基于人工智能和深度数据分析技术的考评系统设计
2021-04-20徐军委刘长胜
徐军委,刘长胜
(国网新疆电力有限公司,新疆乌鲁木齐 830000)
在大数据背景下,新的工作考核评价理论与体系的应用研究成为热点:文献[1]论述大数据技术对高校科研评估科学性、准确性及优化资源配置的积极作用;文献[2]使用大数据技术构建表现预测、迭代检测、质量预警的学习评价体系;文献[3]提出利用大数据及人工智能方法构建高中生专业兴趣评估及学科建立评估系统;文献[4-5]将大数据技术应用于公务员绩效评估中进行理论研究;文献[6]基于智能设备在对建筑工人施工安全方面,建立了相关考核与激励机制。即当前的研究主要集中在理论分析,且多用于对项目的评估及对基层公务员的考核,对员工的工作考核体系的创新性研究较少。针对相关研究较少、工作考评因素单一的问题,该文提出了基于人工智能算法及深度数据分析技术的工作考评系统。
1 系统总体架构
图1 为系统的整体框图,该系统主要由数据获取模块、数据预处理模块、评价考核模块及反馈激励模块组成。以员工为系统的主体,最终评价考核结果再反馈至员工,使整个系统形成闭环。首先,利用数据挖掘技术对员工工作的相关数据进行处理分析,并提取关键性的特征指标;然后,对提取的关键指标进行预处理后,根据权重作为人工智能算法的输入,通过训练后由人工智能算法进行分析;最终,对员工的工作给出等级性考评;由于算法的透明性可将系统的评估过程输出,并将其作为对被评估员工的反馈激励。
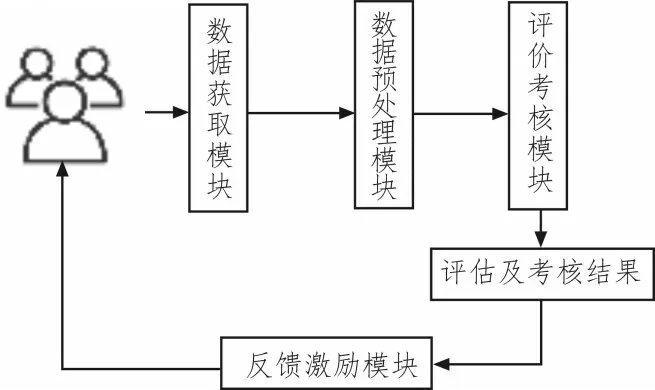
图1 系统总体框架图
2 数据的获取和预处理
2.1 数据的获取
获取的员工数据主要包括两类:基础数据与日常数据。基础数据由员工入职时一次性收集,并由人力资源管理部门定期核查更新,通过定期更新,即可完成此类数据的收集;日常数据传统方法由员工上报或公司定期审查相结合的方式收集,当前随着物联网技术的发展,网络数据库、移动终端等给此类数据的采集提供便利,常用的获取方法有:1)使用统一联网接口进行出勤考核;2)使用二维码对员工任务进行标注,最后通过二维码统计任务数据;3)移动终端申报系统、工作状态识别系统等。
2.2 数据的预处理
数据预处理的过程主要如下:
1)数据清理。即对所获取的数据中的缺失、异常等数据进行处理;
2)数据集成。即去除获取数据中无关数据,并合并数据中的相关数据;
3)数据变换。即利用数据变换将数据转变为方便作为人工智能算法输入的类型。
