基于PB-DBSCAN的GPS数据去噪
2021-03-23刘泽玲王利琴董永峰
汪 鹏,刘泽玲,王利琴,3+,董永峰
(1.河北工业大学 人工智能与数据科学学院,天津 300401;2.河北工业大学 河北省大数据计算重点实验室,天津 300401;3.河北工业大学 河北省数据驱动工业智能工程研究中心,天津 300401)
0 引 言
在公交车载GPS设备定位过程中,GPS数据的误差来源分为GPS定位系统的内部原因和外部原因,内部原因包括信号传播途径问题、GPS卫星相关问题和用户接受设备问题。外部原因主要包括公交车自身行驶特性、城市道路路况和诸多随机因素(天气状况、网络延迟、行驶速度等)。这些误差是GPS数据产生大量噪声点的主要原因,降低了由GPS数据生成公交行驶路线的准确度和可靠性,为减小噪声点对生成路线的影响,提高生成路线的准确度,需要剔除异常的GPS数据。
在数据点噪声处理领域,相关学者在基于聚类算法过滤噪声点等方向提出大量的算法。Yang L等提出了基于自然近邻的ENaN算法[1],根据样本点近邻,寻找各数据点的反向最近邻。ENaN根据样本点是否具有反向最近邻来判断该点是否为噪声点,虽然通过这种方法实现了聚类效果,但对于噪声量较大的数据集聚类效果往往较差甚至无法完成聚类过程;Hao SX等提出了一种基于噪声的应用空间密度聚类(DBSCAN)和支持向量数据描述(SVDD)的噪声数据检测方法[2];张靖等提出一种基于空间和时间密度的抗噪声聚合算法(DBS&TCAN)[3];李强等通过过滤低密度区域的方法优化了DBSCAN算法[4],在处理海量GPS轨迹数据时有效得到了稠密样本点;Bryant A等提出的RNN-DBSCAN算法通过K最近邻点的选择实现了单个参数聚类[5],从而降低了聚类的复杂度,并且提升了簇分布不均匀的数据集的聚类效果;黄子赫等提出了BCS-DBSCAN聚类算法,该算法可以对轨迹数据切分及并行化聚类且能够有效去除噪声点提取最大密度簇心[6]。然而上诉方法均不适用于数据量较大的去噪处理。虽然DBSCAN在聚类速度上具有优势并且对于有冗余点的数据集也可以很好的聚类,但是,当数据量庞大时,DBSCAN算法时间复杂度较高。
