个性化时空数据隐私保护
2021-03-18
(沈阳航空航天大学计算机学院,沈阳 110136)
0 引言
在数字化时代,隐私保护已成为一个越来越具有挑战性的问题。随着科学技术的发展,许多科研机构、企业、国家和个人希望从个人信息中找到可利用的信息,这使得个人信息被许多第三方获取。其中,基于时空数据的大数据分析方法可以帮助实现规划城市发展、制定最优出行计划等功能。时空数据在提供多重纬度数据分析的同时,也存在着严重的个人隐私(如住址、生活习惯和健康状况等)泄露威胁。因此,保护时空数据中的隐私已经成为一项热点研究问题[1-2]。
图1(a)中的用户时空数据以轨迹数据形式列出,每条轨迹由若干个签到数据按时间先后顺序排列而成。图1(b)为用户设置的敏感数据。其中,位置l3为医院,其在轨迹tr1、tr3和tr5中均出现过,用户不想泄露在任何时间前往过该位置的时空数据,将l3设置为敏感位置;位置l7是酒吧,轨迹tr2中的(l7,t23)是用户在t23时刻前往过位置l7形成的签到数据,t23属于用户上班时间段内,用户不想泄露此签到数据,将(l7,t23)设置为敏感签到数据。而轨迹tr4中的(l7,t42)是用户在t42时刻出现在酒吧形成的签到数据,该时刻属于用户的休息时间,用户没有将其设置为敏感数据;(l1,t31)→(l5,t32)→(l3,t33)为用户在某段时间内经过的轨迹,对应图1(a)中的轨迹tr3,该条轨迹包含用户的私密行程,用户将tr3设置为敏感轨迹。可见,对于时空数据,用户具有个性化隐私保护需求。
目前针对时空数据的隐私保护方法分别对位置隐私[3-7]和轨迹隐私[8-11]单独进行保护,针对上述个性化时空数据隐私保护需求,会造成隐私数据泄露或者过度保护,使得数据可用性降低。为解决此问题,本文提出一种个性化时空数据隐私保护方法,用户可以个性化设置隐私数据(位置隐私、签到数据隐私、轨迹隐私),从而有效地对用户的时空数据进行个性化隐私保护。
图1(c)为泛化匿名后的时空数据(以轨迹数据形式列出,泛化后的时空数据如虚下划线处所示)。其中,轨迹tr1、tr3和tr5中的敏感位置l3均被泛化为位置集合{l3,l8,l9,l12},使得l3的泄露概率为1/4;轨迹tr2中的敏感签到数据(l7,t23)被泛化为({l7,l10,l11},t23),使其泄露率为1/3;敏感轨迹tr3中的签到数据(l5,t32)和(l3,t33)分别被泛化为({l5,l4,l13,l14},t33)和({l3,l8,l9,l12},t33),使得轨迹tr3的轨迹匿名(Trajectory Anonymity,TA)率(具体定义后文给出)为50%,轨迹泄露的概率为(100%-50%)=50%。

