基于动态专利有向网络的核心技术集群演化分析*
2021-04-29刘玉林菅利荣
刘玉林 菅利荣
(1.南京航空航天大学经济与管理学院 南京 211106;2.安徽商贸职业技术学院电子商务学院 芜湖 241002)
0 引 言
近年来,企业经营管理者为了获得市场竞争的至高点,围绕技术资源展开了激烈的竞争,并且这种竞争已经从单一的技术竞争转向技术集群的竞争。因为对属性相同的技术集聚而成的技术集群进行研究,能够识别新技术,发现技术发展规律,提前感知市场技术的变化,使企业在技术研发和技术竞争中获得优势。
当然,当前技术集群的研究已经取得了一些成绩,例如Sherwats等提出技术集群具有在一定空间和时间聚集的特性[1],Bressio从宏观因素和微观因素结合角度提出技术集群是经济动态发展的源泉[2],刘慧研究了产业集群与技术集群相互作用的条件和机制,提出了产业集群与技术集群四种相互作用方式[3],Jiang He等调查了美国15个大都市的高性能集群行业,通过考察这些高科技集群的构成试图发现技术集群的类型和发展趋势等[4]。
与此同时,在技术集群研究中,通过专利分析来进行技术集群的研究受到越来越广泛的关注。原因在于:专利是集技术情报、经济情报、商业情报于一体的知识载体,具有及时、可靠、内容详尽等显著的特点[5-6],专利文献作为科技创新成果的重要载体和表现形式,内容新颖,蕴含了更前沿的科技信息,是企业经营、科学研究和技术发展的重要技术竞争情报源之一[7-8]。文献[7,9-11]研究显示95%的发明创造被记录在专利文献中,80%的发明创造仅在专利文献中记载,专利文献、专利信息和专利数据作为反映科技发展,特别是技术发展轨迹的重要情报源,其价值日益突显,成为技术创新活动中最宝贵的知识源泉和战略资源。
通过专利开展技术集群研究引起了广泛的兴趣,部分学者在技术集群含义、分类等方面进行了积极的探索,例如张月通过系统聚类算法实现专利文献的聚类并提出了技术集群分类的方法,描述技术集群生命周期发展曲线,分析技术集群所处的发展阶段[2]。但将专利分析、文本挖掘与复杂网络结合构建动态专利有向网络,进而开展技术集群演化分析的研究非常缺乏。
因此,本文以专利分析视角,基于文本挖掘和复杂网络技术构建动态专利有向网络,在巨片提取和网络拓扑特性分析的基础上,开展核心技术集群演化分析,包括对核心技术集群的主题和演化历程分析等。
1 研究方法
图1给出了基于动态专利有向网络的核心技术集群演化分析流程,包括:从数据库中检索到目标专利;对目标专利进行文本挖掘,进而计算专利文本相似度;构建动态专利有向网络,提取网络巨片和分析网络拓扑指标;最后,开展技术演化分析。其中采用的核心方法有基于TF-IDF的属性-功能词组提取、动态专利有向网络构建、网络巨片的提取等。
