非易失性内存友好的线性哈希索引
——NVM-LH
2021-03-18*
*
(1.中国科学技术大学计算机科学与技术学院,合肥 230001;2.中国人民解放军31002部队,北京 100081)
0 引言
在过去的数十年中,由于存储密度的限制,动态随机访问内存(Dynamic Random Access Memory,DRAM)的容量始终无法超越64 GB,不能满足大数据应用对大容量内存的需求。近年来,非易失性内存(Non-Volatile Memory,NVM)得到了快速发展。特别是Intel 于2019 年4 月推出了单条512 GB 的傲腾非易失内存(Intel Optane DC Persistent Memory),支持8 TB的单机最大NVM 内存,为实现面向大数据实时存取的内存数据库系统提供了有力的支持。在此背景下,如何使得数据库技术(包括索引、缓存管理、查询处理、事务管理等)能够适应引入NVM 之后的数据库系统,成为近些年国内外的研究热点。
与DRAM 相比,NVM 的密度更高,容量更大,但同时也具有读快写慢、写次数有限等限制[1],因此传统数据库算法直接运行在NVM 上往往会导致较多的随机写操作,不仅会影响性能,也会影响NVM的使用寿命,因此需要重新进行设计。
索引是数据库系统保证存取性能的重要技术。由于NVM 引入后人们希望构建纯内存的数据库系统来支持大数据应用,因此,未来基于NVM 的NoSQL数据库系统(例如键值数据库、列存储数据库等)将是一个主要的发展趋势。NoSQL数据库系统通常要求索引能够支持Put、Get等操作,但对范围查询、连接查询等一般不做要求,因此适合采用哈希索引。在哈希索引中,线性哈希索引因其良好的点查询效率、空间代价以及低维护成本而被广泛使用于数据库系统中。但是,传统的线性哈希索引并不能直接应用于NVM。首先,由于NVM具有写慢读快的特点,并且写次数也有限制,这与传统DRAM读写均衡以及写次数不受限有着较大的区别,而传统的线性哈希索引并未考虑NVM 的这一特性;其次,传统基于DRAM的线性哈希索引需要借助先写日志(Write-Ahead Logging,WAL)来实现数据的可恢复性和一致性,但如果在NVM 上也同样采用WAL,将带来大量的NVM 上的日志写操作,同样有损NVM的使用寿命。
近几年,国内外研究人员相继提出了若干针对NVM 的哈希索引算法,例如改进后的可扩展哈希索引CCEH(Cacheline-Conscious Extendible Hashing)[2]、布谷鸟哈希索引[3-4]、Path Hashing[5]、Level Hashing[6-7]等。因为NVM 读快写慢带来的写延迟问题以及持久性特性带来的数据一致性问题之间互相矛盾,因此大家在设计算法时都需要在各项性能之间进行适当的取舍。从目前的研究现状看,研究者考虑了静态哈希和可扩展哈希,但在面向NVM的线性哈希索引方面还鲜有研究。
本文基于传统的线性哈希索引[8],提出并实现了一种NVM 友好的线性哈希索引NVM-LH(NVM-oriented Linear Hashing)。相较于传统的线性哈希索引,NVM-LH 考虑了NVM 的持久性特性,增加了无日志的数据一致性策略,并根据NVM 数据存取的特点,设计了缓存行友好策略以优化内存读写次数,减少写延时带来的额外开销。本文并将NVM-LH与2019年提出的最新NVM可扩展哈希索引CCEH[2]进行了对比。结果表明,NVM-LH 在NVM 写友好性、空间利用率等方面均优于CCEH。
1 相关工作
1.1 研究面临的挑战
1)需要写友好。
NVM 除了持久性之外,最大的特点就是读快写慢,写操作的延迟甚至可以达到DRAM 的数十倍[1],因此设计NVM 友好的算法时,首先要考虑的就是尽量减少写操作的数量。