图1 时空数据和敏感数据及泛化后的时空数据Fig.1 Spatio-temporal data,sensitive data and generalized spatio-temporal data
本文采用启发式泛化方法处理隐私数据,在满足个性化隐私保护需求的前提下,尽可能减少信息损失。例如,针对轨迹隐私保护,以往的研究方法都是对敏感轨迹中所有的签到位置进行处理,这样会因过度保护造成大量信息损失。而采用启发式泛化方法,泛化操作的每一步都同时考虑隐私保护的最大化和信息损失的最小化,减少因过度保护造成的信息损失。实验结果表明,本文算法能有效地个性化保护隐私数据,且信息损失最低。
本文研究内容主要面临3个挑战,如下所述:
1)针对用户分类设置的隐私数据,如何实现个性化隐私保护具有挑战性。以往的研究中,对位置隐私和轨迹隐私单独进行保护,而且没有考虑针对签到数据的隐私保护。如何实现3 种隐私数据的综合保护,且不造成隐私过度保护是研究的难点。
2)如何实现隐私保护最大化的同时降低信息损失具有挑战性。被保护的时空数据最终是要通过大数据分析方法得到利用,以往的研究中,往往只考虑隐私保护最大化,忽略了信息损失造成的影响。本文针对此问题设计的启发式泛化方法是研究的难点。
3)候选泛化位置的选取具有挑战性。如果将签到数据(l,t)中的位置l泛化到位置集合g={l,l′},假设签到数据(l,t)的前驱和后继签到数据分别为(lp,tp)和(ls,ts),那么,位置集合g中的泛化位置l′需要满足以下约束条件:1)泛化位置l′∈g应满足lp和ls之间的时空可达性。以lp为例,用户能在从lp到l的时间(t-tp)内由lp到达l′,即满足时空可达性;2)泛化位置l′应符合用户的运动模式,否则泛化位置l′容易被攻击者识别为假位置;3)因为道路网中的位置数量巨大,如何有效地选择满足上述约束条件的泛化位置是研究的难点,而且是个性化隐私保护算法高效实用的关键。
本文主要贡献包括:1)定义了时空数据发布中保护用户个性化设置的隐私数据的问题;2)提出了一种个性化时空数据隐私保护算法保护用户数据隐私;3)优化了候选泛化位置搜索技术,提高算法执行效率;4)经过大量基于真实时空数据的实验,证明本文算法能有效地保护用户隐私,同时保持已发布时空数据的高可用性。
1 相关工作
针对位置隐私的保护方法主要有差分隐私、空间匿名和加密技术。差分隐私保护技术通过在原始数据中添加随机噪声来干扰隐私数据,能够有效防止基于背景知识的恶意攻击。Xiong等[3]提出一种基于奖励机制的空间众包分配方法,并通过向用户位置信息中添加Laplace噪声来达到位置隐私保护的目的。但是,由于差分隐私方法需要在查询结果中添加大量随机化噪声信息来保护隐私,这样会导致数据可用性急剧下降,甚至在有些复杂查询中,某些真实结果会被随机添加的噪声数据完全掩盖。空间匿名技术最早是由Sweeney[4]提出的一种避免个人敏感数据泄露隐私保护技术,主要思想是用户的敏感位置不能与其他用户的至少k-1个位置区分。Vu等[5]提出了基于局部敏感哈希[6]的隐私保护机制,将用户的位置进行分组,每组包含至少k位用户以实现空间匿名。基于加密技术的隐私保护方法是对用户的基于位置服务查询信息进行加密处理,使攻击者获取到用户信息后也无法分析出隐私信息。Khoshgozaran等[7]提出了一种基于PIR(Protocol Independent Routing)协议并通过模糊位置查询获取k-NN(k-Nearest Neighbor)服务的方法,这种方法可以降低计算和通信的复杂度。
