基于SVM 和GA- SVM 的NIR 光谱柑橘产地鉴别模型研究
2021-04-13但松健
但松健
(重庆第二师范学院继续教育学院,重庆,400067)
支持向量机(Support Vector Machine,SVM)是Vapnik 提出的一种能有效地用于模式识别和数据挖掘的识别模型[1],尤其在处理高维非线性样本问题上,SVM具有很好的识别效果。作为有监督的分类模型,SVM具有以下优势:更适用于小样本数据集;更严谨的数学理论支持;高效的非线性分类性能以及能在一定程度上避免维数灾难[2-3]。
本文首先分析了SVM识别算法,并对SVM的核函数和各项参数的选择进行了讨论和测试,以得到更优的识别结果。其次,基于SVM算法,结合基因优化选择算法,对SVM 算法进行了改进,实验结果显示,采用GA-SVM对16 个地区柑橘样本NIR 的产地鉴别中,能得到比SVM更高的识别率。
1 基于SVM 的产地鉴别模型
我们在windows 7 平台下分别利用Matlab 和LIBSVM[4]实现了基于柑橘NIR 的SVM分类模型,并对16 个地区的柑橘样本进行了产地鉴别。首先采用SG 平滑算法对原始NIR 数据进行预处理,然后选用PCA 提取得到光源的特征数据,并选择前25 维主成分作为SVM的特征输入,最后按照5×10 次的交叉验证,将最后的平均准确率作为分类器评判标准。
1.1 SVM核函数选择
首先,我们对SVM 的核函数选择进行讨论。对于不同的核函数,其映射后的特征空间决定着最优决策超平面的构建,因此核函数往往能影响分类的性能,这里对常见的4 种核函数进行了测试,其中核函数的参数采用LIBSVM 的默认参数。结果如表1 所示:

表1 采用常见的4 种核函数以及不同的主成分个数的SVM模型的识别率
从表1 看出,径向基(RBF)核函数在采用不同主成分作为输入时,都比其他核函数的效果更好,特别是在采用前8 和16 个主成分时,达到了最高的识别率93.52%。其综合的平均识别率为93.25%。紧跟之后的是线性核函数,平均识别率为92.39%。多项式Sigmoid 核函数的结果均不理想,比最好的RBF 核函数低了16.33%以及12%的平均识别率。
实验验证了RBF 核函数更适合于本文的柑橘NIR 数据集。其可能的原因为:①RBF 可以将特征映射到更高的空间维度上,比起线性核函数,RBF更适合于类标签和特征之间存在非线性的情况。②与多项式核函数相比,RBF 需要确定的参数少,核函数参数的多少直接影响函数的复杂程度。另外,当多项式的阶数比较高时,核矩阵的元素值将趋于无穷大或无穷小,计算复杂度会大到无法计算。③Sigmoid 核函数在某些参数下是不正确的(例如,没有两个向量的内积的情况)。
1.2 SVM参数设定
构建SVM 分类器另一个需要解决的是SVM中的各项参数的设置[5]。在SVM 中引入了惩罚因子Cost(记为C),来适当放松对支持向量的解,从而加强了SVM的泛化性。C 的取值越小,则SVM模型的容错能力更加,即泛化性越强,但也会减少对训练样本的拟合程度。而C 的取值过大,虽然更加贴切训练样本,但可能造成过拟合从而无法识别新的样本。可以看出C 的取值将影响SVM分类器的性能。
前面已经验证了RBF 核函数更适合本文的NIR 数据。采用RBF 核函数进行SVM分类器构建时,也需要确定核心参数Gamma(记为g)的值,主要作为RBF 函数的宽度参数,控制函数的径向作用范围[6]。
因此,本文的SVM 产地鉴别模型需要确定两个重要的参数C 和g,本文中采用了网格搜索的方法来寻求该参数对(C,g)的最优组合。网格搜索是最常用的也是最直接的参数获取方法。通过设置步长,简单地循环遍历可能的参数对,并记录每一对参数的识别率,从网格中选出最优识别率的参数作为最终的结果,从而避免了参数选择的盲目性和随意性。
网格搜索的结果如图1 所示:

