云数据中心服务器能耗建模及量化计算
2021-04-25周舟袁余俊明李方敏
周舟,袁余俊明,李方敏†
(1.湖南大学信息科学与工程学院,湖南长沙 410082;2.长沙学院计算机工程与应用数学学院,湖南长沙 410022)
随着云计算数据中心的大量新建,数据中心的能耗问题越来越严重.近期研究显示[1-2]:全球数据中心的总数已超过300 万个,耗电量占全球耗电量的1.1%~1.5%.我国数据中心也发展迅速,总数已达到40 万个,年耗电量已超过500 亿千瓦,占全国总耗电量的1.5%.如果以数据中心的PUE(平均电能使用效率)指数来评测,全球先进数据中心的PUE 指数为1.2,而我国的PUE 指数大于2.2.与此同时,大量的报告也显示[3-5]:许多高性能数据中心服务器的利用率却远远低于50%,其原因在于数据中心资源未得到“有效”利用.因此,节能优化算法的提出有助于提高系统的资源利用率和单位能耗的效用.
能耗模型作为“节能优化算法”的基础[6-7],其准确性直接关系到优化算法的优劣.一个精确、通用、有效的能耗模型不仅为优化算法提供基础,而且也有利于该模型的扩充.对于云资源提供者来说,构建精确的能耗模型有助于资源提供者预测和优化数据中心的能耗,提高单位能耗的效用.因此,对其研究具有十分重要的现实意义.
本文的主要工作如下:
1)基于“任务的特征”构建能耗模型.不同于其它的能耗模型仅考虑CPU 密集型任务,在本文中,基于“任务特征”的不同,任务被划分为三类,分别为计算密集型任务、Web 事务型任务和I/O 密集型任务.
2)不同于已存在的能耗模型仅考虑CPU 和内存部件,而忽略了磁盘和网络接口卡部件,本文所提出的能耗模型考虑了与能耗有关的所有部件如CPU、内存、磁盘和网络接口卡.
3)使用“主成分分析法”分析各部件参数对能耗的贡献并选择最具代表性的参数.
4)运用大量的实验证明了本文所提出能耗模型的精确性和有效性.
1 相关研究
目前,对能耗模型的研究可以分为两类,一类是基于系统利用率的能耗模型[8-12],另一类是基于性能计数器的能耗模型[13-17].
基于系统利用率的能耗模型的主要思想是利用服务器各主要部件的利用率,构建能耗模型.文献[8]基于服务器中资源使用情况,结合回归方法建立了线性模型.文献[9]结合三个参数(%Processor Time,%Memory used,%Page Faults/s)提出了一种CMP(CPU利用率,内存利用率和Pagefaults)模型,相比较以往的能耗模型,该方法具有一定的优势,但该方法因选择的参数有限且没有考虑到负载的特征,其能耗模型的精度仍有待提高.在文献[12]中,罗亮等人针对数据中心的单台服务器提出了一种高精度的能耗模型,该模型分析了不同参数对服务器能耗的影响,然后结合多元线性回归和非线性回归的方法建立能耗模型.同样,文献[11]在线性模型(Linear Model)的基础上提出了一种改进的能耗模型叫Cubic Model,该模型认为服务器的能耗与处理器(CPU)不应是线性关系,而是立方关系.文献[12]基于能耗和系统资源利用率的关系,提出了一种服务器能耗经验模型(Linear Model).此类能耗模型的优点是易于实现且能耗模型的精度较高.
基于性能计数器的能耗模型的基本思想可概括为:根据PMC 与设备能耗之间的关系,针对不同设备(包括处理器、内存、磁盘、I/O 外部设备)筛选出最具代表性的“PMC 集合”;然后通过统计分析的方法,建立PMC 事件与设备功耗之间的函数关系,这种关系既可以是线性关系、也可以是非线性关系.在文献[13]中,程华等提出了一种基于细粒度的实时能耗模型,该模型由模型设定、性能计数器参数选取、数据采集、模型求解和性能评估这五个部分组成.在此文中,作者选择PMC 集合(包含二十多个参数)建立系统能耗模型.文献[14]通过运行负载,在考虑处理器和内存等因素下,基于PMC 方法建立服务器的能耗模型.在文献[15]中,作者在考虑CPU 和内存两大因素的条件下,提出了一种Ramon Model.在文献[16]中,Singh 等使用PMC 方法构建实时的能耗模型.在文献[17]中,肖鹏等首先形式化资源利用率与能耗之间的关系,然后基于性能计数器提出了一种新型的能耗模型,最后基于该能耗模型提出了一种虚拟机调度算法.此类方法因采集到的事件太多,成本相对较高,模型也较为复杂,故不利于该模型扩充.
2 能耗模型的参数选择
数据中心服务器的能耗建模如图1 所示.它包含数据采样、参数的筛选、建立模型和评估模型四个步骤.
