基于机器学习的水文系列插补延长模型研究
2021-05-19翁茂峰刘莹莹寇思飞刘蕊蕊
翁茂峰,刘莹莹,寇思飞,梁 曦,刘蕊蕊
(1.中国电建集团西北勘测设计研究院有限公司,西安 710065;2.陕西省水利电力勘测设计研究院,西安 710001)
0 前 言
水文计算工作常需较长系列的水文资料。随着系列长度的增加,水文计算准确性越高。由于水文站迁移、特殊原因撤站、水利工程建设等影响因素,导致无法保证水文系列中的连续[1],而且常规的水文分析方法在预测缺失系列数据时,存在一定的缺陷[2-3]。传统的插补延长方法是基于同一流域不同水文站之间存在线性关系得以使用,但不同水文站数据受到许多因素的影响,可能存在非线性关系。因此,需要新的方法来实现有效的水文系列插补延长。
在过去的几十年中,机器学习(ML)[4]技术已被证明是解决具有多参数的非线性回归和分类问题的强大统计工具。它可通过学习以前的事件来制定输入属性和输出目标之间的潜在相关性,而无需进行显式编程。近年来,学者们已经普遍认识到机器学习算法(MLA)的效率优于线性统计方法。机器学习算法中能用于数据分析预测的模型包括增强回归树、分类、回归树、多元自适应回归样条、支持向量机、随机森林、和混合判别分析等,并且类似的新颖算法已在其他领域成功实现[4-6]。
在这些新算法中,支持向量机回归(SVR)、BP神经网络和XGBoot模型都具有较好的效果。其中支持向量机回归(SVR)[4-5]遵循SVM的回归策略,该策略已被广泛应用于山洪和洪水阶段的预测,洪水频率,滑坡和水位。BP神经网络[6]是较为常用的人工神经网络,具有较好的预测性能。XGBoot模型[7]基于梯度提升决策树算法,可以有效地防止过拟合现象,具有较为优秀的性能。不过,这些模型尚未用于水文系列插补延长领域。因此有必要利用这些模型来预测水文系列,以达到有效的插补延长效果。此外,为了凸显机器学习模型的效果,本文也利用传统线性模型的方法进行水文插补延长,并对这些模型进行对比分析。以期为水文系列插补延长提供新的有效方法。