Eps和MinPts是DBSCAN算法中用来描述数据点分布密度的两个全局参数,直接影响到聚类效果,合理的取值会显著提高聚类效果,因此聚类参数的自适应调整成为了众多学者研究的方向。Jian Hou等提出了一种基于DSets(优势集)和DBSCAN的无参数算法——Dsets-DBSCAN[7];Ankush Sharma等提出了KNN-DBSCAN无参数密度聚类[8],将K近邻学习与DBSCAN一起使用以实现无参数聚类技术;蒋华等针对CURE算法聚类过程中对噪音点敏感、聚类效率欠佳问题,提出了一种基于MeanShift核函数平移模型DBSCAN算法改进的CURE算法[9]。其中基于路径最短原则的密度自适应参数的DBSCAN算法提高初步聚类精度和可靠性。但上述算法只适用于数据集单一、参数相同的场景,而公交车GPS数据集包含不同线路的所有数据,不同线路具有不同的数据密度,因此需使用不同的参数。
本文对Eps和MinPts参数进行动态选择,有效解决了在不同线路公交车GPS数据聚类过程中,因固定输入参数在不同线路的非普适性而导致的聚类结果偏差较大、聚类效果差的问题。同时为提高DBSCAN算法执行速度,本文提出一种基于像素格的PB-DBSCAN算法,该算法将聚类过程中判断数据点与其它数据点的关系改为判断当前像素格与相邻像素格之间的关系,相较于传统DBSCAN算法降低了时间复杂度,尤其在数据量较大时,算法效率有极大提升。
1 PB-DBSCAN算法
DBSCAN是Ester等提出的第一个基于密度的聚类算法。该算法以数据集在空间分布上的稠密程度为依据进行聚类,将密度相连的点的最大集合定义为簇,DBSCAN对数据集的大小没有限制且无需预先设定簇的数量,适合于对未知内容的数据集进行聚类。
Eps和MinPts是DBSCAN算法的两个全局参数,其中,Eps代表聚类半径,表示目标点周围邻域数据点数的搜索半径,MinPts代表聚类密度,用于判断搜索区域是否满足簇要求的最小点数。任选一个未被检查过的点,检查其Eps邻域,若包含的点的数目不小于MinPts,则该点与其邻域的点形成一个簇,标记该点为核心点,然后以相同的方法处理该簇内所有未被检查的点,从而对簇进行扩展;若包含的点的数目小于MinPts,但该点本身在某一个簇内,则该点标记为边缘点,否则该点被标记为噪声点。
