基于RMSprop的粒子群优化算法
2021-03-23张天泽李元香项正龙李梦莹
张天泽,李元香,项正龙,李梦莹
(武汉大学 计算机学院,湖北 武汉 430072)
0 引 言
粒子群算法(particle swarm optimization,PSO)[1]是由Kennedy和Eberhart提出的一种结构简单、收敛速度快的进化算法。在粒子群算法中,每个解都表示为种群的一个飞行粒子,根据历史最优和全局最优更新当前位置。粒子群算法的优点在于收敛速度快、寻优能力强、算法简单易实现。但粒子群算法容易出现收敛过早、陷入局部最优的现象。为了解决此缺点,近些年学者提出了很多改进思想。一类是融合其它算法提高,利用其它算法的优势提高其寻优能力。文献[2]中将分群策略、混沌优化算法与粒子群算法结合,改善了算法易陷入早熟的问题。文献[3]中将基于PID控制器的控制理论思想和粒子群算法结合,能够让粒子群算法在收敛中调整搜索方向以摆脱局部最优。另一类是改进算法本身,文献[4]提出基于近邻粒子交流的粒子群算法;文献[5]提出了基于自适应高斯分布的简化粒子群算法,使用自适应调节策略强化局部搜索能力;文献[6]提出了自适应惯性权重的粒子群优化算法,利用粒子聚集度、迭代次数来动态改变惯性权重,以此来平衡局部寻优能力和全局寻优能力;文献[7]提出了改进后的自适应惯性权重粒子群算法,利用神经网络中神经元的非线性函数建立数学模型,提高了算法的稳定性和收敛速度;文献[8]将混沌优化算法和粒子群算法结合,提出了一种在搜索过程中动态修正的混沌动态权值粒子群优化算法。不同策略的改进算法都在一定程度上提高了粒子群的收敛速度,但还是避免不了在粒子后期寻优的过程中,随着粒子差异性减小,收敛速度下降,无法跳出局部最优的情况。
粒子群算法属于优化算法一个分支,而经典优化算法在近年取得了更多的发展和应用。在机器学习[9]领域,经典的梯度下降[10]算法是求解最优化问题中最典型的方法。随机梯度下降算法(stochastic gradient descent,SGD)源于1951年Robbins和Monro提出的随机选择一个或者几个样本的梯度替代总体梯度,从而降低了计算复杂度。后续改进策略包括经典动量算法(classical momentum,CM)、Nestero梯度算法(Nesterov’s accelerated gradient,NAG)[11]、Adam(adaptive moment estimation)[12]和Nadam(Nesterov-accelerated adaptive moment estimation)[13]等。文献[14]将Adam算法优化思路与粒子群位置更新相结合,提出了Adam和PSO结合的混合算法AdamPSO,使用Adam方法拓展求解空间进行多一步搜索,提高了粒子群算法的收敛速度。因此,我们可以借鉴经典优化算法中的思想来改进和拓展粒子群算法。
本文则是借鉴了在机器学习梯度下降算法中,学习率自适应变化的思想。与粒子群算法中惯性权重的设置相结合,提出了一种自适应惯性权重的粒子群算法(RMSPSO)。根据每个粒子每个维度的迭代变化设置恰当的惯性权重,提高粒子的局部和全局搜索能力。通过选取对比算法在经典的测试函数进行验证比较分析,结果表明本文提出的RMSPSO在大部分情况下取得了更好的结果,加快了收敛速度的同时还保持了更高的精度。
