基于集成学习的疾病预测模型研究
2021-04-29刘金花王洋赵婧
刘金花, 王洋, 赵婧
(1. 山西医科大学汾阳学院 卫生信息管理系, 山西 汾阳 032200;2. 北方自动控制技术研究所, 山西 太原 030006)
0 引言
目前大多数人遭受各种慢性疾病的困扰,如心血管疾病、糖尿病、肾衰竭等,病人除了需要花费大量时间和金钱进行治疗外,还会遭受各种并发症的困扰[1]。因此,慢性疾病的早期识别和检测已成为全球的热点问题,并在临床实践中发挥着至关重要的作用。近年来,各种数据挖掘技术和机器学习算法被用来预测和诊断疾病。但是,现有模型都假设用于训练模型的数据是完美的。
本研究的主要目的是以糖尿病为例建立一种具有更高可靠性能的疾病预测模型,综合考虑并解决了目前模型中存在的数据的缺失值、数据类别不平衡和分类评价指标选取三个问题。首先,采用补偿算法对缺失数据进行填补。然后,选择一种合适的过采样技术来解决类别不平衡问题。最后,通过一组对比实验来选择合适的、优秀的分类器。本研究所提模型的框架,如图1所示。
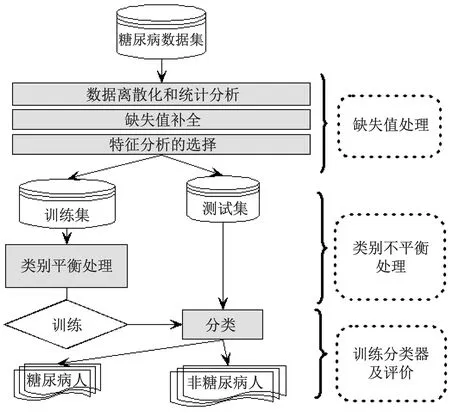
图1 本研究所提模型的框架图
在整个实验过程中,采用了临床试验中比较关注的指标来评价分类性能。实验表明,本研究所提模型在皮马印第安人糖尿病数据集上取得了较高的性能,比同一数据集上的其他预测模型性能更好、更可信。
1 相关工作
目前已经提出了许多糖尿病的预测模型。V. Anuja Kumari[2]采用以径向基函数为核的支持向量机,准确率达到78%。Vijayan[3]采用AdaBoost算法,以决策树(Decision Tree,DT)、贝叶斯(Naïve-Bayes,NB)、支持向量机(Sup-port Vector Machine,SVM)和决策残差作为基分类器,使用决策残差获得了80.72%的最佳准确率。