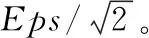
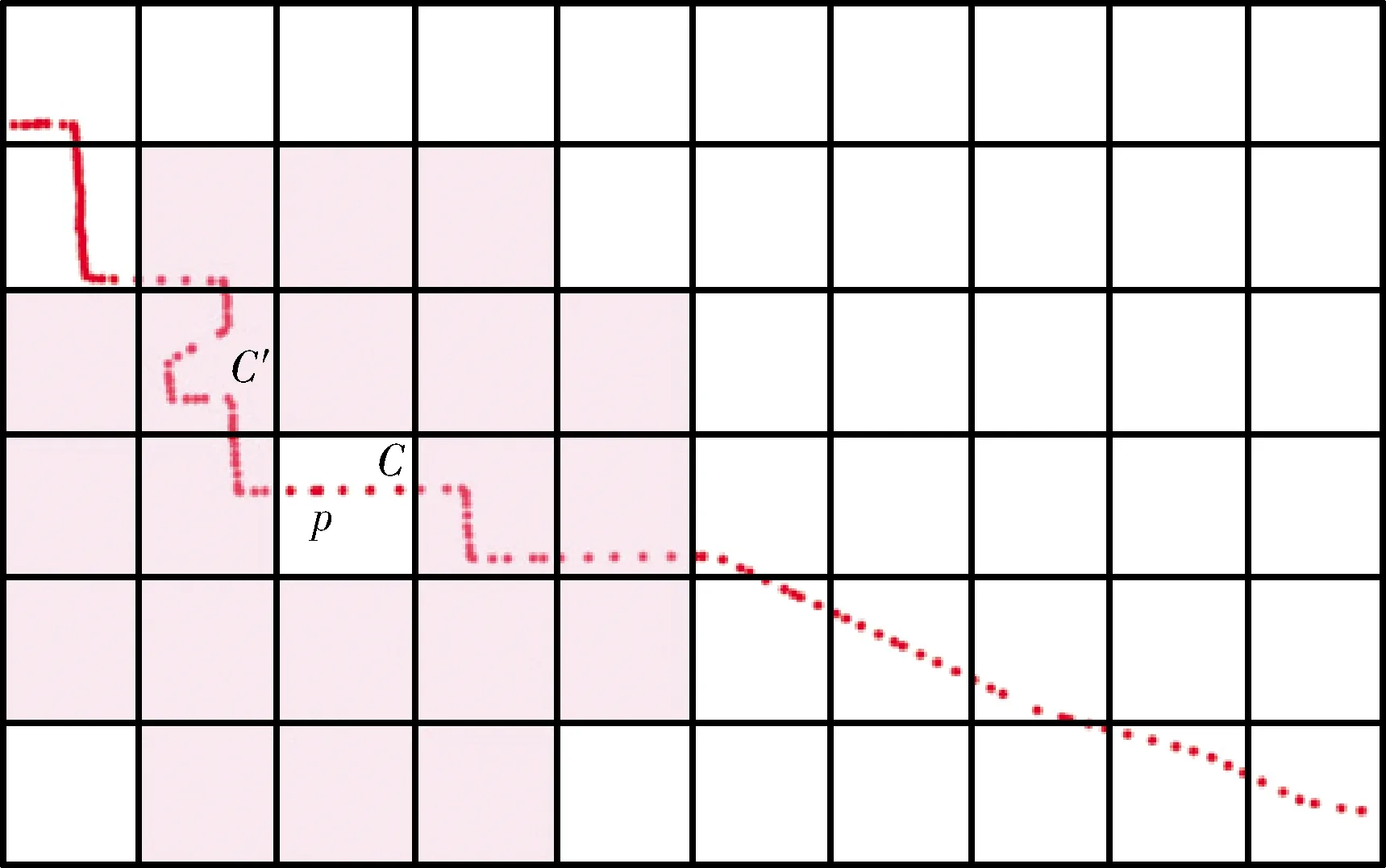
图1 像素格
1.1 构建像素格
首先遍历数据集中的所有点,找到这些点的横纵坐标的最大值和最小值,从而确定像素格空间X轴和Y轴值的范围,然后再将X轴、Y轴等分,将整个像素格空间划分为m行n列的小像素格
(1)
(2)
将每个GPS数据点根据其横纵坐标数值划分到相应的像素格单元中,如图1所示。
1.2 确定核心点
遍历所有的非空像素格,判断当前像素格内的点数是否大于MinPts,如果是,则将该像素格内的所有点标记为核心点,否则遍历该像素格内的所有点,逐个判断其是否为核心点。假设一个点p,属于单元格C,则要确定点p是否是核心点,需要检查p点所在像素格的相邻像素格内的点。将p点所在像素格的相邻像素格表示为C′,NEps(C) 定义为像素格单元C及其相邻的像素格单元C′的集合,如果C与C′之间存在两点之间的距离小于Eps,那么C′为C的一个相邻像素格,如式(3)所示,dist(C,C′) 表示C和C′内任意数据点之间的最短距离
(3)
NEps(C)={C,C′|dist(C,C′)≤Eps}
(4)
如图1阴影部分所示,NEps(C) 由和C相邻的20个像素格组成。遍历这些像素格中的每个点,计算其与点p之间的距离,直到所有的点都已遍历,或点p的Eps邻域内点数大于等于MinPts,终止查找。
1.3 合并簇
对于两个不同的像素格,如果分别位于两个像素格的两个点之间的距离小于等于Eps,那么这两个点属于同一个簇,如图2所示,a为相邻的两个像素格,且均含有4个数据点,假设MinPts=3,那么a、b内所有的点均为核心点,如果a、b之间的距离小于Eps,那么a、b内所有的点属于同一个簇。否则,划分为各含有4个点的两个簇。
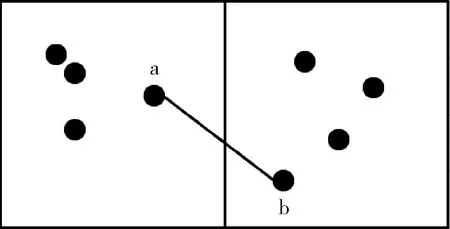
图2 合并簇
1.4 确定边界点和离群噪点
遍历所有非核心点,如果存在NEps(C) 中的核心点,假如最靠近点p的核心点属于簇clusters_1,那么非核心点p可以认定为簇clusters_1的一个边界点。检查完所有非核心点之后,既不是核心点又不是边界点的数据会被标记为噪声点。
