基于注意力机制的主题扩展情感对话生成
2021-04-20杨丰瑞张许红
杨丰瑞,霍 娜,张许红,韦 巍
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学通信新技术应用研究中心,重庆 400065;3.重庆重邮信科(集团)股份有限公司,重庆 401121)
0 引言
在人工智能领域中,让机器可以与人情感交互是一项极具挑战而有意义的任务。近年来,随着深度学习技术在各种应用中的普及,推动了对话系统的快速发展,有关对话生成的研究成果不断涌现。人们交换的言语信息不仅包含句法信息,而且还传达着人们的心理和情感状态。在真实的对话中两个人往往会给予对方情感上的抚慰,称之为情感智力,它是人类智力的重要组成部分。实验结果表明,具有情感智力的对话系统能够减少对话中的故障[1],提高用户满意度[2],因此人们开始聚焦于发展具有情感智力的对话系统。
关于对话系统的研究可以分为三种:基于规则的、基于检索的和基于生成的方法。第一种方法主要依赖于手工制定的规则,只能适应于非常有限的领域中。随着网络上社交数据的快速增长,很多现有研究使用数据驱动的方法来实现对话系统,即基于检索式的方法,从对话语料库中检索与查询匹配的答复,但很大程度上受限于数据库的规模。近年来深度学习技术的兴起推动了生成式聊天机器人的发展,相比之下,基于生成的方法能够产生更灵活的响应,通常是通过训练序列到序列模型,将帖子视为输入,响应视为输出。
然而,生成式聊天机器人生成的回复也存在一些问题,比如经常会生成一些安全却无意义的通用回复,如“我不知道”“我也是”等语句。所以很多研究[3-5]以数据驱动为基础来提升生成式对话系统的效果。最近一些研究致力于实现人机之间的情感交互[6-7],与检索式方法相比,生成式方法更灵活、更方便融入情感。研究者尝试在大规模语料库的背景下使用序列到序列模型生成情感响应。Zhou等[6]首先将情感因素引入到生成式对话系统,提出基于记忆网络的情感对话系统ECM(Emotional Chatting Machine)。他们在传统的序列到序列模型的基础上,使用了静态的情感向量表示、动态的情感状态记忆网络和情感词外部记忆的机制,使得ECM 可以根据指定的情感分类输出对应情感的回复。但是以往在该任务上的研究侧重于关注情感因素,忽视了生成话题内容的相关性和多样性。为了提高情感响应的质量和多样性,本文提出了主题扩展的情感对话生成模型,可以生成内容相关且多样的情绪化响应。与本文相似的工作是文献[7]提出的基于注意力机制的主题增强情感对话生成模型TE-ECG(Topic-Enhanced Emotional Conversation Generation),该模型利用主题词保证生成内容的相关性,并利用动态情感注意力机制来生成蕴含指定情感类别信息的回答。但是该任务忽略了对话过程中一直谈论同一个话题是很无趣的,通常会让人很快结束与机器的对话,可能会导致生成句子内容质量的下降。研究表明,在一个会话中,人们往往倾向于加深或扩大他们聊天的主题,使得对话更有吸引力和更有意义[8],如表1所示。