轨迹隐私保护方法主要有抑制法、假轨迹法、泛化法和差分隐私法。抑制法是有选择地抑制发布轨迹数据中的敏感位置或者整条轨迹。赵婧等[8]提出了基于轨迹频率的轨迹抑制方法,采用特定的轨迹局部抑制法对数据进行处理。抑制法虽能简单直接地对轨迹隐私进行保护,但会造成大量信息损失,且当攻击模型不确定时,抑制法将失效。假轨迹法是通过向原始轨迹数据中加入虚假轨迹来进行干扰,降低原始轨迹泄露的概率。董玉兰等[9]提出了通过旋转真实轨迹得到候选假轨迹的方法,然后根据隐私保护要求阈值对假轨迹进行筛选,并将假轨迹添加到真实轨迹中以达到保护隐私的目的。基于泛化的轨迹隐私保护方法的核心思想是采用空间匿名技术,找到k-1 条与敏感轨迹相似的泛化轨迹与敏感轨迹同时发布,使敏感轨迹泄露的概率不超过1/k以达到隐私保护目的。Abul 等[10]提出了基于贪心聚类算法的(k-δ)-匿名模型,利用每一个采样时间点的位置均值形成聚类轨迹进行发布。基于差分隐私的轨迹隐私保护方法类似于位置差分隐私保护技术,主要思想是向原始轨迹数据中添加随机噪声来扰动原始数据。Hua 等[11]提出了以空间泛化为基础的差分隐私算法,利用Laplace 机制向轨迹数据中添加噪声来保护敏感轨迹。
关于个性化隐私保护方法中,目前的研究同样都是分别对位置隐私和轨迹隐私进行保护,没有考虑用户个性化隐私保护需求。Jia 等[12]提出了基于p-敏感k-匿名的个性化敏感特征匿名技术,利用敏感层次树推广敏感属性级别来保护位置隐私。Tian等[13]提出了一种用于轨迹数据发布的新型个性化差分隐私机制,利用Hilbert 曲线原理对原始轨迹数据进行扰动来实现隐私保护。同样,此方法采用了差分隐私机制,会造成大量的信息损失,使数据可用性降低。孙岚等[14]提出一种个性化隐私保护轨迹匿名算法。该算法采用基于贪心聚类的等价类划分思想对含有不同隐私需求的轨迹集合进行个性化匿名处理。Gedil 等[15]提出了一种针对移动系统中位置隐私的个性化匿名模型,利用统一的个性化隐私框架使每个移动节点能够指定其最低的匿名级别,通过消息扰动引擎来实现隐私数据保护。Deldar等[16]通过提出一种针对移动对象的个性化隐私保护算法来满足不同运动对象的个性化隐私保护要求。此算法将非时空敏感属性和差分隐私有机结合起来,以统一的方式实现个性化隐私属性泛化。
现有的个性化隐私保护方法没有对隐私数据进行分类,用户不能设置自己的隐私数据,不能达到真正的个性化隐私保护要求。本文针对此问题,提出了个性化时空数据隐私保护方法。
2 预备知识与问题定义
时空数据(Spatio-Temporal Data,STD)是同时具有时间和空间维度的数据,时空数据集合用DST表示。位置是地图上的空间坐标点(家、超市、药店、医院、公司等),表示为l=(x,y),其中x为经度,y为纬度,直接使用l代表位置,用L表示位置集合。签到数据是带有时间戳的位置信息,用cd=(li,tdm)来表示,用DC来表示签到数据集合。一条轨迹是由m个签到数据组成的序列,可以将轨迹表示为tr=(l1,t11)→(l2,t12)→(li,tdm),轨迹集合表示为DTR。
定义1时空数据隐私。用户不愿泄露的时空数据称为时空数据隐私。本文将时空数据隐私分为3 个类型,分别为位置隐私、签到数据隐私和轨迹隐私。
位置隐私指用户不愿泄露的敏感空间位置l,如图1(b)中的位置l3是医院,用户不想泄露在任何时间前往过此位置的信息,将其定义为位置隐私,其集合表示为SL;签到数据隐私指用户不想泄露某一具体时刻签到的敏感空间位置(l,t),如图1(b)中的签到数据(l7,t23)中的位置l7是酒吧,用户在休息时间可以随意前往该位置,但是t23时刻属于用户上班时间段内,用户不想泄露此签到数据,将其定义为签到数据隐私,其集合表示为SC;轨迹隐私指用户不愿泄露的某一天内敏感签到数据按时间先后顺序排列形成的集合,如图1(b)中的轨迹(l1,t31)→(l5,t32)→(l3,t33)是用户某天依次经过了位置l1、l5、l3所形成的轨迹,用户不想泄露此条轨迹,将其定义为轨迹隐私,其集合表示为STR。
定义2位置距离dist。给定两个位置li和lj,两个位置间的欧氏距离称为位置距离,如式(1)所示:

定义3位置泄露率lri。给定用户时空数据集DST,每个签到数据中时刻tdm对应的位置集为gi,在此时刻泄露用户真实位置的概率为
其中,位置集gi为对该位置泛化处理后,tdm时刻时空数据所包含所有位置的集合。
定义4轨迹匿名率TA。给定一条敏感轨迹tr,该轨迹泛化处理后的轨迹匿名率如式(2)所示:

其中:|Gtr|为轨迹tr泛化后的轨迹数量;|gtri|表示每条泛化轨迹中位置的数量;dl表示泛化后的位置是否与原位置相同,相同为0,不同为1。
轨迹匿名率用来衡量对敏感轨迹泛化处理后相应轨迹集的匿名程度。例如,图1(c)中敏感轨迹tr3所形成的泛化轨迹数量 |Gtr|=1×4×4=16 条,每条泛化轨迹中的位置数量|gtri|=3个。如果第16 条泛化轨迹gtr16=(l1,t31)→(l14,t32)→(l12,t33),其中:l1与原轨迹中的位置相同,l14和l12与原轨迹中的位置不同,则公式TA中的dl1、dl2、dl3分别为0、1、1。所以,敏感轨迹tr3的轨迹匿名率
此定义保证了敏感轨迹中不同位置的泛化程度均满足隐私保护需求。例如,针对敏感轨迹tr3,若仅考虑其泄露概率小于20%,那么对其泛化后的时空数据可为tr3=(l1,t31)→(l5,t32)→({l3,l8,l9,l12l14},t33)。因位置l3被泛化成位置集合{l3,l8,l9,l12l14},所以,敏感轨迹tr3的泄露概率为20%;但是,此方法中,位置l1和l5没有得到保护,攻击者容易推断出真实的敏感轨迹。采用定义4 给出的轨迹匿名率TA度量轨迹匿名程度,可以使敏感轨迹tr3中2/3 的敏感位置得到匿名保护,使得此轨迹被推演攻击的概率降低。
定义5时空数据隐私泄露。给定用户时空数据集DST,敏感数据集DS={SL,SC,STR},隐私保护阈值(p,q,ε),如果:
1)存在位置l∈SL泄露概率大于1/p;
2)存在签到数据cd∈SC泄露概率大于1/q;
3)存在轨迹tr∈STR轨迹匿名率小于ε。
以上任意一条成立,则称为时空数据隐私泄露。
例如,将位置隐私保护阈值p设为5,图1(c)中的敏感位置l3全部泛化为{l3,l8,l9,l12},使l3泄露的概率为1/4,大于1/p,将造成位置隐私泄露。同理,签到数据隐私泄露指敏感签到数据泄露概率大于1/q。轨迹隐私泄露指敏感轨迹泛化后按式(2)计算得到轨迹匿名率小于ε,即泄露概率大于(1-ε)。
定义6时空数据泛化。给定一个签到数据(li,tdm),泛化操作定义为将签到数据(li,tdm)中的位置li转换为位置集合g={li,l′1,…,l′s},g中有s+1 个位置,g中的每个位置出现在td(m-1)时刻到td(m+1)时刻之间的概率相等。
定义7信息损失。给定时空数据集DST={(l1,t11),(l2,t12),…,(ln,tdm)},将敏感签到数据中的位置li(1≤i≤n)泛化到一个位置集合gi中,得到泛化后的时空数据集DST′={(g1,t11),(g2,t12),…,(gn,tdm)}。时空数据的熵定义为H(DST)=lp× lb(lp)=其中lp=如果位置li被抑制,则 |gi|=|Li|,|Li|为敏感位置所在轨迹的位置数。对时空数据集DST进行泛化和抑制操作时,造成的信息损失定义为
此信息损失定义考虑了位置信息熵对于用户整个时空数据集的影响。以往关于时空数据信息损失的定义,只考虑替换或删除某个位置后该位置的信息损失比率、本文定义更有利于计算因时空数据泛化操作所造成的信息损失。
定义8(p,q,ε)-匿名。给定用户时空数据集DST,隐私保护阈值(p,q,ε),经泛化处理后,得到匿名时空数据集DST′中任一位置隐私泄露率不大于1/p,签到数据隐私泄露率不大于1/q,轨迹匿名率不小于ε,则认为时空数据集DST′满足(p,q,ε)-匿名。
图1(c)中的时空数据集满足(4,3,0.5)-匿名。
问题1 给定用户的时空数据集DST,用户设置的隐私数据集合{SL,SC,STR},隐私保护阈值(p,q,ε),通过对时空数据进行泛化处理,得到的时空数据集DST′满足(p,q,ε)-匿名要求,且保证最低信息损失。
3 个性化时空数据隐私保护
在本章中,提出个性化时空数据隐私保护(Personalized Privacy Protection for Spatio-temporal Data,PPPST)算法,对用户个性化设置的隐私数据进行保护,设计了启发式规则度量泛化操作,并优化了候选泛化位置搜索方法。
首先,提出敏感数据判定(Sensitive Data Determination,SDD)算法,对用户定义的敏感数据集DS={SL,SC,STR}进行判断,生成敏感数据列表S,以便进行启发式迭代泛化。
3.1 敏感数据判定算法
如算法1 所示,算法SDD 以时空数据集合DST、敏感数据集合DS={SL,SC,STR}、隐私保护阈值(p,q,ε)作为输入,输出一个敏感数据列表S。
算法1 敏感数据判定算法(SDD)。

对敏感数据集合{SL,SC,STR}进行分类判断,若时空数据DST中每个包含敏感位置l的签到数据cd泛化后的位置集合g中位置个数小于阈值p,则将该签到数据添加到敏感数据列表S中(第2)~6)行);若敏感签到数据集SC中每个签到数据cd泛化后的位置集合g中位置个数小于q,则将该签到数据添加到敏感数据列表S中(第7)~9)行);若敏感轨迹集STR中每条敏感轨迹tr泛化后的轨迹匿名率小于ε,则将该敏感轨迹中对应的签到数据添加到敏感数据列表S中(第10)~14)行)。最后,算法SDD返回一个敏感数据列表S(第15)行)。
3.2 个性化时空数据隐私保护算法
算法PPPST的主要思想是根据用户的隐私保护需求对每个敏感数据进行启发式迭代泛化,直到满足匿名需求,生成可发布的时空数据集合,且保证最低的信息损失。算法2 以用户时空数据集合DST、用户设置的敏感数据集合DS={SL,SC,STR}、隐私保护阈值(p,q,ε)作为输入,返回一个可发布的时空数据集DST′。
算法2 个性化时空数据隐私保护算法(PPPST)。