图1 网格搜索最佳SVM模型参数
从图1 可以看出,采用RBF 作为核函数,在参数设置为C=512,g=2 时,经过交叉验证,可以得到最高的识别率93.4252%。
1.3 SVM实验结果
在确定了SVM的核函数以及参数设置后,本文给出了SVM 作为产地鉴别分类器在NIR 光谱数据集上的分类结果。实验结果如表2 所示。

表2 SVM模型在柑橘产地鉴别中的性能
如表2 所示,最好的性能为主成分数16 时,SVM的达到了93.52%的识别率。
2 基于GA-SVM 的产地鉴别模型
通过上面的SVM实验结果,我们可以看到,虽然PCA 能有效保留降维前的数据信息,但不代表其最有信息含量的主成分就是最有区分度的特征。在输入不同的主成分时,SVM的性能也有所不同。为了进一步提高SVM的识别准确率,本文提出了基于遗传算法(GA) 的SVM 识别算法(GA-SVM)[7],该算法通过对提取的主成分信息进行最优的组合,以获得最好的识别结果。基于遗传算法的SVM产地鉴别模型如图2 所示。

图2 基于GA-SVM的柑橘产地鉴别流程图
2.1 GA-SVM
遗传算法(GA)是一种模拟自然界中生物进化、自然选择以及遗传学机理的启发式搜索模型[8-9]。其主要特点是能直接操作结构对象,不存在函数连续性和求导的限定;具有内在的并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。因此,在本文中,遗传算法非常适合用来求解最佳的主成分组合。
在遗传算法中,从含有可能潜在的解的种群开始,通过进化能得到另一个更好的解。每一个种群都含有一定数量的个体,这些个体可以突变或者变异,一般由0 或者1 进行基因编码。求解遗传算法是一个迭代的过程,每一次迭代的过程即产生新的一代种群。通过随机产生新的个体,个体的基因进行随机的突变以进化。同时在每一代,根据问题域中个体的适应度的大小来选择合适的个体,并借助于自然遗传学中的遗传算子来进行组合交叉和变异,产生出代表新的解集的种群,并将产生的新的种群作为下一次迭代的输入,从而反复演化,直到得到最优的近似解。这个过程中,新的种群类似于自然进化中的下一代,比前一代具有更适应于环境的能力(在求解问题中即更贴切于目标解),末代种群中的最优个体经过解码过程即为寻求最优化的最终结果。GA 算法与自然选择中适者生存的原理相对应的元素如图3 所示。