1)数据采样.数据采样是数据中心能耗建模的第一步,这一步的主要工作是采集系统的数据,采样的基本方法有基于性能计数器或者基于系统资源利用率.

图1 能耗建模的基本步骤Fig.1 Basic steps for energy modeling
2)参数的筛选.在采样数据之后,就需要对采集到的参数进行筛选.因为采样的参数有些是与系统能耗相关的,有些是不相关的.如何筛选这些参数呢?此时可以借助于“主成分分析法”或者“相关系数矩阵法”去筛选.
3)建立模型.这一步的主要工作是利用前面筛选出的参数,借助于数学中的线性回归或者非线性回归方法(多项式回归,幂回归,指数回归,支持向量机回归)建立能耗模型.
4)评估模型.这一步的主要工作是对前面建立起来的能耗模型进行评估,比较所得到能耗预测值与真实值的差别,目的是确定该模型的准确性和有效性.
2.1 各部件能耗的代表参数
作为云计算数据中心的任何一台服务器,哪些参数应该被选择去构建能耗模型呢?如果参数选择过少,将导致构建出来的能耗模型精度不够,如果参数选择过多,将导致开销增加且不利于该模型的扩展.因此,选择合适的参数构建能耗模型极其重要.对于数据中心的任何一台服务器,其总功率主要由其处理器(CPU)、内存、磁盘和网络接口卡的功率决定.设Psystem是服务器的功率,参数PCPU、Pmemory、Pdisk和Pnetwork分别代表该服务器的处理器(CPU)、内存、磁盘和网络接口卡功率,则Psystem可以表示如下:
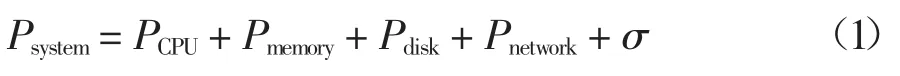
式中:参数σ 是除CPU、内存、磁盘和网络接口卡之外的其它部件功率,可看作常数.对于处理器的功率PCPU,可用式(2)表达[18]:

式中:参数Pmax代表该部件最大的功率,Pidle代表该部件空闲时的功率,U 代表该部件的CPU 利用率.由于PCPU的值与参数U 相关,所以在监控CPU 的能耗时,参数“Processor Time”被选作处理器的代表性参数.参数“Processor Time”指的是系统中所有处理器都处于繁忙状态的时间百分比,即CPU 的利用率.对于Pmemory的值,可以用式(3)表达[18]:
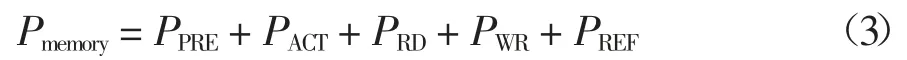
式中:PPRE、PACT、PRD、PWR和PREF分别代表预充电(PPRE)、活动状态(PACT)、读状态(PRD)、写状态(PWR)和刷新状态(PREF)的功率.由于Pmemory的值与读和写状态有关,因此,在监控Pmemory的能耗时,“Memory Used”和“Page Fault/Sec”被选作内存的代表性参数.“Memory Used”指的是内存的利用率,“Page Fault/Sec”指的是处理器处理错误页的综合速率,单位是错误页数/s.当处理器请求一个不在其工作集(在物理内存中的空间)内的代码或数据时出现的页错误.这个错误包括硬错误(那些需要磁盘访问的)和软错误(在物理内存的其它地方找到的错误页).对于Pdisk的值,可以用式(4)来表示[18]:
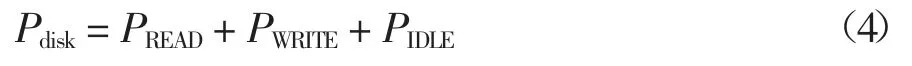
式中:参数PREAD、PWRITE和PIDLE分别代表磁盘读、写和空闲时的功率.在监控磁盘的能耗时,“Disk time”和“Disk Bytes/Sec”被选作磁盘的代表性参数.“Disk time”指的是磁盘驱动器忙于读或写入请求等服务所用的时间百分比,“Disk Bytes/Sec”指的是在进行写入或读取操作时从磁盘上传送或传出的字节速率.
对于Pnetwork的值,可以用式(5)计算[18]:

式中:参数C0和C1可认为是一个常数,参数S 指的是文件大小,单位是MB;参数B 指的是带宽,单位是MB/s.在监视网络接口卡的能耗时,“Bytes Total/Sec”和“Current Bandwidth”被选作网络接口卡的代表性参数.“Bytes Total/Sec”指的是在每个网络适配器上发送和接收字节的速率,包括帧字符在内.“Current Bandwidth”指的是目前带宽.
