供计算架构,两者相结合更好的实现了深度学习的部署.在NCCL基础之上,加州大学伯克利分校与微软共同发布GPU通信库Blink[9].
BWDSP系列处理器[10],是由中电科38所研制的国产单核数字信号处理器,具有完全自主的知识产权.在此基础上设计了BWDSP众核虚拟平台,并设计了并行通信接口MPIRIO,可以提供更高的计算能力和存储资源.遗传算法(GA)[11]可以看作是生物进化理论与搜索优化技术的组合,主要是用来解决组合优化问题,如背包问题[12]、多机调度问题[13]和旅行商问题等都属于NP-Hard[14]问题.
BWDSP众核虚拟平台和MPIRIO并行通信接口,为深度学习模型的部署提供了基础条件.本文考虑采用遗传算法,解决深度学习模型在BWDSP众核虚拟平台上的节点分配问题,充分利用虚拟平台提供的计算和存储资源,加速深度学习模型的训练和推断过程.本文接下来的组织如下:第2部分介绍BWDSP虚拟平台、深度学习和遗传算法相关知识;第3部分介绍深度学习模型节点分配的遗传算法设计;第4部分介绍相关实验和分析;第5部分是总结.
2 BWDSP虚拟平台和相关知识
2.1 BWDSP虚拟平台
BWDSP处理器作为国产DSP芯片,内部体系结构采用多簇设计方案,具有多个乘加器,适合计算密集型的应用.其指令系统采用VLIW和SIMD架构,可以在一个指令中同时执行多个数据操作,提供并行计算能力,理论计算性能达到14GFLOPS.内部存储空间分为16个block,共有6MByte的存储空间,可以通过DDR3/4接口外接存储器.
BWDSP处理器采用单核结构,在此基础上设计了相应的BWDSP众核虚拟平台.BWDSP单核虚拟平台架构示意图如图1所示,板卡上配有4个BWDSP模型,外部存储器模型和数据交换模型,其中交换模型支持RapidIO[15]协议和Ethernet[16]交换协议.BWDSP单板卡上提供了出板卡的端口,可以通过级联其它单板卡形成众核虚拟平台.
在BWDSP众核虚拟平台的基础上,设计了并行通信接口MPIRIO,提供了类似MPI标准的通信接口,并对其中的群集通信接口进行了优化.深度学习模型中主要包括数据通信和数据计算节点,而MPIRIO提供的通信接口可以实现数据通信,适合深度学习模型的部署,同时也方便用户部署计算任务和使用.
2.2 深度学习和遗传算法
深度学习模型的发展历程,总体上是由简单到复杂,对计算资源和存储资源的需求越来越大.其快速发展主要有下几个原因:
1) 深度学习框架不断完善.随着深度学习技术在学术界和工业界的发展和应用,出现了多种深度学习框架,如Tensorflow[17]和MXNet等.
2) 计算设备的不断发展.高性能计算设备如DSP、CPU、FPGA和GPU都在不断发展,提供了更高的计算能力和更大的存储资源.
3) 深度学习模型越来越大.早期的深度学习模型结构比较简单,可能发生过拟合问题[18].现在的深度学习模型可以达到十几层和上百层,如VGG16、VGG19和ResNet等,模型的精度更高.
遗传算法是一种通过模拟自然进化过程来搜索最优解的方法.在计算机领域中,存在着许多优化问题,其中某些优化问题属于NP-Hard问题,即无法在多项式时间内解决的问题.针对NP-Hard类问题,可以考虑使用遗传算法,在有限时间内获得一个较优解.
3 深度学习节点分配的设计
深度学习模型的训练过程包括前向传播和反向传播过程,其示意图如图2所示.其训练过程涉及计算节点如何分配到计算设备上,将该问题抽象为优化问题,可以使用遗传算法解决该问题.本文设计了静态遗传算法和动态遗传算法解决该问题.
3.1 深度学习训练过程分析
深度学习模型中的卷积运算属于典型的计算密集型运算,通常具有较少的权重参数,但是却占了整个模型近90%的计算量.设输入数据为一张图片,其通道数为c_in,图片的高为h_in,图片的宽为w_in,卷积核的数量为c_out,卷积核的尺寸为k_h×k_w(通常k_h和k_w是相等的).输出的张量高为h_out,张量宽为w_out,通道数为c_out,需要的乘法计算量为com_m,加法计算量为com_a,总的计算量为com_t,分别满足公式(1)和公式(2).卷积运算需要的存储量为mem_t,分为输入数据存储量mem_in,卷积核存储量mem_k,输出数据存储量mem_out,其关系满足公式(3).