Maniruzzaman[4]发现医学数据的结构具有非正态性、非线性和内在相关性。因此,他们采用了基于高斯过程的分类,采用了线性、多项式和径向三种核的分类方法,使用径向核的分类准确率达到了81.97%。前面所述这些文献都是在原始数据集上直接进行实验,而没有考虑数据的质量。Maniruzzaman[5]首先用中位数替换缺失数据和离群值,提取糖尿病数据集的特征。对比10种不同的分类器,实验表明,随机森林(Random Forest,RF)特征选择和RF分类技术的准确率为92.26%,灵敏度为95.96%,特异度为79.72%。Birjais[6]采用K-近邻(K-Nearest Neighbors,KNN)对缺失数据进行填补,梯度提升分类器的准确率达到86%。但这些方法的数据中均存在大量缺失和类别不平衡问题。
2 研究材料和方法
2.1 数据分析和缺失值填补法
本研究使用的数据来自UCI机器学习知识库的皮马印第安人糖尿病数据集[7-8]。对该数据集属性的描述,如表1所示。
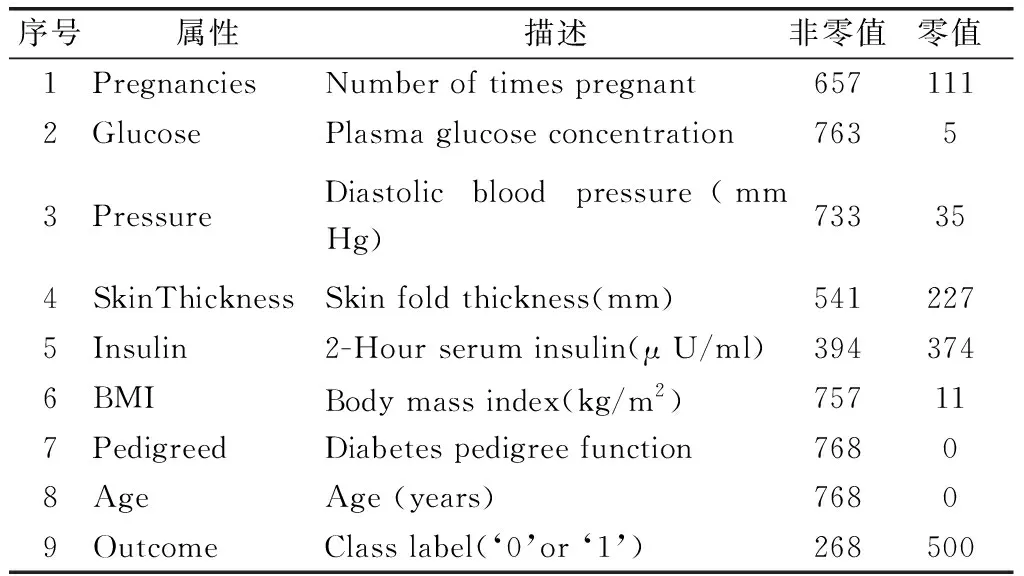
表1 皮马印第安人糖尿病数据集描述及缺失值统计
包括268名患者和500名非患者。很明显,患者人数远远超过非患者。举一个极端的例子,如果所有的样本都预测为非糖尿病患者,就可以达到65.1%的准确率。不平衡数据集会削弱学习算法预测少数类别的能力,这个结论已经得到了验证[9]。因此,在数据类别不平衡的学习任务中,仅用准确率来评价分类性能是不可信的。此外对数据集进行了统计分析,因为有大量缺失值。
