融合发音动作特征和声学特征的病理语音检测
2021-03-23薛珮芸
王 颇,白 静,薛珮芸
(太原理工大学 信息与计算机学院,山西 晋中 030600)
0 引 言
听障患者普遍存在构音障碍问题,由于听功能损失,患者缺乏听觉对发声的反馈作用,导致其发音部位不准确,发音动作不协调,进而出现异常发音[1]。对于听障患者病理语音的检测,语音信号处理技术提供了一种非入侵性的方法,通过提取语音的特征参数并进行模式识别,可以高效地对正常语音和病理语音进行分类,能够辅助医生对病理语音患者进行诊断和治疗[2]。
目前,根据病理语音特征实现计算机自动诊断仍然是医学工作者和语音研究工作者努力的方向。Fang Shih-Hau等[3]采用美国的MEEI数据库,结合梅尔倒谱系数(Mel frequency cepstrum coefficient,MFCC)和深度神经网络进行病理语音检测。由于语音信号具有非平稳性和突变性,李海峰等[4]提出一种基于S变换的病理语音特征MSCC,使用荷兰的NSNC病理数据库验证了所提方法的有效性。关于汉语病理语音的研究,庞宇峰等[5]采集临床声带息肉患者和正常人的语音数据,分析基频微扰、振幅微扰等特征差异。许远静等[6]使用自建库,提取熵、Hurst参数、吸引子等非线性特征,结合随机森林算法(random forest,RF)识别不同程度病态嗓音。以上研究表明病理语音检测的特征比较丰富,但是这些特征集中于语音声学特性的研究,忽略了语音产生过程中发音器官的运动特性。
近年来,三维电磁发音仪(electromagnetic articulograph,EMA)[7]在语音研究领的应用增多,Zhang Yan等[8]采集舌、唇、颌部的运动数据,分别以鼻梁和上唇为参考点,计算下唇、舌尖、舌中的相对位置作为发音动作特征(articulatory movement features,AMF),进行短时文本的说话人识别。蔡明琦等[9]指出相比声学特征,语音的发音动作特征描述了发音过程中唇、舌等发音器官的位置变化,它们不受外界噪音和环境的影响,具有更高的鲁棒性。因此本文分析病理语音的发音动作特征,提取发音动作特征以及声学特征进行融合,使用核主成分分析法进行降维,在支持向量机(support vector machine,SVM)、随机森林、多层感知机(multilayer perceptron,MLP)分类模型中,验证发音动作特征和融合特征的有效性。