(1)

(2)

(3)
全连接层与卷积层相反,权重参数量很大,占用了很多的存储资源,而计算量比卷积层小的多,通常是二维的矩阵乘法.设输入数据为二维矩阵,高和宽分别为h_in和w_in,权重参数矩阵w的维度为h_wei和w_wei,偏置值为bias,其维度是h_in,其中w_in等于h_wei.全连接层需要的计算量为com_full,需要的存储资源为mem_full,满足公式(4)和公式(5),其中bias需要的计算量很小,可以忽略不计.

(4)
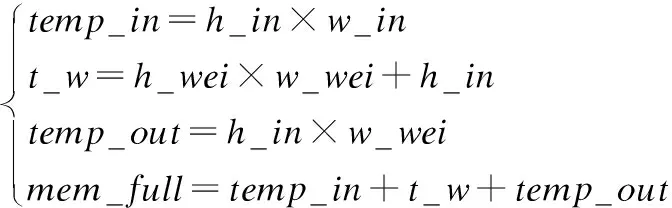
(5)
3.2 静态遗传算法设计
静态遗传算法是指,对于深度学习模型的各个计算节点,预估其所需要的计算资源和存储资源,然后结合各设备的计算能力和存储资源进行分配.BWDSP众核虚拟平台提供的带宽很大,结合MPIRIO并行通信接口,使得数据传输时间可以被BWDSP的计算时间所覆盖.静态遗传算法中弱化了数据通信时间的限制,重点分析BWDSP众核虚拟平台如何使用遗传算法加速模型的训练过程.
预估深度学习模型各层的计算时间,主要是计算量.深度学习模型各层需要的存储空间,主要包括输入数据、权重参数和输出数据所需要的存储空间.设计了相关函数来获得模型各层的计算和存储消耗,主要有以下函数:
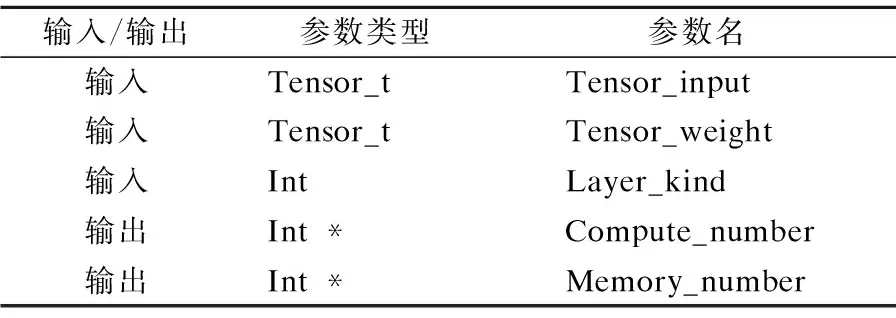
表1 compute_memory_prediction()介绍Table 1 Introduction of compute_memory_prediction()
1)compute_memory_prediction()函数:该函数的参数介绍如表1所示,返回值为布尔类型.其中tensor_t是自定义结构体,用来代表张量,其中包括张量的维度以及各维的大小,以及数据指针.输入参数包括输入和权重张量,以及层类型layer_kind,对于卷积层和池化层,设计单独的函数获取计算和存储消耗.输出包括计算量和存储量.

表2 conv3_compute_memory_prediciton()介绍Table 2 Introduction of conv3_compute_memory_prediction()
2) conv3_compute_memory_prediction()函数:该函数的返回值也是布尔类型,用于获得卷积操作的计算量和存储量.该函数的参数介绍如表2所示,输入参数包含输入数据tensor_input,卷积核参数tensor_kernel,滑动步长参数stride,填充参数pad和是否具有偏置值标志bias_flag.本设计中滑动步长在水平和垂直方向是一样的,只有一个滑动步长参数stride.输出参数也是计算量和存储量.