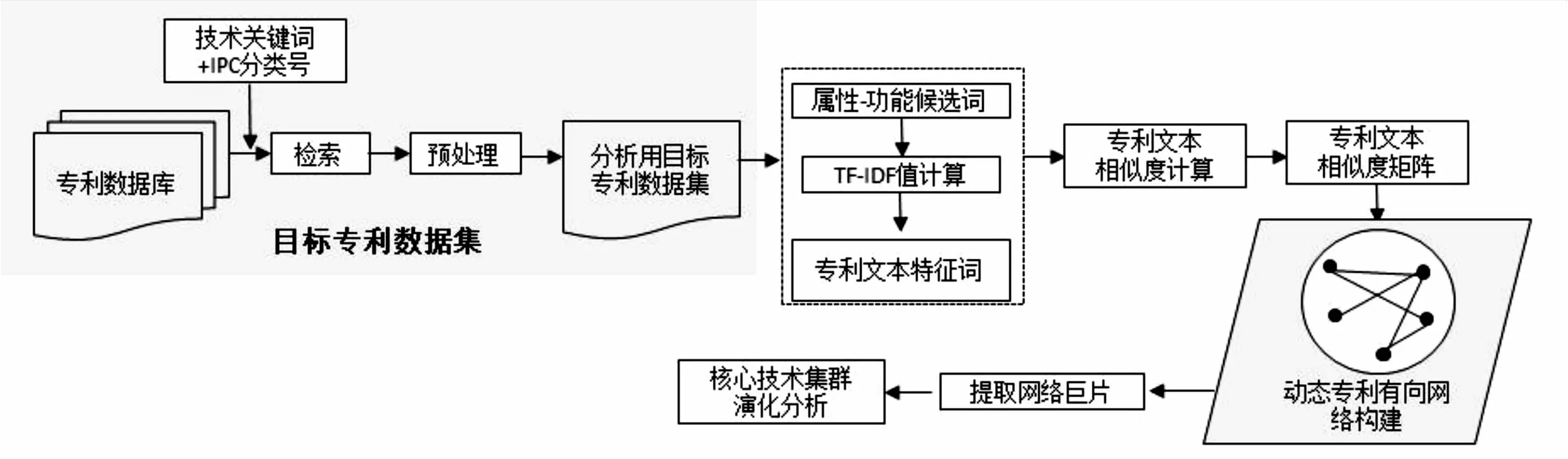
图1 基于动态专利有向网络的核心技术集群演化分析流程
1.1基于TF-IDF的属性-功能词组提取Noh等认为专利分析结果将取决于所选择的专利文本特征,如果它不能很好地代表整个文档的特征,后续分析的可靠性和准确性可能会受到影响[12]。专利文献通常包含通用词和术语两类词语,通用词常具有主题无关性,而术语则表达某个专业知识,具有较高的类别相关性[13]。Yoon等认为属性和功能作为专利文本中重要的术语表达内容,可以通过对专利文本的语法分析来提取,同时进一步发现属性和功能描述了专利的唯一性[14]。Dewulf在调查美国专利商标局(USPTO)约16 000项专利后总结发现:属性与形容词有关,而功能主要与动词有关,属性表示系统的特定特性,而功能表示系统的适当操作[15]。Yoon等进一步研究认为应该采用二元关系的形式来表示属性和功能,即属性用形容词+名词形式表示,功能用动词+名词形式[14]。基于此,本文采用属性和功能的二元关系词组(即形容词+名词、动词+名词)作为专利文本的特征。
专利文本中特征词并非同等重要,专利文本相似度测量应该考虑不同特征词的贡献。在计算特征词的权重时,胡学钢建议采用TF-IDF方法计算[16],俞琰等发现TF-IDF权值法是专利文本中计算特征权重应用最广的方法[13]。TF-IDF值的计算公式如式(1)所示。
Value (TF-IDF) = TF * IDF=
(1)
其中nij为在专利文本中某属性-功能词组出现的频率,∑nij表示在专利文本中某属性-功能词组出现的总频率,D为专利文档总数,{d∈D:ti∈dj}表示含有该属性-功能词组的文档数,1+{d∈D:ti∈dj}使分母不为0。
1.2动态专利有向网络在专利网络中,专利是节点,当两个专利文本相似度超过一定阈值时即可建立连接关系。如图2所示,t0、t1、t2为先后顺序的时间点,在专利网络中考虑时间维度,t0时刻节点i与t1时刻节点j建立的连接是从早期时间点指向后期时间点的有向连接,此时该专利网络为动态专利有向网络。需要注意的是,在本文中,将时间分辨率定义为天,不在同一天申请的专利节点均可以建立有向连接,在同一天申请的专利节点不建立有向连接。

图2 动态专利有向网络示意图
1.3网络巨片网络巨片是网络中最大的连通片。事实上,网络的连通性是一个非常脆弱的性质,很多网络中的节点并不是彼此连通,通常情况下网络会有一个最大的连通片,即网络巨片,该巨片具有一定数目的节点和连接,并表现出一定的特性。在本文研究中,选取属性-功能词组作为专利文本特征,属性-功能词组作为专利中的术语,实质上是技术因子的有力代表。属性-功能词组衡量专利文本相似性本质上代表技术因子相似性。因此,电商数据处理技术动态专利有向网络中的连通片可定义为技术集群。同时,巨片是网络中最大的连通片,故巨片是核心技术集群的有力代表,通过巨片挖掘能够深入分析核心技术集群的主题及其演化特征。