2.2 计算密集型任务的参数选择
计算密集型任务也叫CPU 密集型任务.全球标准性能评估公司SPEC 提供的CPU2006[19-20]数据集就是标准计算密集型任务,该数据集包含“401.bzip2”、“403.gcc”、“429.mcf”、“453.povray”和“450.soplex”等子项.以DELL PowerEdge R720 服务器为例(服务器配置见表1),当它运行“401.bzip2”任务时,其在不同负载下的能耗和相关参数值如表2 所示.

表1 DELL R720 服务器配置Tab.1 Dell R720 server configuration
从表2 得出:当“Processor Time”=4.23%,Memory Used=4.47%,Page Fault/Sec=512.78,Disk Time=0.66,Disk Bytes/Sec=4 102.28,Bytes Total/Sec=562.00 和Current Bandwidth=9.22 ×1018时,此时的能耗为122.49 W.对于这7 个参数(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec 和Current Bandwidth),它们是如何影响能耗的呢?哪些与能耗相关?哪些与能耗不相关呢?为解决这个问题,利用SPSS 中的“主成分分析法”[21]分析每个参数的贡献(即因子贡献),表3 列出了每个因子的贡献.
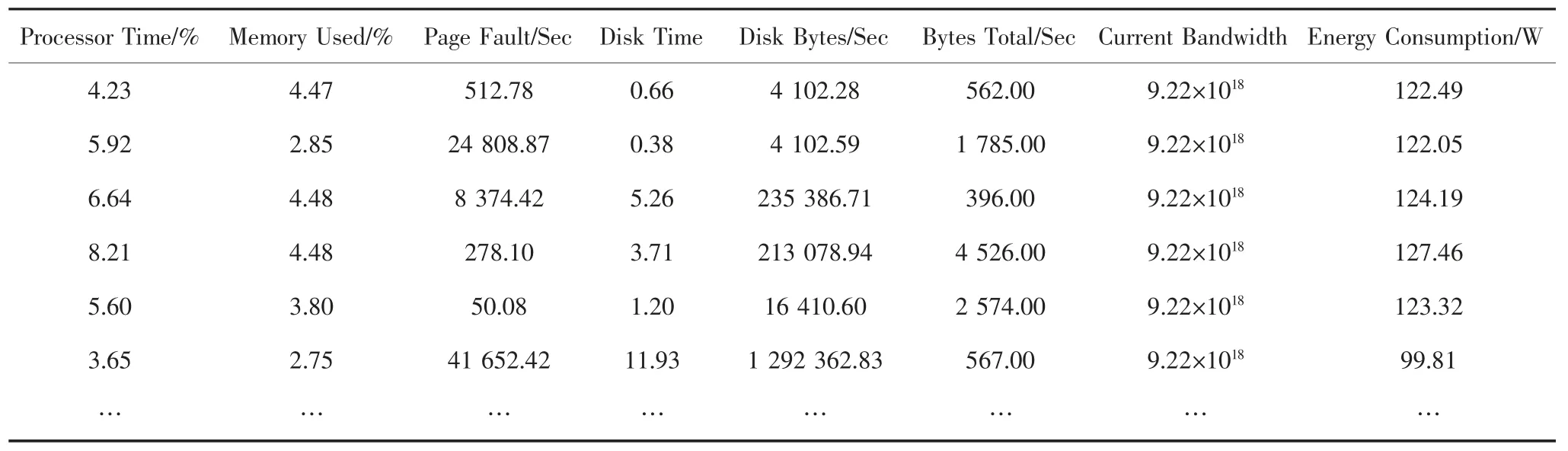
表2 不同负载下的参数值及能耗Tab.2 Parameter values and energy consumption under different loads

表3 计算密集型任务下因子贡献Tab.3 Factor contribution under computation-intensive tasks
表3 表明:参数“Processor Time”对能耗的贡献是62%,“Disk Bytes/Sec”是19%,“Disk Time”是14%,“Page Fault/Sec”是4%,“Memory Used”是1%,“Bytes Total/Sec”和“Current Bandwidth”都是0.这些数据说明,“Processor Time”对能耗的贡献最大,而“Bytes Total/Sec”和“Current Bandwidth”对能耗没有贡献.因此,在下一节能耗建模中,值不为零的5 个参数“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”被选中用于实验建模.
与此相似,在现实生活中,我们干掉高考这个BOSS以后,武功进入了一个瓶颈期,每个人的斗志也因此消磨许多。所以,我们不妨试着将这四年的大学时光,当作是一段特殊的“闭关修炼”,修身养性,格物致知,潜心修炼内功和外功。在不断提升自我的同时,抵御绑定了潜在风险的外来诱惑。
2.3 Web 事务型任务的参数选择
HP LoadRunner[22-23]是一种典型的Web 事务型任务,以DELL PowerEdge R720 服务器为例(服务器配置见表1),当它运行“HP LoadRunner”任务,在用户数是3 000 时,采用同样的办法可以得到每个参数对能耗的贡献即因子贡献,表4 展示了这7 个参数(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec 和 Current Bandwidth)对能耗的贡献.