图3 遗传算法中与适者生存的自然进化原理中相对应的元素
其中,图左边为GA 算法中的基本元素,右边为对应的最适应的自然选择的操作。
在本文中,基于GA 算法的主成分选择的详细流程如下:
(1)初始化:首先,从前25 个主成分中随机的选出一个种群,并设置迭代次数T=0,初始化最大进化代数Tmax。选择前25 个主成分是因为已基本涵盖了柑橘NIR 光谱的全部信息。
(2)基因编码:将种群中每个个体的输入编码为[1-25]的字符串。例如,一个6 位的字符串代表可能的最优特征组合 {1,2,3,5,7,9},表示该基因序列包含了第1,2,3,5,7,9 个主成分。
(3)适应度计算:个体适应度的大小决定着各个个体的优劣程度,从而决定其遗传机会的大小。本文中,直接利用将SVM的分类准确率Pa%作为个体适应度的评价指标。
(4)选择运算(或称为复制运算):把当前群体中适应度较高的个体按某种规则或模型通过转移到下一代群体中。通常适应度较高的个体拥有更高的概率将其遗传到下一代群体中。本文中采用常用的轮盘赌选择法进行个体选择。在该方法中,各个个体的选择概率与其适应度成正比,为保留最佳适应度的方法来确定各个个体复制到下一代群体中的数量,选择最大识别率的种群作为双亲复制下一代。设种群大小为n,其中第i 个个体的适应度为fi,则该个体被选中的概率可以看出个体适应度越大。其被选择的概率就越高,反之亦然,这与自然界中适者生存的法则类似。
(5)交叉运算:交叉运算为通过在某一概率下相互交换某两个个体之间的部分染色体从而产生新的个体的过程。本文中采用单点交叉的方法,即首先随机对群体进行配对;其次随机设置交叉点位置;最后相互交换配对染色体之间的部分基因。
(6)变异运算:变异运算是按某一较小的概率改变个体中的某一个或某一些基因座上的基因值,也是产生新个体的一种操作方法。本文采用基本位变异的方法来进行变异运算,首先确定出各个个体的基因变异位置,然后依照某一概率将记录的变异位置上的原有基因值直接取反,从而得到变异后的个体。
通过迭代,GA 算法自动识别出最适合SVM模型的主成分组合,并抛弃没有区分度的主成分,得到最终的特征集即作为SVM 模型的训练输入,从而得到最佳的SVM分类模型。
图4 给出了上述过程的流程图。其中,适应度评价在本文中直接选择优化目标,即SVM 的分类准确率作为评价指标;遗传算子包括了基因的选择、交叉和变异过程。终止条件为达到最大的迭代次数或者达到设定的训练精度;最终输出为训练识别率最高的基因组合,通过解码,即可得到最优的主成分组合。

图4 GA 算法进行遗传进化的流程图
2.2 GA-SVM参数设置与讨论
GA 算法的需要设置的参数较多,包括种群规模,交换律,变异率等[10]。为了得到最佳的GA-SVM性能,根据本文柑橘的NIR 数据特点,为GA 算法设置适当的参数是非常必要的。在本文的实验中最优的主成分组合被编码为1 到25 的整数。对于输出的染色体个数等于最后选择的主成分个数。例如,如果输出的结果为6,即染色体的长度为6,代表着从25 个主成分中相对应的选出的最优的6个主成分。初始化是随机从训练数据中选出一组作为初始的种群。
(1)种群的大小
GA 算法中,种群的大小影响着最优解搜索和收敛速度[11]。如果种群数太小,则GA 无法达到足够的精度或者没有找到最优解就结束了搜索。种群数太大则增加了搜索范围和计算的复杂度。由于各个应用中数据的复杂度和分布不同,目前文献中没有具体的算法来自动的选择种群的大小。本文中测试了不同的种群大小,并记录其适应度以得到合适的参数值。经过测试,各个参数的最优情况下的适应度如图5 所示。
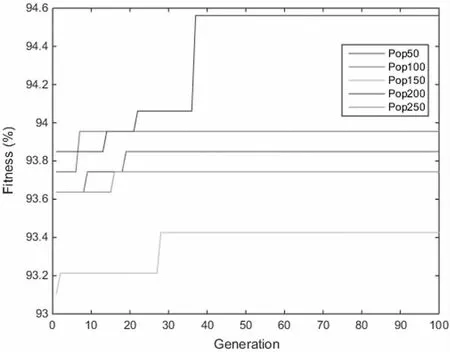
图5 利用GA-SVM在不同的种群大小下进行训练得到的最优适应度
从图5 可以看到当种群大小设置在200 时,GA-SVM可以得到最优的适应度。因此在本文实验中,种群大小将设置为200。
(2)遗传算子
GA 算法中,遗传算子(交叉和突变)促使下一代的基因具有多样性,从而能有效在特征空间中进行启发式的搜索,而突变有效保障了不会丢失可能的解[12]。交叉率和突变率往往影响着GA 算法的性能以及收敛的速度。一般交叉率设定在[0.5,1]之间,而突变率≥0.01。本文中,我们以步长0.1 测试了不同的突变率和交叉率。同时采用了单点交叉来产生最优的下一代,以及均匀变异来存储下一代丢失的信息以产生更合适的个体。
各个交叉率下的最优适应度如图6 所示。从图中可以看出,随着交叉率的增大,适应度也随之提高,但在超过0.7 之后迅速下降。这一现象说明更高的交叉率可以获得更多的新的下一代从而获得更多的机会得到更好的解。但是当交叉率过高,则GA 算法出现一定程度上的退化。因此,根据以上实验本文中交叉率设定为0.6。