网络巨片的检索采用广义优先搜索模型,并通过Python编程实现,包括:
step1:首先从网络中随机选择节点1,并建立列表A,将节点1归属于列表A;
step2:在剩下的网络节点中随机选择节点2,并判断节点2与当前列表A中的所有节点是否有连接关系,存在连接关系时将节点2归属于列表A,反之新建列表B,将节点2归属于列表B;
step3:按照step2在剩下的网络节点中随机选择节点i,判断节点i与现有列表j中所有节点是否存在连接关系,存在连接关系时节点i归属于列表j,否则继续新建列表m,将节点i归属于列表m。如果节点i同属2个及其以上的列表,则将这些列表中节点归并为一个列表;
step4:重复step3,直到网络中的节点都归属于不同的列表;
step5:计算所有列表中的节点数量,排序后显示出节点数规模最大的列表,该列表中节点及其连接关系所形成的子网络即为该网络的巨片;
step6:通过step1-5搜索不同时间段的网络巨片。
2 实证分析
本文选择美国电商数据处理技术作为实证案例,原因在于:a.电子商务已经成为我国战略性新兴产业的重要组成部分,电商数据处理技术已经被利益相关者视为一项重要的新兴技术,对电商数据处理技术的创新与发展已经成为国家竞争力、行业发展和民生所需的关键战略。《电子商务“十三五”发展规划》进一步说明:“面向电子商务创新发展重点方向,要加强电子商务基础理论研究,加强大数据等方面的技术应用与创新等”。b.在对电商数据处理技术的研究和创新中,中美两国均有独特的优势。美国率先提出电商概念并实践,随后亚马逊、PayPal等一批有代表性的公司或经营方式涌现出来。当然,中国也是后起之秀,包括阿里巴巴、京东、支付宝等代表性的公司或经营方式也“从无到有,从弱到强”,在世界范围内形成了影响力。因此,对美国电商数据处理技术方面的创新和知识管理分析,对中国电商数据处理技术的研发与投资决策有很好的参考意义。
2.1数据源以德温特专利数据库(Derwent Innovation)作为目标专利采集数据库,采用Niemann等提出的“关键词+IPC分类号”的检索方式[18],检索式为{TIE=(ELECTRONIC ADJ COMMERCE) OR TIE=(E- ADJ COMMERCE) OR ABE=(ELECTRONIC ADJ COMMERCE) OR ABE=(E- ADJ COMMERCE) },IPC大类选项设置为G06(计算、推算、计数类),在检索结果中筛选申请国为美国(US),时间跨度为1994年4月至2019年12月,采集时间为2020年3月21日。针对采集结果,进行数据清洗,包括数据去重、缺失值处理和人工校对等,最终得到分析用美国电商数据处理专利2 840条。当然,需要声明的是:美国电商数据处理专利是指在美国境内申请并经美国政府部门授权的电商数据处理专业领域专利。