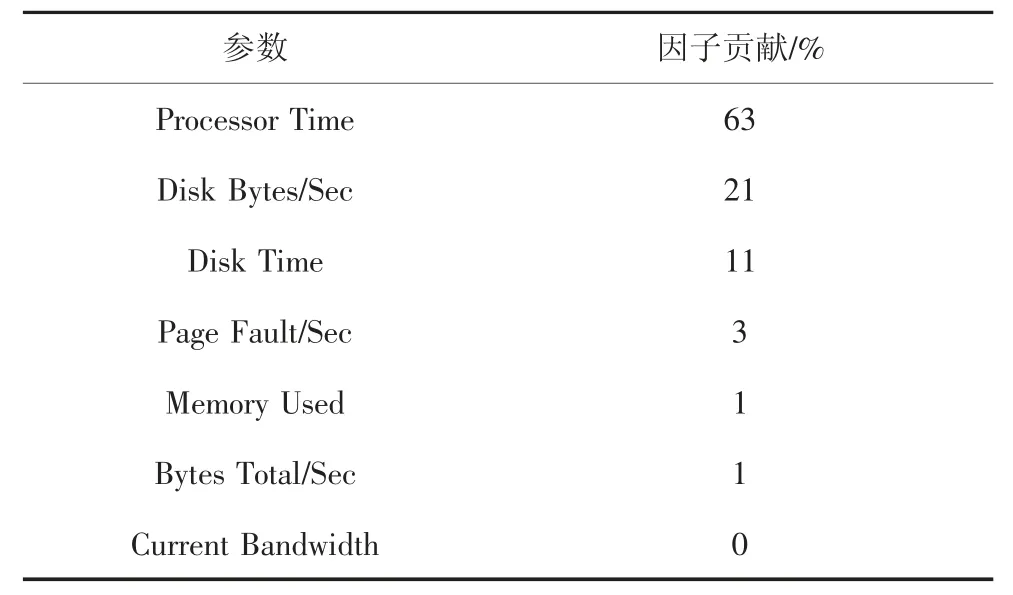
表4 Web 事务型任务下因子贡献Tab.4 Factor contribution under Web transactional tasks
从表4 可以看出,参数“Processor Time”对能耗的贡献是63%,“Disk Bytes/Sec”是21%,“Disk Time”是11%,“Page Fault/Sec”是3%,“Memory Used”是1%,“Bytes Total/Sec”是1%,“Current Bandwidth”是0.这些数据说明,“Processor Time”对能耗的贡献最大,而“Current Bandwidth”为0 即表示对能耗没有贡献.因此,在下一节能耗建模中,值不为零的6 个参数“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”,“Memory Used”和“Bytes Total/Sec”被选中用于实验建模.
2.4 I/O 密集型任务的参数选择
Iozone[24-25]是一种典型的I/O 密集型任务,以DELL PowerEdge R720 服务器为例(服务器配置见表1),当它运行Iozone 数据集时,采用同样的办法可得到每个参数对能耗的贡献即因子贡献,表5 展示了这7 个参数(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec和Current Bandwidth)对能耗的贡献.从表5 可以看出,参数“Processor Time”对能耗的贡献是53%,“Disk Bytes/Sec”是27%,“Disk Time”是15%,“Page Fault/Sec”是3%,“Memory Used”是1%,“Bytes Total/Sec”和“Current Bandwidth”都是0.这些数据说明,“Processor Time”对能耗的贡献最大,而“Bytes Total/Sec”和“Current Bandwidth”都为0 即表示对能耗没有贡献.因此,在下一节能耗建模中,值不为零的五个参数“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”都被选中用于实验建模.