表1 主题扩展的情感对话示例Tab.1 Emotional conversation examples with topic expansion
本文提出的模型是基于带有注意力机制的编解码器框架,该模型通过融合模块将情感因素和主题信息整合到对话系统中,融合模块利用语义相似度扩展主题词,提升回复内容的多样性;利用依存句法分析提取与主题相关的情感词,加入情感智力。为了验证提出模型的有效性,在大型微博帖子和回复对上进行了实验,并通过自动评估和人工评估将提出的模型与多个模型进行了比较。实验结果表明,本文模型可以生成内容丰富的情感响应,并在评估指标上取得良好的性能,优于实验对比模型。
本文提出的模型同时将主题信息和情感因素整合到对话系统中,主要工作如下:
1)提出了主题扩展的情感对话生成模型。利用语义相似度扩展主题词,这是提升回复内容多样性的关键步骤。同时,利用依存句法分析提取与主题相关的情感词,融入情感因素。
2)提出的对话系统可以生成话题丰富的情绪响应,效果优于传统的序列到序列对话生成模型。
1 相关工作
对于人机情感对话,目前的工作大致分为两类。
1.1 对话生成
由于可用数据集的增加和深度神经网络技术的快速发展,对话系统已经取得了很大进展。传统的对话系统通常依赖于手工构建的模板和规则,阻碍了对其他领域的泛化能力。近年来,已经提出了更多数据驱动的对话系统。在开放领域,它们大致分为两大类:基于检索和基于生成的方法。基于信息检索的系统[9-11]根据输入的句子在候选应答中匹配最相似的句子作为应答,这涉及到特征的选择和排序算法。但它们必须满足这一前提条件:选定的响应应该预先存在,因此,性能受到存储库的规模和质量的限制。后面基于生成的系统受统计机器翻译[3,12]的启发,利用数据驱动的方法对帖子及其响应之间的映射进行建模。对话系统往往会产生一些普遍且毫无意义的回应,例如“我也是”。因此,已经进行了大量的研究来改善对话的内容质量。一些研究者提出用主动内容引入的方式来生成对话[4,13]。Tao 等[14]应用多头注意力机制来捕获查询话语中不同方面的语义,并通过正则化目标函数使得回复更多样化且仍与给定查询相关。Liu 等[15]通过将用户配置文件整合到会话模型中来完成个性化响应排序任务。尽管这些研究可以产生有意义且高质量的响应,但是由于缺乏情商,聊天机器人仍然无法自然地与用户进行交流。
1.2 情感智力
情感智力是成功的、智能的对话系统不可或缺的重要组成部分[16]。研究人员尝试赋予对话系统以情感。Ghosh 等[17]提出一个定制情感文本生成的神经语言模型Affect-LM(neural Language Model for customizable Affective text generation),可根据输入情感类别、情感强度β和上下文单词生成句子。Zhou 等[6]提出了ECM 模型,结合了情感类别的向量,并加入内部情感机制,最后引入外部情感机制来选择回复的词为一般词还是情感词,从而得到附有不同情感类别且文本质量也很好的回复内容。Zhang 等[18]提出了两种情绪感知条件变分自编码器EsCVAE(Emotion sensitive Conditional Variational AutoEncoder)结构,用于确定响应生成的合理情绪类别。彭叶红[7]提出了TE-ECG 模型,利用主题词保证生成内容的相关性,并利用动态情感注意力机制来生成蕴含指定情感类别信息的回答;但是没有考虑到人机对话时聊天主题的多样性,以及人们对不同主题有着不同的情感倾向,可能会导致聊天很快结束。为了解决这个问题,本文提出了一个新颖的模型,通过融合模块将主题信息和主题相关的情绪整合到对话系统中,可生成内容丰富并且情绪相符的响应。本文所提模型受到相关的研究[7-8]启发,考虑了聊天时话题的深入和情感的共鸣,本文的工作与相关研究[7-8]有所不同,具体而言,融合模块利用语义相似度扩展主题词,提升了回复内容的多样性,利用依存句法分析提取与主题相关的情感词,加入了情感智力。
2 本文模型
给定源序列(查询)X=(x1,x2,…,xT)和用户给定的情感类别e,对话任务是生成与情感类别e相一致的目标序列(响应)Y=(y1,y2,…,yT′)。情感类别包括{喜欢,悲伤,厌恶,愤怒,高兴,其他}[6]。为了在对话任务中生成内容丰富且情绪相符的响应,本文提出的情感对话系统总体方案如图1所示。
该方案首先对上下文的完整历史信息进行全局编码,引入主题模型获得全局主题词,使用外部情感词典获得全局情感词;其次,融合模块利用语义相似度扩展主题词,利用依存句法分析提取与主题相关的情感词;最后该模型采用注意力机制来对上下文、全局主题词和扩展的主题词、全局情感词和提取的与主题相关的情感词进行加权,然后将它们馈送到用于生成响应的循环神经网络(Recurrent Neural Network,RNN)解码器中。
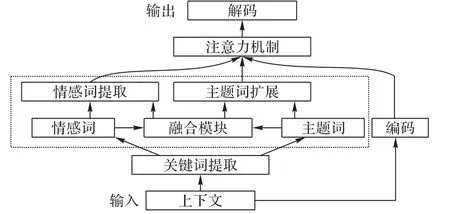
图1 基于注意力机制的主题扩展情感对话生成系统框架Fig.1 Framework of topic-expanded emotional conversation generation system based on attention mechanism
2.1 编码器
在序列到序列(Sequence to Sequence,Seq2Seq)模型中,给定源序列(查询)X=(x1,x2,…,xT)和目标序列(响应)Y=(y1,y2,…,yT'),该模型会最大化以X为条件的Y的生成概率:p(y1,y2,…,yT'|x1,x2,…,xT)。Seq2Seq 由编码器和解码器组成,编码器通过循环神经网络(RNN)将输入序列压缩成指定长度的向量,这个向量可以看成这个序列的语义,表示为上下文向量c,然后解码器RNN 以c为输入来估计Y的生成概率。Seq2Seq模型的目标函数如式(1)所示:
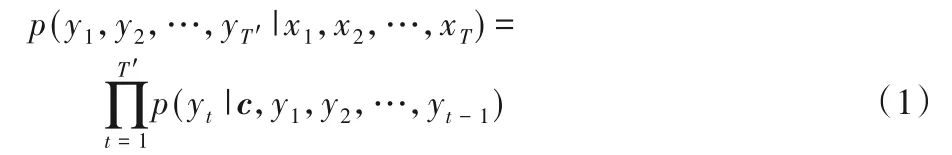
给定由几个词语组成的上下文,将其视为单词序列。RNN编码器计算上下文向量如式(2)所示:

其中:上下文W表示数目为T的单词序列;ewt是第t个词语的嵌入向量;ht是RNN 在时间t的隐藏状态;f是非线性变换函数。通常把编码器最后时刻输出的隐藏状态hT表示为上下文向量c。
因为传统的RNN 在处理序列数据时会受到短时记忆的制约,可能会遗漏重要的主题和情感信息。本文使用的是基于RNN 改进的门控循环单元(Gated Recurrent Unit,GRU)[19]来实现f函数,GRU网络的参数化为式(3)所示:

其中:xt是输入向量;ht是输出向量;u是更新门向量;r是重置门向量;Wu、Wr、Ws、Uu、Ur、Us是参数矩阵;∘表示逐元素相乘;σg和σh分别是sigmoid和tanh激活函数。
2.2 关键词获得
为了使人们参与对话,聊天机器人应该生成信息丰富且有趣的响应,所以应该在生成响应时引入关键的信息,例如主题和情感。这个想法的灵感来自于对人类之间对话的观察。在人与人的对话中,人们经常围绕某些主题来展开对话,并且带有对主题的特定情感交互。基于上下文的消息内容,首先通过训练基于Twitter 的隐式狄利克雷(Latent Dirichlet Allocation based on Twitter,Twitter LDA)主题模型[20]来生成主题词典。Twitter LDA 模型的主要思想是将每个文本对应于一个主题,并且文本中的每个单词都是该主题下的背景词或主题词。Twitter LDA模型的结构如图2所示。
采用Gibbs 采样算法估计Twitter LDA 模型的参数。使用模型将主题z分配给源序列X,选择主题z下概率最高的前k个主题词(实验中设置k=20)。在学习中,需要获得每个主题词的向量表示。首先通过式(4)计算主题词w的分布:

其中:qwz是主题词w在训练中分配给主题z的次数;p(z|w)为主题词w的向量表示。并且使用外部情感词典获得情感关键词,本文使用的情感词典源于文献[21]所做的工作,其中涵盖了七种情感类别的共计27 466个关键词。首先对输入的序列X进行分析,得出情感类别,为了高度抽象表示情感类别,引入不同的情感类别向量v={ve},再进一步选择情感关键词。本文不是直接使用输入序列的编码向量hi,而是采用注意力机制来突出情感特征,具体的计算步骤如下:

根据式(8)生成的概率分布,可以从情感词典中选出最合适的情感关键词。

图2 Twitter LDA模型的结构Fig.2 Structure of Twitter LDA model
2.3 融合模块
针对隐式狄利克雷(Latent Dirichlet Allocation,LDA)模型只适用于提取全局特征词的局限性,以及人工指定情感类别的弊端,本文在全局主题词和全局情感词的先验知识下,基于真实的上下文信息,对LDA 主题模型进行改造,进一步提出了融合模块,扩展主题词以提高局部主题词的发现率,以主题词为目标尽量发现更多的局部情感词,实现细粒度主题词和情感词的提取;并在解码器阶段学习输入文本、主题和情感的融合表示。
2.3.1 主题词扩展
在许多扩展主题词的方法中,为了更好地考虑上下文信息,采用词嵌入来计算与主题词的语义相似度以扩展主题词。词嵌入,也称为分布式表示,是将单词表示为数学向量。该模型使用连续的词袋(Continuous Bag Of Words,CBOW)来基于上下文信息预测当前词,并使用跳字模型(skip-gram)架构来预测所给当前词的周围词,以学习词的分布式表示形式,将词表示成一个定长的连续的稠密向量。语言模型是通过三层神经网络构建的,如图3所示,词向量是在构建过程中产生的。
在神经网络中,所有单词的集合是一个词典,映射矩阵C将每个单词映射为一个向量,C(wt)表示为wt的词向量。选择已知的前n-1 个单词{wt-n+1…wt-2wt-1}作为第一层的输入,而普通的双曲正切隐藏层是第二层。然后,在第三层中,使用激活函数softmax 将输出值归一化为概率。最后,执行随机梯度下降算法以优化模型,从而从输出值中获得下一个单词wt即对应于词典中的第i个单词的词向量。通过词向量间的余弦相似度可计算词之间的相似性。
当输入一个源序列X时,首先给其分配主题并选取概率最高的前k个主题词,输入序列文本中除主题词之外的背景词可能也含有重要语义信息,计算一个主题下的主题词和背景词的余弦相似性,并选取相似度最高的k′个词加入主题词中,实现主题词的扩展(k+k′)。余弦相似性计算如下:

其中:θ为两个向量之间夹角角度。cos(θ)的值越接近1,那么词向量间的相似度越高。

图3 三层神经网络模型Fig.3 Three-layer neural network model
2.3.2 主题词相关的情感词
人们通常会表达对特定主题或对象的情感,而情感词在句法分析中通常与主题或对象存在依存关系。因此,本文主要考虑以下三个依存关系:
VOB(verb-object):“VOB”代表动词和宾语之间的关系。情感词是动词,主题词是动词的宾语。例如,“我喜欢大海。”中,在“喜欢”和“大海”之间存在“VOB”关系。
SBV(subject-verb):“SBV”代表主语和谓语之间的关系。情感词是谓语,主题词是情感词的主体。例如,“星星很漂亮。”中,在“星星”和“漂亮”之间存在“SBV”关系。
ATT(attribute):“ATT”代表属性之间的关系。情感词是属性,主题词是情感词的修饰中心。例如,“精彩绝伦的表演!”中,在“精彩绝伦”和“表演”之间存在“ATT”关系。
采用哈尔滨工业大学的语言技术平台(Language Technology Platform,LTP)进行简单的句法分析,本文提取了上述三种与主题词相关的情感词。设计的主题相关的情感词提取算法如下所示。

2.4 解码器
本节在解码器阶段加入了注意力机制。在模型的解码阶段,解码器每一个时刻的隐藏状态的计算都需要上下文语义编码向量c。传统的Seq2Seq 模型中,只用编码器最后一个时刻的输出作为语义编码向量c,且保持固定不变,但加入注意力机制之后,每一时刻的c都将各不相同,从而能保证在解码的不同时刻,输入序列中的每一个词语对当前时刻解码的词语的贡献不同。在t时刻,上下文、主题和情感信息最终被综合在权重向量ct中,计算如下所示:

αti是权重系数;hi为上面已知编码器的输出向量;T是上下文词语的数量;M是主题词的数量;N是主题相关情感词的数量。与隐编码向量hi性质一样,训练中间参数矩阵Wt进行运算得到主题词隐向量mi和情感词隐向量ni,计算如式(11)所示:

其中:eTi是第i个主题词的向量表示;eEi为第i个情感词的向量表示。
由于每一时刻的权重向量ct都各不相同,解码器在t时刻的隐藏状态st计算如式(12)所示:

其中:yt-1是t-1 时刻的输出词。最后,解码器RNN 逐个词地解码出目标语言序列,计算如式(13)所示:

其中:Wy和by是投影层的参数,该层将隐藏状态投影到词汇表中所有单词的概率分布;Ti是第i个主题词;Ei是第i个情感词;yt是目标响应的第t个词;σs是softmax激活函数是yt的一位有效编码。