在增加新数据时,至少会有一次写操作来将数据的指针加入到索引中,而其他写操作则可能来自于哈希值冲突的处理,因此应当尽量避免处理冲突时进行写操作,比如强行设置冲突项移动的次数上限[6]。除此之外动态哈希在增加新数据后桶溢出时要进行分裂和扩展,此时也会出现写操作,因此减少在哈希表分裂时产生的写操作也是一种值得考虑的方法,例如分裂后不立刻删除原桶中已经迁移出的数据,而是在后续插入新数据时再覆盖这些可以判断出不合法的数据[2]。
2)需要缓存行(Cacheline)友好。
因为中央处理器(Central Processing Unit,CPU)缓存(Cache)从内存取数据时,通常以缓存行为单位进行(一般为64 B),因此,NVM 中的数据在存储时应保持按缓存行对齐,并将经常一起使用的数据放到同一个缓存行中以提高缓存的效率[2]。
3)需要减少CPU缓存对NVM的影响。
在现有计算机架构中,CPU 缓存和内存之间的数据交互是必要的,但某些操作对于NVM 并不友好,例如强制将缓存数据刷入NVM 的clflush 操作会增加NVM 写操作,mfence 操作强制规定写操作执行顺序会增加NVM 上的写等待时间[7,9-10]。
4)需要减少指针操作。
NVM 既可以作为计算用的内存,也可作为持久数据存储介质。当NVM 作为存储介质时,程序可能会使用较多的指针操作来访问NVM,这些指针操作可能会导致运行的错误,因而减少指针操作也是一个需要考虑的问题。
5)需要保证数据一致性。
NVM 具有非易失性,因此相较于DRAM 不需要考虑断电时的工作状态。但由于64 位CPU 一次只能操作8 B 的数据,在CPU与NVM之间按64 B的缓存行进行交互时,仍然需要保证失败原子性[11]。如果写缓存行时断电,不会造成只写入了一半的情况,重启后要么完全写入,要么完全没写入。
另一个与一致性相关的问题是如何保证多个写操作之间的顺序(例如WAL 写操作与随后的数据写操作之间的顺序)。为了控制写数据的顺序,系统需要经常使用mfence 和clflush操作或者使用日志记录或写时复制机制,而这又会给NVM 的运行带来极大的时间开销[7,10-11],因此,算法要求在保证一致性的同时具有较低的时间开销。
6)需要较高的空间利用率。
虽然NVM 具有大容量的特点,但只是相对于现有的内存而言的,与磁盘等设备相比,NVM 的容量仍显不足。因此,提高NVM 的空间利用率量也是需要考虑的一个重要方面。尤其对于基于NVM 的索引而言,空间利用率高意味着同等情况下索引的大小更小,更有利于存取性能的提升。
1.2 面向NVM的哈希索引研究
哈希索引作为一种基本的索引结构,既可以作为磁盘数据库索引,也可以作为内存数据库索引。本项目针对的是内存数据库索引,因此本节主要以内存哈希索引为基础进行讨论。下面从静态哈希和动态哈希两个方面讨论NVM 感知的哈希索引研究现状。
1)NVM感知的静态哈希索引。
布谷鸟哈希(Cuckoo Hash)是常用的内存哈希结构,具有空间利用率高、查询速度快等特点。布谷鸟哈希通过多次置换的方式寻找可分配的空间以解决哈希冲突问题。然而,大量的级联更新会引发额外的写操作,因此不能保证对NVM 的写友好性。为了解决这个问题,DEBNATH 等在布谷鸟哈希上进行了一系列的优化,提出PFHT(PCM-Friendly Hash Table)索引结构[9]。PFHT 由Main Table 和Stash Table 组成。在解决哈希冲突策略上,Main Table 使用布谷鸟策略,Stash Table 使用链式策略。通过限制Main Table 的置换次数,可以减少NVM 的写操作;然而,由于Stash Table 的链式结构存在大量的指针,使得读操作时会导致大量的CPU 缓存的丢失因而降低读性能,同时写性能也会由于指针的额外更新操作而下降。