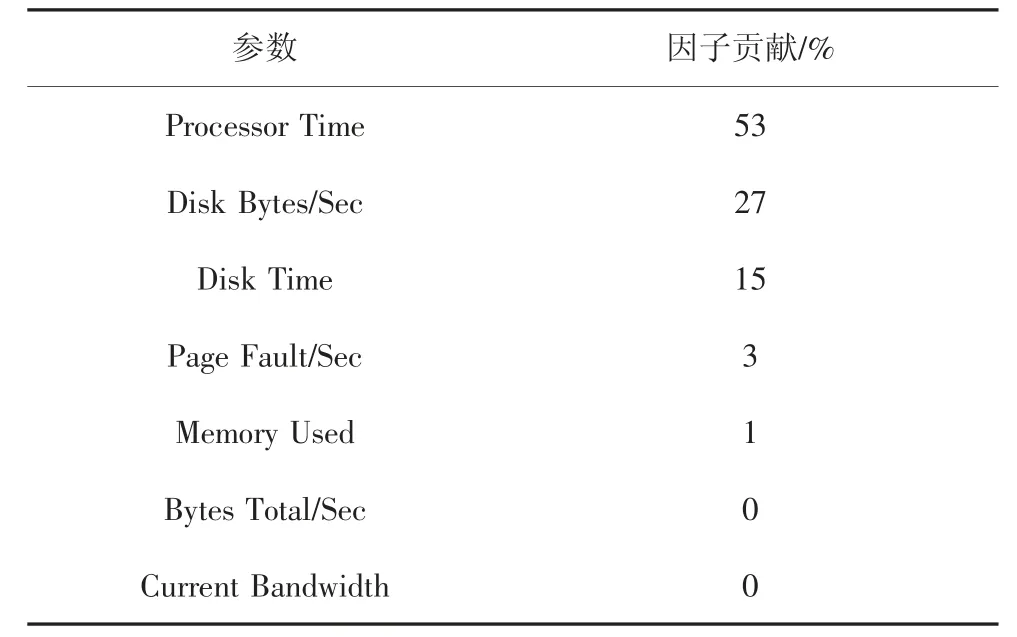
表5 I/O 密集型任务下因子贡献Tab.5 Factor contribution under I/O intensive tasks
3 能耗建模
对于不同的任务类型,第二节已确定有那些参数被选中用于能耗建模.在这一节中将使用EViews 8.0[26]软件,分别用多元线性回归法、幂回归法、指数回归法和多项式回归法建立能耗模型.对于多元线性回归法,其包含m 个因变量的回归模型如下:
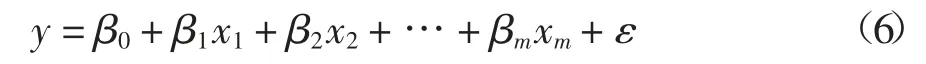
式中:变量y 是观测到的真实能耗;β0,β1,β2,…,βm是回归系数;ε 是随机误差.对于幂回归法,其包含m个因变量的回归模型如下:
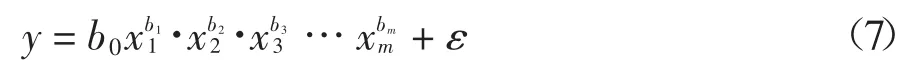
式中:变量y 是观测到的真实值;b0,b1,b2,…,bm是回归系数;ε 是随机误差.对于指数回归法,其包含m个变量的回归模型如下:
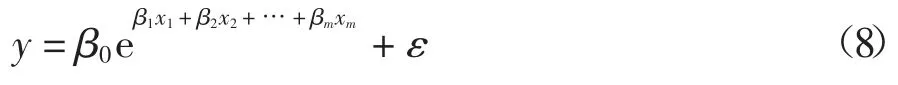
式中:变量y 是观测到的真实值;β0,β1,β2,…,βm是回归系数;ε 是随机误差.对于多项式回归,其包含m个变量的回归模型如下:
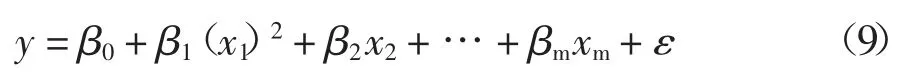
式中:变量y 是观测到的真实值;β0,β1,β2,…,βm是回归系数;ε 是随机误差.
为方便3.1~3.3 节中所述内容的说明,表6 列出了常用的参数及其代表的含义.

表6 参数及其含义Tab.6 Parameters and their meanings
3.1 计算密集型任务的能耗模型
对于计算密集型任务CPU2006[19-20]数据集,结合2.2 节的代表性参数和EViews 8.0[26]软件,分别用多元线性回归法、幂回归法、指数回归法和多项式回归法建立能耗模型,见公式(10)~(13):

式中:参数y,x1,x2,x3,x4,x5分别代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”.
3.2 Web 事务型任务的能耗模型
对于Web 事务型任务HP LoadRunner[22-23],在用户数3 000 情况下,结合2.3 节的代表性参数和EViews 8.0[26]软件,分别用多元线性回归法、幂回归法、指数回归法和多项式回归法建立能耗模型,见公式(14)~(17):

式中:参数y,x1,x2,x3,x4,x5,x6分别代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”,“Memory Used”和“Bytes Total/Sec”.