通过上面的4个步骤,可以实现GPS轨迹点的快速聚类,并且标记出数据集中的噪声点,通过剔除噪声点来完成GPS数据的去噪处理。
2 动态参数选择
在对不同线路GPS数据进行聚类的过程中,由于公交线路的多样性,在Eps和MinPts的选取中,同一聚类参数无法适应所有的线路。不同线路根据同一聚类参数聚类得到的结果在公交行驶路线的后续起终点获取中,会引起起点获取不准确、起点周围噪声点删除不全等问题,进而影响由GPS数据点生成公交行驶路线的准确度。因此本文提出一种动态参数选择的方法,使PB-DBSCAN算法在对包含多条线路GPS数据集去噪时实现参数的自适应选取。
为实现动态参数选择,引入聚类率ρ及最优聚类率区间 [ρmin,ρmax],聚类率如式(5)所示,反映了聚类后样本的数据量占原始数据量的比例。
定义1 假如聚类后的所有GPS数据点个数为m,样本总数据量为n,那么聚类率ρ为
ρ=m/n
(5)
一般而言,聚类率并不是越大或者越小越好。聚类率过大,则是在聚类参数选取过程中,聚类密度过小或聚类半径过大,从而导致部分噪声点未被剔除,聚类后剩余的点数过多,聚类效果较差。相反,如果聚类率过小,则是在聚类参数选取中,聚类密度过大或聚类半径过小,从而导致部分核心点或边缘点被剔除,聚类后剩余点数过少,聚类效果较差。因此提出最优聚类率区间。
定义2 最优聚类率区间:当聚类率落于该区间内时,大部分噪声点得到剔除,所得簇的数量和每个簇的大小能够满足GPS数据的下一步处理,不会影响后续处理的准确性。
动态参数选择迭代过程的终止条件之一为迭代后计算所得聚类率位于最优聚类区间内,通过对数据集中不同线路GPS数据的探索性实验,得出最优聚类率区间为[0.45,0.55]。
通过对多条线路的探索性实验,得到满足绝大部分线路聚类效果要求时,最大迭代次数N为64。动态参数选择聚类实现过程如图3所示。
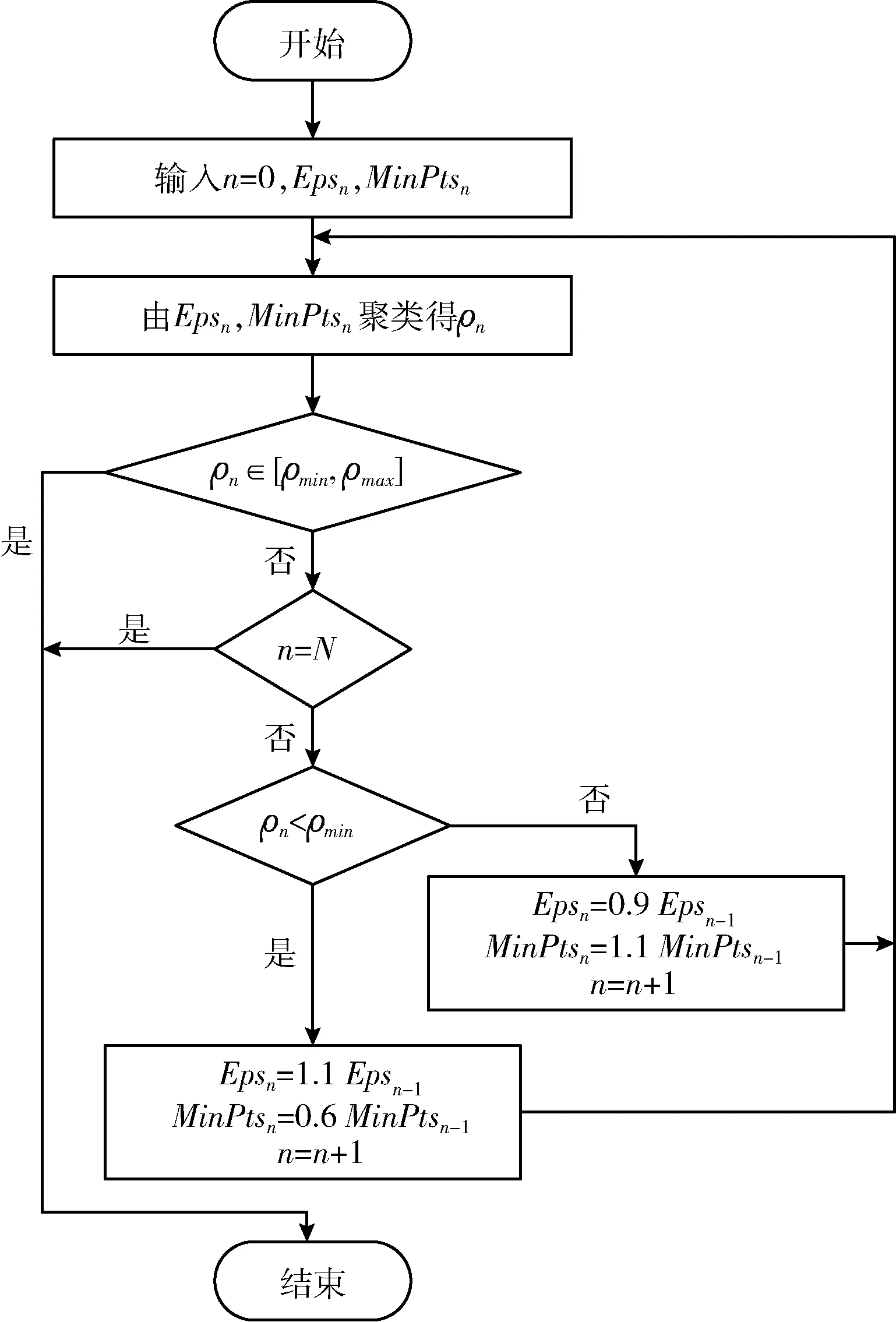
图3 动态参数选择流程
(1)确定初始参数。Eps0和MinPts0。迭代次数n=0。其中Eps0和MinPts0为在分别对各线路进行固定参数的预聚类实验之后,得到的在多条线路下满足聚类率在聚类区间内或临近聚类区间的共同初始输入参数;