各类大数据集中特别是医疗数据中存在大量的缺失值是很正常的,然而,数据的纯度和完整性是机器学习算法的基础。补偿法是处理缺失值最常见的手段。在这里,本研究采用了条件均值填补方法,即根据类标签将数据集分为糖尿病和非糖尿病两组,缺失的值由每个组的平均值替换。
2.2 特征选择和分析
在基于机器学习的研究中,良好的数据是基础,而特征是数据表示的基石。糖尿病数据集有8个属性(特征),本研究还对数据进行了基于皮尔森相关系数的特征相关分析,如图2所示。
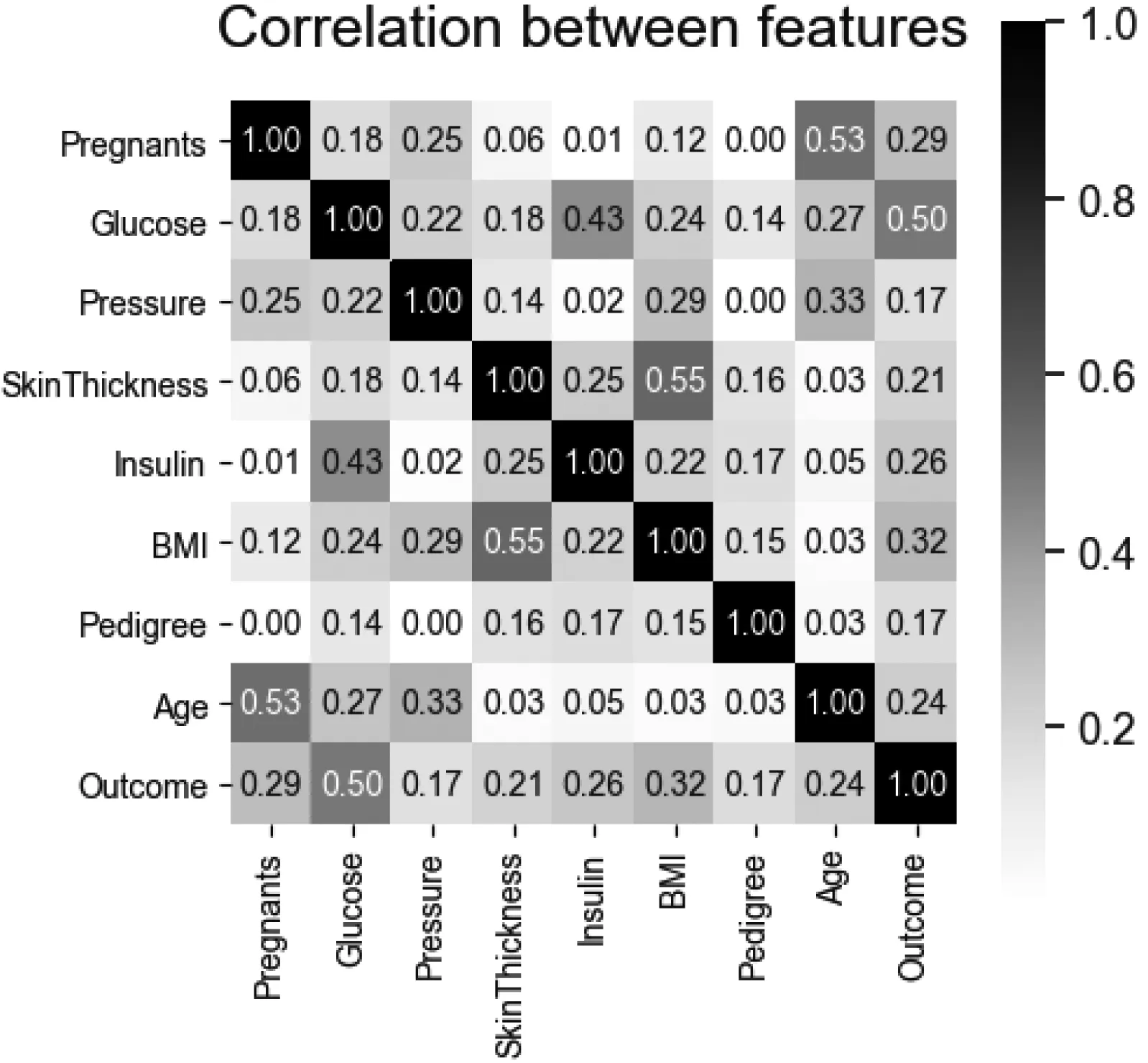
图2 糖尿病数据集间特征的相关性分析
所有8个特征与结果呈正相关。而血糖、BMI、胰岛素、怀孕次数是糖尿病的重要特征。此外,年龄与怀孕、血压这两属性的相关性较大,BMI与皮瓣厚度的相关性较大。所以选择了除了Pedigreed 属性之外的其他7个属性作为最后的特征。
2.3 数据类别平衡处理
针对类别不平衡问题,已经提出了许多解决方案,如欠采样、过采样、代价敏感学习法、基于集成的方法等[10]。由于人工合成少数类样本的过采样技术(Synthetic Minority Over-sampling Technique,SMOTE)是通过随机生成新实例来扩充数据,而不是简单地从原始数据中复制现有样本[11]。因此,这里使用了SMOTE来解决类不平衡的问题。
对于给定的少数类样本x,求得它与其他少数类样本之间的最近邻,并计算它们的差值(距离)。然后,随机选取0和1之间的数乘以该差值,并将其添加到原始样本x中。生成新样本,如式(1)。
(1)

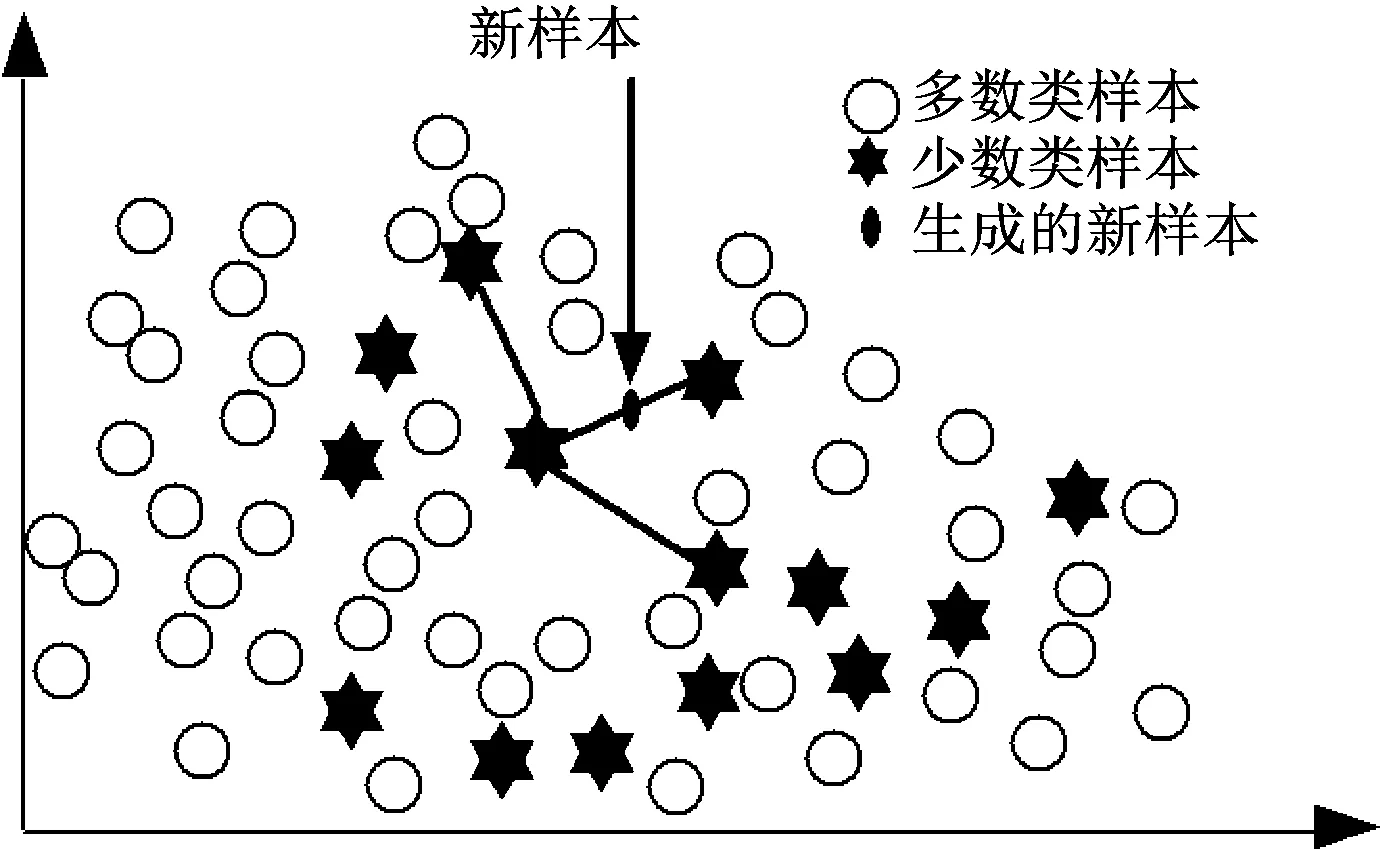
图3 SMOTE生成新样本的过程
3 梯度提升树