华中科技大学的华宇教授等提出了Path Hashing 索引[5],其逻辑结构类似于一棵倒置的二叉树。Path Hashing 通过多个哈希函数和数据置换操作等优化技巧,提高了索引结构的内存利用率。同时,底层的结构和Stash Table 的效果是相同的,但它通过类似二叉树的结构消除了指针带来的影响,从而提高了写性能。在物理组织上,将相邻的两层中具有连接关系的节点组织在同一个缓存行中,从而提高查询时CPU 缓存的命中率。
面向NVM 的哈希索引不仅需要考虑到NVM 的读写特性,还需要考虑数据的可恢复性。因此,研究者提出了Group Hashing[12],它利用原子更新和相关指令,保证了索引结构的可恢复性。Group Hashing 将存储空间分成多个组(类似页面结构),通过共享组的方式,解决哈希冲突。此外,通过原子更新位图,实现数据的更新和删除,从而保证索引更新时的数据一致性。
2)NVM感知的动态哈希索引。
静态哈希适合数据集大小相对稳定的应用场景,然而,在插入/删除频繁的应用场景下,由于数据的波动较大,静态哈希需要通过重建哈希索引的方式进行扩容。这一过程不仅会导致对NVM 的大量写操作,造成性能的抖动和下降,而且在并发操作时需要对扩容的哈希索引进行加锁,导致索引的访问被阻塞。动态哈希通过桶分裂的方式进行增量式扩容,扩容过程不需要重建整个哈希索引,而且不需要对整个索引进行加锁,因此可以较好地平衡可扩展性和性能。
目前在面向NVM 的动态哈希索引方面的研究工作相对较少,主要有2019 年提出的Level Hashing 和CCEH。Level Hashing[6-7]采用双层结构:Top Level 和Bottom Level。当Bottom Level 无法插入新的数据时,触发哈希桶目录的扩容操作。首先,创建新的Top Level 并将旧的Bottom Level 中的数据进行拷贝;接着,将旧的Top Level 作为新的Bottom Level 并丢弃旧的Bottom Level 完成扩容操作。CCEH 索引[2]是2019年提出的另一种NVM 优化的可扩展哈希索引。区别于传统的可扩展哈希结构,它在哈希桶目录和桶之间增加了一个段结构以减少目录结构带来的空间开销,但由于CCEH 采用了可扩展哈希的设计,每次成倍地增加段结构的数量,使得每次增长后的哈希索引空间利用率都会降低,这与NVM 索引的空间高效性设计目标相背离。
2 基于NVM的线性哈希索引
目前,如何在现有的计算机系统中合理地使用NVM 仍是一个未完全解决的问题。目前Intel 推出的傲腾持久化内存支持两种架构,即Memory Mode 和App-Direct Mode。在Memory Mode下,DRAM 作为NVM 的缓存使用,数据存取会首先访问DRAM,DRAM 没有命中时再访问NVM。Memory Mode 方式并不适合数据库系统。首先,由于DRAM 只是作为NVM 的缓存,因此系统可见的内存仅为NVM 的空间,因此在内存空间使用上不合算;其次,这一架构只是利用了NVM 比DRAM 容量大的优点,所有数据访问依然还是通过DRAM,没有充分利用NVM 的非易失性特点。在App-Direct Mode下,系统可用的内存空间等于DRAM 和NVM 的容量之和,而且操作系统可以感知两类内存的特性,可以充分利用DRAM 和NVM各自的优点。从目前DRAM 和NVM 的发展趋势来看,DRAM和NVM 并存的App-Direct Mode 对于数据库系统更具有可行性和发展前景。因此,本文的研究也基于App-Direct Mode 架构开展设计。