1 语音特征参数提取
1.1 发音动作特征
文中发音器官的运动数据使用三维电磁发音仪采集,该设备可以捕获高精度的运动信号,并且不损害人体,是采集发音器官微小动作的专用设备。在EMA系统中,每个传感器对应一个通道,数据采集前,对传感器进行预热、校准,然后将传感器黏贴在受试者的唇部(上唇、下唇、左嘴角、右嘴角)、舌部(舌尖、舌中、舌后)、颌部进行数据采集,同时在鼻骨、左耳骨、右耳骨、下齿槽分别黏贴传感器作为参考传感器,用来消除发音过程中头部转动影响。发音动作数据采样频率为250 Hz,语音数据与发音动作数据同步采集,采样频率为16 KHz。EMA记录了每个传感器三维空间(X轴、Y轴、Z轴)坐标,X表示前后方向,Y表示左右方向,Z表示上下方向。发音器官的左右方向的运动幅度较小,因此使用X轴、Z轴的数据进行分析。
研究表明,听障患者发音时舌部运动不到位是影响其发音的重要因素,王晴等[10]研究听障患者的鼻韵母发音时,发现部分发音的舌位偏高或者偏低,与正常人发音的舌部运动存在差异。本文画出正常人和听障患者分别发单元音/a/时,舌尖和舌中在X轴、Z轴上的运动轨迹,如图1和图2所示。
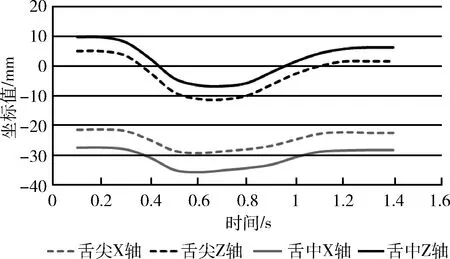
图1 正常人发元音/a/的舌部运动轨迹
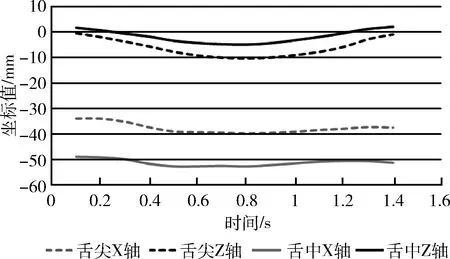
图2 听障患者发元音/a/的舌部运动轨迹
图中可以看出听障患者发音时舌尖、舌中的运动幅度比正常人较小,这和之前的研究相符合。因此提取舌尖、舌中部位的运动位移和速度作为特征,位移特征指相对于初始位置,传感器的最大位移,计算公式如下
sX=max|x(t)-x(0)|
(1)
sZ=max|z(t)-z(0)|
(2)
式中:sX表示X轴最大位移,x(t)表示t时刻传感器的X轴坐标值,x(0)表示初始时刻传感器的X轴坐标值,sZ表示Z轴最大位移,z(t)表示t时刻传感器的Z轴坐标,z(0)表示初始时刻传感器的Z轴坐标。
速度指发音器官在每一时刻位移变化量,通过式(3)、式(4)进行计算,将最大速度、最小速度、平均速度和速度的方差作为特征
(3)
(4)