深度学习模型具有n层,有m个计算设备,满足n>m的条件,当n≤m时,理论上来说将模型的每一层分别放在每个计算设备上可以使模型训练时间最短.模型的每层在每个设备上的计算时间构成一个时间矩阵time=[...]n×m,其中timeij表示模型第i层在第j个设备上的计算时间.存储矩阵memory=[...]n×m,其中memoryij表示模型第i层在第j个设备上需要的存储空间.各个计算设备具有的存储资源构成一个设备存储矩阵M=[...]m,其中Mj表示第j个设备所具有的存储资源.
静态遗传算法主要包括以下几个步骤:
1)编码:本设计中采用整数编码的方式,x是一个长度为n的整数串,x={a1,a2,...,an}(1≤ai≤m,i=1,2,...,n),ai代表模型的第i层放在第ai个计算设备上.
2)选择:本设计中采用轮盘赌算法,即每个个体的适应度得到一个概率值,该概率值表示传递给下一代的概率.
3)交叉:在两条父染色体(分配方案)中同时选择一个交叉位,然后将两条父染色体的后面部分交换,形成新的染色体,如图3所示.
4)变异:选择一条染色体(分配方案),将其中的一位或多位变异生成新的分配方案如图3所示.
5)消除不可行解:通过设置每个计算设备都需要被使用的约束,如公式(7)所示,其中countij表示模型的第i层是否放在第j个计算设备上.可以将某些不符合约束条件的染色体进行调整,使其变为符合约束条件的解,如图3所示.本设计中的约束条件主要是每个BWDSP芯片的存储资源有限.
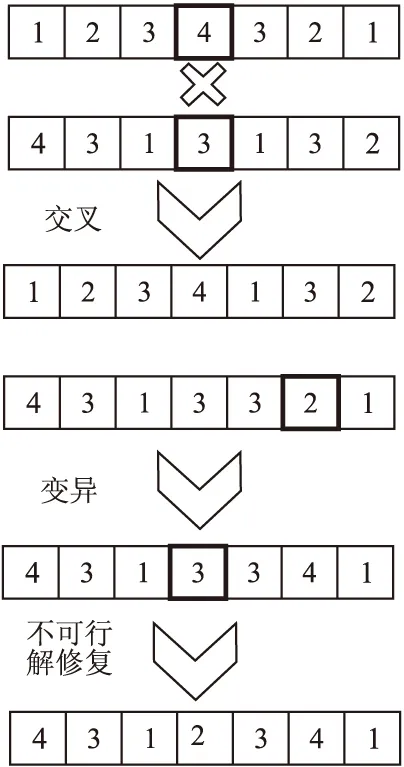
图3 静态遗传算法交叉变异示意图Fig.3 Schematic diagram of static genetic algorithm cross mutation
6)优化目标:优化目标f是深度学习模型节点分配在各个BWDSP模型上,需要计算时间最大的BWDSP模型其执行时间越小越好.优化目标如公式(6)所示,其中ti代表在第i个计算设备BWDSP上最终需要的计算时间.
7)适应函数:遗传算法的进化原则是适应度好的个体留下来,而优化目标是最小的计算时间,所以设计如公式(8)所示的适应函数.其中T是加上约束条件的计算时间,而F是适应函数值,αj作为惩罚系数设置为2.
f=min max(t1,t2,...,tm)
(6)
(7)
(8)
静态遗传算法视为二重迭代算法.迭代次数为E,种群大小C,每个个体进行深度学习训练时间为t.每个个体占用的存储资源为s.由于t和s都是通过函数预估计算出来的,所以可以用一个常数t_const来代表t,用常数s_const代表s,则使用静态遗传算法时间复杂度近似为O(E×C×t_const),空间复杂度近似为O(n×C+C×s_const).
3.3 动态遗传算法设计
动态遗传算法是指,将深度学习模型的每一个分配方案都进行编码,然后将其分配到各个计算设备上运行.根据运行时间求得适应度函数,再选择较优的个体遗传到下一代.该算法与静态遗传算法的区别在于,通过实际运行深度学习模型获得计算时间,得到的结果更加准确.