本文基于传统的线性哈希索引,提出了NVM 友好的NVM-LH 索引。该索引通过存储数据时的缓存行对齐实现了缓存行友好性,并增加了无日志式的一致性保证,从而在保证数据一致性的基础上进一步减少NVM上的写操作。
2.1 缓存行对齐
为了实现CPU 缓存友好,需要实现缓存行对齐,并尽可能将一起使用的数据存在同一个缓存行中,同时尽量将读写操作分开在不同的缓存行上执行。
当键值长度小于一个缓存行时,图1 所示的一个桶可以存储多条同哈希值的数据并实现缓存行对齐。在读取数据时,可以一次性读入多条同哈希值的数据,这有助于提高查询性能。
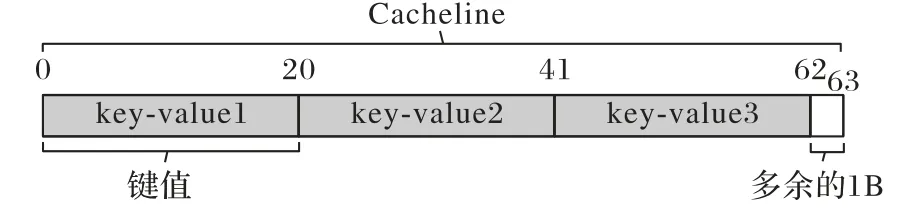
图1 缓存行友好的结构设计Fig.1 Cacheline-friendly structure design
2.2 NVM-LH的操作
索引初始分配n个桶(编号0~n-1),每个桶有m个slot。为了便于统计,n、m均取2 的整数次幂。线性哈希索引需要设定一个加载因子上限,当索引的加载因子达到这个上限时,需要对索引进行分裂操作。加载因子也决定了线性哈希索引的空间利用率。索引还需要维护一个深度值i(i≥1),表示当前索引中的桶数n应满足2i-1≤n<2i。
1)插入。
对于插入key 的请求,NVM-LH 先计算出key 的哈希值,取哈希值的二进制后i位得到桶编号x。若x<n,则说明该桶已存在,可以存入数据;若x≥n,则说明x指向的桶还未被分裂出来,因此应当将数据存入未分裂的桶,即编号为(x-2i-1)的桶。找出对应的桶,然后在桶中的空slot处存入键值,若桶中已满,则申请一个新的溢出桶,将键值存入溢出桶中,并将指向溢出桶的指针存在原桶中。
以上操作需要保证失败原子性,2.3 节将会对此问题进行详细讨论。每次插入完成后,都需要计算当前索引的加载因子,若加载因子超过了初始设定的上限,则执行分裂操作。
2)分裂。
当索引的加载因子超过了设定的上限时,需要对索引进行分裂操作(分裂操作不被允许在用户界面调用),这也是动态索引与静态索引的不同之处。索引维护一个指针p,其始终指向下一个需要分裂的桶,创建索引时p指向第一个桶。
当需要执行分裂操作时,算法先找到p所指向的原桶,然后再申请一个新桶,并将新桶添加到索引中,编号为n。遍历原桶,将原桶中满足其key 的哈希值的二进制第i位为1 的记录存入新桶,然后标记原桶中的该条记录位置为空。全部执行完成后,将n加1,并将p指向原桶的下一个桶。若此时桶的总数n和索引的深度i满足:n≥2i,则索引深度加1,更新p重新指向第一个桶。图2 显示了一轮完整的分裂过程(取加载因子上限为0.75,哈希函数即为其自身,每个桶有3个slot,带有P标识的桶为即将分裂的桶)。图2(a)显示了初始索引,其中深度i=3,桶数n=4,总记录数r=8。图2(b)中,插入13 到索引后由于对应的桶已满,但加载因子未达到上限,故将13 存入溢出桶,同时导致加载因子达到上限,触发桶0 分裂。图2(c)中,插入23、16 成功,插入11 出现冲突并触发桶1 分裂。图2(d)中,插入33成功,插入35触发桶2分裂。图2(e)中,插入24 成功,插入6 导致桶3 分裂。此时桶数n=2i,说明一轮(共2i-1次)分裂操作完成,p重新指向桶0,索引深度更新为i=4)
完成分裂操作后,算法再检查索引的加载因子是否超过上限,如果超过,则再执行一次分裂操作。需要注意的是,如果分裂操作导致原桶的溢出桶为空,则立刻释放溢出桶。
3)查询。
查询操作确定桶编号的过程与插入记录时的操作类似,这里不再多述。利用key 的哈希值找出对应的桶后,在桶中遍历找出与给定key相同的记录,返回该记录的value即可。