3.3 I/O 密集型任务的能耗模型
对于I/O 密集型任务Iozone[24-25],结合2.4 节的代表性参数和EViews 8.0[26]软件,分别用多元线性回归法、幂回归法、指数回归法和多项式回归法建立能耗模型,见公式(18)~(21):
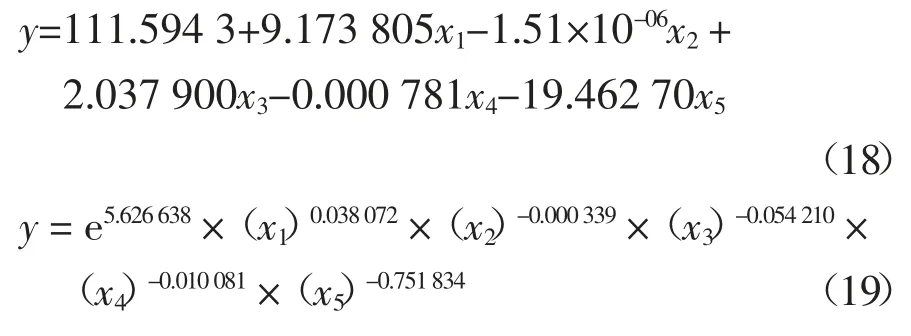

式中:参数y,x1,x2,x3,x4,x5分别代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”.
4 实验结果及分析
本文所用的服务器是DELL PowerEdge R720 服务器(见表1),CPU 频率是2.0 GHz(2×6 核),内存是DDR2 20 G,磁盘是2×1 TB,网络接口卡是Intel quad-port Gigabit network adapter.实验测量能耗的工具是北电仪表公司所生产的Power Bay-SSM.计算密集型任务使用的是“403.gcc”,“429.mcf”,“401.bzip2”,“453.povray”和“450.soplex”数据集[19-20].对于“Web 事务型任务”和“I/O 密集型任务”,则分别使用“Load-Runner”[22-23]和“Iozone”数据集[24-25],这两个数据集每次产生任务都是“随机生成”.
为评价本文所建模型的精度,采用式(22)计算每个模型的相对误差:
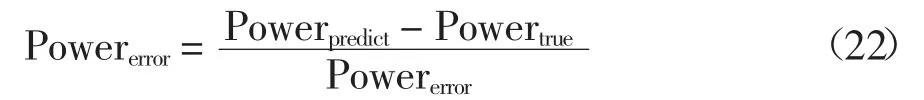
式中:Powerpredict表示能耗的预测值;Powertrue表示能耗的真实值;Powererror表示能耗的相对误差.
为评价能耗模型的好坏,选择Linear Model[12],Cubic Model[11]和Ramon Model[15]能耗模型作对比.
4.1 计算密集型任务的实验结果及分析
利用3.1 节所建立的能耗模型,运行计算密集型任务CPU2006[19-20]数据集,得到预测值和真实值的相对误差,如图2 和图3 所示.
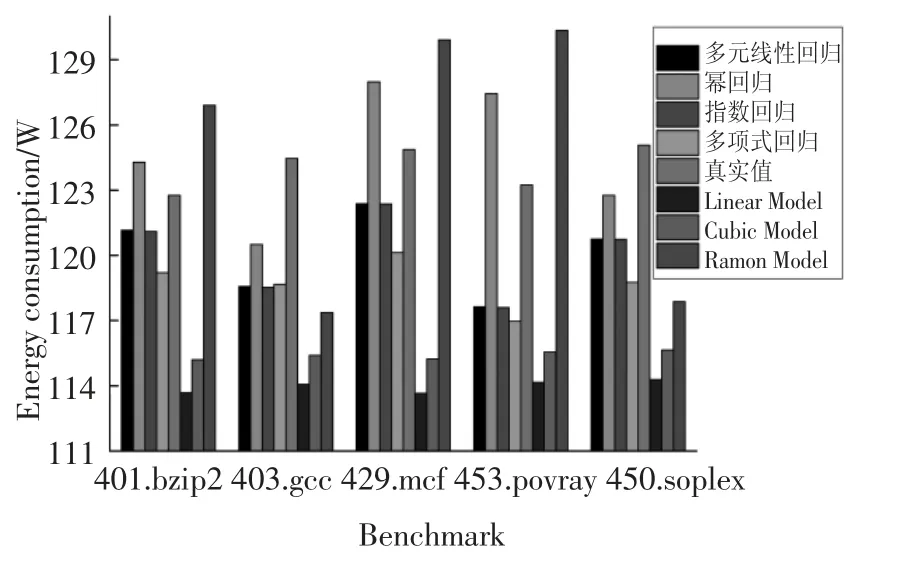
图2 计算密集型任务下各模型的能耗Fig.2 Energy consumption of each model under computation-intensive tasks
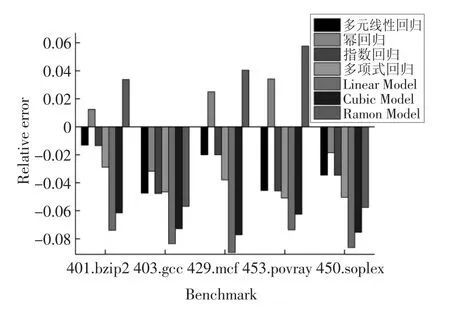
图3 计算密集型任务下各模型相对误差Fig.3 Relative error of each model under computation-intensive tasks
图2 和图3 分别展示了这7 种能耗模型(多元线性回归、幂回归、指数回归、多项式回归、Linear Model、Cubic Model 和Ramon Model)的能耗和相对误差.这4 种模型(多元线性回归、幂回归、指数回归和多项式回归)优于Ramon Model,原因在于两方面:第一,这4 种模型在建模时考虑了处理器(CPU)、内存、磁盘和网络接口卡因素,而Ramon Model 仅考虑处理器(CPU)和内存因素.第二,这4 种模型(多元线性回归、幂回归、指数回归和多项式回归)考虑了任务的特征并利用“主成分分析法”提高了能耗模型的精度.Ramon Model 优于Linear Model 和Cubic Model,原因在于其考虑了处理器(CPU)和内存两个因素,而Linear Model 和Cubic Model 仅考虑CPU 因素.