图4 动态遗传算法框架图Fig.4 Dynamic genetic algorithm framework
动态遗传算法的基本框架如图4所示,采用整数编码方式.整体过程类似于静态遗传算法的步骤,主要包括种群初始化,适应度值计算,个体选择、交叉和变异,生成下一代种群等过程.动态遗传算法与静态遗传算法主要有如下几点区别:
1)动态遗传算法中,每次深度学习模型的分配方案一旦确定,就需要将其在BWDSP虚拟平台上进行运行,收集实际的运行时间.采用公式(7)和公式(8),对某些不可行解进行修复,并进行惩罚操作,获得最终得适应度值.
2)深度学习模型在BWDSP虚拟平台上运行时,虚拟平台的拓扑结构会影响模型中不同层间的通信时间.当BWDSP虚拟平台较小时,各BWDSP设备的距离比较近,所以通信时间可以被数据计算时间所覆盖.当BWDSP虚拟平台较大时,对于距离较远的BWDSP设备,通信时间可能无法被计算时间所覆盖.此时数据流水线会受到影响,得到的模型分配方案运行时间较长.
3)动态遗传算法得探索空间更大,静态遗传算法中模型节点的计算时间和存储空间已经预估出来,探索空间相对确定.动态遗传算法在实际运行过程中,可能会发现某些深度学习模型分配方案,这些方案更适合BWDSP虚拟平台拓扑结构,而该分配方案是静态遗传算法难以发现的.
动态遗传算法的过程也视为二重迭代算法,分别为种群迭代次数和每代种群个体数.迭代次数为E,种群大小为C,个体进行深度学习训练时间的平均值为T,占用的存储资源为S,则动态遗传算法时间复杂度近似为,空间复杂度近似为.动态遗传算法中的时间是深度学习模型的实际训练时间,而静态遗传算法中时间是通过函数计算得到的,两者可能会存在误差.
深度学习模型中存在多级并行性,如一个批次通常包含多条数据,每条数据通常用多维矩阵表示等.由于BWDSP虚拟平台上各个BWDSP芯片提供的存储资源有限,将深度学习模型的训练过程变为流水线形式,即一个批次的输入数据按照流水线送入虚拟平台中,得到虚拟平台运行模型的时间.
MPIRIO通信接口中提供了mpirio_send函数和mpirio_recv函数,可以实现向量数据发送.深度学习模型中的数据通信,通常是张量形式的数据,将其转化为矩阵后,以向量的形式通过MPIRIO的通信接口发送.MPIRIO还提供了优化的broadcast、gather和reduce等操作接口,这些接口适合深度学习模型的数据并行训练方式.本文主要描述深度学习模型的模型并行训练方式,使用MPIRIO通信接口提供的点对点通信函数.
4 实验及评估
实验过程主要是设计一个深度学习模型,使用静态遗传算法和动态遗传算法分别训练,获得模型在BWDSP众核虚拟平台上的分配方案.
本次实验使用的BWDSP虚拟平台拓扑结构如图5所示,是由两个BWDSP单板卡虚拟平台组成,共有8个BWDSP芯片模型.
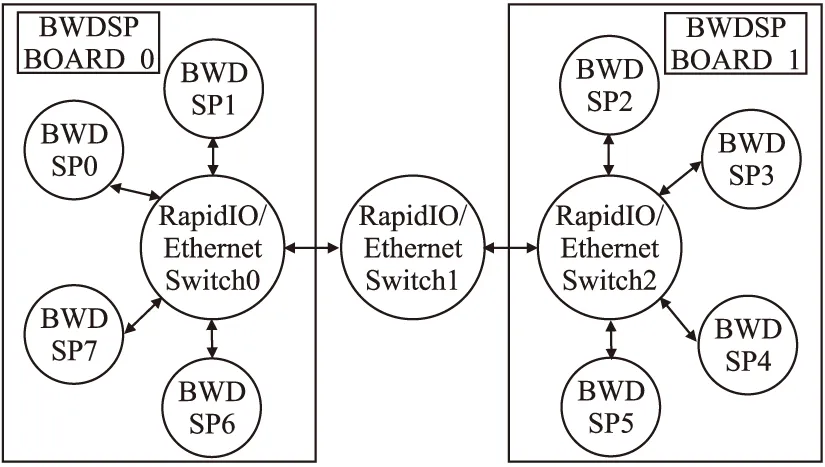
图5 实验使用BWDSP虚拟平台拓扑结构图Fig.5 Experiment uses BWDSP virtual platform topology structure diagram
本次实验设计了一个10层的深度学习模型,其结构如图6所示.由于本设计的重点是验证遗传算法解决深度学习模型节点在BWDSP虚拟平台上的部署,主要分析卷积层和全连接层的影响.激活层计算量和存储量较小,池化层分析过程类似于卷积层,所以设计的深度学习模型主要包括全连接层和卷积层.

