基于改进的Mask R-CNN的游泳池溺水检测研究
2021-04-02井明涛于腾冯梦瑶杨国为
井明涛 于腾 冯梦瑶 杨国为

摘要: 针对传统的前景检测方法在复杂场景下存在精度低、速度慢且不能有效检测目标动作轮廓等问题,本文主要对改进的Mask R-CNN的游泳池溺水检测进行研究。采用实例分割网络Mask R-CNN进行检测与分割,实现溺水检测,在Mask分支引入空间注意力引导模块,设计了深度注意力分割模型SAG-Mask R-CNN,并在训练Mask R-CNN网络时,严格按照视频顺序帧的顺序输入进行训练,确保Mask R-CNN网络能学到溺水动态特征。同时,将前景检测方法和模型Mask R-CNN进行对比实验。实验结果表明,与Mask R-CNN相比,深度注意力分割模型SAG-Mask R-CNN,在保持检测高速度的同时,分割精度提升了15%~20%,提高了溺水检测的准确性。该研究对减少游泳池中溺水事故的发生意义重大。
关键词: 前景检测; 深度神经网络; 图像分割; 注意力机制; 目标检测
中图分类号: TP391.413; TP183文献标识码: A
作者简介: 井明涛(1994-),男,山东人,硕士研究生,主要研究方向为机器学习和图像处理。
通信作者: 杨国为(1964-),男,教授,主要研究方向为人工智能及机器学习等。 Email: ygw_ustb@163.com
近年来,游泳池中溺水事故[1]频发,溺水事故与游泳场所[2]的环境[3]有关,尤其在光线不足和人满为患的深水复杂环境中,易发生溺水。游泳池多使用摄像机进行手动监控,但耗费人力,容易漏检,而且人类情绪和疲劳等因素影响监视效果。在少数无人监视中,常见算法是传统的背景减除法[45],它是一种运动物体检测算法,其思想是建立背景模型,使用背景参数模型对背景图像的像素值进行近似,并将当前帧与背景图像区分开,比较运动区域的检测,差异较大的像素区域作为运动区域,较小差异的像素区域作为背景区域,并使用当前帧和背景模型进行减法运算,获得前景目标。但背景建模通常受场景中许多动态变化因素的约束,例如水面的闪烁,照明的突然变化等,建模的质量直接影响后续目标提取和目标跟踪的工作,因此背景减除法在复杂环境下存在溺水检测准确性低的问题。随着计算机视觉技术的飞速发展,目标检测技术取得了长足的进步。在目标检测与识别的相关领域,如AlexNet[6],VGGNet[7],ResNet[8],Faster R-CNN[9]等领域,这些目标检测方法虽然可以对目标进行分类定位,却无法进行图像分割。由于传统背景减除法在复杂场景下存在准确率低、速度慢的问题,且Faster R-CNN等目标检测方法无法进行分割图像,不能更好的检测目标的动作轮廓。针对以上问题,He Kaiming等人\[10\]引入实例分割方法Mask R-CNN进行溺水检测,而且为了确保网络能学习到动态特征,严格按照视频顺序帧的顺序输入进行训练。该网络能容易地扩展到其他任务,如估计人的姿势,即人类关键点检测,但在溺水检测领域并未得到广泛应用,这将为Mask R-CNN引入溺水检测提供可能性。此外,注意力机制可以关注重要特征,并抑制不必要的特征信息。基于此,本文在Mask R-CNN中添加了空间注意模块,以提高分割和检测的准确性。该研究可减少游泳池中溺水事故的发生。
1深度注意力分割模型
深度注意力分割模型是由backbone (ResNet+FPN)、RPN (region proposal network)、ROI Align (region of interest align)、class、box和SAG-mask (spatial attention-guided mask)六部分組合而成,深度注意力分割网络结构如图1所示。