4.2 Web 事务型任务的实验结果及分析
利用3.2 节所建立的能耗模型,运行Web 事务型任务HP LoadRunner[22-23],在用户数3 000 情况下,得到预测值和真实值的相对误差,如图4 和图5 所示.
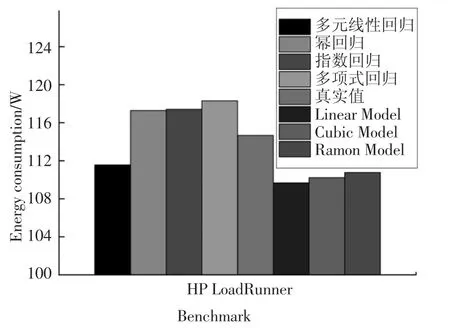
图4 Web 事务型任务下各模型的能耗Fig.4 Energy consumption of each model under Web transactional
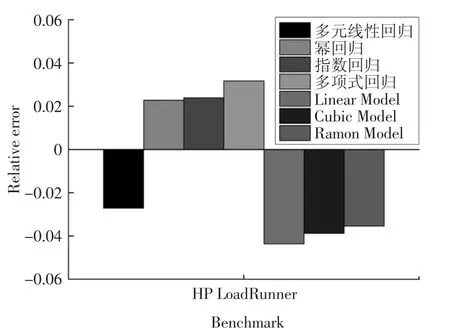
图5 Web 事务型任务下各模型相对误差Fig.5 Relative error of each model under Web transactional tasks
图4 和图5 分别展示了这7 种能耗模型(多元线性回归、幂回归、指数回归、多项式回归、Linear Model、Cubic Model 和Ramon Model)的能耗和相对误差.这4 种模型(多元线性回归、幂回归、指数回归和多项式回归)相比较Ramon Model,其能耗精度提高1%以上,其原因可归结为两方面:第一,Web 事务型任务的特点决定了该类任务对内存和网络的访问较为频繁,Ramon Model 只考虑了CPU 和内存因素,而这4 种能耗模型考虑了处理器、内存、磁盘和网络接口卡这4 个因素.第二,这4 种模型考虑了任务的特征并利用“主成分分析法”提高了能耗模型的精度.
4.3 I/O 密集型任务的实验结果及分析
利用3.3 节所建立的能耗模型,运行I/O 密集型任务Iozone[24-25]数据集,得到预测值和真实值的相对误差,如图6 和图7 所示.