3 实验与结果分析
3.1 实验设计
本文使用了中文对话语料数据作为实验数据,该数据来自NLPCC(Natural Language Processing and Chinese Computing)于2017 年发布的情感对话数据集,其中包括了1 119 207 个问句-回答对,其中在每个问句和回答都带有一个相应的情感类别的标记,数据具体的构建方法见文献[3]。随机划分出5 000 个问答对作为验证集,5 000 个问答对作为测试集,剩余数据作为训练集。
本文模型是在Tensorflow 平台上实现的。编码器和解码器具有两层GRU 结构,每个GRU 层隐藏节点数设置为256,将词嵌入大小设置为100。词汇量限制在40 000个以内,词汇表之外的所有单词都映射到特殊标记UNK(unknown)。情感类别的嵌入大小设置为100。最后,本文将主题数量设置为100 个,选择每个主题对应的前20 个主题词。从输入序列文本中扩展了至少5 个主题词。本文使用Adam[22]优化目标函数,批次大小和学习率分别设置为128和0.001。
选用了两个基准模型作为本文的对比方案:一个是基于注意力机制的Seq2Seq 模型(Sequence to Sequence model with Attention,Seq2SeqA)[23];另一个是TE-ECG 模型[7],该模型在对话中融入了主题信息,并指定回复情感类别。
3.2 实验结果与分析
本文遵循现有的研究采用了人工和自动评价两种方式。正如前面所说,对话任务是生成与给定源序列(查询)和用户给定的情感类别e相一致的目标序列(响应)。本文对话中不仅分析上下文信息,充分考虑主题和情感因素,生成有意义的、信息丰富的且情感交互的回答。因此为了相对准确地衡量生成响应的质量,本次实验参考ECM 模型和TE-ECG 模型的人工评价方法。
本文还考虑了自动评价标准将生成响应与真实响应进行比较。BLEU(Bi-Lingual Evaluation Understudy)不适合评价会话生成,因为它与人工评价的相关性较低[24]。为了验证响应的信息量和多样性,本文采用了Li 等[25]设计的distinct-1 和distinct-2 度量标准。distinct-1 和distinct-2 分别是不同的单字和双字在生成的总的字符中的所占比例,较高的distinct-1 和distinct-2意味着响应更加多样化。
3.2.1 人工评价
对同一输入序列语句,将Seq2SeqA、TE-ECG 和本文模型所分别生成的输出响应进行人工评价,来判断哪种模型的生成响应质量更好,表2 中的数值代表模型对比时三种不同评价所占的比例。从表2 所示的三种模型的人工评价结果可以看出:突出了主题和情感信息的本文模型生成响应的效果较传统Seq2SeqA 模型有了很大的提升,与没有扩展主题词的TE-ECG 模型相比,效果也有一定的提高,说明传入到注意力机制中的主题和情感信息增大了上下文中有意义的信息量,丰富了生成回复内容,提升了情感交互体验,更加符合人类的对话习惯;但是本文方法与TE-ECG 方法的对比效果没有很大的提升,可能是本文使用主题下的背景词来作为主题词的扩展,在同一个主题下,背景词的信息量占比较小,本文以后的工作也会继续探究如何使用其他方法来增大主题特征词的信息量。

表2 三种模型的人工评价结果比较Tab.2 Comparison of manual evaluation results of three models
对于同一个输入序列语句,解码器可以输出很多个不同的生成结果,所以考虑多个生成结果的有效占比更能反映出模型的效果。遵循已有的文献[23],在模型中使用beam search 解码器返回前10 个最优的输出结果。如表3 所示,如果输出生成结果被人工评价为内容有意义时,输出结果有效,表3 中的数值代表有意义的输出响应结果相对于总体的占比。从表3 的比较结果可看出,本文模型的效果明显好于传统的Seq2SeqA 模型,在考虑前10 个最优输出结果时(Top10)效果更为明显,说明了本文基于LDA 主题模型进一步扩展主题词,提高了生成语句的多样性,从而验证了本文模型的有效性。