1.1Mask R-CNN
Mask R-CNN(mask region-based convolutional neural networks)是一种实例分割网络,它基于Faster R-CNN,并在模型中添加了Mask分支。另外,使用ROI Pooling代替ROI Align,提高了准确性。它是一个多任务网络,可以同时完成检测和分割任务。
卷积backbone是由ResNet和特征金字塔网络[11](feature pyramid network,FPN)组成。ResNet使用跨层连接来简化训练,残差块(residual block)有两种连接方式,采用BatchNorm[12]标准化处理,网络性能不会随网络过深下降,ResNet残差块结构如图2所示。
FPN来整合不同层次的特征信息,低层的位置信息较好,高层的语义信息较好,但位置信息较弱。FPN结构可以融合不同层特征信息,获得更好的特征信息。P2~P6是ResNet+FPN结构产生的5个feature map,ResNet+FPN结构图如图3所示。
RPN的作用是获取感兴趣的区域ROI。将特征P2~P6输入RPN网络,使用滑动窗口生成k个anchors。经过训练,得到2k分和4k坐标,最后筛选得到网络感兴趣区域ROI(region of interest)。
ROI Align(region of interest align)是解决Faster R-CNN的ROI Pooling中信息丢失问题。在ROI Pooling中,为了获得固定大小的feature map,改变部分十进制坐标,导致了特征信息的丢失,但在ROI Align方法中,采用双线性插值方法解决了该问题,保证了特征信息的完整性。
Class模块、Box模块和Mask模块分别用于分类、回归和分割任务,模型中三个部分同时进行训练,输入为尺寸大小相同特征图。分支Mask利用反卷积进行分辨率的提升,同时减少通道的个数,最后输出特征图大小为14×14×80。
1.2空间注意力引导模块(spatial attention-guided mask,SAG-Mask)
注意力方法广泛应用于目标检测,它可以专注于重要的特征信息,降低其他信息的关注度,甚至会过滤掉无关信息,能解决信息过载问题。其中,空间注意力方法[1314]关注的是信息区域的位置;通道注意力方法[1516]强调的是特征通道关注哪里。受空间注意机制[17]的启发,将空间注意力模块引入Mask R-CNN网络,提出了深度注意力分割网络SAG-Mask R-CNN。模块SAG-Mask结构如图4所示。
2实验及结果分析
2.1实验数据集制作
本实验没有开放式游泳池场景数据集,实验中的训练数据集和测试样本是在多个游泳池中制作。实验中,使用罗技科技有限公司的可移动摄像机,在4个不同的室内游泳池中,共拍摄200多分钟的游泳池视频。每18帧读取一幅图片,得到2 000多幅图片,筛选保留代表性图片组成实验数据集[20]。数据集部分筛选图如图5所示。
数据集四种状态样本数如表1所示。利用图片标记工具Labelme标记图片,生成對应.json文件。标记过程中,要对游泳池内所有人进行标记,为了生成一个良好的数据集,轮廓线使用要精确。游泳池内人的状态分为四类:直立、游泳、站立和溺水,其中,溺水状态是由人工模拟。最后将数据集转换成COCO数据集格式,便于训练。四种状态部分标记图如图6所示。