4)删除。
为了减少写内存的操作,删除数据时可以采用只删除key的方法(或将key的值改为invalid),这样既不影响后续数据的插入、分裂和查询,也减少了相当数量的写操作。
需要注意的是,如果删除操作导致目标桶的溢出桶为空,要即时释放溢出桶。
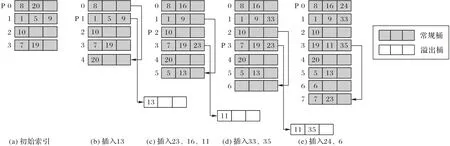
图2 NVM-LH的分裂过程示意图Fig.2 Schematic diagram of NVM-LH splitting process
2.3 无日志的一致性保证
数据一致性要求当操作执行到一半时如果发生了异常导致操作中断,需要保证执行到一半的操作可以回退到执行之前的状态,或者继续执行完成全部的操作并得到正确的结果。传统数据库系统中通常使用WAL 来实现数据一致性。WAL可以完整地记录所有的数据更新操作细节,可以实现系统崩溃时的操作回滚,使数据恢复到崩溃前的一致性状态。但是在NVM 上登记WAL 需要大量的写操作,同时还需要使用大量的mfence 指令来保证日志的先写顺序,这不仅会对算法的执行速度产生很大影响,同时大量的NVM 写操作也会进一步加大系统的处理延迟,此外,NVM 写操作过多也不利于NVM的寿命。本文给出了一种不需要记录日志就能完成一致性状态回退的算法,可以有效减少NVM写操作次数。
2.3.1 非高并发状态
本节首先讨论非高并发状态下的情况。本文的算法直接使用每条记录的key 来判定该条记录是否合法。如果一个slot 中key 的值为invalid(设置为一个不可能出现在数据库中的数)时,该slot即认为是空slot,可以插入数据。
1)插入。
当插入key 时,NVM-LH 使用mfence 指令将key 的写入放在整个插入操作的最后,只有当key 的值从invalid 修改为待插入的值时,该插入操作才算全部完成。如果插入操作执行到一半时发生了中断,重启后因为key 的值仍为invalid,所以无论是否已经成功找到目标桶或slot,或是已经成功插入了value,该数据的插入都认为是失败的。通过这种方式,NVMLH可以保证插入操作的失败原子性。
2)分裂。
当进行分裂操作时,因为无论算法是否并发,同一时刻都只能至多有一个桶在执行分裂操作,所以在开始分裂之前,算法先在NVM 中记下当前分裂的桶。从而在程序重启后也可以立即找到操作中断时的正在分裂的桶。由于NVM-LH先将申请的新桶添加到索引中,再遍历原桶开始搬迁数据,因此重启后新桶中的已经完成搬迁的数据不会丢失,并且也为后续的分裂操作奠定了基础。
由于插入操作可以保证失败原子性,因此分裂中断时正在从原桶迁移至新桶的记录肯定不会存储在新桶中。算法需要保证在单条数据迁移完成之前,数据一定要在原桶中。基于这一分析,可以发现,在执行分裂操作时,将原桶中数据的key的值修改为invalid这一步应当放在整个迁移过程的最后,即先将数据插入新桶,再删除原桶中的数据,这样程序重启后继续完成分裂操作时不会丢失数据。同时,重复插入具有相同key 的数据在执行插入操作时会被自动忽略(或者返回相应的错误码),这样就保证了在继续执行前面中断的分裂操作时,数据既没有丢失,也不会被重复插入。
显然,算法不在执行分裂操作时3 个全局数据n、p、i之间满足关系式n=2i+p,因此在分裂操作时,先更新桶数n,再申请新桶,对数据进行搬迁,然后再根据需要更新深度i(由算法可知大部分情况下不需要更新深度),最后再更新指针p。如果中断重启后发现3 个参数之间的关系变成了n>2i-1+p,说明只有桶数进行了更新,此时恢复该分裂操作只需要程序再重新完整地执行一遍该分裂操作。同样,如果中断重启后发现三个参数之间关系变成了n<2i-1+p,则表明索引深度i的值已经更新,但在更新指针之前程序发生了中断,说明只有指针还未更新,因此在继续完成分裂操作时只需要完成指针更新即可。