每一种泛化处理方法都倾向于增加隐私数据匿名性和降低信息损失,关键在于泛化处理的每一步都同时考虑这两种影响,使泛化收益最大。所以,本文采用启发式迭代泛化方法,对隐私数据进行处理。算法2 首先通过SDD 算法生成敏感数据列表S(第1)行)。然后,算法PPPST获得一个Score值降序排列的候选泛化列表Q(第2)行)。其中,Score是一个启发式函数,其值度量了泛化操作匿名性和信息损失的共同影响。Score值越高,泛化操作的匿名性越高,且信息损失越小。列表Q中所有的候选泛化数据通过位置泛化(Location Generalization,LG)算法计算得到。算法2 循环选择Score值最大(在列表Q顶端)的候选泛化位置集合g加入到时空数据集DST中,直到敏感数据列表S为空,即隐私数据全部泛化完毕(第3)~5)行)。最后,算法返回一个符合个性化隐私保护要求的时空数据集合DST′(第6)行)。
3.3 泛化数据度量
对敏感时空数据进行泛化处理,实际上是对各类敏感数据中签到数据(l,t)中的位置l进行泛化。用op=(li,g)表示一次数据泛化,其中g是一个泛化位置集合,g中的位置由泛化位置搜索(Generalized Location Search,GLS)算法搜索得到。用op=(li,-)表示抑制操作,是将因用泛化操作无法达到保护要求的位置数据进行删除。
泛化操作的每一步都需考虑隐私保护的最大化和信息损失的最小化。本文通过位置多样性(表示为Div(g,DST))和信息损失度(表示为InfoLoss(op))来衡量泛化处理的影响,为了最大化泛化处理的作用效果,本文设计了如式(3)所示的启发式规则来度量泛化数据:

其中:位置多样性Div(g,DST)取值越大,Score值越高,隐私保护效果越好,但会造成更多的信息损失;信息损失度InfoLoss(op)越低,Score值越高,数据可用性越高,但隐私不能得到很好的保护。对隐私数据进行泛化操作时,每一步操作都生成一个Score值,并将其降序排列,最终选择Score值最大的位置匿名集合添加到时空数据集中。
位置多样性Div(g,DST)的定义如式(4)所示,此式表示泛化处理后,时空数据集中有数量变化的签到数据集数占总签到数据集数的比例。