梯度提升决策树(Gradient boost decision tree,GBDT)是另一种强大的集成算法。其核心思想与随机森林一样,GBDT采用迭代的方法建立决策树,并通过减少损失函数对模型进行评估。沿着损失函数梯度下降的方向,GBDT不断更新当前模型的参数,不断地对模型进行调优使损失函数收敛到全局最小。

(1) 初始化预测模型F0(x)为一常数,如式(2)。
(2)
其中决策树分类器γ也初始化为常数。
(2) 循环迭代m=1:K(K为最大迭代次数). 每迭代一次构建一个基于回归树的弱分类器,并且生成相应的预测值Fm(x). 负的梯度计算,如式(3)。
-gk(x)=-[∂L(yi,F(xi))/∂F(xi)]F(x)=Fm-1(x)
i={1,2,…,N}
(3)
(3)h(x;αm)为弱分类器建立的回归树,第m个回归树应该沿着m-1次损失函数梯度下降的方向建立。因此,参数αm利用式(4)进行更新。
(4)
(4) 沿梯度下降的方向优化步长,将使损失函数逐步变小,如式(5)。
(5)
(5) 在每次迭代后,模型的预测函数将随之进行更新,如式(6)。
Fm(x)=Fm-1(x)+βmh(xi;α)
(6)
4 实验与分析
4.1 实验设置
为了消除属性之间的差异,在实验之前,首先得对数据进行归一化处理。为了获得稳定可信的结果,本实验采用了十折交叉验证策略。
4.2 评价指标
由于糖尿病数据存在缺失和类别不平衡的问题,本研究引入更多的指标来充分评价分类性能。除了ACC、灵敏度、特异度,还有接受者操作特性曲线(Receiver Operating Characteristics, ROC)和ROC曲线下的面积(Area under the ROC,AROC)。AROC指标是一种较好的医学诊断指标,在理论和实践上都得到了验证。上面提到的这些指标都是基于混淆矩阵定义的。混淆矩阵,如表2所示。

表2 混淆矩阵