无论何种情况,程序都将更新桶数n作为分裂操作的开始信号,将更新完指针p作为分裂操作结束的信号。
3)删除。
当进行删除操作时,算法直接修改key 的值为invalid,其他部分不做变动,这一过程是一个原子操作,可以保证数据一致性。
2.3.2 高并发状态
在高并发状态下,2.3.1 节讨论的无日志算法依然对单个线程有效,因此各操作的原子性依然可以得到保证。现在的问题是如何保证各线程之间的数据一致性。解决这一问题常见的方法是通过加锁来实现线程间的数据一致性。本文也通过给操作增加以桶为粒度的S 锁和X 锁来实现线程间的操作约束。当执行查询操作时,线程需要先申请目标桶的S 锁;当而执行插入、删除操作时则需要申请目标桶的X锁。
下面讨论由索引维护的全局数据:总记录数r,桶数n,索引深度i和待分裂指针p。
1)r:r在算法中的作用是负责触发索引的分裂操作,但因为索引的分裂操作的触发仅仅由当前桶数和总记录数(每个桶的容量和加载因子上限在创建索引时已经固定)决定,不需要由特定的线程触发,且分裂操作的目标桶与触发索引分裂的插入操作的目标桶之间毫无关系,因此分裂操作在一定范围内是允许滞后的,即:总记录数r的更新可以只保证弱一致性。这样在应当分裂到执行分裂之间的这段时间内,本来需要插入新桶的数据会被存进原桶中,但最终执行分裂操作时仍会被迁移至新桶中。因为所有的插入操作都需要更新总记录数,但只有极少数的插入操作会发生在应当分裂但未分裂的时间间隙中,因此在程序高并发时,和保证总记录数强一致所导致的等待时间相比,这部分写内存操作的代价可以忽略不计。
2)n:n是索引分裂的触发条件之一,因此在允许r保持弱一致的情况下,n应当始终保持强一致。
3)i:i在算法的插入和分裂操作中都需要被读取,因此深度i需要十分精确以确保大量的插入操作都能正确地执行,所以i必须保持强一致性。
4)p:p在索引中的作用是提供下一个需要被分裂的桶的位置。在创建索引时,如果单个桶的大小m被设定得较大,则每次分裂之间的时间间隔也会足够大,因此在这种特定初始情况下待分裂指针也就没必要时刻保证一致性,只需要保证弱一致即可。
2.4 算法分析
NVM-LH 的数据结构与传统线性哈希索引的结构类似,因此两者具有相似的算法执行顺序,在查询性能和空间利用率上没有区别。与传统线性哈希索引相比,NVM-LH 的性能提升主要体现在插入数据时的缓存行对齐和无日志一致性保证上。因为算法进行了缓存行对齐优化,因此写入一对键值只需要1 次写内存操作:先将键值写入缓存,再由缓存写入NVM,因为缓存行对齐的缘故,键值由缓存写入NVM 时理论上只需要一次写操作。同理,索引进行分裂操作时因为缓存行对齐,有很多的相邻数据都被写入了同一个缓存行,故实际写操次数作应小于迁移的键值对数。算法使用了无日志的一致性保证,避免了记录日志产生的大量写操作,但仍需要使用一定数量的mfence 指令来保证数据写入的顺序。每个插入操作都需要使用一次mfence 指令;对于每次分裂操作,如果更新了索引深度则需要三次mfence 指令,如果未更新索引深度则只需使用两次mfence 指令。而对于传统基于日志的线性哈希索引,每次插入数据时除了写数据操作之外还需要额外的写日志操作,因此NVM 写操作次数将明显高于NVMLH。