1 机器学习模型原理
1.1 支持向量机模型
支持向量机回归(Support vector regression, SVR)[5,8-10]模型是根据内核统计学习理论,以结构风险最小化原则为基础的一种新型机器学习方法,其特点是能够解决小样本、非线性和高维数据空间模式识别等问题(Vapnik 1995)。SVR的类型有epsilon-SVR和nu-SVR 2种,常用的核函数类型有线性linear核函数、多项式核函数、径向基RBF核函数、sigmoid核函数等。在SVR中,核函数类型、惩罚参数Cost、核参量gamma等3个参数对建模精度有很大的影响[11-13]。本研究中,核函数类型需经多次试算来确定,用训练集交叉验证和网格搜索法(Grid search)进行参数寻优,按照均方差最小原则确定惩罚参数Cost和核参量gamma的值[14]。
1.2 XGBoost模型
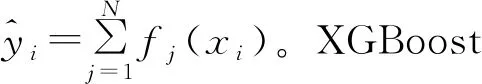
1.3 BP神经网络模型
BNP结构是多层感知器(MLP),通常使用误差反向传播(EBP),简称为反向传播算法(BP)作为算法[17-20]。BPN的主要组件如下所示:
(1) 输入层:代表神经元编号的网络输入变量,用于由特定问题确定的处理。更多的输入神经元导致更高的BPN复杂度,并在控制训练时间和错误收敛方面更加困难。
(2) 隐藏层:代表输入单元之间的交叉影响。隐藏层的数量可以是一个或多个,通常通过故障测试方法或经验法则来确定,而优化的数量则取决于测试收敛效果。
(3) 输出层:代表具有特定问题确定的待处理神经元数量的网络输出变量。
神经网络具有较高的准确率,因为它可以构建非线性模型并表示变量之间的交叉。另外,神经网络具有高度的适应性,可以接受逻辑、数字、有序分类、无序分类的变体作为输入,并且可以广泛地应用于函数反射、数值数组预测、样本分类、数据/图表压缩和图像识别。