其中:div(g,DC)表示签到数据集合DC在添加位置集g后的数据量变化,有变化为1,无变化为0。如图1(c)所示,对用户原始时空数据泛化处理完后的位置多样性为Div(g,DST)=
信息损失度InfoLoss(op)的公式表示为InfoLoss(op)=H(DSTop)-H(DST),其中H(DST)和H(DSTop)分别表示时空数据在泛化操作前后的熵值(由前文定义7给出)。
3.4 位置泛化算法
本文提出位置泛化算法LG,以生成按Score值降序排列的候选泛化时空数据列表Q。泛化过程受两个条件约束,分别是时空可达性和用户运动模式。
定义9时空可达性。用户在两个相邻签到位置间,以该用户平均最大的位移速度vmax在某一时间段内是可达的,称为时空可达性,由式(5)判断:
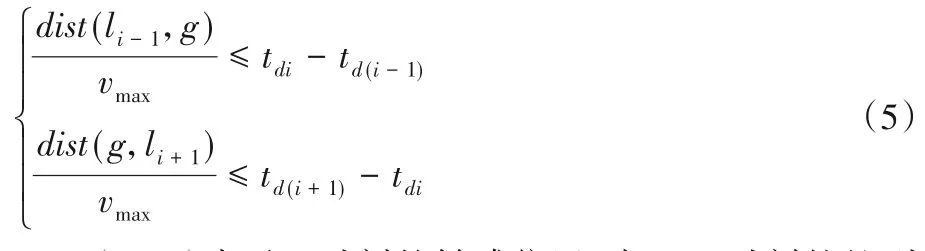
其中:dist(li-1,li)表示tdi时刻的敏感位置li与td(i-1)时刻的签到位置li-1之间在路网中的最短距离,vmax表示用户时空数据中的平均最大位移速度。如果式(5)第1 行不等式不成立,用户将不能在(tdi-td(i-1))时间内由泛化位置li-1到达敏感位置li。同理,很容易推导出式(5)第2 行不等式。当敏感位置li是起始位置时,只考虑式(5)第2行不等式;当敏感位置li是终点位置时,只考虑式(5)第1行不等式。
如图2所示,签到数据(l3,tdi)中的l3为敏感位置,(l2,td(i-1))是其前一时刻td(i-1)的签到数据,(l6,td(i+1))是其后一时刻td(i+1)的签到数据。根据式(5)计算判断可得候选泛化区域Z。
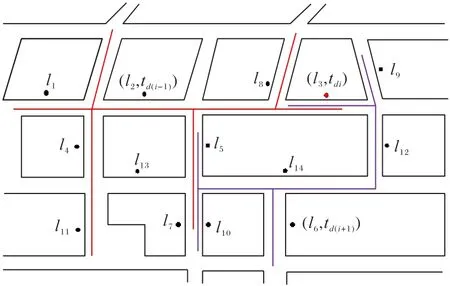
图2 候选泛化区域ZFig.2 Candidate generalized region Z
为了防止攻击者识别出泛化位置,算法LG还必须保证泛化位置符合用户的运动模式。因此设置阈值α,只有泛化位置出现的频度大于α才被作为候选泛化位置。
如算法3 所示,输入时空数据集DST,敏感数据列表S,隐私保护阈值(p,q,ε);输出一个Score值按降序排列的候选泛化时空数据列表Q。
算法3 位置泛化算法(LG)。


在算法3 中,对敏感数据列表S里每个敏感签到数据cd中的敏感位置sl进行泛化操作op=(sl,g={l′})(第2)~10)行)。其中,候选区域Z是通过式(5)计算得来,针对敏感位置sl的候选泛化位置l均从泛化位置搜索算法生成的区域Z中选择(第3)行),且候选泛化位置l要符合用户运动模式约束条件,即l在时空数据集DST中出现的频度不小于阈值α(第5)行)。然后,计算泛化操作op的Score值,并将泛化操作op、敏感位置sl对应的签到时间tdi和Score值插入到列表Q中(第9)~10)行)。
算法3还要对生成的候选泛化位置集合g进行判断,判断其中的位置数是否满足隐私保护阈值的要求,若敏感位置或敏感签到数据泛化后的位置集合g中的位置数分别小于p或q,敏感轨迹泛化后的轨迹匿名率小于ε,则将相应的位置集合g中敏感位置进行抑制操作op=(sl,-)(第12)~13)行)。然后,计算抑制操作op的Score值,并将抑制操作op、敏感位置sl对应的签到时间tdi和Score值插入到列表Q中(第14)~15)行)。最后,算法LG 返回一个Score值降序排列的列表Q(第16)行)。
3.5 泛化位置搜索算法
本文提出泛化位置搜索(GLS)算法,对生成泛化区域Z中的位置搜索进行优化。因生成泛化区域Z时采用宽度优先遍历(Breadth First Search,BFS)搜索候选位置,每个敏感位置需要对路网进行两次BFS,对于一个敏感位置集SL总共需要次BFS,会增加算法运行时间,本文提出Dist-Index数据结构来存储候选泛化位置,以此节省算法运行时间。
定义10距离索引Dist-Index。给定一个敏感位置l,该位置与其他位置的距离索引Dist-Index 定义为一个列表,用l.D表示。列表中存储的元素是搜索得到的候选位置l′和l与l′之间在路网中的距离,l.D中所有的元素按照位置间距离升序排列。
图3(a)所示为道路网中各位置之间的距离矩阵,距离的单位为千米(km)。图3(b)表示各位置间的距离索引。设l.D(d)表示与位置l距离dkm的一组位置,其中d是输入的参数。例如,对于距离敏感位置l30.5 km 的区域搜索,结果为l3.D(0.5)={l1,l2,l5}。
如算法4 所示,输入时空数据集DST,敏感位置sl,输出位置列表l.D。运用数据结构Dist-Index,算法以DST中的每个位置l作为起点,执行一次BFS就可以得到所有可达的位置及位置间的距离。
算法4 泛化位置搜索(GLS)算法。
输入:时空数据集DST,敏感位置sl;
输出:位置列表l.D。