式中:vX表示X轴瞬时速度,x(t+Δt)表示t+Δt时刻的X轴坐标值,x(t)表示t时刻的X轴坐标值。vZ表示Z轴瞬时速度,z(t+Δt)表示t+Δt时刻的Z轴坐标值,z(t)表示t时刻的Z轴坐标值。
1.2 声学特征
梅尔倒谱系数是语音识别领域常用的特征,它基于人耳的听觉特性,在梅尔刻度下,人耳对声音频率的感知度成线性关系,它与频率的关系可表示为
Mel(f)=2595lg(1+f/700)
(5)
式中:f表示实际的语音频率,单位是Hz。
如果把声道看作理想的谐振腔体,舌头的运动会改变声道的形状,进而影响谐振频率,即共振峰。在语音学中,第一共振峰与舌位高低呈负相关关系,第二共振峰与舌位前后呈正相关关系。由听障患者发音动作特征可知患者发音时舌部运动不到位,这必然会影响语音的共振峰,因此本文提取共振峰特征进行病理语音检测。
基频反映了发音者音调的大小和音质的好坏,基频的大小与声带的长度、厚度、张力有关,并且受到声门上下之间的气压差效应的影响,是病理语音研究中的重要特征。听障患者由于发音部位不准确、发音动作不协调,基频特征与正常人存在差异。
1.3 特征融合
发音动作特征描述发音器官的运动特性,声学特征描述语音的频谱特性,两种类型的特征表达的物理意义不同,将他们进行归一化处理构成融合特征,即SVMFP特征。融合特征可以表示为
(6)

由于上述的融合特征可能包含冗余信息,本文使用核主成分分析法(kernel principal component analysis,KPCA)对其进行降维,降维后的特征表示为KSVMFP。KPCA是在PCA的基础上提出,相比PCA,KPCA在处理非线性数据方面效果更好。它的基本原理是通过非线性函数将原始数据映射到高维空间,从而对高维空间的数据进行相应的线性分类。本文采用径向基高斯核方法进行降维,核函数公式如下
(7)
σ取常数,在降维过程中需要对σ进行调节。
在降维过程中,将训练样本的n维特征表示成n个列向量的特征矩阵α,通过非线性映射Φ将其映射到高维空间中
Φ(α)=[Φ(α1),Φ(α2),…,Φ(αn)]
(8)
在高维空间进行降维变换
X=WTΦ(α)
(9)
求解Φ(α)之后得出非线性降维后的特征矩阵X。
2 多层感知机
听障患者病理语音检测的MLP拓扑如图3所示。MLP的层次结构为5层,隐含层为3层,每层包括64个神经元。
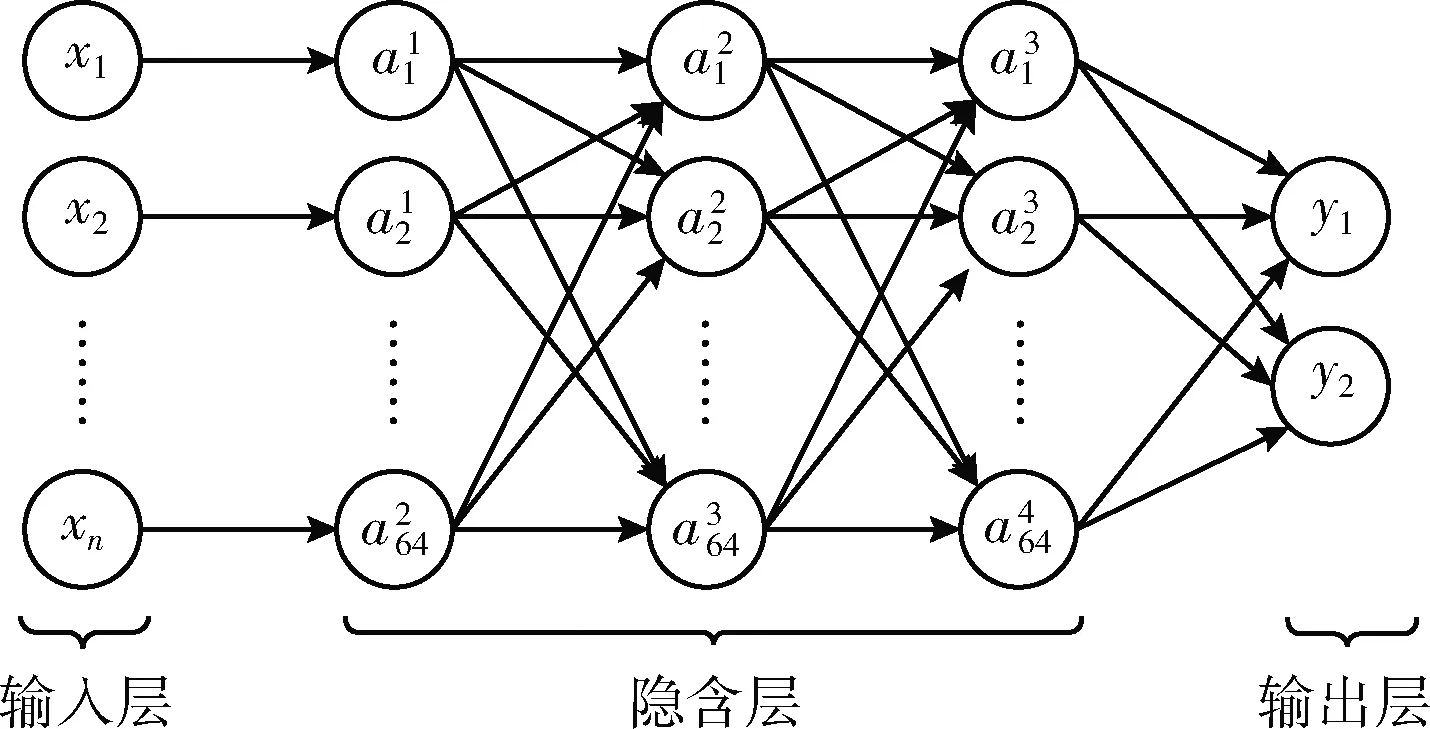