该系统使用Python 语言数据的预处理相关工作,相关的处理方法如下。
①数据的装载
data=pandas.read_csv("./data.csv");
或data=pandds.ExcelFile("./data.xlsx");
其中,函数参数为对应读取文件的路径。而data 变量为生成的Data Frame 的数据结构。通过此方法,可读取.csv 或.xlsx 类型数据。下面即可使用科学数据库对数据进行处理。
②缺失值的处理
关键操作如下:
index_null=pandas.isnull(column);
column_null_true=column[index_null];
其中,column为待处理的数据列。pandas库中使用isnull()方法可以获取列数据中缺失数据的索引,通过获取到的缺失数据索引再对缺失值进行处理。
对于员工指标数据中的缺失值,要根据指标不同的重要程度采取对应的措施,如:再次补录或使用所有数据中的某个统计量代替(最小量、最大量、中位量、众量等)。
③无关值的删除与相关值的合并
无关值删除关键的操作为:
data.drop('column',axis=1)
执行该操作可删除名为data 中列的名字为column 的数据,其中axis=1 代表对列进行删除操作;
对于相关数据可使用data["column"]引用对应列的数据,之后可使用对应的运算向相关的数据行处理或合并。如:
data["column1"]=data["column1"]+data["column2"]
data.drop('column2',axis=1)
上述操作实现了对列1 与列2 相关数据的合并。
在员工相关数据的处理中,对姓名、序号、工号等与绩效评估无关的数据可在进行考评前删除;对诸如入职年份、工龄、出勤次数、缺勤次数等可先根据其相关关系,对数据进行合并。
④连续数据的离散化
连续数据离散方法如下:

其中,data 为DataFrame 格式的数据,fun 为自定义的操作函数,可通过自定义系列操作函数完成复杂的数据处理。
实现连续数据离散化的自定义函数格式如下:

其中,column 为待处理的数据列的列名称,column data 为根据列名获取的列数据,value 为指定的连续数据的分割值,class1、class2 分别为指定的离散化后数据的类名称。
3 评估算法及反馈激励