(2)计算聚类率。根据式(5)计算聚类率ρ0,判断ρ0是否落在最优聚类率区间 [ρmin,ρmax] 中;
(3)参数动态选择。如果ρ0落在最优聚类率区间 [ρmin,ρmax] 中,聚类结束。否则,若ρ0>ρmax,则调大MinPts至原MinPts的1.1倍,调小Eps至原Eps的0.9倍;若ρ0<ρmin,则调小MinPts至原MinPts的0.9倍,调大Eps至原Eps的1.1倍。在调大或调小的倍数选择中,为减少运算次数,调大倍数应越大越好,调小倍数应越小越好,过大或过小会导致两次迭代结果的聚类率相差太大,甚至错过最优聚类率区间,所以经过大量实验得出最优的调大倍数为1.1倍,调小倍数为0.9倍。
(4)迭代。令n=n+1,循环(1)~(3),直至n的大小等于最大迭代次数N或者聚类率ρ位于最优聚类率区间,完成聚类。
3 实验与结果分析
3.1 实验数据及环境
数据采用河北省某市2018年1月-3月所有线路公交车的GPS数据,其中公交线路有223条,总数据量111 G,共818 251 686条数据。搭建伪分布式Hadoop集群存储GPS数据,集群由一个主节点,4个从节点构成,服务器搭载两个8核处理器,32 G内存,1 TB存储空间。利用HIVE处理HDFS上的数据,HIVE是基于Hadoop静态批处理的数据仓库工具,可以通过类似SQL语句的HQL语句进行数据库的增删改查等操作,易于掌握。HIVE还提供了内置函数和Java API接口,开发人员可以根据这些函数去实现复杂的业务逻辑。这些HIVE的操作底层均是转为机器学习中的MapReduce任务去执行,可以方便地实现海量数据的统计分析[10]。
3.2 评价标准
实验评价标准采用F1值[11]及均方根标准偏差(root-mean-square standard deviation,RMSSTD)[12]。F1值是一种评价聚类结果的综合指标,计算公式如式(8)所示。其中,正确率Precision为实验结果簇中噪声点与簇中总数据点的点数比;召回率Recall为簇中非噪声点的点数与总数据集非噪声点的点数比。例如数据集总点数为N,聚类后的簇中数据点为N′,总数据集的非噪声点数为M,簇中非噪声点数为M′,则