表3 模型的Top1和Top10有效率比较Tab.3 Comparison of Top1和Top10 effective rates of models
3.2.2 自动评估
自动评估实验是采用两个客观的指标,在内容上评估生成的响应。分别从unigram 多样性(distinct-1)和bigram 多样性(distinct-2)上比较各模型,如前所述,本文使用的基准模型是Seq2SeqA 和TE-ECG,在测试集上利用本文模型和基准模型分别生成响应。自动评估结果如表4 所示,本文模型总体效果最优,并且在每个不同的情感类别中都得到了改善。与TE-ECG 模型相比,本文模型在unigram 多样性(distinct-1)和bigram 多样性(distinct-2)上分别提高了16.3%和15.4%;与Seq2SeqA 模型相比,本文模型在distinct-1 和distinct-2 上分别提高了26.7%和28.7%。表4 的结果表明了将丰富的主题信息与主题相关的情感因素相融合,与基准模型生成的响应相比,本文模型优先考虑了主题词和情感词信息,可以生成更高质量的响应。

表4 distinct-1和distinct-2在三种模型上的自动评估结果Tab.4 Automatic evaluation results for distinct-1 and distinct-2 of three models
3.2.3 结果分析
在表5 中展示了一些样例,分别由基准模型和本文模型生成。可以看出,与Seq2SeqA 相比,本文模型融合主题和情感信息后生成的响应内容丰富,情感明确;与TE-ECG 相比,本文模型因为扩展了主题可以生成多样化的响应,并且融入了主题相关的情感信息使得情感表达更加贴切。实验结果表明,本文模型能够同时在内容和情感上生成合适的响应。
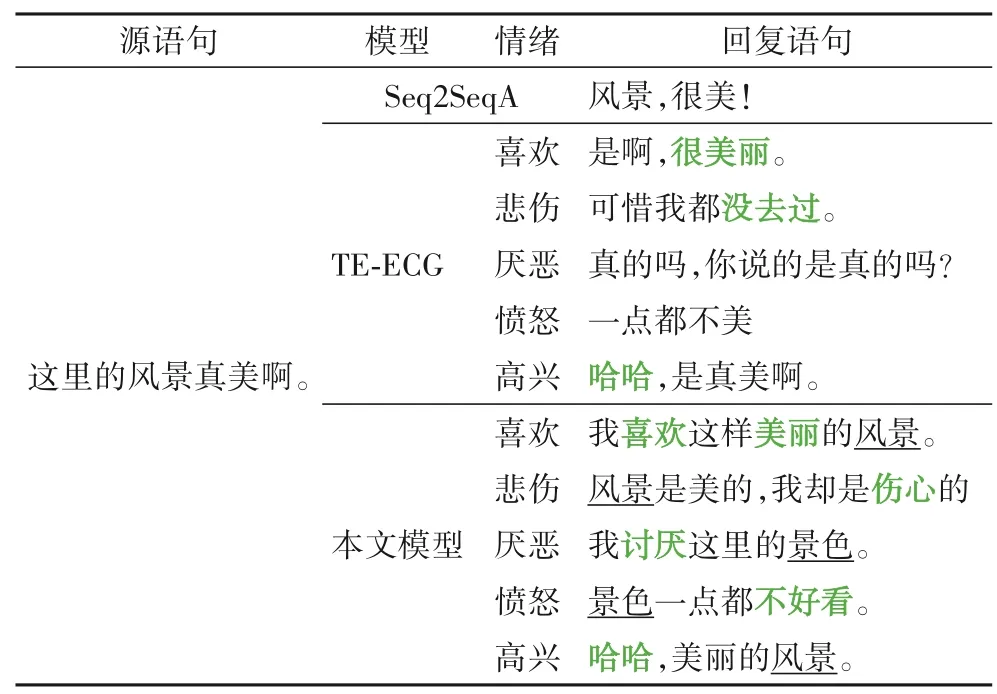
表5 不同模型生成的回复样例Tab.5 Sample responses generated by different models
4 结语
本文提出的模型由全局模块和融合模块组成。全局模块对上下文进行全局编码,并且获得全局主题词和全局情感词。融合模块将主题和情感信息相融合。人工评价和自动评价都表明,本文模型不仅在内容上,而且在情感上都能生成合适的响应。在未来的工作中,会继续提升融合主题和情感的对话生成质量,进一步探索如何精准地提取关键词,将关键词自然地融入到对话生成中。