实验中,使用硬件NVIDIA和开发语言Python进行编程。为得到最佳模型,使用单个图形处理器(graphic processing unit,GPU)、控制学习速率、训练时间和批次大小对模型进行训练。模型使用Facebook研究团队发布的Pythorch深度学习框架进行训练,并将Mask R-CNN和SAG-Mask R-CNN模型的训练损失进行对比,模型训练损失对比如图7所示。由图7可以看出,相比于模型Mask R-CNN,SAG-Mask R-CNN的收敛速度更快,变化更加平缓,最终收敛的值更小,说明模型SAG-Mask R-CNN的性能比Mask R-CNN更好。
2.4模型方法比较
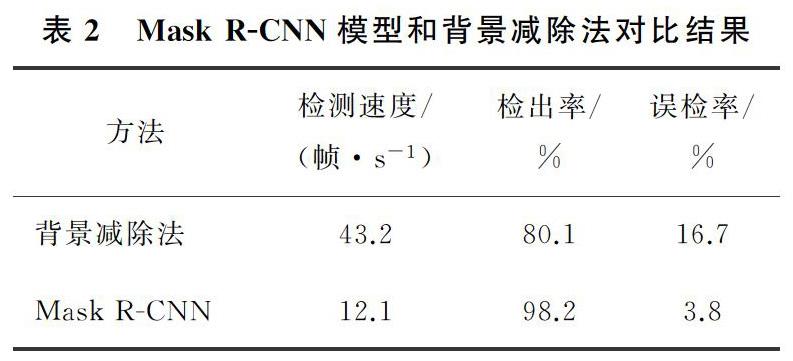
背景减除法建模方式多样,本实验采用高斯混合模型进行建模,并与Mask R-CNN模型在检测速度、检出率、误检率方面进行比较,Mask R-CNN模型和背景减除法对比结果如表2所示。由表2可以看出,Mask R-CNN模型的检测速度与准确率均领先于背景减除法。
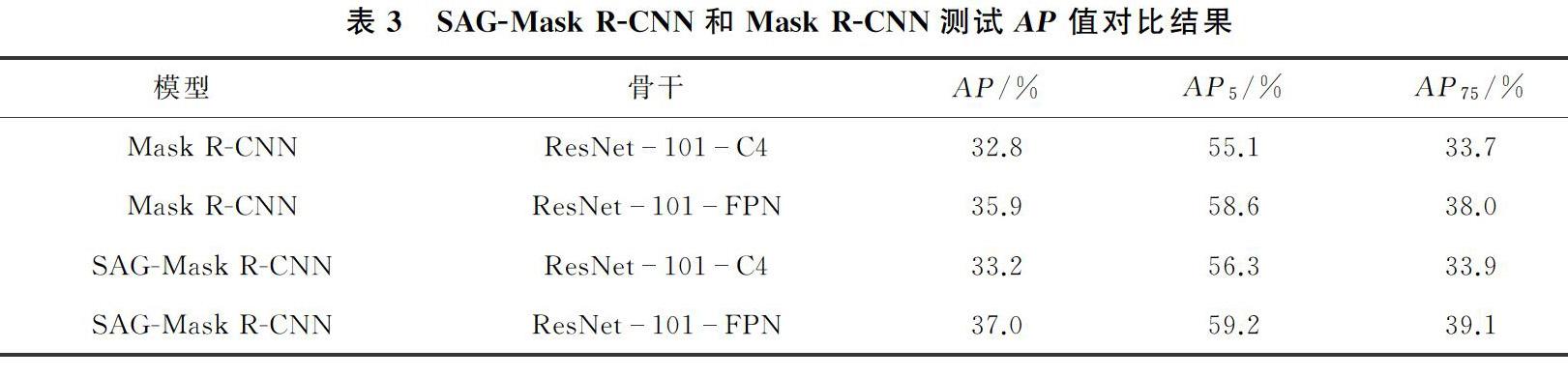
在相同训练数据集上,使用不同的backbone来训练模型SAG-Mask R-CNN和Mask R-CNN,然后在相同的测试数据集上测试两个模型的AP值,SAG-Mask R-CNN和Mask R-CNN测试AP值对比结果如表3所示。由表3可以看出,SAG-Mask R-CNN的AP值及检测精度较高。
采用ResNet-101骨干训练SAG-Mask R-CNN和Mask R-CNN两个模型,并比较两个模型在不同迭代轮数下测试的mAP值。Mask R-CNN和SAG-Mask R-CNN测试mAP值结果如表4所示。由表4可以看出,迭代次数越多,模型的映射值越高,性能越好。在相同迭代次数下,SAG-Mask R-CNN具有更高的性能。
为更好的比较SAG-Mask R-CNN和Mask R-CNN模型的分割效果,在四个游泳池内分别使用两种模型进行测试,SAG-Mask R-CNN的测试结果如图8所示,Mask R-CNN模型测试结果如图9所示。通过对比两个模型在四个游泳池的测试结果可以看出,图8的分割效果明显比图9更加饱满,分割细节更突出,图9中存在漏检、检测置信度较低的情况。通过上述比较可知,深度注意力分割模型SAG-Mask R-CNN与Mask R-CNN相比,在溺水检测的准确度和实例分割精度上都具有显著提高。
3结束语
本文将实例分割模型Mask-R-CNN应用于溺水检测,通过实验对比,与前景目标检测方法相比,该模型检测更快、更准确,并能有效检测人类动作,这是传统的检测方法所无法做到的。此外,为了提高分割检测精度,在模型中引入空间注意机制,提出了SAG-Mask R-CNN模型,可有效地抑制无用特征信息。通过实验对比可知,SAG-Mask R-CNN模型比Mask R-CNN模型检测更快、更准确。训练中,由于严格按照视频顺序帧输入训练,可有效的学习溺水动态特征,提升了模型性能,与直接进行单个图片训练的方法相比,模型特征提取效果显著。而且与现有的方法相比,SAG-Mask R-CNN模型在分割和检测方面具有更好的性能。该研究在实际溺水检测领域具有广阔的应用前景,对减少溺水事件具有积极意义。本研究发现,溺水检测的时空信息十分重要,希望未来探索更多的时空信息,以便更准确地进行溺水检测。
参考文献:
[1]Wintemute G J, Cook P J, Wright M A. Risk factors among handgun retailers for frequent and disproportionate sales of guns used in violent and firearm related crimes[J]. Injury Prevention, 2006, 11(6):357-363.