对于SVR、XGBoost以及BPN,使用PLS-Toolbox工具箱实现。
1.4 模型评价指标
通过决定系数R2和均方根误差(Root mean squared error,RMSE)来综合评价模型的效果。R2越接近于1,RMSE越接近于0,表征模型的预测精度越高,预测能力越强。R2和RMSE的计算公式如下:
(1)
(2)
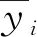
2 应用实例
为验证应用机器学习技术建立水文模型来解决水文系列插补延长问题的适用性,选取了位于陕西省安塞县延河流域的安塞水文站[21](地理坐标东经109°19′,北纬36°56′)和位于陕西省延安市上砭沟村的枣园水文站[22](地理坐标为东经109°20′,北纬36°38′)。其中安塞水文站控制流域面积1 334 km2,有1981—2015年实测水文资料。枣园水文站控制流域面积719 km2,有1971—2015年实测水文资料。
利用1991—2015年的2个站点数据作为建模集,用以校正模型。1981—1990年的两站数据作为验证集来验证及评价模型。
2.1 相关性分析
由于安塞水文站与枣园水文站在不同河流上,为了确认两者之间是否存在相关关系。对两者的数据进行相关性分析,发现两者之间的相关系数为0.78,其显著性水平可达P>0.001(极显著)。由此可以发现,2个站点之间存在一定的相关关系,为后续的研究分析提供了基础。
2.2 建模过程
利用PLS-Toolbox工具箱,进行编程,将站点数据导入。并以1991—2015年的2个站点数据建立模型,再用1981—1990年的数据来验证模型效果。具体计算过程在计算机中进行。
2.3 线性模型结果

图1 线性模型建模散点图
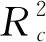

图2 线性模型验证散点图
2.4 机器学习模型结果
2.4.1支持向量机模型结果
