基于梯度提升决策树的变形宏病毒检测①
2021-05-21位凯志
闫 华,刘 嘉,位凯志,古 亮
1(中国科学院 深圳先进技术研究院,深圳 518071)
2(深信服科技股份有限公司,深圳 518071)
高级持续性威胁(Advanced Persistent Threat,APT)是危害企业信息安全的主要攻击形式,也是当前网络安全布防的重点.其最常见的方式之一是通过鱼叉攻击诱骗受害者打开恶意邮件的Office 附件,并运行其中的宏病毒程序,进而入侵受害者的计算机和网络.例如,2020年2月,印度APT 组织以新冠肺炎疫情题材的鱼叉邮件对我国卫生部门和相关企事业单位投放宏病毒.可见,宏病毒检测是抵御APT 攻击的重要环节.
传统反病毒系统对被检测样本做静态分析,通过查询病毒数据库的方式检测病毒[1,2].病毒数据库D=Dhash∪Drule包 含病毒文件哈希库Dhash和病毒规则库Drule,其中病毒规则r∈Drule是包含通配符和逻辑算子的字符串匹配模式.给定被测样本 ε,若ε的哈希值dε在病毒哈希库中(dε∈Dhash),或者ε 符合病毒规则r∈Drule,则判定ε为病毒[3,4].
变形是病毒绕过反病毒系统的重要手段[1-5].令σP为程序P的语义,变形g通过替换标识符、插入冗余代码、动态执行字符串和打乱指令顺序等方式产生P′=g(P),使得P′≠P且 σP′=σP.
与传统的Windows PE (Portable Executable)病毒不同,对宏病毒进行变形无需考虑编译和二进制重写等因素,因此成本低廉且方式灵活[5,6].例如,通过添加空白字符等简单修改,即可绕过病毒文件哈希库Dhash;通过混淆程序的字符串模式等略复杂的变形,即可绕过病毒规则库Drule.宏病毒变形是对传统病毒检测方法的挑战.实践表明,传统反病毒系统查杀变形宏病毒的效果较差[1,2,4-6].
研究者提出使用机器学习的方法,训练模型在高抽象层次上识别变形病毒的不动点,从而检测变形病毒[5-9].然而,现有方法在特征工程、机器学习算法选型、样本规模和样本真实性方面均存在局限性,导致了其在效果方面的不足,限制了其在工业界的应用和推广.
本文介绍一种基于机器学习的变形宏病毒检测方法──OVD (Obfuscated VBA Detector).与传统反病毒系统不同,OVD 不依赖文件的哈希值和病毒规则,而是使用机器学习算法训练模型,然后通过模型预测文件是否为病毒.与现有的基于机器学习的方法相比,OVD 在特征工程规模、特征工程精细度、样本规模和样本真实性等方面优于现有工作.在特征工程方面,与现有工作[5-9]不超过20 维的特征工程不同,OVD 采用520 维的细粒度特征工程.在训练集方面,OVD 基于用户真实场景的海量样本采集.在性能方面,OVD以轻量级的词法分析器作为预分析器,避免对被测文件做重量级的语法分析或语义分析.
在400 万个样本上的实验表明,OVD的召回率和准确率分别为97.34%和99.41%;对比文献[5]的方法在相同样本集上的召回率和准确率分别为72.97%和88.87%.在机器学习算法选型方面,实验对比支持向量机[10]、随机森林[11]、梯度提升决策树[12]和多层感知机[13].实验数据表明,在大规模样本集上,梯度提升决策树的效果最佳.
1 总体框架
如图1所示,OVD的总体框架包括训练和查杀两个阶段.在训练阶段,首先采集宏病毒样本,形成文件样本集 Ω;然后对文件ω ∈Ω按Office 文件的格式标准[14]进行结构化解析,并对其中的宏程序做词法分析;基于文件解析和词法分析做特征提取,生成特征向量xω;最后,应用机器学习训练算法,生成宏病毒模型f.在查杀阶段,首先解析被检测文件ε,并对其宏程序进行词法分析,进而提取特征向量xε;通过f对xε进行预测,从而判断ε是否为变形宏病毒.
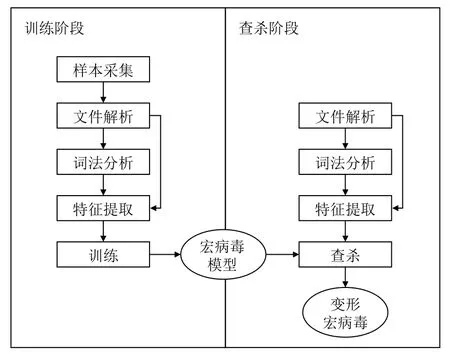
图1 OVD的总体框架
2 梯度提升决策树
在有监督机器学习中,一种典型的集成学习方法是提升法(boosting)[12].它迭代地将M个弱学习器(或基函数)h{1},h{2},···,h{M}∈H集成为一个强学习器f;在第i轮迭代向f{i}中集成h{i}时,被在第i-1 (1<i≤M)轮迭代中预测错误的样本被赋予较高权重.梯度提升法在训练中使用梯度下降法最小化损失函数,如算法1.