图6 利用GA-SVM在不同的交叉率下进行训练得到的最优适应度
对于突变率,实验中分别选择0.01,0.02,0.03,0.04,0.05,0.06,共6 组参数进行测试,其最优的适应度如图7 所示。从图中可以看出,取0.03时,达到最优的适应度,因此最优突变率设置为0.03。

图7 利用GA-SVM在不同的突变率下进行训练得到的最优适应度
2.3 GA-SVM实验结果
在选定了合适的参数之后,本文给出了采用GA-SVM模型对柑橘NIR 数据集进行产地鉴别的结果。为进行对比,本文在实验中同时采用了SVM模型对同一数据集进行预测。按照本文提出的框架,原始NIR 数据经过SG 平滑、PCA 分析操作后,选取前25 个主成分作为GA-SVM和SVM的输入进行训练和测试。本文进行了5×10 次的交叉验证,取最后的平均识别率作为最终的性能输出。
表3 给出了在确定了不同的最终特征个数时,选定的25 个主成分的情况。其中1 表示该主成分被选中,0 表示该特征未作为结果输出。从表中可以看出,第1 个主成分由于含有最丰富的信息,被选中最多。除此之外,第3、6、7、8 项主成分也被选中最多,说明其选中的特征具有很高的区分度。
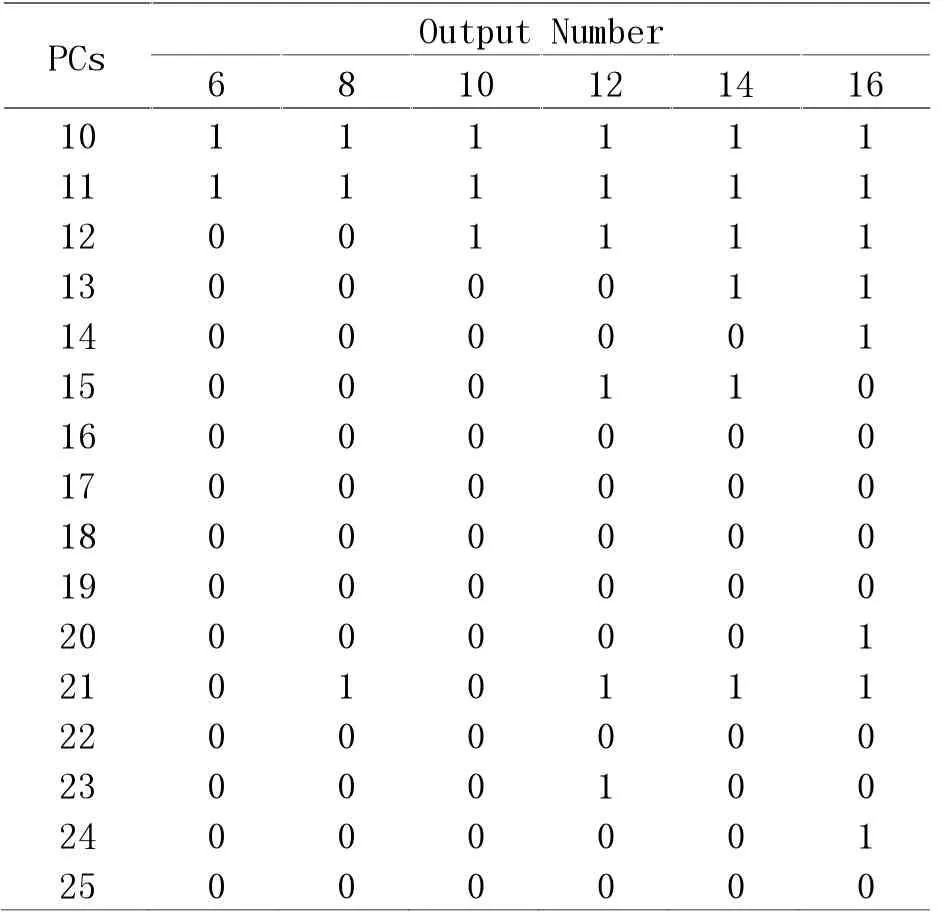
表3 在SG 平滑后的NIR 光谱数据上,通过GA-SVM模型选出的最优的主成分组合
表4 给出了GA-SVM和SVM的性能对照。其中,SVM取前n 个信息最大的主成分进行训练,而GA-SVM取前n 个最佳的主成分组合。可以看出经过遗传算法优化,在取相同的主成分个数进行识别时,GA-SVM 明显优于SVM。在主成分取16个时,GA-SVM 得到最高的识别率94.57%,其最终的平均识别率为93.43%,SVM同时也达到最高识别率93.52%,最终平均识别率方面与GA-SVM接近,达到了93.01%。该实验结果验证了遗传算法通过对主成分进行最优的选择,能够在一定程度上提高SVM的识别率。