算法4 首先以敏感位置sl为中心点,通过式(5)计算并判断出用户在最大移动速度下行驶的最大距离dmax(第2)~12)行)。然后,以敏感位置sl为起点在道路网中进行一次宽度优先遍历,将搜索得到的候选位置和相应的距离插入以Dist-Index 为存储结构的l.D中,直到搜索距离等于dmax时结束(第13)行)。最后,算法返回一个列表l.D。

图3 距离矩阵和每个位置的Dist-IndexFig.3 Distance matrix and Dist-Index of different locations
3.6 算法复杂度分析
在本节中,将对算法的复杂度进行理论分析。设DST为时空数据集合,DS为敏感数据集合,SC为敏感数据集中的签到数据集合,L为时空数据集中签到位置集合,tr为敏感位置所在的轨迹。
在算法SDD 中,需要对|SC|个敏感位置进行判断,所以,算法SDD 的时间复杂度为O(|SC|)。在算法GLS 中,需要对敏感位置sl所涉及到的时空数据集中的前后位置进行BFS 遍历搜索,所以,算法GLS的时间复杂度为O(|tr|2)。在算法LG中,需要进行|SC|次泛化区域搜索,时间复杂度为O(|SC|·|tr|2),每个泛化操作计算Score值的时间复杂度为O(4·|SC|),最多耗时2|tr|·|SC|,所以算法LG 生成列表Q的时间复杂度为O(2|tr|·|SC|2·|tr|2)。对于算法PPPST,在每次迭代泛化中(第3)~5)行),分别需要O(|SC|)和O(4·|SC|·|Q|)的时间来更新列表S和Q,Q中最多包含|SC|·|L|·|tr|个元素,算法需要循环迭代|SC|·|L|·|tr|次,所以,算法PPPST的时间复杂度为O(2|tr|·|SC|3·|L|·|tr|3)。
4 实验评估与分析
本章通过实验测试对提出的个性化时空数据隐私保护算法进行性能分析和评价。用户的时空数据来自斯坦福大学复杂网络分析平台公开的两个真实数据集Gowalla和Brightkite,同时也利用了这两个数据集所在California 州的道路网数据,包括21 047个节点和21 692条边。本文从两个数据集中分别随机选取了5 000 个用户在加州签到的时空数据集,表1 展示了数据集的相关信息。

表1 实验数据集的统计信息Tab.1 Statistics of experimental datasets
本文提出的个性化时空数据隐私保护算法PPPST,通过与个性化信息数据K-匿名算法(Information Data Used through Kanonymity,IDU-K)[14]和个性化Clique Cloak(Personalized Clique Cloak,PCC)算法[15]进行对比实验来分析本文算法的性能。最后,通过实验评估各算法对数据可用性的影响。
实验环境如下。
1)计算机硬件配置:Intel Core i5 2.5 GHz,8 GB DRAM;
2)操作系统:Windows 10;
3)编程环境:Java语言,IDEA开发平台。
实验中,敏感数据集DS中签到数据个数|SC|是用户个性化设置的敏感位置、敏感签到数据和敏感轨迹中的签到数据数量之和,其取值范围为[5,25](默认为5);隐私保护阈值p和q根据两个真实时空数据集实验总结所得,其取值范围均为[2,6](默认为2),轨迹匿名率阈值ε的取值范围为[0.5,1](默认为0.5);用户运动模式频度阈值α由关联规则挖掘算法根据实验数据集统计所得,其默认值为2。
4.1 算法性能分析
图4 展示了时空数据集DST的平均信息损失随敏感时空数据集DS中签到数据个数|SC|变化的情况。对于时空数据集DST,定义其平均信息损失为,其中Loss为定义7 中给出的时空数据集DST总共的信息损失为时空数据集中签到数据的数量。
由图可见,随着|SC|的增加,信息损失越多,但本文提出的PPPST算法造成的信息损失远低于IDU-K 和PCC 算法,平均低约82.53%。由于本文算法考虑了隐私分类保护,轨迹隐私中可能包含位置隐私和签到数据隐私,采用启发式泛化方法时,当敏感轨迹匿名率大于给定阈值后结束泛化操作,这在一定程度上会降低隐私过度保护造成的信息损失。