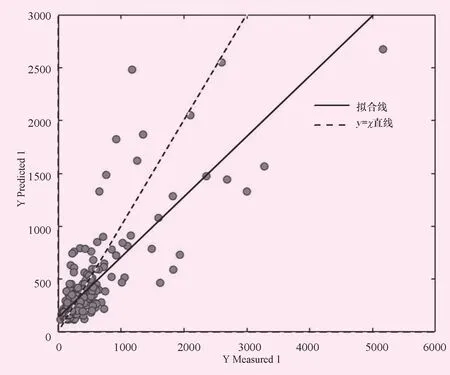
图3 支持向量机模型建模散点图

图4 支持向量机网格寻优结果图
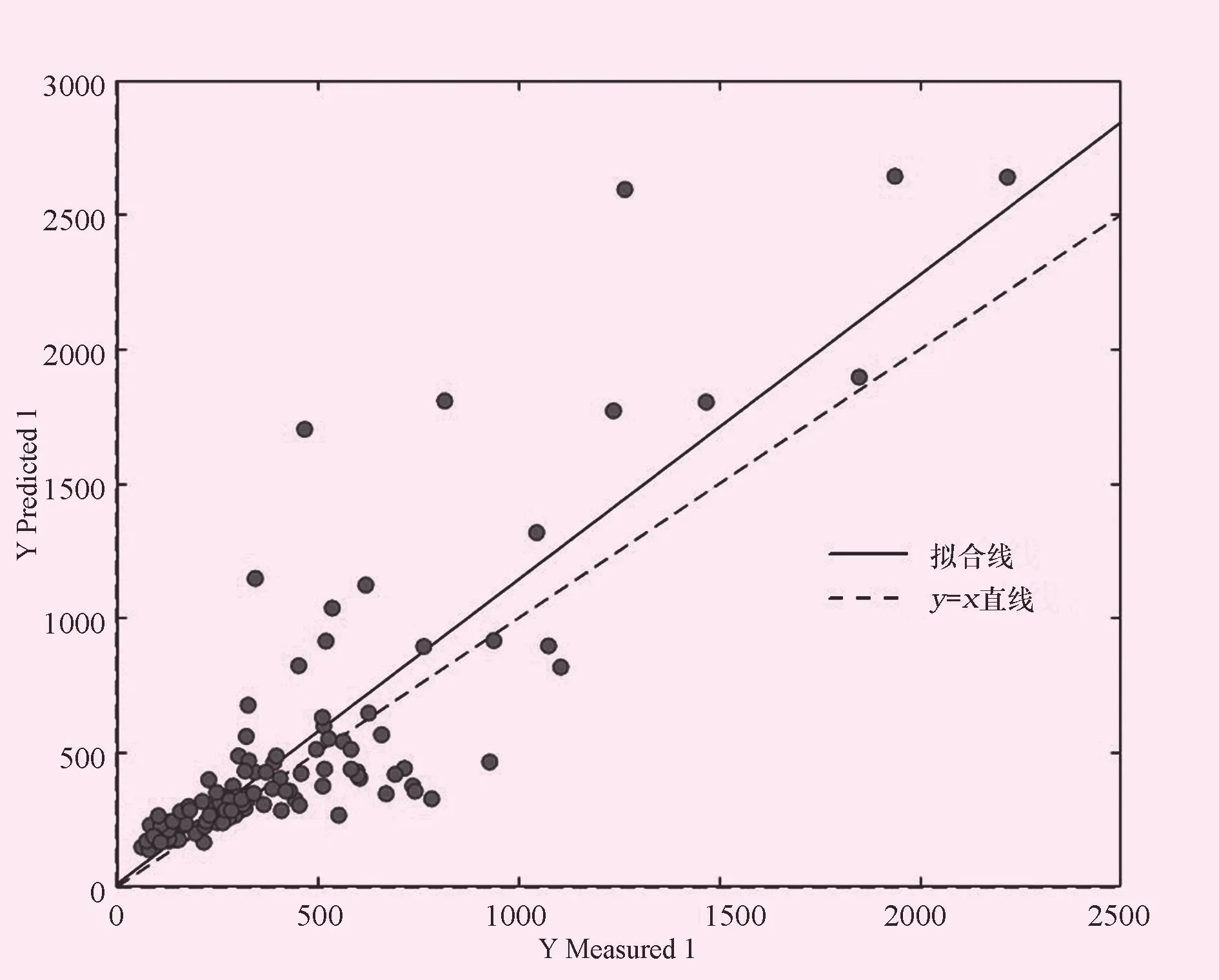
图5 支持向量机模型验证散点图
2.4.2XGBoost模型结果
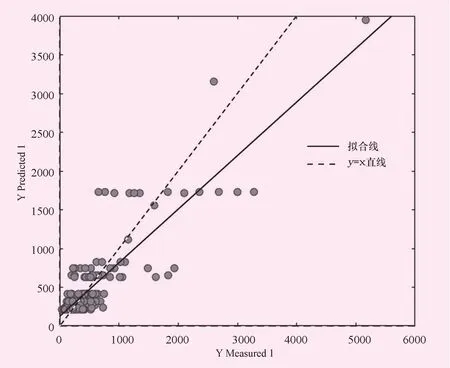
图6 XGBoot模型建模散点图
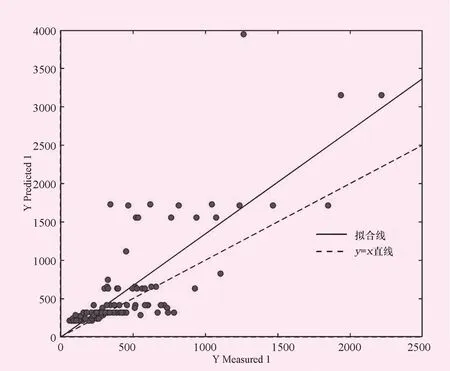
图7 XGBoot模型验证散点图
2.4.3BP神经网络模型结果

图8 BP神经网络模型建模散点图
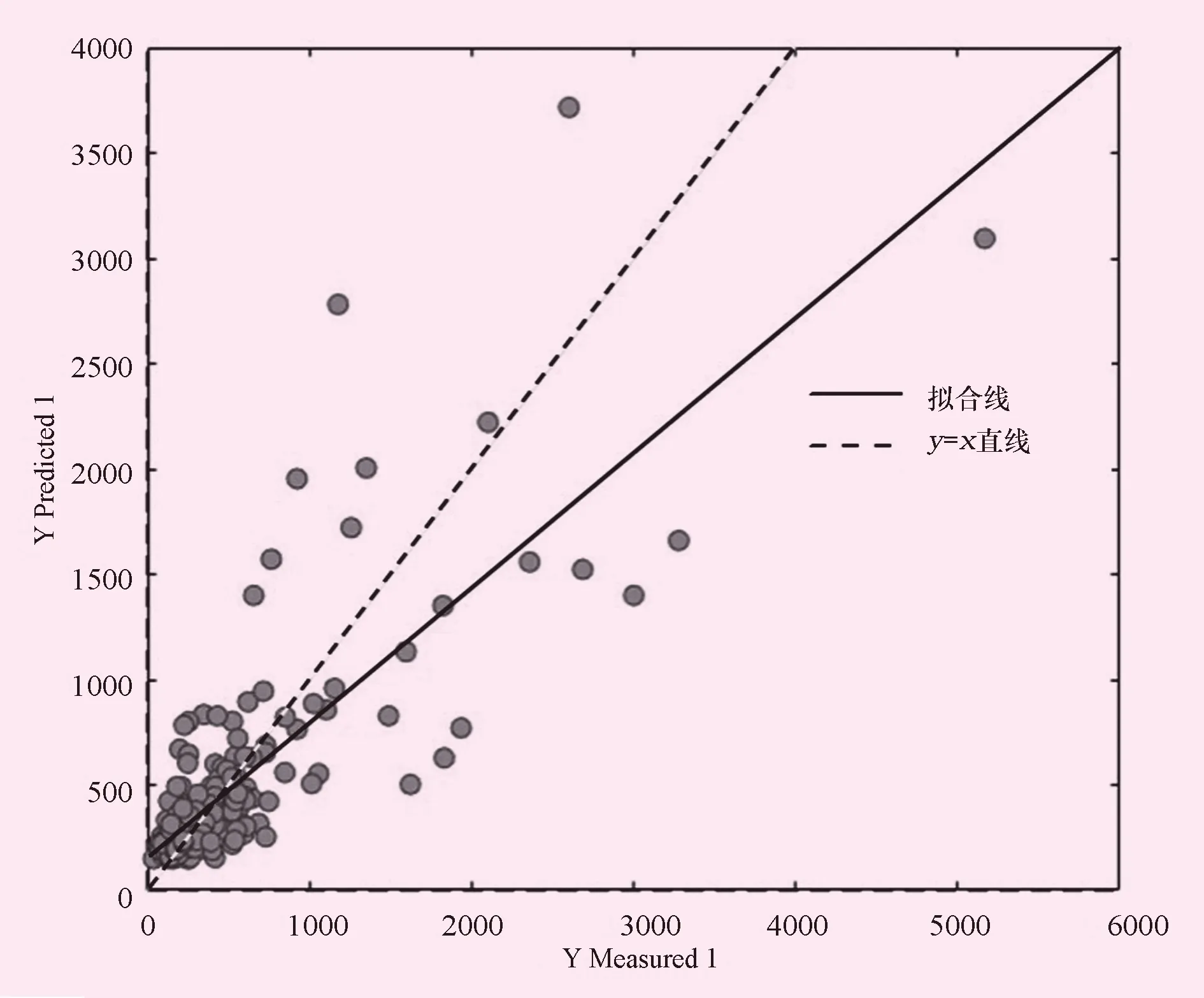
图9 BP神经网络模型验证散点图
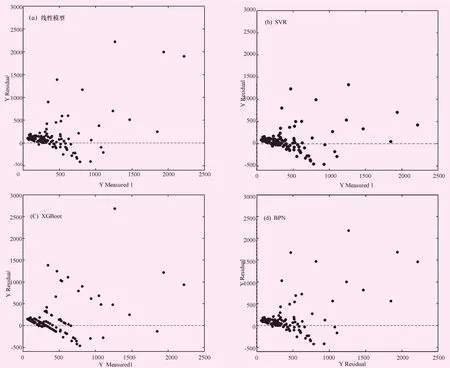
图10 不同模型的残差分布图
2.5 模型对比分析
为了便于直观的对比模型,绘制以下模型残差分布图。图中的散点表示,各个预测值与实测值的差距,离虚线越远,表示其偏差越大。对比4幅子图可以发现,XGBoot模型的残差分布最广,其范围在-500~3 000万m3之间。线性模型其次,其残差范围在-500~2 500万m3之间。BPN模型与线性模型的效果基本接近,残差范围也与其基本相似。所有模型中SVR的效果最佳,其残差范围最窄,为-600~1 400万m3,说明SVR模型更加适用于水文插补延长。此外,从建模效果上比较也可以发现,XGB模型的效果最佳,但是验证效果较差,说明该模型过拟合,并不适合用于水文插补延长。而其余3个模型中SVR模型其建模效果和验证效果都较好,相比较而言,模型更稳定。
3 结 论
本文将不同类型的机器学习模型应用于水文径流系列插补延长,并与传统的水文插补延长模型进行对比。得到以下结论:

(3) SVR模型结合网格寻优可以得到有效的水文插补延长模型,其验证均方根误差仅为271.88万m3。