图6 实验使用深度学习模型结构Fig.6 Experiment using deep learning model structure
4.1 静态遗传算法测试
静态遗传算法首先要对深度学习模型进行预估,即预估模型各层的计算量和存储量.使用本文设计的compute_memory_prediction()函数和conv3_compute_memory_prediction()函数,对图6所示的模型进行预估,得到的模型每层的计算量和存储量如表3所示.

表3 实验模型每层计算量和存储量Table 3 Calculation and storage of each layer of the experimental model
以表3中第1层的数据分析,输入数据维度是3×128×128,卷积核参数维度是16×3×3×3,步长是2,填充长度是0.根据公式(1)和公式(2),对于一条三维输入数据,需要的计算量是3342336,与表3中数据一致.按照公式(1)和公式(3),需要的存储量为115120,由于数据通常是整型或者浮点类型,统一为浮点类型后每个数据需要4字节的存储空间,故需要的存储空间为460480字节,大约0.47M的存储空间.表3中第6层的数据,输入数据维度为128×32×32,权重参数维度为1024×100.根据公式(4)得到计算量为26201600,根据公式(5)得到存储量为246272,需要的数据存储空间为985088字节.
将表3中计算量和存储量进行转化,获得在BWDSP设备上的计算时间和数据存储空间,生成的数据见表4.BWDSP的理论计算性能可以达到14GFLOPS,实际计算性能可以达到12.87GFLOPS.
分析表4中的数据可以发现,深度学习模型每层的数据存储空间消耗小于1MByte,故限制每个BWDSP芯片的存储空间为1MByte,则虚拟平台提供8M的数据存储空间.8M的数据存储空间,可以完整的部署深度学习模型,同时也可以测试多个计算节点分配在1个BWDSP芯片模型上,可能出现的违反约束条件的情况.

表4 实验模型计算时间和数据存储空间表Table 4 Experimental model calculation time and data storage space table
深度学习模型用静态遗传算法得到的分配方案结果如表5所示,变异算子设置为0.1,交叉算子设置为0.6,种群大小为100,遗传算法迭代次数为10000次.表5中6种分配方案的优化目标都是11.080523MS,这是因为本次选择的模型中第5层的计算时间较长,在最后获得的最佳分配方案中第5层的计算时间起决定性因素.

表5 静态遗传算法测试结果Table 5 Static genetic algorithm test results
以表5中第1条数据为例进行分析,详细分配表示模型的第1层分配在0号BWDSP上,模型的第2层分配在2号BWDSP上,依次类推.观察这6条数据,可以发现当模型的第5层分配在某个BWDSP设备上后,该设备上不会分配其它模型层,原因是该层占据了较多的计算量.
为了证明静态遗传算法具有一定的灵活性,重新设置BWDSP虚拟平台中各个BWDSP模型的数据存储空间大小,验证该深度学习模型在虚拟平台上的部署,得到了与表5类似的实验结果.对深度学习模型第5层及之后的模型层进行修改,调整权重张量,使模型第5层的计算量有所减少,模型各层在整体上更加平衡.然后部署在BWDSP虚拟平台上,验证了静态遗传算法的灵活性和有效性.
4.2 动态遗传算法测试
基于图6所示的深度学习模型,进行动态遗传算法测试.在动态遗传算法中,对于变异因子和交叉因子,分别设置为0.1和0.6,种群大小为100,与静态遗传算法保持一致.动态遗传算法的迭代次数设置为1000次,主要考虑到训练消耗时间,并且在迭代1000次之前算法已经得到较优分配方案.
动态遗传算法中,对于每一个深度学习模型的节点分配方案,都需要将其部署在BWDSP虚拟平台上运行.如果模型当前层和下一层不在同一个BWDSP模型上,就需要使用MPIRIO提供的MPIRIO_send()和MPIRIO_recv()通信函数.