2.2动态专利有向网络的构建通过Python对专利摘要文本进行基于TF-IDF的属性-功能词组提取,选择摘要作为专利文本的原因在于:专利文本通常由标题、摘要、权利要求和描述等部分构成,原则上专利文本部分都可以提取专利的关键特征,然而文献[10,22-23]研究表明摘要应该作为专利文本中最重要的部分,摘要字段涵盖专利的新颖性、详细说明、优点等,比较准确的描述专利信息,从摘要中提取关键信息对分析是有价值的。
在基于TF-IDF的属性-功能词组提取时,调用了斯坦福大学(Stanford)的英文依存句法分析(Stanford Dependency Parser)程序包,对摘要的名词(nn)、形容词(j)和动词(v)等依存关系进行进一步分析[17]。属性-功能词组提取结果也经过2位电商技术专家的人工复核,最终形成能够代表专利文本特征的属性-功能词组,具体见表1所示。
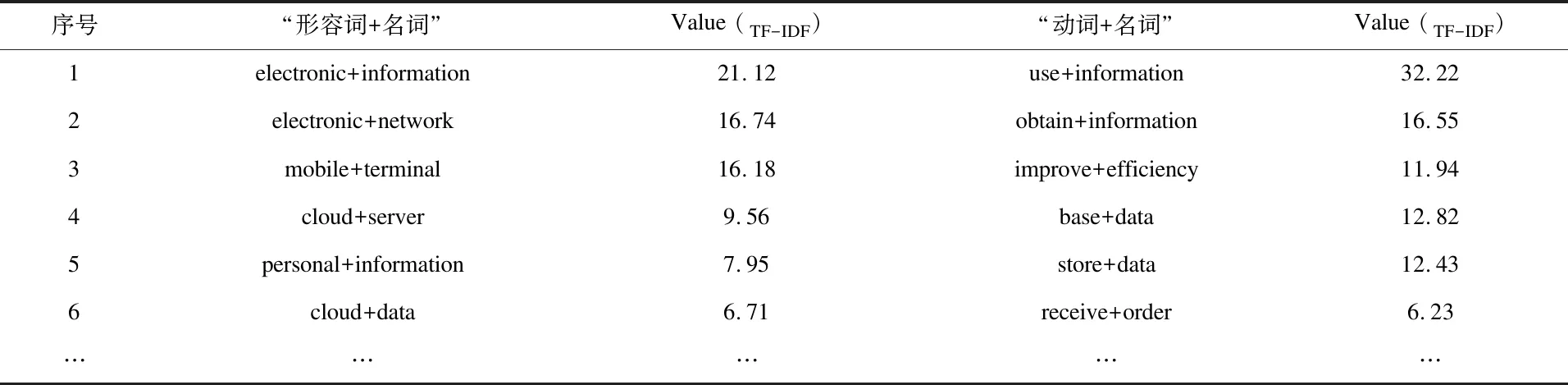
表1 经过自然语言和技术专家处理的部分属性-功能词组
在属性-功能词组提取基础上,在Python中基于余弦相似度计算专利文本相似度,形成专利文本相似度矩阵,见表2。将专利文本相似度阈值设定为0.6,将阈值化的专利文本相似度矩阵导入Gephi中,启用时间线,并在Photoshop软件中添加年份,从而获得动态专利有向网络,见图3。需要说明的是,相似度阈值0.6的设定是在尝试不同阈值后,根据网络呈现的拓扑性质和研究需要确定。

表2 专利文本两两相似度值

图3 时间维度下中美电商数据处理技术专利网络
在图3中,所有的专利节点按照年份进行了网格化,在Gephi中启用时间线后,可以展示和统计不同时间点的动态专利有向网络指标数值。
2.3核心技术集群演化分析
2.3.1 网络巨片提取与拓扑特性分析 通过网络巨片的Python提取程序,对美国电商数据处理技术动态专利有向网络进行巨片提取,并对巨片节点数、边数和网络密度统计,结果如表3所示。
表3显示,1994-1995年并无网络巨片产生,尚未发生技术联系和融合。1996年出现了第一对节点连接,这一节点连接并不能称之为连通片,但这一连接是网络巨片的雏形,因此本文也将其视为巨片。1997年及其之后,巨片边数有升有降,说明有代表多个不同技术集群主题的巨片在更替,这种更替现象说明电商数据处理技术的研究热点在变化。在表2中,巨片的网络密度有高有低,对此合理的解释在于:技术包括核心技术因子和辅助技术因子[19]。