该文将对员工工作的考评问题等价于对相关工作数据的分类操作。近年来有多种人工智能算法被应用于分类问题,文献[7-8]使用SVM 算法实现对遥感图像及恒星光谱的分类。文献[9-10]使用神经网络相关算法实现了文本及目标图像的分类;文献[11-12]使用K 近邻算法实现对多标签数据及高速铁路故障的分类;文献[13-16]使用决策树或决策森林实现了对数据的分类。其中,决策树算法具有实现简单、运算量小、决策过程透明且可复现等优点,综合考虑相关因素,本体系采用决策树算法。
3.1 决策树算法的实现
决策树算法利用信息熵原理对数据进行分类,信息熵值可表征数据的混乱程度,信息熵定义为:
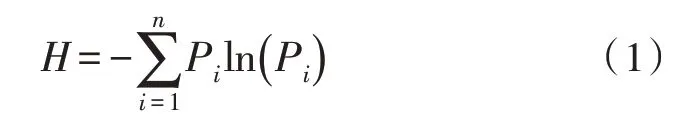
式(1)中,H为数据集的信息熵,Pi为对应数据i在整个数据集中发生的概率,n为数据集中数据的类数。
决策树算法的实现过程如下:
1)计算整个数据集的信息熵:
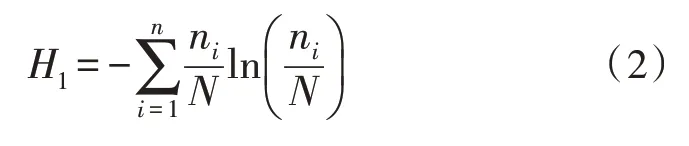
式(2)为整个数据集熵的计算方法。其中,ni是每类数据在数据集中的个数,N为数据集中数据总个数;
2)计算信息熵的增益,信息熵增益的计算方法如式(3)所示。
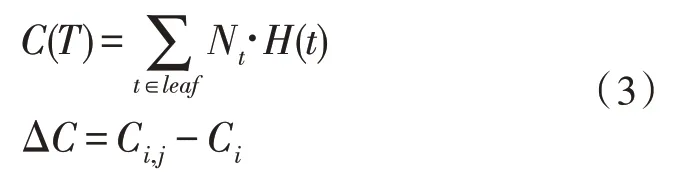
式(3)中,Nt为对应枝的概率,Ci为数据集信息熵,Ci,j为添加分割属性j后的信息熵。然后,选择熵增益最大的属性作为根节点,完成分割后再重新执行上述决策树算法的步骤1)和2)。
由此即可建立出决策树的分类模型。同时,可视化该模型即为反馈激励模块的输出。
3.2 反馈激励机制
由于决策树的透明性及可复现性[17-19],在生成决策树后,整个决策过程可进行输出,通过决策过程可表现出各个指标在评估过程中的重要程度。因此,将评估过程生成的数据反馈给被评估者,可以使被评估者清楚地了解自己在工作中的不足,以及各评估指标的重要程度,从而激励被考评者的工作潜能与积极性。
4 系统的实现
选取某企业员工工作考核表数据进行系统实现,数据集中共40 名员工。经数据预处理后[20-21],提取与工作关联较大的指标有:Jobage、Task、Language、Teamwork 和Professional,而考评结果从优到劣分为由A 到D 共5 个类别,其中B 类2 个。
选取数据集中24 名员工为训练集,剩余16 名员工为测试集对该考评系统进行测试。24 个训练集中5 类考核结果个数分别为:3,5,9,5,2。由式(1)得初始集合的信息熵为:
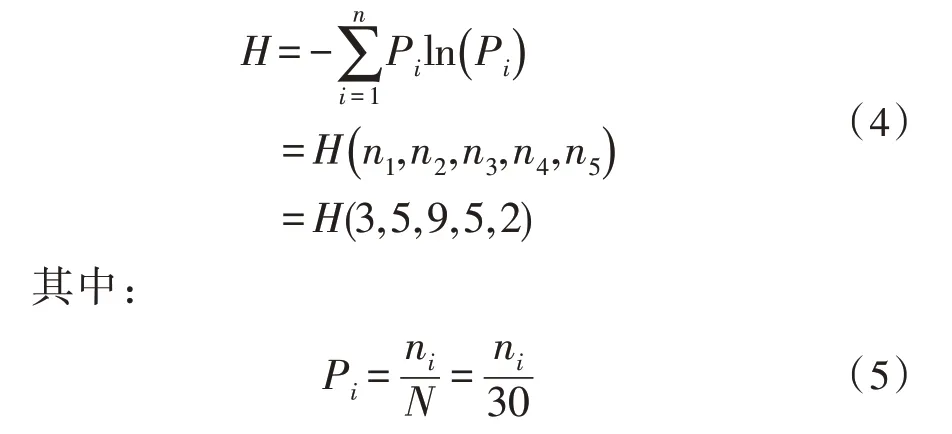
将式(5)代入式(4)中得:H=1.975 4;
对应Task 为excellent 时,共有8 个样本,各类考核结果的个数分别为:3、3、2,则此时信息熵为:
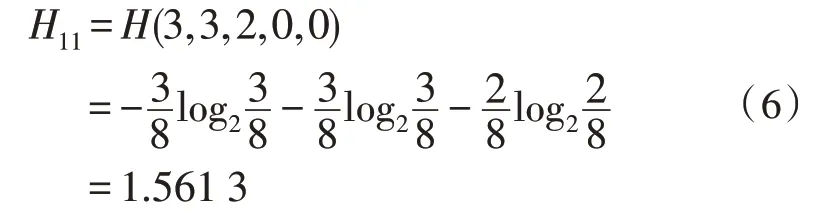
同理可得,当Task 为good、poor 时:
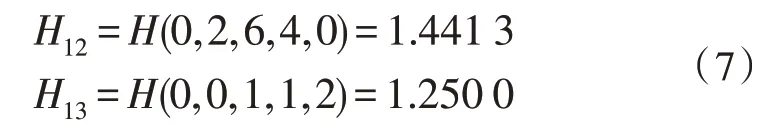
则由式(2)对应Task 的信息熵为:
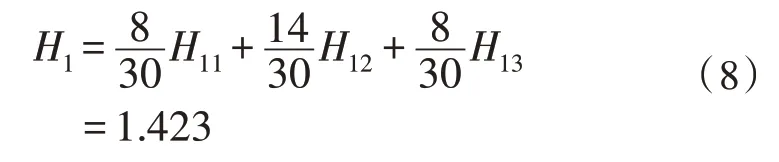
则选Task 为根节点的信息熵增益为:
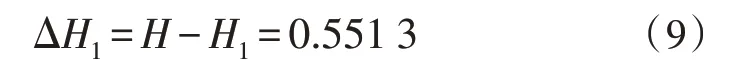
同 理,计 算 对 选Jobage、Language、Teamwork、Professional 为根节点计算信息增益率,如表1 所示。
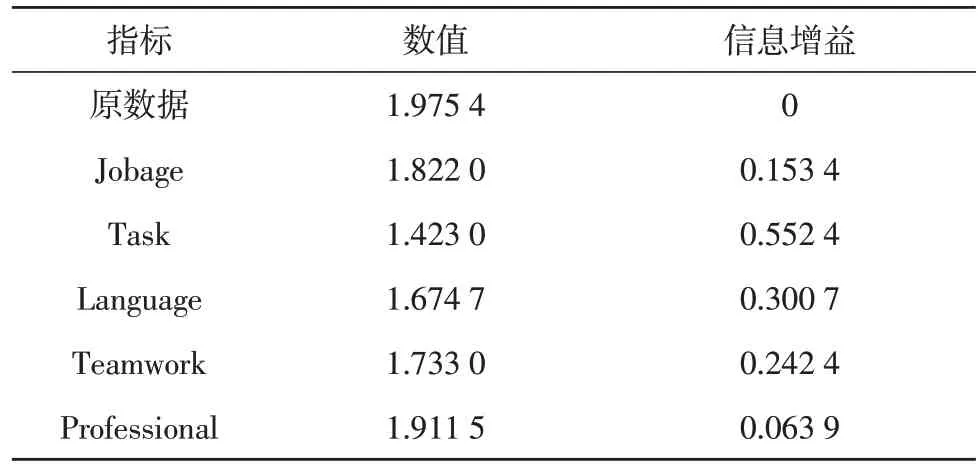
表1 确定根节点熵增益表
根据表1 可知,Task 属性的信息增益最高,因此选择其为根部节点。同理,根据信息增益的数值,依次确定决策树的决策过程如图2 所示。
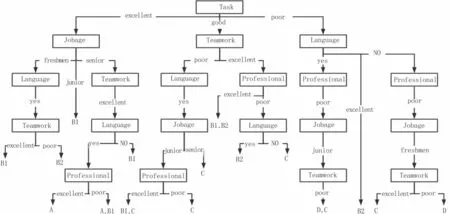
图2 决策过程
使用该决策树对6 个测试样本进行考评,考评结果如表2 所示。
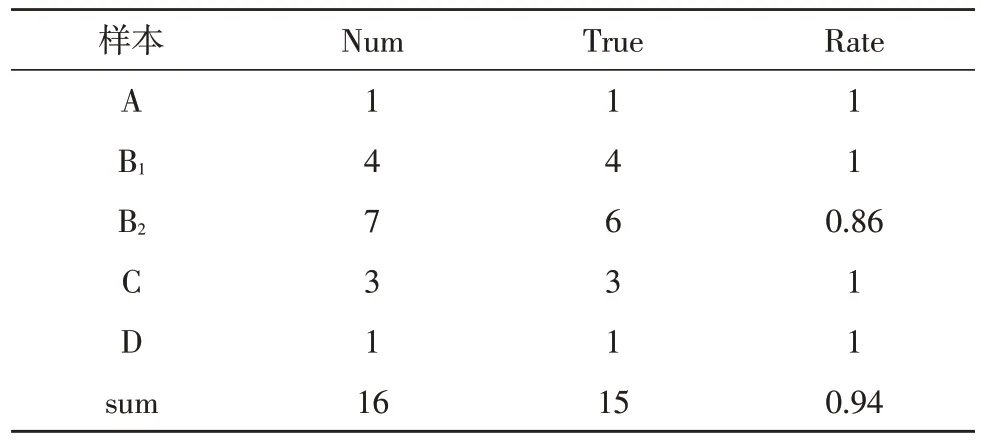
表2 考评结果
由数据结果可知,考评的正确率可达94%,验证了该体系的正确性和有效性。同时,系统把决策过程也反馈给被考评的员工,从该过程中,员工可以获得以下信息:明晰自己绩效的变化,Task 指标的重要性,了解Jobage、Teamwork 和Professional 等指标的信息,从而起到对员工的激励作用。
5 结束语
该文利用人工智能相关算法及深度数据分析技术构建员工的工作考评体系。该体系中利用数据挖掘技术,对获取的员工数据进行清理、集成与变换,即使用决策树算法利用处理好的数据实现员工工作的考核评价。同时,利用评价过程对员工进行反馈激励,使员工评价考核体系几乎无主观因素的影响,且更加智能化。该体系也存在一些不足,例如:为使评价考核的过程更加清晰明了、保持良好的运算速度,该文未使用多棵决策树组成随机森林算法,导致了考评结果的准确率有所降低,而且在出现多类的叶子节点时,仍需人工进行再次分类。