算法1.梯度提升树算法{(x(i),y(i))}n i=1输入:数据集,假设空间H,损失函数L,迭代次数M,学习率v输出:梯度提升决策树i=1L(y(i),γ)1f0=argmin γ n∑2 for m∈{1,2,···,M}do:]3 γ{m}(i)=-[∂L(y(i),f(x(i)))∂f(x(i))f=f{m-1},∀i∈{1,2,···,n}(r{m}(i)-h(x(i)))2 4h{m}=argmin h∈H n∑i=1 L(y(i),f{m-1}(x(i))+γh{m}(x(i)))5 γ{m}=argmin γ n∑i=1 f{m}←f{m-1}+νγ{m}h{m}6 return f{m}7
梯度提升决策树是以决策树为基函数的提升法,即限定基函数的假设空间H为回归树:
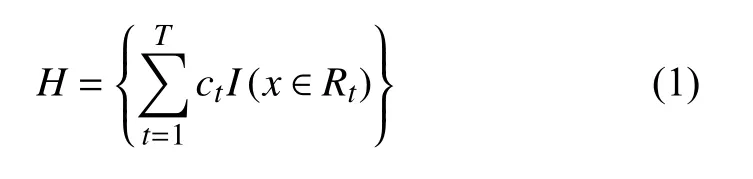
其中,T为叶子数量,ct为在Rt区域内的预测值.
3 面向变形宏病毒的特征工程
基于病毒专家在大量变形宏病毒样本上的研究经验,将OVD的特征工程分为若干子任务,如图2所示.子任务的划分依据病毒专家经验和实验分析.本章各小节详细介绍各子任务产生的特征与变形病毒属性之间的相关性.各子任务的必要性和特征工程粒度的合理性在实验中论证(见5.4 节).OVD的细粒度特征工程是效果驱动的,仅考虑对区分变形宏病毒和正常宏程序有贡献的特征;OVD 不考虑无效特征,例如Office文档的内部目录结构和文件修改日期等.
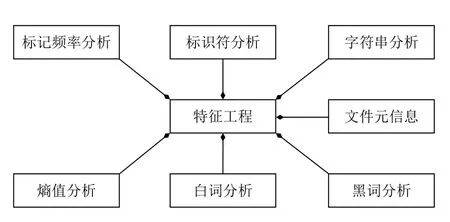
图2 特征工程任务分解
3.1 标记频率分析
通过词法分析,OVD 得到宏程序的标记(token)集合,并统计每种标记的频率.其意义在于:变形宏病毒较频繁地使用某些类型的标记,而较少使用其他类型的标记.对标记按类型统计频率可以为区分变形宏病毒和正常文件提供重要参考.例如,表示字符串拼接的标记“+”和“&”在变形宏病毒中比较常见,因为字符串拼接是使病毒规则失效的常用手段.如图3所示的真实病毒样本中的宏程序,出现了较多的“+”.再比如,一种常见的变形手段是将恶意代码隐藏在大量无实际意义的整数常量计算中.因此,整数常量的数量是识别变形宏病毒的有效特征之一.OVD的词法分析器识别220 种标记,表1列出了几种对识别变形宏病毒有较大贡献的标记.OVD 在样本特征向量中记录每种标识符的数量和频率.

图3 使用字符串拼接的变形宏病毒

表1 OVD 识别的典型词法标记类型
3.2 标识符分析
正常程序一般使用有意义的单词或词组,通过驼峰法等方式为变量名和函数名等标识符命名.变形宏病毒程序的标识符与正常程序往往有明显不同,其典型特点包括:① 元音字母较少;② 大写字母占比较高;③ 数字占比较高;④ 长度较大;⑤ 长度方差较小.例如,在图4所示的真实宏病毒程序中,标识符平均长度超过20,且标识符内容全部为大写字母,这与正常程序有明显区别.OVD 统计宏程序中标识符的平均长度、长度方差、平均元音字母占比、平均大写字母占比、平均小写字母占比和平均数字占比,并记入样本的特征向量.
3.3 字符串分析
利用脚本语言的动态特性,通过执行字符串形式的动态代码完成恶意行为是躲避反病毒系统的常用手段.因此,字符串在变形病毒中出现频繁.一种典型的变形方式是将恶意代码编码为字符串,然后将其分割为大量子字符串,再动态地通过拼接、反转和解码等操作将恶意代码还原,从而在不改变恶意代码语义的前提下对其灵活变形,绕过传统反病毒系统的病毒规则库.图5是一个真实的宏病毒程序.该病毒程序通过大量的字符串拼接操作达到变形的目的.