1 粒子群算法和RMSprop算法
1.1 粒子群算法
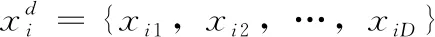
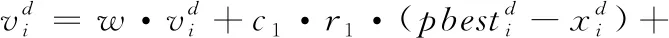
(1)
(2)
其中,ω是惯性权重系数,惯性权重决定了粒子历史飞行速度对当前飞行速度的影响程度。c1是粒子在其历史搜索中找到的最优值的权重系数,通常设为2;c2是粒子在群体搜索中找到最优值的权重系数,通常设为2,c1和c2通常称为加速度常数。r1和r2是(0,1)范围内的两个随机分布值。
基本粒子群算法流程见表1。

表1 粒子群算法流程
1.2 RMSprop算法[15]
在机器学习中,学习率的选择对最终的结果有很大的影响。太小的学习率会导致收敛缓慢,太大的学习率会导致波动增大,妨碍收敛到最优解。目前可采用的方法是在训练过程中调整学习率的大小,如模拟退火[16]算法:预先定义一个迭代次数m,每迭代m次便减小学习率,或者当适应值函数低于一个阈值便减小学习率,然而迭代次数和阈值需要提前定义,因此无法适应数据的特点。
在SGD和Nesterov Momentum[17]中,对于所有参数使用相同的学习率。AdaGrad算法[18,19]的思想是:每一次更新参数,不同参数使用不同的学习率。如式(3)和式(4)所示。其中α是学习率,默认值为0.001。εt是为了防止分母为0的参数,默认值为1e-6
(3)
(4)
AdaGrad在实际使用中发现,从训练开始累计梯度的平方会导致学习率过早的减小,使得训练提前结束。
RMSprop为了克服AdaGrad的缺点,只累计过去w窗口大小的梯度,采用指数加权平均,如式(5)所示,ρ是指数加权参数,一般取0.9
(5)
该算法更新下一位置采用式(6)所示,其中α是学习率,默认值为0.001,εt是为了防止分母为0的参数,默认值为1e-6
(6)
RMSprop相当于计算之前所有梯度平方对应的平均值,可缓解AdaGrad算法学习率下降较快的问题。
2 RMSprop算法在粒子群算法上的应用
2.1 基于RMSprop算法的粒子群算法
(7)
针对粒子群算法存在的这个问题,我们借鉴RMSprop算法的思想,提出了一种基于RMSprop算法的自适应惯性权重取值策略。自适应惯性权重能够根据不同粒子不同维度的搜索信息而提供合适的取值,因此可以得到更快的收敛速度和更好的求解精度。
gij=gbesti-xij
(8)
随着迭代次数的增加,每个粒子i都趋向群体最优位置,则粒子i的梯度gij逐渐减小。因此,我们采用指数加权平均,采用式(9)更新当前维度的梯度和累加∑[g2]t。ρ是加权系数,取值为(0,1)之间
(9)
最后,按照式(10)更新粒子i维度j上的惯性权重ωij,其中α和β是调节系数,α取值为(90,100),β取值为(0.4,0.5)
(10)
从粒子群中的某些维度的粒子来看,在迭代过程中某些粒子当前维度全局最优gbestj到xij的距离gij较大,粒子这一维度的惯性权重ωij就相对较大,有利于粒子探索更多区域;某些粒子当前维度全局最优gbestj到xij的距离gij较小,粒子这一维度的惯性权重ωij则相对较小,有利于局部挖掘。