表4 GA-SVM和SVM在柑橘产地鉴别的性能
为了进一步综合分析SVM 和GA-SVM 的性能,图8 和9 分别显示了采用SVM 以及GA-SVM在16 个地区的柑橘产地鉴别中的混淆矩阵。其中识别相关的数据已转换为百分比。从图中可以看出,在大部分的地区,SVM 都能准确的识别,识别率最高达到了100%。仅有少量地区的产地识别存在误差,如图中将少量江西信丰地区的柑橘识别为广西全州,以及江西寻乌的柑橘识别为江西安远。在本文选取的样本中,重庆市的柑橘样本较多,选择了包括北碚、渝北、奉节、云阳、巫山等5个地区,由于地理位置较近,种植土壤和光照条件都比较接近,特别是奉节和云阳以及渝北和北碚属于交界地区,因此该地区的样本很难识别。SVM在奉节和云阳地区的识别上出现了较大的混淆。特别是云阳地区的柑橘有28%都误认为奉节的柑橘。
GA-SVM经过特征优化,能找到最优的主成分组合从而提高识别的精度。从图9 可以看出,采用同样的数据集使用GA-SVM 进行产地鉴别,原先江西信丰和广西全州的误分类得到纠正。在混淆较多的重庆奉节和云阳地区,奉节的识别率达到了83%,云阳达到了38%,明显优于SVM 的73%和28%,但在云阳地区的识别上仍然不理想。除此之外,在各个地区的柑橘产地鉴别都达到了很高的精度。

图8 使用SVM模型在16 个地区的柑橘产地鉴别中的结果用混淆矩阵表示

图9 使用GA-SVM模型在16 个地区的柑橘产地鉴别中的结果用混淆矩阵表示
3 结论
为了进一步提升SVM 的识别性能,本文利用遗传算法(GA)对提取的前25 个主成分进行了最优的特征组合。同时,对GA 模型参数的设置进行了讨论,如种群大小、交叉率、突变率等,本文都进行了最优适应度实验。在获得最佳的GA 模型参数后,我们对16 个地区的柑橘进行了产地鉴别实验,并与SVM算法进行了对比。实验结果显示GA 特征选择算法能有效提高识别的性能,特别是提高了部分误分类地区,如重庆奉节与云阳这两个交界地区的SVM识别准确率。最终得到的GA-SVM 模型能达到94.58%的识别准确率,这一结果验证了基于GA-SVM 的NIR 光谱柑橘产地鉴别具有一定的实用价值。