(6)
(7)
(8)
RMSSTD通过衡量聚结果的同质性,即紧凑程度,来判断聚类效果的好坏。计算公式如式(9)所示
(9)
式中:Ci代表第i个簇,ci是该簇的中心,x∈Ci代表属于第i个簇的一个样本点,ni为第i个簇的样本数量,P为样本点对应的向量维数(例如一个簇含有10个点,则该簇的向量维数即为10)。 ∑i(ni-1)=n-NC,其中n为样本点的总数,NC为聚类簇的个数,通常NC≪n,因此∑i(ni-1) 的值接近点的总数,为一个常数。综上,RMSSTD可以看作是经过归一化的标准差来衡量聚类的效果好坏。
3.3 PB-DBSCAN较DBSCAN在聚类效率上的提升
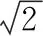
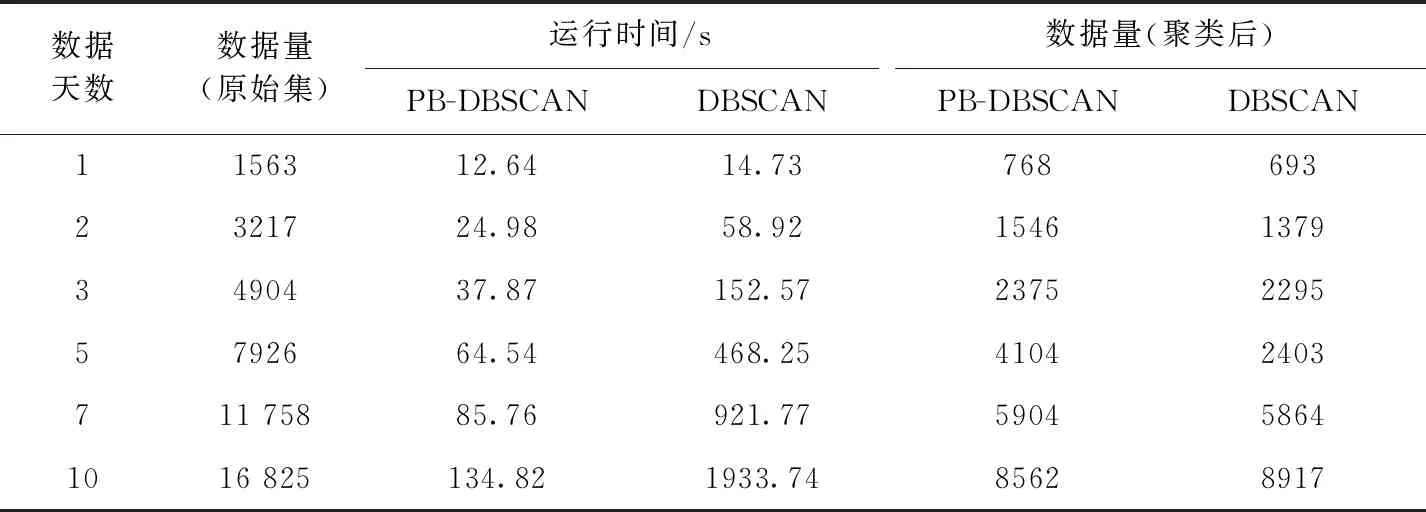
表1 PB-DBSCAN与DBSCAN聚类性能比较
传统的DBSCAN聚类方法,假设数据集总数为n,两个数据点计算一次距离所用时间为t,由于要遍历所有点与未遍历过的点之间的距离,可得所需总时间T=(n-1)t+(n-2)t+(n-3)t+…+t=n(n-1)t/2,所以传统的DBSCAN聚类方法的时间复杂度为O(n2),PB-DBSCAN聚类方法,假设数据集总数为n,分为k个像素格,两个数据点计算一次距离所用时间为t,每次判断每个像素格内的点是否为核心点所用时间nkt,由于每个像素格的相邻像素格数量为20,所以遍历非核心点理论所需最大计算时间为20nt,可得所需总时间T=(20+k)nt,所以PB-DBSCAN聚类方法的时间复杂度为O(n)。
3.4 动态参数选择较固定参数在聚类性能上的提升
为验证动态参数选择聚类方法相较于固定参数对聚类结果性能上的提升,选取石家庄106路、108路、34路、55路、56路和68路在2018年1月12日的上行GPS数据,分别使用动态参数的PB-DBSCAN算法和固定参数的PB-DBSCAN算法进行聚类,实验结果见表2。
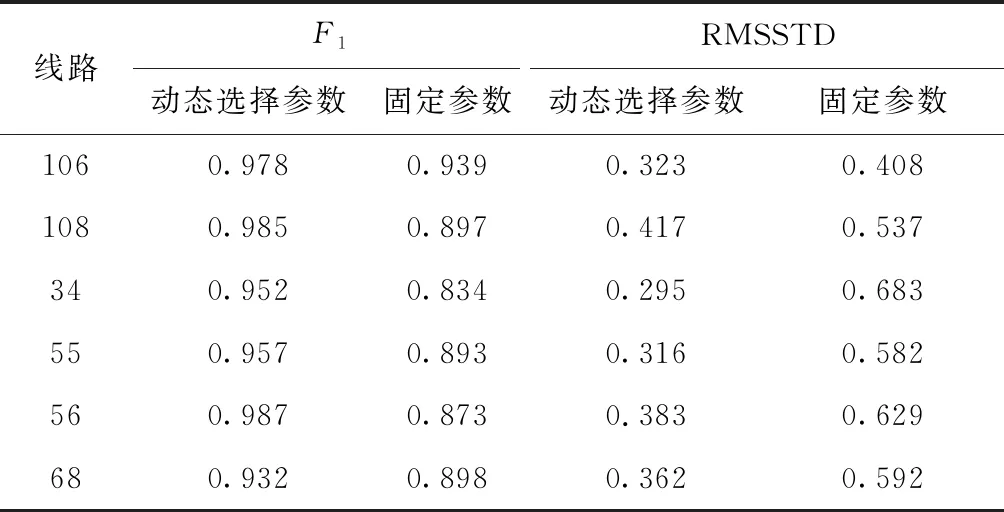
表2 自适应参数与固定参数聚类性能比较