从粒子群的粒子群体来看,在粒子群算法初期,粒子当前维度全局最优gbestj到xij的距离gij较大,计算的惯性权重ωij较大,有利于粒子全局探索;在粒子群算法末期,粒子当前维度全局最优gbestj到xij的距离gij较小,计算的惯性权重ωij较小,有利于局部挖掘,找到最优解。从而该策略保证了粒子群的多样性和收敛性。
2.2 算法流程
改进的粒子群算法与基本的粒子群算法流程相似,只是在基本粒子群算法的基础上,对惯性权重进行自适应更新,具体的算法流程见表2。

表2 RMSPSO算法流程
3 数值实验和对比分析
为了验证基于RMSprop算法的粒子群算法RMSPSO的收敛性能。本文选取了经典的数值优化函数进行了实验验证,包括单峰函数、多峰函数和组合函数。同时与经典PSO算法GPSO、经典改进算法LPSO、基于CAS理论的粒子群优化算法DAPSO[20]、基于自适应高斯分布的简化粒子群算法IPSO3进行对比实验。
3.1 实验条件及结果
数值优化问题引入了10个数值优化测试函数。分别是经典的测试函数Sphere函数和Ellipsoid和CEC 2013测试函数集中的6、12、13、18、21、23、24、28号函数。分别记为f1、f2、f3、f4、f5、f6、f7、f8、f9、f10。 其中f1和f2是单峰函数,f3、f4、f5、f6是多峰函数,f7、f8、f9、f10是组合函数。以完整检测算法的收敛速度、脱离局部最优的能力和在较小梯度下的收敛能力。测试函数的定义、取值范围和最优解详见表3。
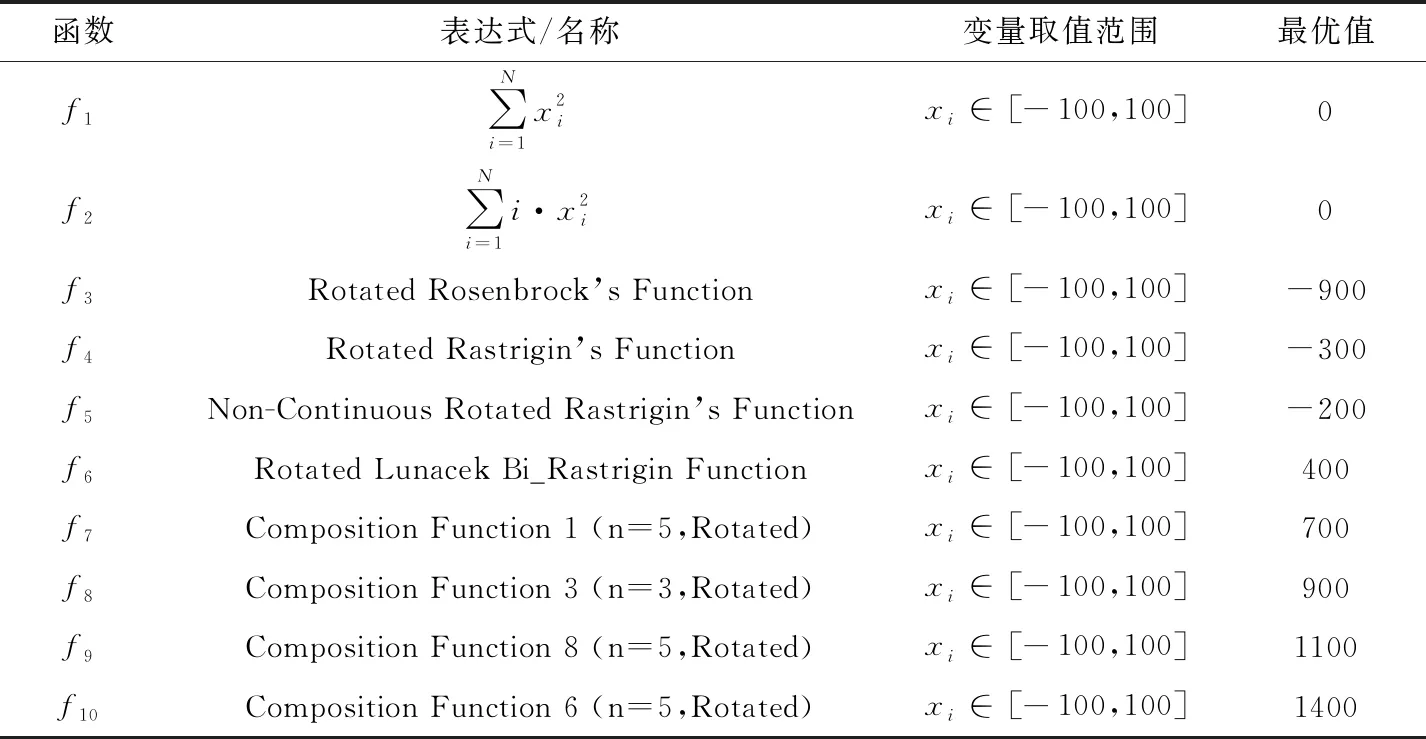
表3 数值优化测试问题
在本节中,将RMSPSO算法和GPSO、LPSO、DAPSO、IPSO3进行比对实验。所有实验的粒子种群为20,每个函数的最大迭代次数为5000。PSO惯性系数ω从0.9到0.5随代数衰减,加速度常数c1和c2设置为2.0。LPSO的参数φ和χ采用默认参数2.01和0.729 844。对测试函数分别在30维和50维进行测试,每个函数独立运行50次,记录实验结果的平均值和方差。
3.2 实验结果分析
为了更加清晰、直观观察改进后的粒子群算法 RMSPSO 的收敛效果,通过10个测试函数的实验仿真图来比较RMSPSO、GPSO、LPSO、DAPSO和IPSO3这5种不同粒子群算法的收敛情况。如图1~图3所示。
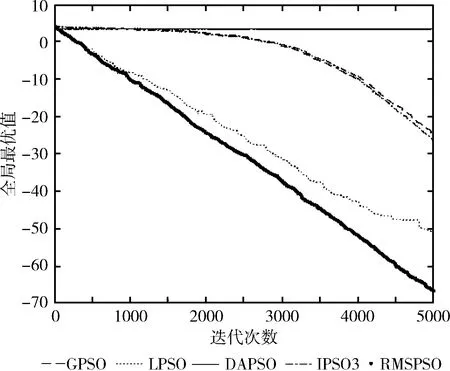
图1 f1测试函数维度=30
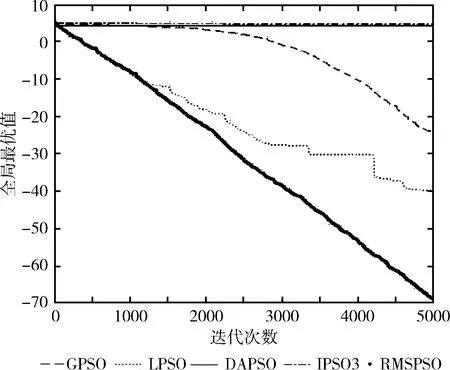
图2 f2测试函数维度=30

图3 f3~f10测试函数维度=30
图1和图2反映了单峰函数f1和f2在30维度上的实验对比结果。通过实验结果可以明显发现,RMSPSO相比GPSO、DAPSO和IPSO3可以在算法早期维持更高收敛速度,在迭代完成后,收敛精度大幅度提高。在迭代中后期,RMSPSO相比LPSO寻优能力更强。可以得出RMSPSO在单峰函数上寻优精度大幅提高,在算法前期、中期和后期始终保持更高的收敛速度,算法寻优效果大幅增强。
图3反映了多峰函数f3、f4、f5、f6和组合函数f7、f8、f9、f10在30维度上的实验比对结果。