图3 MLP拓扑
隐含层中神经元的输入和输出如下所示
al=σ(zl)
(10)
zl=Wlal-1+bl
(11)
式中:al表示第l层神经元输出,σ表示激活函数,zl表示第l层神经元的输入,W表示第l-1层神经元与第l层神经元之间权值组成的向量,bl表示第l层偏置组成的向量。
本文使用的激活函数为Leaky ReLU,如式(12)所示

(12)
相比ReLU[11],Leaky ReLU函数对负值输入有很小的坡度,可以减少静默神经元的出现,允许神经元缓慢学习;在正半区和ReLU具有相同的特性,当输入信号超过阈值时,神经元进入激活状态,可以选择性响应部分输入信号,屏蔽不相关信号,提取出重要的稀疏特征。
通常在模型的训练过程中,使用交叉熵形式的代价函数描述模型的分类精度,形式如下
(13)
式中:y为预测概率值,y′为真实概率值。H(y)越小,模型的输出值与真实值差距越小,分类越准确。通过训练,H(y)逐渐减小,最终达到全局最优或局部最优。在神经网络的参数训练方法中,随机梯度下降(stochastic gradient descent,SGD)是最常见的优化方法,但是它对所有的参数更新使用同样的学习率,因此选择合适的学习率比较困难,设置不同的学习率,可能产生差异较大的结果。本文使用Adagrad算法[12]自适应地训练参数。
3 病理语音检测流程图
病理语音检测流程如图4所示,对病理语音数据库中的数据预处理后,提取位移、速度两种发音动作特征以及MFCC、基频、共振峰3种声学特征,然后将提取的特征归一化,使用KPCA降维,结合MLP完成病理语音和正常语音的分类。
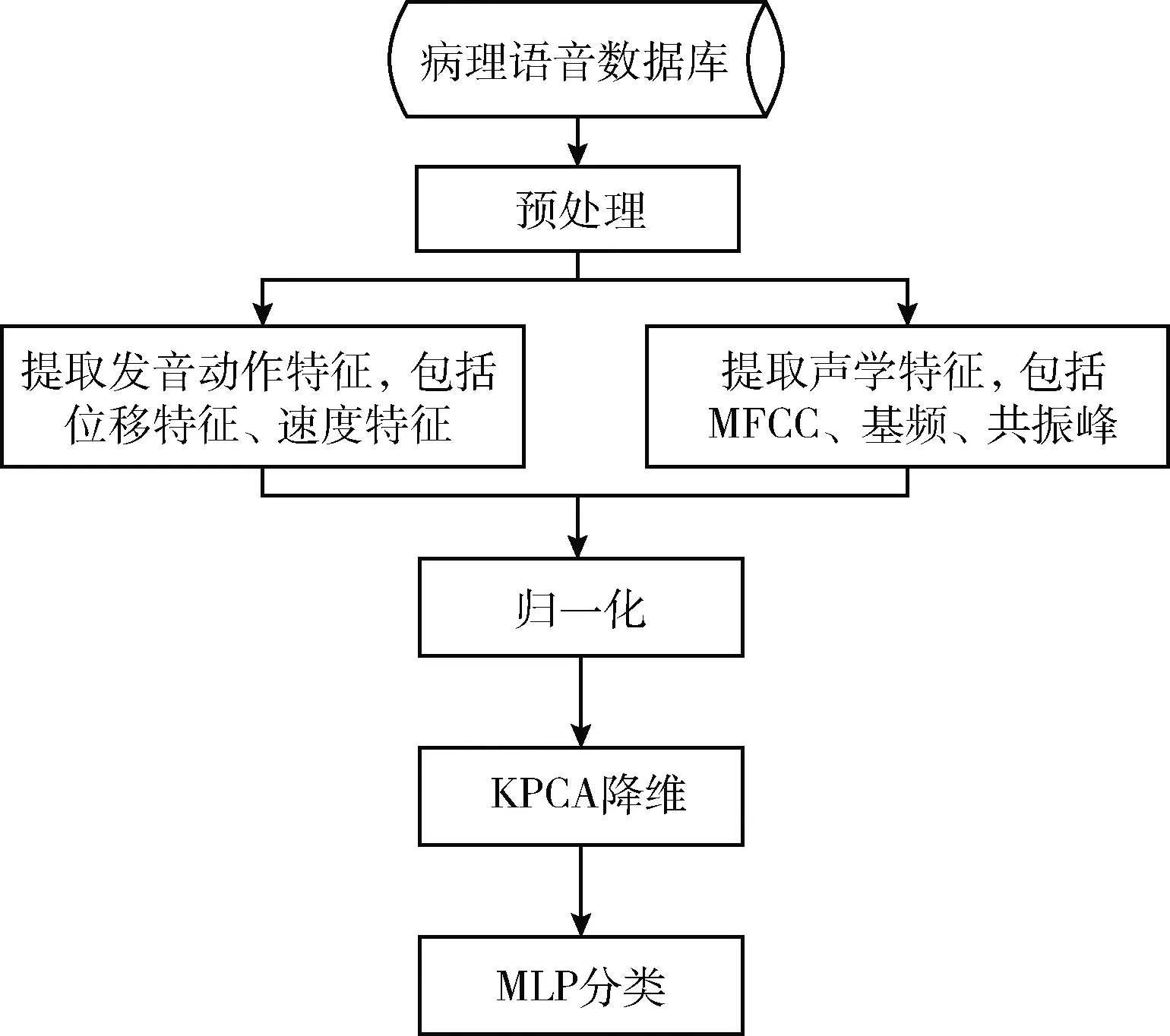
图4 病理语音检测流程
4 实 验
4.1 实验数据
实验数据库为实验室自建库,其中包括听障学生和正常学生的数据,听障学生在太原市聋哑学校随机选取,男、女各5名,共10名,除听力受损外,全身无其它畸变,能自主发音。正常学生为在校大学生,男、女各5名,共10名,普通话水平均为二级甲等及以上,测试期间均无呼吸道感染。数据库语料为普通话水平测试用表的常规发音,本文对采集的数据进行筛选,结果见表1。

表1 病理语音检测语料
4.2 实验结果及分析