与基于NVM 的可扩展哈希索引(如CCEH[2])相比,NVMLH 的优势主要体现在两个方面:首先,CCEH 索引由于在每次桶溢出时即成倍增加桶,因此空间利用率较低(这是由可扩展哈希索引的设计特性导致的),而NVM-LH采用的是线性扩展的设计,每次只增加一个桶,因此在同等数据集上的空间利用率将大大高于CCEH;其次,如果插入的数据具有较强的倾斜性,即大部分的数据都集中在某几个桶中,CCEH 将产生较多的桶分裂操作,并且每一次桶分裂操作由于都是成倍增加桶数量,将带来大量的NVM 写操作。相比之下,NVM-LH 由于有溢出桶的存在,桶分裂次数将远小于CCEH,因此理论上的NVM 写次数也小于CCEH。在第3 章中的实验结果也证明了这一点。
需要指出的是,CCEH 的理论查询性能必定优于NVMLH。这是因为可扩展哈希索引不存在着溢出桶,因此其查询性能必定优于需要访问溢出桶的线性哈希索引。但是,线性哈希索引的优点在于能够提供时间性能和空间代价两个方面的折中设计;并且,由于NVM-LH 采用了缓存行对齐、无日志一致性保证等技术,以及减少了桶分裂操作,因此在减少NVM 写操作次数方面优于CCEH。综合而言,NVM-LH 为NVM 上的哈希索引设计提供了一种在空间利用率、插入性能、NVM写友好三个方面都具有较好性能的设计思路。
3 性能验证
3.1 实验环境与准备
实验平台为Ubuntu-18.04.4-desktop-amd64,编译环境为gcc-7.5.0,编译命令为g++-std=c++17-I./-lrt-O3-c-o nvmlh.o nvmlh.cpp。
为了进行对比实验,本文选择了2019 年最新的NVM 感知哈希索引CCEH(https://github.com/DICL/CCEH)[2]。实验主要对比性能和空间利用率。实验使用的数据集分为A、B两组。A 组数据的key 为1~R按顺序排列,其中R为数据集大小;B 组数据的key 为随机生成的十进制16 位数字,两种数据的value均为随机生成的由字母构成的32位字符串。
实验中涉及到的可调变量包括:NVM 写延迟时间(测试中默认为300 ns),索引初始桶(段)数量n,单个桶(段)大小m,数据集大小R,NVM-LH 的加载因子上限u(测试中默认为75%)。实验输出的结果变量包括程序的运行时间、算法写内存次数、算法的空间利用率。
3.2 最佳桶大小
CCEH 的论文中给出了其最优段大小范围为4~16 KB[2],因此后续的实验中CCEH 的单个段大小均设置为16 KB,即m=1 024。
NVM-LH 的最佳桶大小选取了插入操作的吞吐量和NVM 写次数两个指标:图3(a)显示了不同桶大小执行插入操作时的吞吐量;图3(b)显示了不同桶大小执行插入操作时的写内存次数。
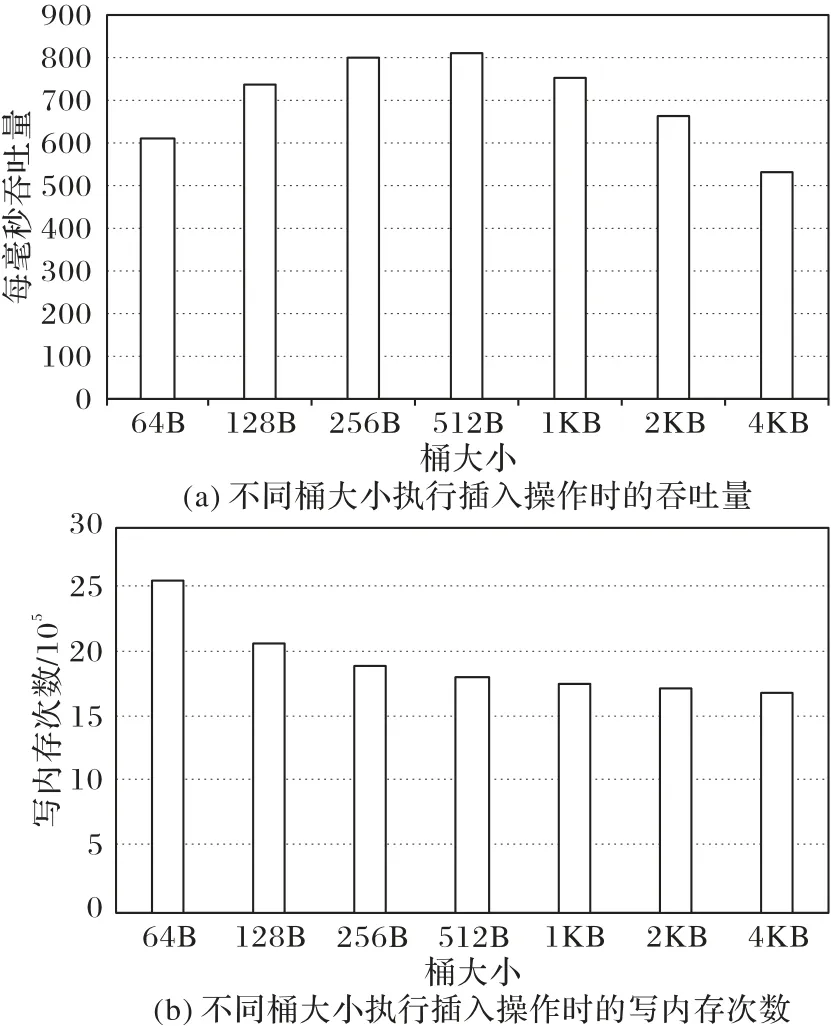
图3 最佳桶大小搜寻结果Fig.3 Result of finding the best bucket size
由图3 可以看出,写内存次数随m的增大而减少,但减少的趋势越来越缓,而数据的吞吐量在512 B 时取到峰值,因此综合考虑,可以将最佳桶大小范围取在256~512 B。在后续的测试中,本文均设置单个桶大小为512 B,即m=32。
3.3 插入操作的效率
实验选取的变量为初始桶(端)的数量n。因为NVM-LH和CCEH 的数据结构不同,因此需要按比例对齐坐标:CCEH中的一个段容量相当于NVM-LH 中的32 个桶,即m(CCEH)=32m(NVM-LH),因此n(NVM-LH)=32n(CCEH)。图4(a)和图4(b)分别展示了插入200万B 组数据时二者的吞吐量和NVM写次数对比结果。其中最后一组数据,即n(NVM-LH)=131 072,n(CCEH)=4 096 时,索引初始大小已经超出数据集大小,即此时理论上NVM-LH 不会触发分裂操作,而CCEH 只会触发极少的分裂操作,此时两种算法的NVM 写次数都等于或者接近数据集大小,即2 000 k。但是从图4(b)中可以发现,NVM-LH 的NVM 写次数多出了500 k,推测应为算法在实现过程中未能成功保证所有的缓存行对齐所致。