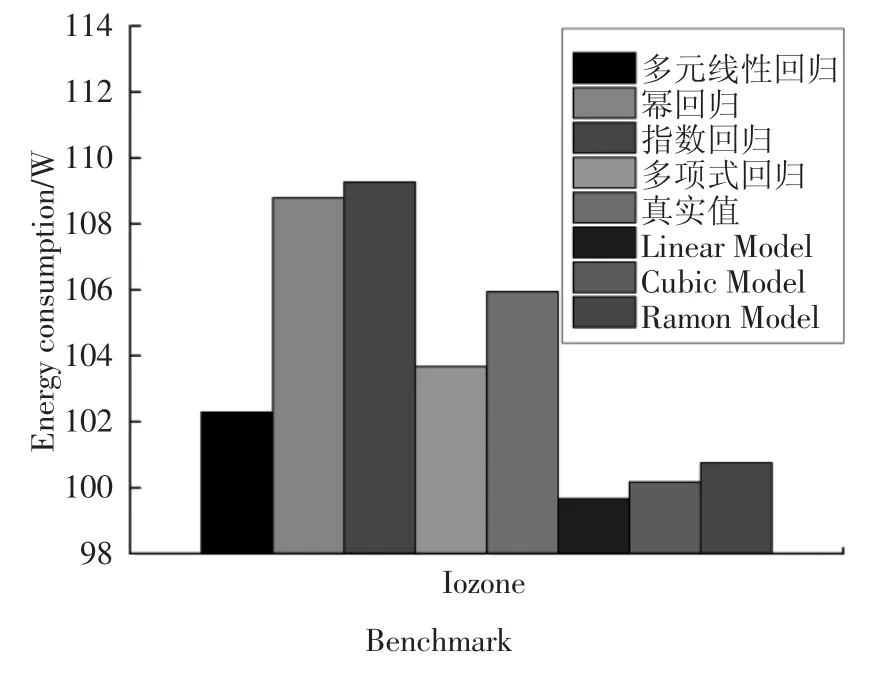
图6 I/O 密集型任务下各模型的能耗Fig.6 Energy consumption of each model under I/O intensive tasks
图6 和图7 分别展示了这7 种能耗模型(多元线性回归、幂回归、指数回归、多项式回归、Linear Model、Cubic Model 和Ramon Model)的能耗和相对误差.图7 表明,这4 种能耗模型(多元线性回归、幂回归、指数回归和多项式回归)相比较Linear Model,Cubic Model 和Ramon Model,其能耗精度提高3%左右,其原因可归纳为以下两个方面:第一,I/O 密集型任务的特点是对磁盘的访问较为频繁,因此在建模时应该考虑处理器、内存和磁盘多个因素.这4 种能耗模型考虑了处理器、内存、磁盘和网络接口卡这4个因素.第二,这4 种模型考虑了任务的特征并利用“主成分分析法”提高了能耗模型的精度.
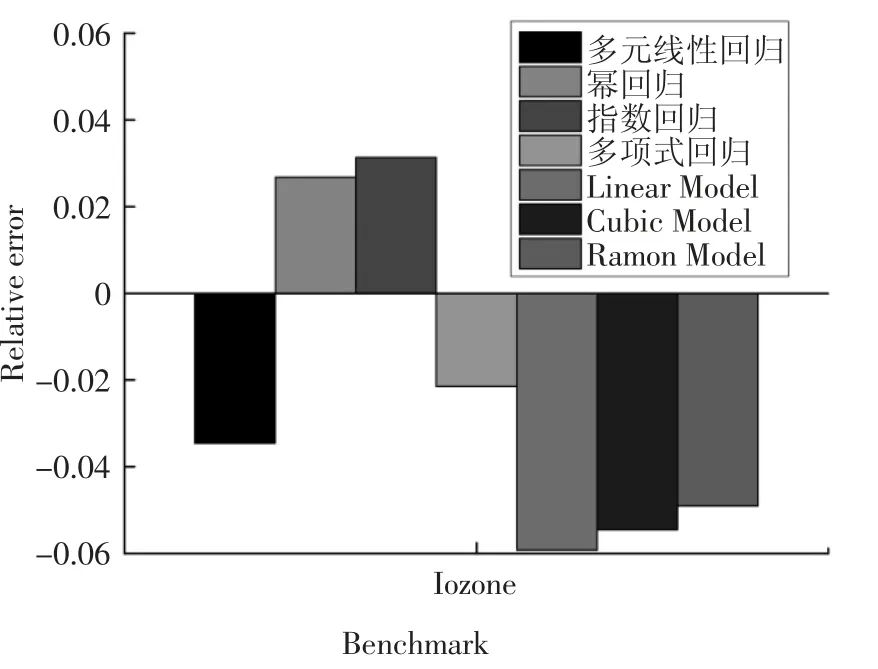
图7 I/O 密集型任务下各模型相对误差Fig.7 Relative error of each model under I/O intensive tasks
4.4 4 种模型的对比
根据4.1、4.2 和4.3 节中的实验结果和分析,不管何种任务类型(计算密集型任务、Web 事务型任务和I/O 密集型任务),幂回归模型精确度最高,多元线性回归模型一般,指数回归模型和多项式回归模型较差.因此,在以后的能耗建模中,推荐使用幂回归模型进行能耗建模.
5 总结
针对数据中心服务器能耗模型精度低的问题,本文根据“任务的特征”结合“主成分分析法”构建了新型的能耗模型.与其它的能耗模型对比,本文所构建的能耗模型在精度方面提高了3%,其原因可归结为:1)本文所构建的能耗模型考虑了“任务的特征”;2)在能耗模型的构建过程中,考虑了CPU、内存、磁盘和网络接口卡多个因素;3)利用“主成分分析法”筛选出了与能耗有关的部件.
本文所提出的模型有望用于云计算数据中心,为数据中心服务器能耗的“量化”提供理论和实践依据.同时,本文所提出的模型也可用于评估节能算法的优劣,有助于资源提供者预测和优化数据中心的能耗.