当测试语料为汉语字母和汉语单音节时,将发音动作特征和不同声学特征输入不同分类模型,测试不同特征和分类模型组合的分类性能。分类模型的参数设置如下:SVM的核函数为RBF核,使用鸟群算法[13]优化参数;MLP激活函数为Leaky ReLU,使用Adagrad优化网络参数;RF中子树的数量为100。实验中字母的样本总数为520,单音节的样本总数为780。使用五折交叉验证得出最后的实验结果,采用灵敏度(sensitivity)、特异度(specificity)、识别率(accuracy)3个指标对分类结果进行评价。
4.2.1 单一特征的实验结果
当测试语料为汉语字母和汉语单音节时,单一特征的检测效果分别见表2和表3。
由表2可知,①在MLP中,MFCC的特异度比发音动作特征低,灵敏度和识别率比其它特征高;在SVM和RF中,MFCC的灵敏度、特异度、识别率比其它特征高;从整体上看,MFCC的检测效果最佳。②在SVM中,发音动作特征的灵敏度、特异度、识别率比基频和共振峰高;在RF中,发音动作特征的灵敏度比共振峰低,特异度比基频低,识别率比基频和共振峰高;在MLP中,发音动作特征的灵敏度比共振峰低,特异度和识别率比基频和共振峰高;从整体上看,发音动作特征的检测效果优于基频和共振峰。③在SVM中,共振峰的灵敏度、特异度、识别率比基频高,共振峰优于基频;在RF中,基频的灵敏度比共振峰低,特异度、识别率比共振峰高,基频优于共振峰;在MLP中,共振峰的特异度比基频低,灵敏度、识别率比基频高,共振峰优于基频。
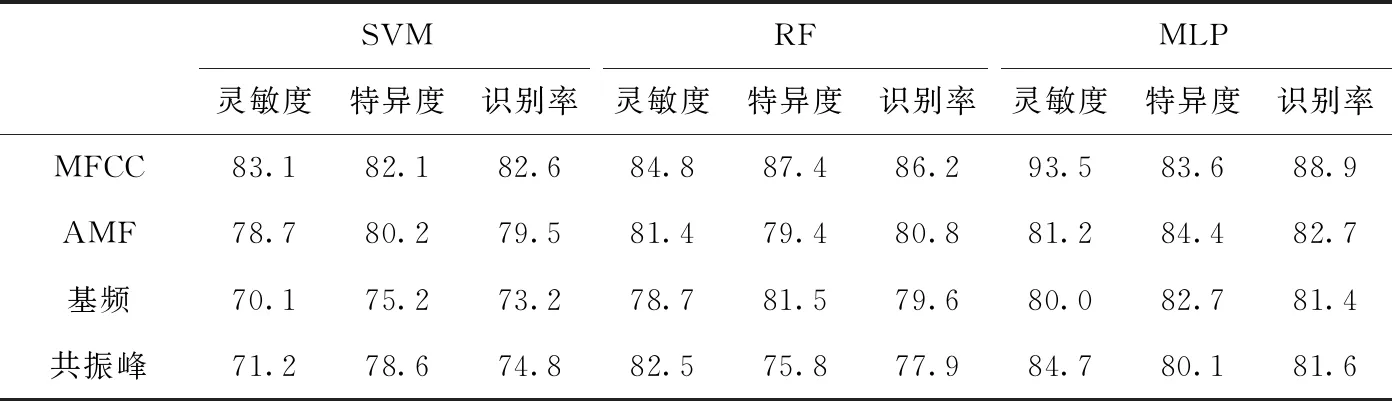
表2 汉语字母的单一特征检测效果对比/%
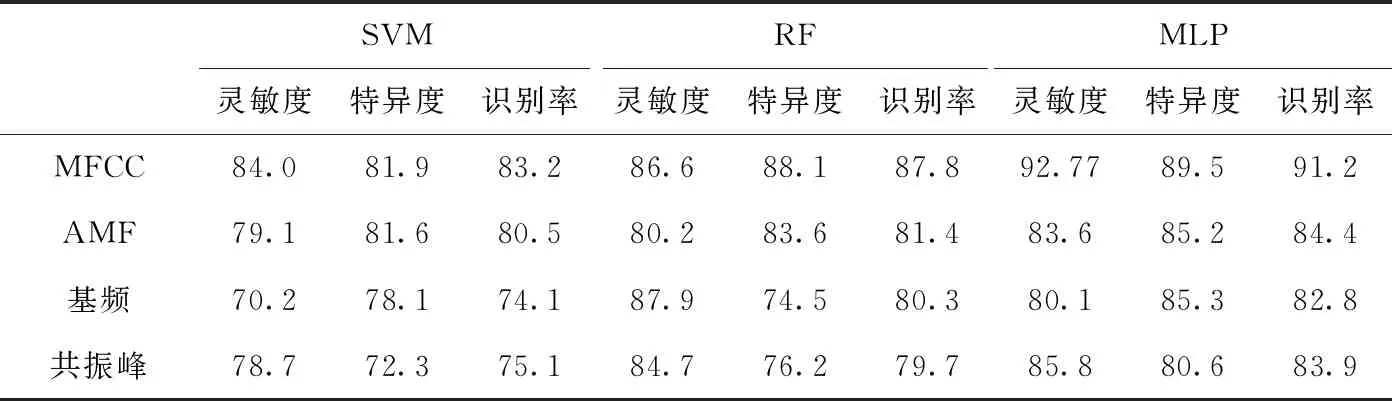
表3 汉语单音节的单一特征检测效果对比/%
由表3可知,①在RF中,MFCC的灵敏度比基频低,MFCC的特异度和识别率比其它特征高;在SVM和MLP中,MFCC的灵敏度、特异度、识别率比其它特征高;从整体上看,MFCC的检测效果最佳。②在SVM中,发音动作特征的灵敏度、特异度、识别率比基频和共振峰高;在RF中,发音动作特征的灵敏度比基频低,特异度、识别率比基频和共振峰高;在MLP中,发音动作特征的特异度比基频低,灵敏度和识别率比基频和共振峰高;从整体上看,发音动作特征的检测效果优于基频和共振峰。③在SVM中,共振峰的特异度比基频低,灵敏度、识别率比基频高,共振峰优于基频;在RF中,基频的特异度比共振峰低,灵敏度、识别率比共振峰高,基频优于共振峰;在MLP中,共振峰的特异度比基频低,灵敏度、识别率比基频高,共振峰优于基频。