准确率(Accuracy,ACC)是指分类器正确预测阳性样本或阴性样本的能力。如式(7)。
(7)
灵敏度(Sensitivity,SEN)表示分类器在实际阳性样本中识别阳性项的能力。SEN与医学上的漏诊率密切相关,如式(8)、式(9)。
(8)
MissedDiagnosisRate=1-Sensitivity
(9)
一般来说,一个好的疾病预测模型应该提高SEN,降低漏诊率,因为阳性样本指的是糖尿病患者。反之,特异性(Specificity,SPE)则表示分类器识别实际阴性样本中阴性项的能力SPE在医学上与误诊率有关,如式(10)、式(11)。
(10)
MisdiagnosisRate=1-Specificity
(11)
特异性是医学上的另一个主要指标,SPE越低,误诊率越高。因此,一个良好的诊断模型应尽量减少误诊率和漏诊率,也就是提高诊断的SEN和SPE。
ROC是一个综合指标,权衡SEN和SPE。ROC曲线是以SEN为纵坐标,1-SPE(也称为误诊率)为横坐标绘制的曲线。AUC是ROC的数量指标,指ROC曲线下方的面积。理论上,AUC的取值为[0,1],在理想的分类器中,AUC的值应该是1。
5 结果与讨论
为了验证本研究所提方法在每个阶段的性能,设计了多组对比实验。此外,除了本研究提到的GBDT算法外,还选取了RF、NB、DT和逻辑回归(Logistic Regression,LR)三种传统的分类算法进行实验。本研究采用5个分类器对原始的糖尿病数据集进行分类,并将其结果作为基准,如表3所示。
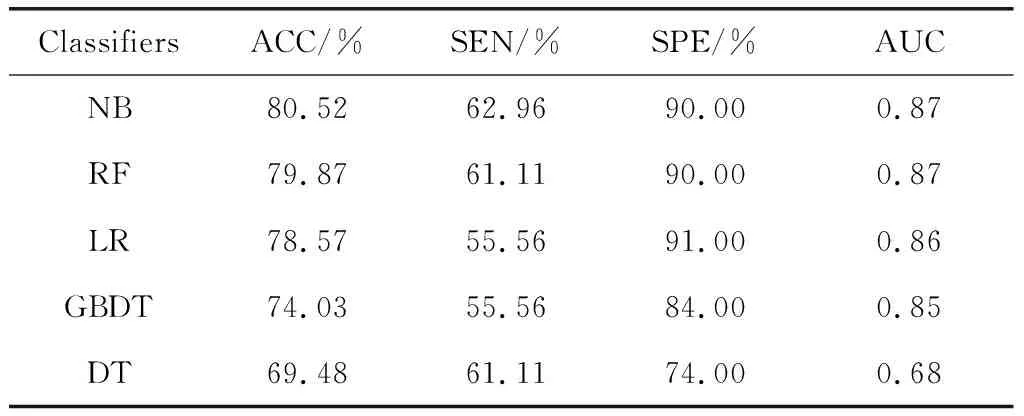
表3 在原始数据集上分类性能比较
先忽略准确率,从表3可以看出每个分类器的灵敏度较低,即医学上的漏诊率较高,显然不符合临床诊断试验的要求。