张奔[20]和王永杰等[19]的研究表明,一般技术都是从核心技术因子的发展开始,呈现顺轨式技术发展形式,巨片中专利节点的文本相似度高,容易形成连接,此时巨片表现为高网络密度。当技术发展到一定阶段,辅助技术因子成为该技术“木桶”当中“最短的那块木板”[19],技术需求形成的新创新源推动辅助技术发展,呈现出衍生式、渗透式或复合脱轨式技术发展形式,辅助技术专利节点文本相似度较低,巨片呈现出低网络密度。
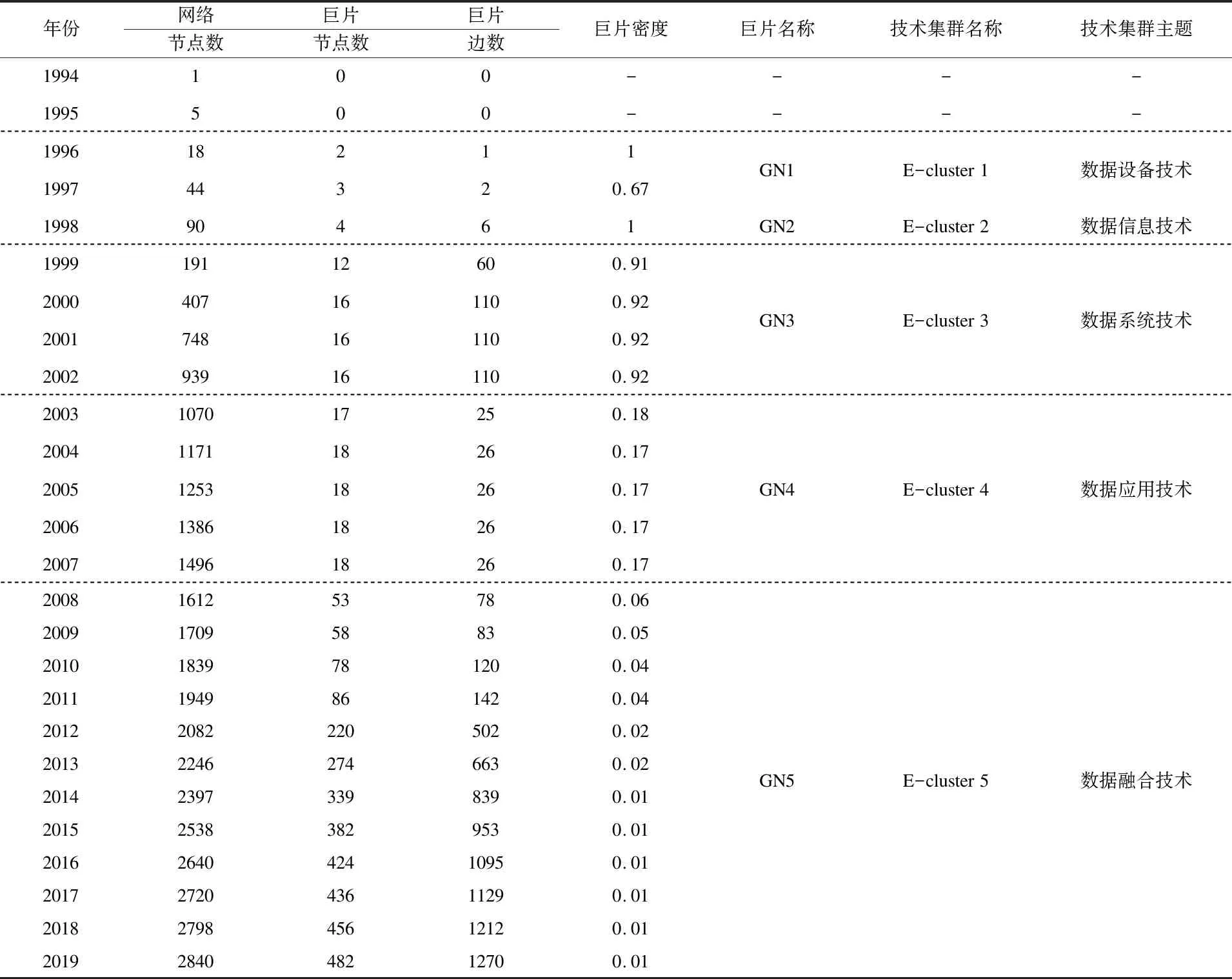
表3 美国电商数据处理技术动态专利有向网络巨片拓扑性质数据
2.3.2 巨片与核心技术集群主题分析 巨片是核心技术集群的有力代表,每一个巨片可视为一个技术集群,因此将巨片GN1-GN5所代表的核心技术集群命名为E-cluster 1-5,如表3所示。核心技术集群E-cluster 1-5的技术主题可以通过体现技术因子的属性-功能词组分析,具体分析如下:
a.E-cluster 1-数据设备技术。如图4所示,巨片GN1由三个节点US1、US17和US29组成,均以“electronic+module”和“Process +Device”为关键属性,但节点US1与US17更突出关键属性“store +device”,即存贮设备技术因子,节点US1和US29更突出关键功能“use+device”,即设备使用技术因子。因此将技术集群E-cluster 1的主题定义为数据设备技术。

图4 巨片GN1-5网络最终形态
b.E-cluster 2-数据信息技术。巨片GN2由四个节点US11、US21、US22、和US90两两连接形成,网络密度为1,因此E-cluster 2是一个体现核心技术高度相似的技术集群。同时节点均有共同关键属性“electronic+information,以及关键功能 “use+information”“form +information”“store+information”“sent+information”,说明技术集群E-cluster 2的核心技术因子为数据信息的形成、获取与使用。因此将技术集群E-cluster 2的技术主题定义为数据信息技术。
c.E-cluster 3-数据系统技术。巨片GN3初期网络密度为0.91,在不断吸收节点后,网络密度不减反增,说明技术集群E-cluster 3一直都在核心技术因子上进行创新。此时节点主要体现 “electronic+system”和“interactive+system”、relating+system”关键属性,以及“sent”与“system、network 、payment”等关联后的关键功能,说明技术集群E-cluster 3在于探索电子销售交互系统数据发送、数据网络与支付等研发主题,因此将技术集群E-cluster 3的技术主题定义为数据系统技术。