[2]Lin C Y, Yen W C, Hsieh H M, et al. Diatomological investigation in sphenoid sinus fluid and lung tissue from cases of suspected drowning[J]. Forensic Science International, 2014, 244: 111-115.
[3]Brenner R A, Saluja G, Smith G S, et al. Swimming lessons, swimming ability, and the risk of drowning[J]. Injury Control and Safety Promotion, 2003, 10(4): 211-215.
[4]Tang Q, Zhou Y, Lei J. Fast median filters based on histogram and multilevel staged search[C]∥International Conference on Image & Graphics. IEEE, 2007: 100-105.
[5]Sullivan H W, Rutten L J F, Hesse B W, et al. Lay representations of cancer prevention and early detection: associations with prevention behaviors[J]. Preventing Chronic Disease, 2010, 7(1): A14.
[6]Gulcehre C, Cho K, Pascanu R, et al. Learned-norm pooling for deep feedforward and recurrent neural networks[J]. Springer Berlin Heidelberg, 2013, 8724: 530-546.
[7]Pfister T, Simonyan K, Charles J, et al. Deep convolutional neural networks for efficient pose estimation in gesture videos[C]∥Asian Conference on Computer Vision. Springer, Cham, 2014: 538-522.
[8]He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]∥IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016.
[9]Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[10]He K, Gkioxari G, Piotr Dollár, et al. Mask R-CNN[C]∥IEEE Transactions on Pattern Analysis and Machine Intelligence. IEEE Computer Society, 2020: 386-397.
[11]Wong F, Hu H. Adaptive learning feature pyramid for object detection[J]. IET Computer Vision, 2019, 13(8): 742-748.
[12]Huang K Y, Chang W L. A neural network method for prediction of 2006 World Cup Football Game[C]∥International Joint Conference on Neural Networks. IEEE, 2010.
[13]Yang C T, Liu J C, Huang K L, et al. A method for managing green power of a virtual machine cluster in cloud[J]. Future Generation Computer Systems, 2014, 37: 26-36.
[14]Chen L, Zhang H, Xiao J, et al. SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2016.
[15]Hu J, Shen L, Sun G, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023.
[16]Xiang L X, He D, Dong W R, et al. Deep sequencing-based transcriptome profiling analysis of bacteria-challenged Lateolabrax japonicus reveals insight into the immune-relevant genes in marine fish[J]. Bmc Genomics, 2010, 11(1): 472-493.
[17]Neumann M, Vu N T. Cross-lingual and multilingual speech emotion recognition on english and french[C]∥International Conference on Acoustics. 2018.
[18]Lambers J V. An Explicit, Stable, High-order spectral method for the wave equation based on block gaussian quadrature[J]. IAENG International Journal of Applied Mathematics, 2008, 38(4): 333-348.
[19]Al-Furaiji O J M, Tuan N A, Yurevich T V. A new fast efficient non-maximum suppression algorithm based on image segmentation[J]. International Journal of Advanced Computer Science and Applications, 2020, 19(2): 1155-1163.
[20]Hamel B, Audran M, Costa P, et al. Reversed-phase high-performance liquid chromatographic determination of enoxacin and 4-oxo-enoxacin in human plasma and prostatic tissue. Application to a pharmacokinetic study[J]. Journal of Chromatography A, 1998, 812(1-2): 369-379.
Abstract: Aiming at the problems of traditional foreground detection methods such as low accuracy, slow speed and ineffective detection of target motion contours in complex scenes, this paper mainly studies the improved Mask R-CNN swimming pool drowning detection. The instance segmentation network Mask R-CNN is used for detection and segmentation to achieve drowning detection. The spatial attention guidance module is introduced in the Mask branch, and the deep attention segmentation model SAG-Mask R-CNN is designed, and when training the Mask R-CNN network, the sequential input of video sequential frames is strictly followed for training to ensure that the Mask R-CNN network can learn the dynamic characteristics of drowning. At the same time, the foreground detection method and the model Mask R-CNN are used for comparative experiments. Experimental results show that, compared with Mask R-CNN, the deep attention segmentation model SAG-Mask R-CNN, while maintaining high detection speed, increases the segmentation accuracy by 15% to 20%, and improves the accuracy of drowning detection. The research is of great significance to reducing the occurrence of drowning accidents in swimming pools.
Key words: foreground detection; attention mechanism; deep neural network; image segmentation; drowning detection