图4 信息损失Fig.4 Information loss
图5展示了三个算法的运行时间随敏感签到数据个数|SC|变化的情况。可以看出,随|SC|的增加,运行时间也逐渐增加。本文算法PPPST运行时间始终比IDU-K 和PCC 算法运行时间高,平均多出29.36%的运行时间,因为本文算法采取了启发式时空数据泛化方法,需要更多的时间计算泛化操作的Score值并更新泛化区域Z。但本文算法GLS(算法4)优化了泛化位置的搜索,在一定程度上节省了一半的位置搜索时间。

图5 算法运行时间Fig.5 Algorithm running time
根据定义3 中给出的位置泄露率公式lri,时空数据集DST的平均位置泄露率可以定义为
图6展示了平均位置泄露率AL随敏感位置隐私保护阈值p的变化情况。可见,阈值p越高,时空数据的平均位置泄露率越低。因为随着泛化位置的增加,每个敏感位置得到的混淆位置更多,位置泄露的概率就会降低。本文算法PPPST的平均位置泄露率比IDU-K 和PCC 算法平均低约6.54%,因IDUK 算法对未被泛化的位置信息进行舍弃,会使攻击者通过关联规则攻击技术更容易判断出发布轨迹与原始轨迹的差别,使得平均位置泄露率远高于本文算法;而PCC 算法采用自适应敏感分级的方法对敏感数据进行保护,对于敏感级别较低的属性,该算法不予以保护,所以平均位置泄露率高于本文保护算法。

图6 平均位置泄露率Fig.6 Average location leakage rate
图7 为平均签到数据泄露率AC=随敏感签到数据隐私保护阈值q的变化情况。可见,阈值q越高,平均签到数据泄露率越低。因本文算法PPPST考虑了用户设置的签到数据隐私,即同一位置不同时刻的隐私保护需求。而算法IDU-K 和PCC 仅考虑保护轨迹隐私或者位置隐私,没有根据用户的实际隐私保护需求对敏感签到数据进行保护,导致其平均签到数据泄露率远高于本文算法,平均高约88.2%。

图7 平均签到数据泄露率Fig.7 Average check-in data leakage rate
图8展示了平均轨迹泄露率ATR=其中,TA为定义4 给出的轨迹匿名率(随轨迹匿名率阈值ε的变化情况)。由图可见,阈值ε越高,平均轨迹泄露率越低。本文算法PPPST采用启发式泛化方法,当敏感轨迹匿名率大于匿名阈值ε后,终止对敏感轨迹的泛化操作,使敏感轨迹得到保护的同时,其信息损失最低。算法IDU-K 对敏感轨迹中的所有签到位置进行匿名操作,其轨迹匿名率最高,平均轨迹泄露率最低,比本文算法平均低约19.8%。算法PCC 只对敏感位置进行个性化保护,导致敏感位置所在的轨迹泄露概率最高,比本文算法平均高约65.3%。

图8 平均轨迹泄露率Fig.8 Average trajectory leakage rate
4.2 数据可用性分析
本文评估了发布的时空数据在频繁模式挖掘中的性能,图9展示了数据可用率随敏感位置数|SC|变化的情况。频繁模式置信度阈值设置为10%,时空数据泛化前挖掘出的频繁模式(大于10%)定义为P,泛化后的频繁模式定义为POP,则数据可用率可以定义为DR=

图9 数据可用率Fig.9 Data availability rate
由图可见,随着|SC|的增加,需要在用户原始数据集中添加更多的泛化位置来保护隐私数据,使得DR逐渐降低。因IDU-K 算法对未被聚类的位置进行舍弃,造成大量信息损失,所以其DR值最低;本文算法中考虑了用户的时空可达性和运动模式的限制,使得泛化位置更接近于敏感位置,所以本文算法PPPST的平均数据可用率分别比PCC 和IDU-K 算法高约4.66%和15.45%。
5 结语
本文首次提出面向时空数据的个性化隐私保护模型,并基于该模型提出一种个性化时空数据隐私保护算法PPPST。该算法采用启发式规则来选择候选泛化数据,并对泛化位置搜索进行了优化。PPPST算法可以对用户个性化设置的时空数据隐私进行保护,同时实现了数据的高可用性。基于真实时空数据集进行实验测试和分析,实验结果表明PPPST算法能有效地保护个性化时空数据隐私。由于本文采用欧氏距离的方式计算签到位置间的距离,这与用户真实的移动轨迹存在差异,怎样将真实路网添加到时空数据隐私保护中,将是下一步的研究方向。