d.E-cluster 4-数据应用技术。巨片GN4的网络密度数值一直低于0.2,根据学者He等研究表明,巨片GN4形成的技术集群E-cluster 4已经开始辅助技术的开发,尤其辅助技术因子多,造成文本相似度低,很多专利节点未能建立连接关系,从而使巨片的网络密度处于较低水平。其中节点的关键属性包括“financial+system ”“financial+transaction”等,同时涵盖“use+site”“use+online”“form+card”等关键功能,体现技术集群E-cluster 4强调在金融系统和金融交易中电商数据的处理与使用,因此将技术集群E-cluster 4的技术主题定义为数据应用技术。
e.E-cluster 5-数据融合技术。巨片GN5的网络密度比巨片GN4数值更低,但其含有的节点规模为482,远大于巨片GN1-GN4,较低的网络密度和较高的节点规模使技术集群E-cluster 5在辅助技术方面开发的更深入。为了挖掘技术集群E-cluster 5的主题,对巨片GN5采用K-壳分解,当kmax值到达11时,巨片GN5网络仅有2个社团,见图4。令人惊奇的是社团1和2均由12个节点和33条有向边组成,网络密度均为0.5。社团1节点的关键属性为“electronic+product”“electronic+system”,关键功能为“associate+product”“store+data”和“associate+data”等,社团2节点的关键属性为“e-commerce+ data”“e-commerce+system”,关键功能为“use+system”“receive+data”。综上,社团1体现出数据与产品交互的融合特点,社团2反映出系统与数据融合的特点,因此,将技术集群E-cluster 5的技术主题定义为数据融合技术(见图5)。

图5 巨片GN5 Kmax图(Kmax=11)
2.3.3 核心技术集群演化分析 通过上述分析,美国电商数据处理技术核心技术集群的演化呈现下列特点:
a.美国电商数据处理技术演化进程。美国电商数据处理技术发展历经5个重要时期,包括1996-1997年数据设备技术研发时期、1998年数据信息技术研发时期、1999-2002年数据系统技术研发时期、2003-2007年数据应用技术研发时期和2008-2019年数据融合技术研发时期。5个发展时期反映出数据技术发展的一般规律,即以数据设备研发为先,以数据信息和系统技术为突破口,以数据应用为目标,以数据融合为趋势。