表2和表3的结果表明,相比其它单一特征,MFCC在病理语音检测中效果最佳,发音动作特征比MFCC的检测效果差,但是比基频和共振峰的检测效果好,说明发音动作特征和声学特征同样有效。声学特征表示语音不同方面的声学特性,而发音动作特征能够有效地表示发音器官在发音过程中的运动信息,两类特征表达的物理意义不同,互为补充特征。此外,基频和共振峰的检测效果比较结果不固定,在RF中,基频的检测效果优于共振峰,在SVM和MLP中,共振峰的检测效果优于基频,说明单一特征对语音的表达不充分、鲁棒性较差。
4.2.2 融合特征的实验结果
为弥补单一特征表示语音特性的不足,本文将发音动作特征和声学特征归一化融合,并使用KPCA进行降维,特征归一化和KPCA降维的检测效果分别见表4和表5。

表4 汉语字母的融合特征检测效果/%

表5 汉语单音节的融合特征检测效果/%
对比表2和表4、表3和表5的结果,可以得出无论测试语料是汉语字母还是汉语单音节,在SVM、RF和MLP中,融合特征的灵敏度、特异度、识别率比单一特征高,说明融合特征的检测效果优于单一特征,可以更充分地表示语音的特性。对比特征归一化和KPCA降维的检测效果得出,特征KPCA降维后检测效果更佳,说明特征的归一化融合存在信息冗余,经过非线性降维能够消除冗余达到最佳的检测效果。
此外,在表2、表3、表4、表5中,不同特征作为输入时,对比SVM、RF、MLP的检测结果,可以得出MLP的检测效果最佳,说明MLP将特征进行抽象的转换,具有更强的拟合能力,提高了病理语音的检测效果。文中汉语字母的最佳识别率达到94.5%,汉语单音节的最佳识别率达到95.2%。
5 结束语
病理语音自动检测技术的研究日益重要,它可以有效地减少病理语音诊断过程中人力物力的投入。目前,虽然声学特征的研究成果丰富,但仍不能满足临床要求,并且单一特征对病理语音和正常语音的差异表示不足,因此,本文提出一种融合发音动作特征和声学特征的方法用于听障患者病理语音的检测。实验结果表明发音动作特征和声学特征同样有效,融合特征弥补了单一特征的不足,使用KPCA降维消除了特征之间的冗余信息,提高了检测效果,本文的方法为医学临床的自动诊断技术提供了参考。