为体现不同线路的动态参数选择聚类过程对初始参数的自适应性,分别对这些线路进行固定参数的预聚类实验,得到在多条线路下满足聚类率在聚类区间内或临近聚类区间的共同初始输入参数:Eps0=20和MinPts0=5。
从F1值评价指标来看,在同一线路比较中,动态选择参数的F1值均大于固定参数,与固定参数相比,F1值平均提高了10%,在不同线路比较中,动态选择参数的F1值更加稳定;从RMSSTD评价指标来看,动态选择参数的RMSSTD值均小于固定参数,与固定参数相比,RMSSTD值平均降低了30%。说明动态参数选择方法的聚类过程相较于固定参数的聚类过程具有良好的稳定性与准确性。
3.5 基于PB-DBSCAN及传统DBSCAN公交GPS去噪的可视化比较
通过对石家庄68路公交车GPS数据的处理来分析验证基于PB-DBSCAN算法的有效性,并且与DBSCAN算法所得到的结果进行可视化比较。图4为PB-DBSCAN算法聚类效果,图5为DBSCAN算法聚类效果。可以看出,在拐点处或点数过密集处,DBSCAN不能很好剔除噪声点,导致最后所得公交线路有明显折线,偏离实际线路,尤其拐点处更是有大量折线,不符合道路实际特征,而PB-DBSCAN所得的聚类结果,由于噪声点少,尤其在拐点处的去噪效果尤为明显,没有出现明显的偏差,所得线路基本符合实际道路,因此,PB-DBSCAN聚类效果明显优于DBSCAN。
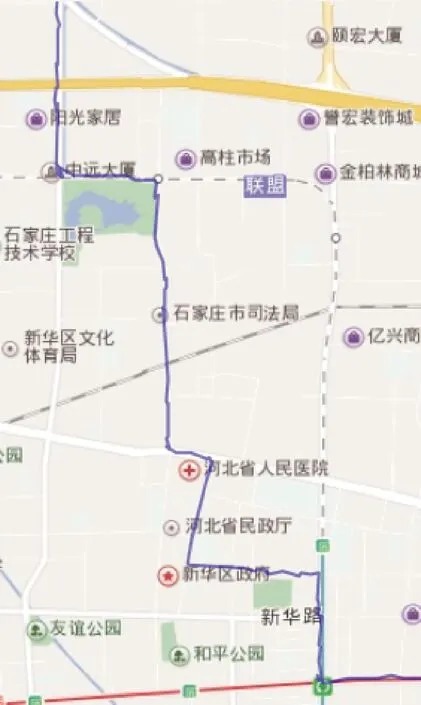
图4 基于PB-DBSCAN的线路生成
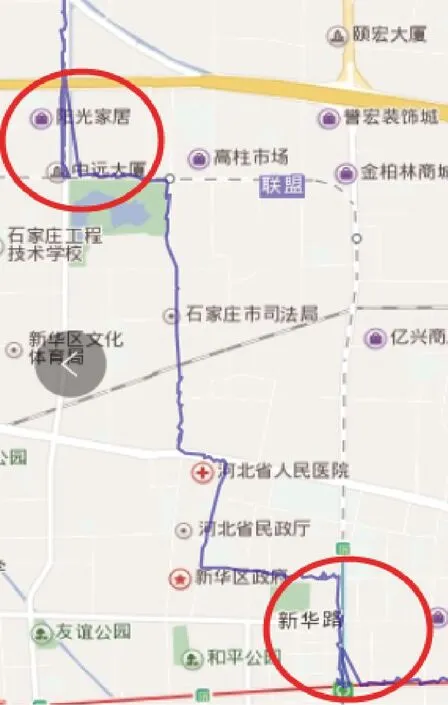
图5 基于DBSCAN的线路生成
4 结束语
本文在DBSCAN算法的基础上,提出了一种基于像素格的快速密度聚类算法——PB-DBSCAN算法,通过将庞大的GPS数据集使用基于像素格的PB-DBSCAN进行聚类,时间复杂度由传统DBSCAN的O(n2) 降为O(n),提高了算法效率。同时本文通过动态参数选择方法,解决了单一的聚类参数无法在保证聚类准确度的情况下对多个不同GPS数据集同时聚类的问题,F1值平均提高了10%,RMSSTD平均降低了30%。下一步的研究中,会对聚类后的GPS数据进行抽稀、拟合等操作,使其更好贴合实际道路,实现数据的价值。