b.美国电商数据处理技术演化生命周期。技术集群的发展往往表现出“产生-发展-成熟-衰退”的生命周期轨迹,在网络巨片上表现为“连通片生成、连通片壮大、巨片出现、新的巨片出现”历程。当然,原有的巨片在成熟时,某一巨片的雏形连通片已经在产生和发展中。图6为巨片GN1-5的生命周期时间进程,在图6中,深色实心进度条是巨片的出现和持续年份,白色空心进度条是对应巨片雏形连通片出现和持续时间。

图6 网络巨片时间进度
在图6中,从时间进度衔接看,深色实心进度条在时间进程中衔接有序,代表了网络中的巨片呈现更替演化模式,巨片之间并未出现重叠交错情况,当然也未出现“起死回生”的再现现象。因此,美国电商数据处理技术集群之间很好的实现技术更新替换机制。从时间持续时间看,5个巨片表现出“冰火两重天”的持续时间现象,既有“昙花一现”的巨片GN2,也有“经久不衰”的巨片GN5,说明美国电商数据处理技术集群发展存在多样性,其中技术集群E-cluster2的突然出现,犹如“断崖式”的技术革新,将技术发展E-cluster1和E-cluster3隔开,表现出技术变革的短期性和偶然性,技术集群E-cluster5持续了12年,又表现出技术变革的长期性和必然性。
在图6中,巨片GN2和GN4均有白色空心进度条,其代表的技术集群E-cluster2和E-cluster4生命周期为典型的“产生-发展-成熟-衰退” 历程。巨片GN1和巨片GN3只有深色进度条,其代表的技术集群生命周期只有部分生命周期历程,尤其是E-cluster3仅仅存在一个年度,表现为“产生即衰退”的非典型生命周期历程。对于巨片GN5而言,无论是白色空心进度条,还是深色实心进度条,都有较大的时间跨度,其中白色空心进度条跨度9年,深色实心进度条跨度12年,技术集群E-cluster5从“产生-发展-成熟”已历时21年,且目前没有衰退的迹象。
在图6中,巨片GN2、GN4和GN5因为白色空心进度的存在,与其他巨片GN1、GN3等形成时间交叉。其中1997年时巨片GN2白色空心进度条与GN1深色实心进度条交叉重叠,代表了1997年是数据设备技术衰退和数据信息技术新生的转变期。2000年时巨片GN5白色空心进度条和GN2深色实心进度条首次发生交叉重叠,此时正值巨片GN3中间时期,代表了技术集群E-cluster5数据融合技术在技术集群E-cluster3数据系统技术时期已经开始孕育,并历经技术集群E-cluster4数据应用技术时期,才逐步形成和完善。2001-2002年是巨片GN4雏形连通片的出现期、巨片GN5雏形连通片的中期和巨片GN3的结束期,说明技术集群E-cluster3、4和5有很好并发辅助效果,而2001-2002年也是美国电商数据处理技术发展时间点上的特殊时期,在该时期中数据系统技术成熟鼎盛中孕育了数据应用技术的产生,并再次促进了数据融合技术的发展。