可知在多峰函数f3、f4、f5、f6上RMSPSO相比GPSO、LPSO、DAPSO和IPSO3大多取得了更好的收敛精度。充分说明了RMSPSO解决某些多峰函数的优越性,跳出局部最优能力更强。可知在复杂的组合函数f7、f8、f9、f10上RMSPSO相比GPSO、LPSO、DAPSO和IPSO3上大多也取得了更好的收敛精度,也充分说明了RMSPSO解决某些组合函数的优越性,解决复杂函数能力更强。
算法多次运行的最优解均值和最优解方差是衡量算法性能的重要指标。将GPSO、LPSO、IPSO3、DAPSO和RMSPSO分别在30维度和50维度的10个测试函数上运行50次,取平均最优解和最优解方差,运算结果见表4。
由表4可以看出,分别在30维度和50维度在测试函数f1~f10上执行50次数值实验后得到的平均值和平均方差中,30维度下RMSPSO最优解均值取得了8个最优,最优解方差取得了5个最优;在50维度下RMSPSO最优解均值取得了8个最优,最优解方差取得了7个最优。在非最优解的情况下,RMSPSO计算的结果与最优解相差较小。因此可以充分支持本文提出的算法在单峰问题、多峰问题和组合问题上大部分能够取得较好的实验结果。与GPSO、DAPSO和IPSO3相比,结果有较大提升。在少数测试函数上,与LPSO不相上下。由此可以验证本文提出的赋予粒子自适应权重的改进PSO算法增强了粒子在迭代过程中的寻优能力,加快了算法的收敛速度,提高了算法的收敛精度。
从整体的实验效果上看,本文提出的改进算法RMSPSO在单峰、多峰、组合等数值优化问题上都具备一定的适应性。从实验统计结果中平均值可以分析得出,本文提出的改进算法RMSPSO在大部分测试函数的多个维度上可以取得更优的计算结果,这充分说明了本文对每个粒子每个维度设置自适应惯性权重提高了粒子的寻优能力,从而更易跳出局部最优找到更优值,提高了算法的收敛能力和计算精度。从实验统计结果中5个算法运行的最优解方差可以分析得出,本文提出的改进算法RMSPSO在具备更好的收敛能力的同时,计算结果方差更小,计算结果更加稳定,这充分说明了本文提出的RMSPSO具备更佳的鲁棒性。
4 结束语
在粒子群算法中,速度由惯性权重乘以上一代速度加上到局部最优和全局最优的距离更新而来,其中惯性权重ω随迭代次数递减。而在机器学习梯度下降算法Momentum引入了动量的概念,下一梯度由学习率乘以历史梯度加上当前梯度更新而来。可以发现两种算法具有一定的相似性,而基于Momentum改进算法RMSprop是一种自适应学习率方法。因此,本文将RMSprop的自适应学习率的设置策略与粒子群算法相结合,提出了一种自适应惯性权重的粒子群算法RMSPSO。根据每个粒子每一维度上位置的变化设置合适的惯性权重,因此在每一代中不同粒子和不同维度的惯性权重都不同。相比原始粒子群算法,结合自适应惯性权重的粒子群算法能够根据粒子各个维度上的变化设置惯性权重,提高了粒子的寻优能力。实验结果表明,本文提出的改进算法RMSPSO在单峰、多峰、组合数值优化问题多数可以得到比粒子群算法GPSO、改进粒子群算法LPSO、DAPSO和IPSO3更好的结果。这说明本文提出的改进算法RMSPSO在提高粒子寻优能力和加快算法收敛速度和精度上有明显的效果。本文只是将自适应惯性权重设置策略应用于传统粒子群算法,后续工作将着重于研究将自适应惯性权重设置策略和其它粒子群优化算法相结合,进一步验证本文提出改进策略的普适性。

表4 粒子群算法在30维和50维的f1~f10测试函数上的实验结果