图4 标识符平均长度超过20的变形宏病毒

图5 含常量字符串的变形宏病毒
OVD 统计宏程序中的字符串数量,并记入特征向量.另一面,一种典型的字符串变形手段是通过对超长字符串编码,从而隐藏有效载荷(payload).针对该变形手段,OVD 统计字符串的平均长度,识别常见编码格式(如base64)的超长字符串,并统计其数量.
下载器(downloader)是一类常见的宏病毒.它通过网络下载并自动运行其他类型的病毒.这类宏病毒程序往往出现“powershell”、“exe”和“download”等关键字符串.OVD 统计这些关键字符串的数量和频率,并记入特征向量.
3.4 文件元信息
文件元信息与文件是否为病毒有相关性.例如,为了便于病毒在网络中扩散传播,鱼叉邮件中的Office 文件附件通常较小.因此,病毒Office 文件的体积和其中病毒宏程序的体积有一定规律.基于此现象,OVD 将Office 文件的体积和其中宏程序的体积记入特征向量.另一方面,一些变形宏病毒将恶意代码隐藏在Office文件的自定义属性中,并通过从自定义属性中取值的方式在宏程序中还原恶意代码.因此,OVD 在样本的特征向量中记录自定义属性的数量和属性内容的平均长度.
3.5 黑词分析
对宏病毒程序统计词频,结合病毒专家经验,得到宏病毒中出现较多的标识符集合;排除正常宏程序中出现较多的标识符集合,形成黑词库Wblk=-.给定被测样本ε,OVD 统计ε 中每个黑词w∈的出现次数和频率.表2列出了部分OVD 识别的黑词.图6是一个真实变形宏病毒示例,其中含有document_open、chr和shell 等黑词.注意,OVD 对英文字母大小写不敏感.

表2 OVD 识别的部分黑词

图6 含OVD 所识别的黑词的变形宏病毒
3.6 白词分析
3.7 熵值分析
研究表明,变形恶意程序的信息熵[15]高于正常程序[9].给定被测样本ε,OVD 计算ε 在其滑动窗口上的平均信息熵,算法如算法2 所示.更具体地,OVD 以500字节为宽度生成 ε的滑动窗口集合S,对所有滑动窗口s∈S计算信息熵,并取平均值记入ε的特征向量.
4 大规模样本采集
样本规模是保证机器学习效果的重要条件.主流的现代反病毒系统采用云端分离的分布式的架构.如图7所示,“云”一般部署在反病毒厂商,“端”是指反病毒系统的客户端.在客户端部署样本上传模块,将客户端的文件样本通过网络采集到云上,实现大规模样本采集.
通过宏程序变形工具,进一步对恶意样本变形,可增加变形宏病毒的样本数量.样本集包含主流变形工具生成的变形宏病毒样本.主流变形工具包括:macro_pack[16]、Macroshop[17]、vba-obfuscator[18]、VBad[19]、Veil Framework[20]、Generate-Macro[21].通过杂交,进一步扩大样本集.令 φ为杂交操作,给定正常样本和,则仍为正常样本;给定变形宏病毒和,则仍为变形宏病毒.
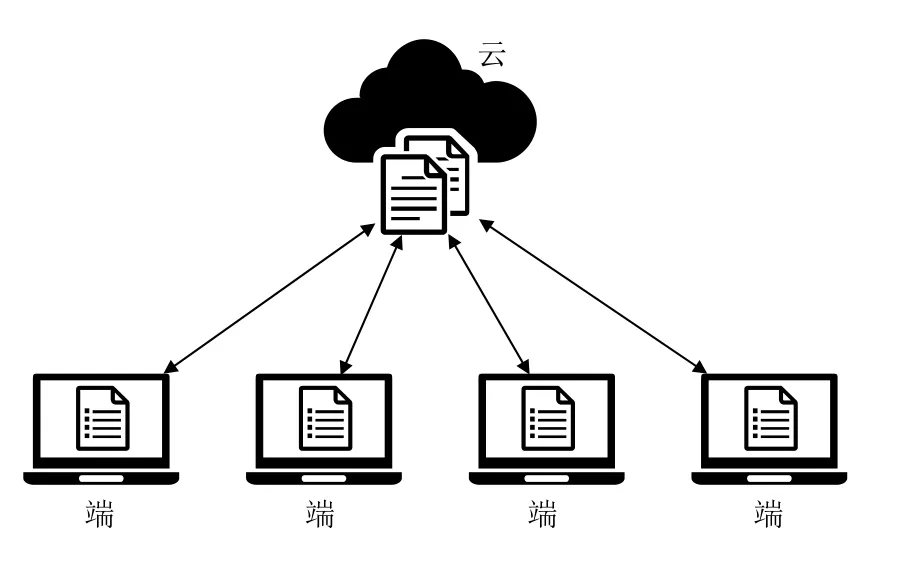
图7 分布式的反病毒系统部署
5 实验分析
采用XGBoost[22]作为梯度提升决策树的实现,样本空间大小|Ω|=4000 000,样本集分布如表4所示.实验平台为3.5 GHz Intel Xeon 16-core CPU,256 GB 内存,操作系统为Ubuntu 18.04 LTS.实验进行5 次,取平均值作为结果.令TP为被分类正确的恶意样本数量,TN为被分类正确的正常样本数量,FP为被分类错误的正常样本数量,FN为被分类错误的恶意样本数量.正确率(accuracy)、准确率(precision)和召回率(recall)的定义分别为:

5.1 OVD的实验效果
采用网格搜索优化XGBoost的超参数.决策树数量为1000,树高为6,学习率为0.1.采用16 线程,训练时间为13 410 s.采用10 折交叉验证,实验效果如表5所示.OVD的正确率、准确率和召回率分别为98.38%、99.41%和97.34%.由于变形工具和杂交算法的规律性,OVD 对变形工具和杂交算法生成的恶意样本的识别能力比真实样本更强.

表4 样本集分布
5.2 机器学习算法的对比
基于Scikit-learn[23]对比了支持向量机、随机森林、梯度提升决策树和多层感知机的效果.结果如图8所示.梯度提升决策树在正确率、准确率和召回率上均高于其他3 种机器学习算法.
梯度提升决策树的两种主流实现是XGBoost和LightGBM[24].使用相同的超参数(决策树数量为1000,树高为6,学习率为0.1,采用16 线程训练),对XGBoost和LightGBM的实验结果如表6所示.XGBoost 在正确率、准确率和召回率均略高于LightGBM,而在训练时间方面LightGBM 优于XGBoost.因为宏病毒检测对检测效果的敏感性,故XGBoost 更优.

表5 OVD的实验效果

图8 机器学习算法的对比

表6 对比XGBoost和LightGBM
5.3 与相关工作的对比
文献[5]提出的基于多层感知机的方法,采用15维特征对宏程序向量化,并使用多层感知机作为机器学习算法.文献[5]的工作仅基于2537 个样本(其中变形宏病毒样本773 个,正常样本1764 个)进行实验,准确率和召回率分别为93.80%和91.50%.
在4000 000 样本集上通过两组实验对比OVD和文献[5]的方法:① 对比文献[5]基于多层感知机的方法在大样本集和小样本集上的效果差异;② 采用梯度提升决策树,对比文献[5]提出的15 维特征和OVD的520 维特征.表7给出实验结果.虽然文献[5] 基于15 维特征的方法在小样本集上取得了较好的正确率、准确率和召回率,但在大样本集上的效果较差.一种可能的解释是样本量过小导致过拟合.在大样本集上的实验结果表明:① 梯度提升决策树(MLP)的效果优于多层感知机(XGB);② OVD的特征工程优于文献[5]的方法.

表7 对比文献[5]的方法和OVD
5.4 特征工程粒度的合理性分析
通过实验分析特征工程各子任务(图2)的必要性.基于4000 000 样本,将各子任务t从特征工程T中去除,对比T-{t}和T的效果,以验证t的必要性.实验结果如表8所示.其中,去除特征工程的任意子任务t,总体检测效果在综合考虑正确率、准确率和召回率时降低.特别的,去除白词分析,虽然召回率小幅提升,但正确率和准确率下降;去除熵值分析后,虽然准确率小幅提升,但正确率和召回率下降.基于上述分析,OVD的特征工程中的各子任务对优化总体检测效果具有必要性.

表8 特征工程子任务的必要性分析
在扫描时间方面,对单个样本做全量特征工程T的平均耗时为57.65 ms,其中文件解析和词法分析的平均耗时为45.02 ms.表9给出各子任务t的平均时间开销.所有子任务共产生28.01%的时间开销.该指标属于合理范围,不影响工业级应用推广.各子任务t均不产生明显的内存开销.

表9 特征工程子任务的时间开销
6 结语
本研究提出了OVD—一种基于梯度提升决策树的变形宏病毒检测方法.与传统的基于病毒数据库的检测方法不同,OVD 通过机器学习在高抽象层次对变形宏病毒的不动点建模,实现了良好的泛化性.OVD 面向工业级应用,基于专家经验实现了520 维的变形宏病毒特征工程,较现有方法粒度更细.介绍了特征工程及其各子任务的功能和设计思路.实验验证了细粒度特征工程的合理性,并讨论了其性能影响.大规模数据集上的实验表明,OVD 能有效检测变形宏病毒,准确率和召回率分别达到99.41%和97.34%,优于现有方法.