动态遗传算法测试结果如表6所示,最终得到的单个BWDSP芯片的最长计算时间在12MS左右.得出的分配方案运行时间比静态遗传算法略长,是因为系统中存在3个交换模型,交换模型的转发速度限制了模型上一层的输出数据及时到达模型下一层.观察表6中的数据,可以发现每个模型分配方案中,模型的第5层与第4层或者第6层分布在不同BWDSP单板卡上,由于第5层需要的计算时间较长,采用这种分配方案可以让传输时间较长与计算时间较长达到相互配合.动态遗传算法能够发现这种规律,并且在迭代过程中生成了相应的分配方案.
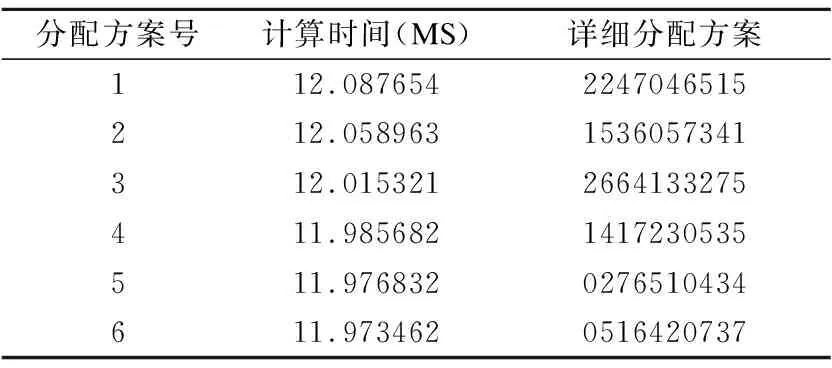
表6 动态遗传算法测试结果Table 6 Dynamic genetic algorithm test results
动态遗传算法在不同批次大小的情况下,其训练消耗时间比较大.对于图6所示的深度学习模型,其完整的前向传播过程在单个BWDSP模型上需要大约31MS.在BWDSP众核虚拟平台上,其需要的流水线时间Time满足公式(9).其中full代表一个完整的前向传播的时间,即31MS,batch_size代表一批输入数据的数量,part代表流水线中最长的一段的时间,即12MS.如果以单个BWDSP模型训练一批数据,其所需要的时间为Full_time,满足公式(10).动态遗传算法得到的分配方案,相比单个BWDSP模型的加速比为P,满足公式(11).
Time=full+(batch_size-1)×part
(9)
Full_time=full×batch_size
(10)
(11)

表7 动态遗传算法在不同批次大小训练时间Table 7 Training time of dynamic genetic algorithm in different batch sizes
从表7中可以看出,当batch_size为50时,单个模型个体的训练时间为619MS,动态遗传算法训练耗时达到61900S,超过了17个小时.动态遗传算法通过训练阶段消耗大量的时间,得到一个较优的分配方案,在实际模型训练和推断的过程中节约时间.
4.3 实验总结
上述实验结果表明:静态遗传算法和动态遗传算法,两种算法都可以得到较优的模型分配方案.静态遗传算法首先预估模型需要的计算资源和存储资源,利用预估数据代表模型的训练开销,进行遗传算法优化,得到模型较优的分配方案.动态遗传算法通过深度学习模型的实际训练,收集训练时间开销,得到较优的分配方案.
5 总 结
本文在BWDSP虚拟平台和MPIRIO并行通信接口的基础上,分析了深度学习模型在训练过程中需要的时空资源,并使用遗传算法优化深度学习模型在BWDSP众核虚拟平台上的部署.设计了静态遗传算法和动态遗传算法,静态遗传算法可以在较快的时间内获得一个较优的模型分配方案,但损失了一些时间上的准确度.而动态遗传算法通过在训练阶段消耗更多的时间,得出较优的模型分配方案,并且获得更加准确的模型训练时间.两种遗传算法得出的深度学习模型分配方案,都可以加速深度学习模型在BWDSP众核虚拟平台上的部署和运行,提高了BWDSP众核虚拟平台的可用性.
本文中重点讨论了模型的前向传播过程,之后的工作重点需要考虑模型的反向传播过程,如何在遗传算法优化模型节点分配的过程中,优化深度学习模型的参数.本文考虑的深度学习模型结构比较简单,之后需要对残差网络和跳跃网络等进行分析,并用遗传算法优化其在BWDSP众核虚拟平台上的部署,提升本文遗传算法的适用性.