图4 插入操作性能Fig.4 Performance of insertion operation
3.4 空间利用率
图5 给出了NVM-LH 和CCEH 在不同的桶/段大小下插入200 万条数据后的空间利用率(NVM-LH 的分裂上限设置为80%)。从图中可以看出,NVM-LH 的平均空间利用率达到了70%以上,而CCEH 的平均空间利用率在40%左右。而且,NVM-LH 的空间利用率随着桶/段大小的增加呈现上升趋势,而CCEH 则呈现下降趋势。这是因为两个算法中影响空间利用率的主要因素不同。影响NVM-LH空间利用率的主要因素是分裂过于频繁而产生的空slot;而影响CCEH 空间利用率的主要因素是段分裂而产生的空slot。因此NVM-LH 桶容量越大,分裂的频率就越小,产生的空slot就越少;而CCEH 的段容量越大,分裂后未使用的slot就越多。

图5 不同桶/段大小下的空间利用率Fig.5 Space utilization under different buckets/segment sizes
3.5 结果分析
由图4 的插入操作实验结果可以看到,在初始条件相同的情况下,NVM-LH 和CCEH 的插入性能相差不大,且吞吐量和NVM 写次数均符合指数增长(下降),与横坐标的增加趋势保持一致。而NVM-LH 在减少NVM 写操作方面的表现更为出色,同时在空间利用率上平均比CCEH 高了30%。虽然NVM-LH的插入性能略低于CCEH,但NVM-LH的插入性能可以通过调低加载因子上限加以提升,因为这时索引需要更加频繁的触发分裂操作来降低自己的加载因子,从而减少了溢出桶的数量,但相对的,NVM 写次数会有所增加。综合而言,NVM-LH 的优势在于提供了一种在时间性能和空间利用率两个方面运行用户进行折中设计的灵活选择,而CCEH 则无法实现这一点。
由于CCEH 采用了无溢出桶的可扩展哈希设计,因此它的理论查询性能优于NVM-LH。由于这是显而易见的结果,因此本文中未对查询性能加以对比。但NVM-LH作为线性哈希索引,其优势在于更高的空间利用率和更少的NVM 写次数。
在高并发状态下,因为NVM-LH 索引中分裂操作是以m=32 的桶为单位进行,而CCEH 中则是以m=1 024 的段为单位来进行的,而且CCEH 是只要发生冲突就会触发分裂,因此NVM-LH 在分裂时的开销要比CCEH 小。事实上图4(b)中NVM-LH 的NVM 写次数始终保持在CCEH 的85%左右,比CCEH 减少了15%左右。其主要原因在于NVM-LH 在分裂时产生的额外开销要更小。
4 结语
本文基于传统的线性哈希索引结构,提出了一种新的NVM 友好的线性哈希索引NVM-LH 并进行了实验验证。通过与现有的NVM 友好的动态哈希索引CCEH 进行对比,表明NVM-LH具有更好的空间利用率和NVM写次数。
在实际的数据库系统中,索引不仅要考虑查询和更新的性能,也要考虑空间利用率,体现时间和空间代价上的综合考量。本文提出的NVM-LH 以线性哈希索引为基础,利用了线性哈希索引良好的空间利用率以及较好的综合性能,为构建面向通用数据库系统上的NVM感知索引提供了设计参考。
在未来工作中,如何优化哈希索引使其能够适应基于DRAM 和NVM 的异构混合内存[13]以及哈希连接算法[14]是值得研究的方向。此外,高并发环境下的索引一致性问题也是未来值得研究的一个重要问题[15-16]。采用锁机制很显然会带来较大的代价,但无锁化的线性哈希索引设计目前还存在难点,需要研究创新的方法。