c.美国电商数据处理技术演化类型。形成技术集群的巨片网络密度的变化如图7所示,网络密度呈现三个层次:属于[0.8,1]的高网络密度区,属于[0.4,0.8)的中网络密度区,属于[0,0.4)的低网络密度区。值得注意的是,阈值0.4和0.8的设定应进行实验测定,但在本文中,高中低三个网络密度区有很明显的区域划分,因此使用0.4和0.8作为阈值划分网络密度区不影响巨片和技术集群性质的分析。在高网络密度区,巨片网络基本上为全局耦合网络,其中节点两两连接,体现为技术集群中技术研发紧密相连,即任何两个专利之间都存在技术因子关联,此时技术研发可视为核心技术的关联研发,由此可见,技术集群2和技术集群3表现为数据信息和数据系统的核心技术研发。在中网络密度区,巨片网络呈现出“树”型结构,即网络中有主干节点,也有支叶节点,主干节点是核心技术的研发,其中度高的节点及其之间的连接表现为“树干”,度低的节点与度高节点的连接表现为“支叶”,而支叶节点可视为对核心技术有辅助功能的技术研发,即辅助技术研发。当然在中网络密度区巨片网络中主干节点居多数,核心技术的研发占主导地位。由此可见,技术集群E-cluster1前期表现为数据设备的核心技术研发,但很快就进入了数据设备辅助技术研发,E-cluster1是5个技术集群中唯一发生网络密度区转变的技术集群。在低网络密度区,巨片网络呈现出“雪花”型结构,“雪花”中度高的节点较少,度低的节点较多,可视为辅助技术的研发占据主流,由此可见,技术集群4始终表现为数据应用的辅助技术研发,技术集群5为数据融合的辅助技术研发。
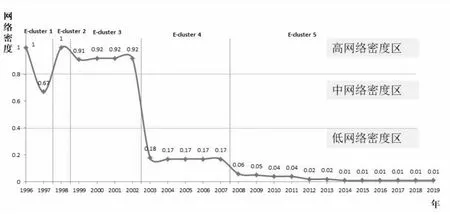
图7 巨片网络密度变化与技术集群示意
3 结论与讨论
本文通过构建动态专利有向网络,并基于Python程序提取巨片,通过对巨片拓扑性质统计,从而开展核心技术集群主题和演化历程分析等。
以美国电商数据处理技术为例,通过动态专利有向网络,开展核心技术集群分析发现:a.美国电商数据处理技术包括数据设备技术、数据信息技术、数据系统技术、数据应用技术和数据融合技术等五个核心技术集群;b.美国电商数据处理技术集群E-cluster1-5均为每个时期的新生技术,且技术集群之间体现出技术更新替换机制;c.技术集群2和技术集群3表现为对数据信息和数据系统的核心技术研发,技术集群4表现为数据应用的辅助技术研发,技术集群5为数据融合的辅助技术研发。E-cluster1是既有核心技术的研发,也有辅助技术的拓展。
当然,本文的研究还存在以下不足:a.技术集群的演化趋势预测未进行研究;b.对高中低网络密度区划分的阈值未开展深入的实验检验。但总体而言,本文通过文本挖掘和复杂网络技术,构建动态专利有向网络,是一种新的开展核心技术集群分析的有效方法。最后,希望本文的研究能引起更多的学者关注,加强对核心技术集群的识别和演化分析探究。