数据经过条件均值补全法填补,又经过SMOTE处理后,得到了完整的类别平衡的训练数据,如表4所示。

表4 在平衡数据集上训练分类器的性能比较
表4给出了在平衡数据中训练模型得到的测试分类性能。从表4可看出,各分类器的SEN均有提高,特别是GBDT和RF算法,但各分类器的SPE有所下降。这是合理的,因为SEN和SPE本质上是矛盾的。五种分类算法的ROC曲线,如图4所示。
显然GBDT相比其他具有更强的鉴别能力,而RF的分类性能略低,但在运行时间上如前面所述,RF要比GBDT更好。因此,可以根据自己的情况选择分类器。
所提模型与现有模型的对比,如表5所示。本研究所提模型的准确率落后于Maniruzzaman et[5],然而,他们是在类别不平衡的数据中进行的实验,ACC会倾向多数类,不可信。因此,在不同分布的训练数据中进行实验,ACC不具可比性。除去ACC,可以看到本研究所提模型的SEN和SPE都高于其他模型。从临床实践的角度来看,本研究模型优于其他模型。
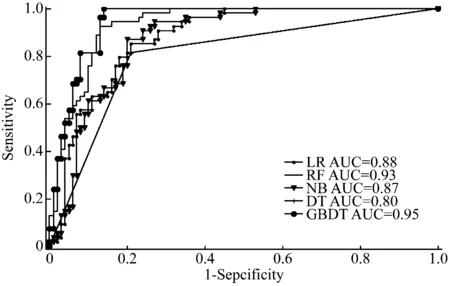
图4 不同分类器的ROC曲线比

表5 与现有模型进行比较
6 总结
针对慢性疾病的预测与早期识别,本研究综合解决了在已有预测模型中存在的问题,利用条件均值法对缺失数据进行填补。类别不平衡导致分类结果不可信、不可靠,本研究利用SMOTE算法对数据进行平衡处理。此外,与以往的评价指标不同,本研究采用临床诊断试验中更常用的SEN、SPE和ROC来评价预测结果。GBDT与其他常规分类器相比,其预测ACC为90.26%,SEN为100%,SPE为85%,AUC为0.95,表现出良好的性能。此外,同样的方法可以推广到预测其他类型的疾病。预测结果可以提醒医生和病人及早控制和治疗。
